](https://deep-paper.org/en/paper/2406.16536/images/cover.png)
像 GPT-4 和 Qwen 这样的大型语言模型 (LLM) 彻底改变了我们与文本交互的方式。它们可以写诗、生成代码,并总结复杂的文档。然而,在一个看似简单的具体任务上,这些巨头经常跌跟头: 中文拼写纠错 (CSC) 。
这看起来似乎违反直觉。一个能够通过律师资格考试的模型,怎么会无法纠正中文句子中一个简单的同音字错误呢?
在这次深度探索中,我们将研究一篇引人入胜的论文——“C-LLM: Learn to Check Chinese Spelling Errors Character by Character” (C-LLM: 学习逐字检查中文拼写错误) 。 我们将揭示为何现代 LLM 的标准架构会为拼写纠错造成根本性的瓶颈,以及一种新方法 C-LLM 如何提出结构性转变——改变模型“看”文本的方式——从而达到最先进的效果。
如果你是 NLP 或计算机科学专业的学生,这次分析将带你经历从问题定义到分词机制,最后到超越现有基准的新颖解决方案的旅程。
LLM 在拼写纠错中的悖论
中文拼写纠错 (CSC) 是一项具有非常具体约束条件的任务。与可能涉及重写整个短语的语法纠错不同,CSC 通常涉及检测并纠正单个错误字符。
该任务通常遵循两条严格的规则:
- 等长约束 (Equal Length Constraint) : 纠正后的句子必须与源句子具有完全相同数量的字符。
- 语音约束 (Phonetic Constraint) : 大约 83% 的中文拼写错误是同音字或发音相似的字 (例如,输入了“dà”而不是另一个“dà”) 。
为什么通用 LLM 在这里会失败?
你可能期望 LLM 能通过少样本提示 (few-shot prompting) 在这方面表现出色。然而,研究人员发现,像 GPT-4 这样的模型经常产生违反这些约束的“幻觉”式修改。
测试显示,GPT-4 生成的输出中, 10% 的预测句子与源句长度不符 。 更糟糕的是, 35% 的预测字符与原始字符在发音上不相似 。 这意味着模型不仅仅是在纠正拼写,它经常是在完全重写句子,或者猜测听起来与原字毫无关系的字符。
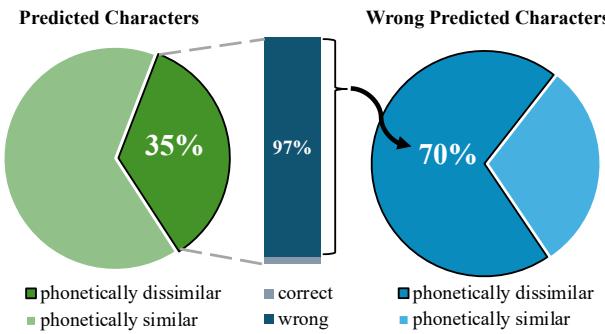
如 图 2 所示,模型的一大部分错误来自于这些发音不相似的预测 (蓝色部分) 。如果模型猜了一个听起来完全不同的字,它就不是在执行“拼写检查”——而是在进行语义重写,这并不是我们想要的。
研究人员指出,根本原因不在于模型的智能程度,而在于分词 (tokenization) 。
根本原因: 字词混合分词
要理解 C-LLM,我们首先需要了解标准 LLM 如何处理文本。现代模型使用 字节对编码 (BPE) 或类似的子词分词策略。这很高效,因为它将常见的字符组合成单个 token (词) 。
例如,在英语中,“unbelievable”可能是一个 token。在中文里,常见的由多个字组成的词,如“胆量”或“图片”,会被组合成单个 token。
对齐问题
这种分组创造了一种“字词混合”的情况,破坏了 CSC 所需的一对一映射。
让我们看一个研究人员提供的具体例子。
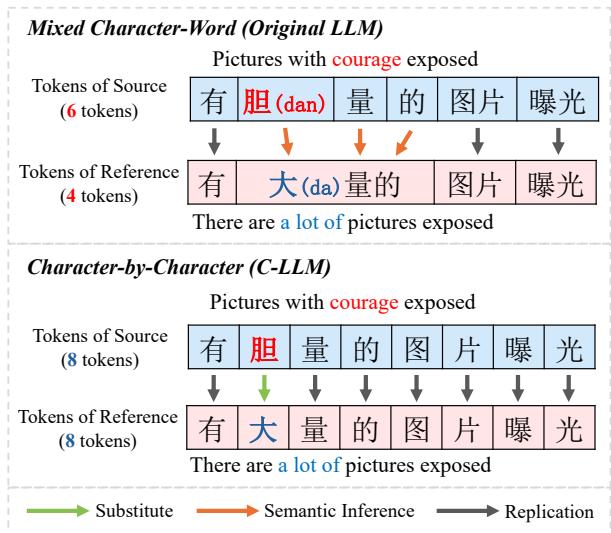
在 图 1 的上半部分,我们看到了“原始 LLM”的方法。
- 源 (Source) : 输入包含字符“有 胆量 的…”。
- 参考/目标 (Reference) : 纠正应该是“有 大量 的…”。
问题就在这里: 分词器将“胆量” (dǎn liàng) 视为一个 token 。 但纠错需要将“胆”改为“大” (dà) 。模型实际上必须:
- 获取 token “胆量”。
- 在内部将其拆解为“胆”和“量”。
- 意识到“胆”是错的。
- 找到一个新词“大量”或 token 组合“大”和“量”来替换它。
这种复杂的推理要求模型推断隐式对齐。它不能简单地说“将第 2 个字符替换为字符 X”。
错位的数学视角
我们可以将这种错位形式化。设 \(x_t\) 为源 token,\(y_t\) 为参考 (纠正后的) token。
在标准 LLM 中,一个源 token 可能映射到多个字符,或者多个 token 可能合并为一个词。
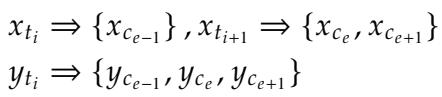
在上面的方程中:
- \(x_{t_{i+1}}\) 是一个包含两个字符 \(\{x_{c_e}, x_{c_{e+1}}\}\) 的单个 token。
- 目标 \(y_{t_i}\) 将三个字符组合在一起。
这产生了一个“多对一”或“一对多”的映射问题。模型很难学习等长约束 , 因为即使字符数量应该保持不变,token 的数量却在变化。
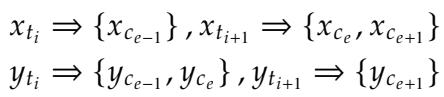
即使是在上述 token 数量匹配的情况下,token 的边界可能会发生偏移,从而混淆语音映射。模型本质上失去了关于哪个特定字符发音像哪个其他字符的线索。
解决方案: C-LLM (逐字处理)
为了解决这个问题,研究人员提出了 C-LLM 。 其核心理念既优雅又简单: 强制 LLM 逐字 (Character-by-Character) 处理文本。
如果模型一次只读一个字,CSC 任务就从一个复杂的推理问题简化为一个直接的序列标注任务: “复制这个字,复制那个字,替换这个字。”
以下是 C-LLM 流程的概览:
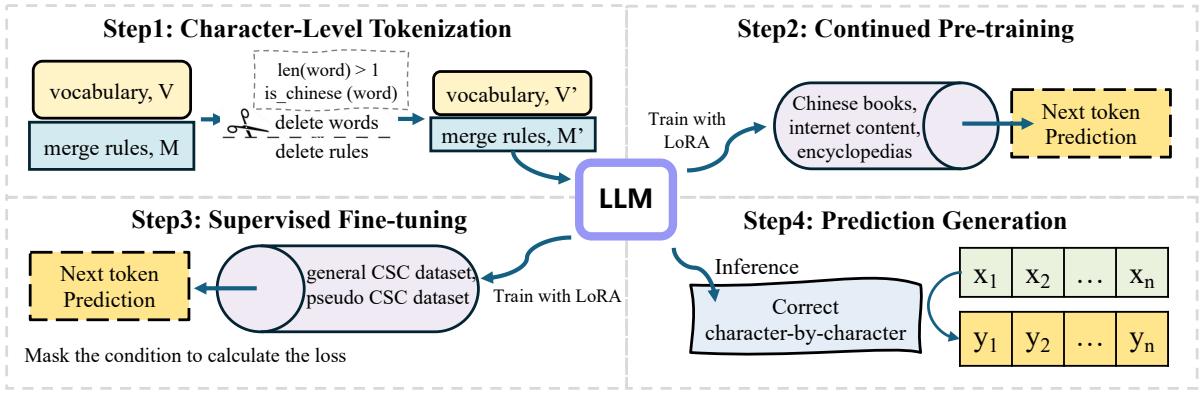
该方法包含三个不同阶段:
- 字符级分词 (Character-Level Tokenization)
- 持续预训练 (Continued Pre-training)
- 有监督微调 (SFT)
让我们逐一拆解。
第一步: 字符级分词
第一步是修改模型的词表。研究人员获取了标准词表 (在本实验中来自 QWEN) 并进行了过滤。
他们移除了任何代表多字中文词的 token。他们调整了合并规则,以确保任何中文字符串都会被拆分成单个字符。
结果是一个干净的、一对一的对齐:
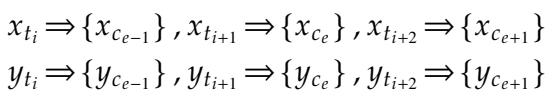
如上式所示,每个源 token \(x_{t_i}\) 对应确切的一个字符,以及确切的一个目标 token \(y_{t_i}\)。这在架构层面显式地强制执行了长度约束。
第二步: 持续预训练
你不能仅仅更改分词器就期望模型能正常工作。模型原本是被训练来理解“词”的。通过将所有内容切分为字符,我们实际上扰乱了它的内部语言模型——其“困惑度” (perplexity,衡量模型对文本感到惊讶程度的指标) 会飙升。
为了修复这个问题,研究人员进行了持续预训练 。 他们使用带有新字符级词表的模型,在海量通用中文文本语料库 (书籍、百科全书、互联网内容) 上进行训练。
这一步使模型能够适应新的细粒度输入。正如论文中所述,在这一步之前,困惑度非常高 (意味着模型很困惑) 。经过预训练后,困惑度回落到与原始模型相当的水平。
第三步: 有监督微调 (SFT)
最后,模型被教授拼写纠错的具体任务。研究人员使用了 LoRA (低秩适应) , 一种参数高效微调方法。
使用的损失函数是生成模型的标准函数:
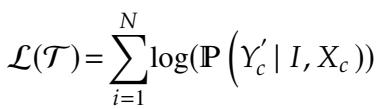
模型被输入 (包含错误的输入句,纠正后的句子) 对,并学习预测正确的序列。由于第一步的操作,这个学习过程现在对模型来说容易得多: 它主要只是学习“复制” token,只有当它检测到语音或视觉不匹配时才激活其“纠错”逻辑。
实验结果
研究人员在两个主要基准上评估了 C-LLM: CSCD-NS (通用拼写错误) 和 LEMON (一个涵盖医疗、游戏、汽车和新闻领域的困难多领域数据集) 。
他们将 C-LLM 与以下模型进行了比较:
- BERT 类模型: 以前的最先进模型 (如 PLOME, SCOPE) 。
- 原始 LLM: 使用标准分词的 QWEN、ChatGPT 和 GPT-4。
性能对比
结果是决定性的。C-LLM 显著优于 BERT 基模型和标准 LLM。
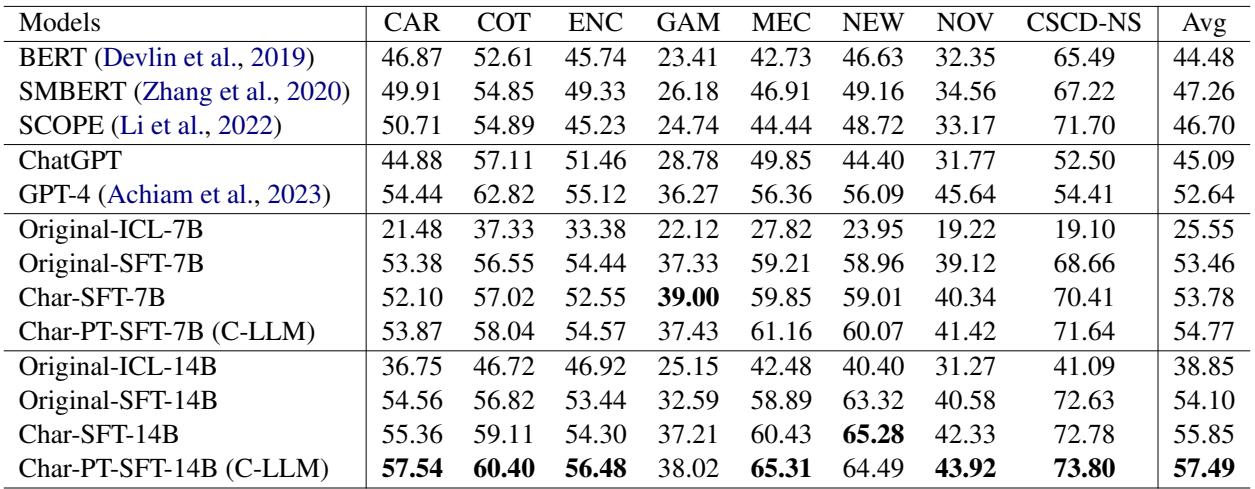
在 表 3 中,查看最右侧的 Avg (平均) 列:
- BERT 类模型 的平均 F1 分数在 44% 到 47% 之间。
- GPT-4 达到了 52.64%。
- 原始 QWEN (14B) 达到了 54.10%。
- C-LLM (14B) 达到了 57.49% , 创造了新的 SOTA (目前最佳) 水平。
在特定垂直领域,改进甚至更为剧烈。例如,在 汽车 (CAR) 和 医疗 (MEC) 领域,C-LLM 显示出相对于基线的大幅提升。
扩展趋势
现代 AI 中最重要的问题之一是: “它能扩展吗?”如果我们把模型做大,这个方法还有用吗?
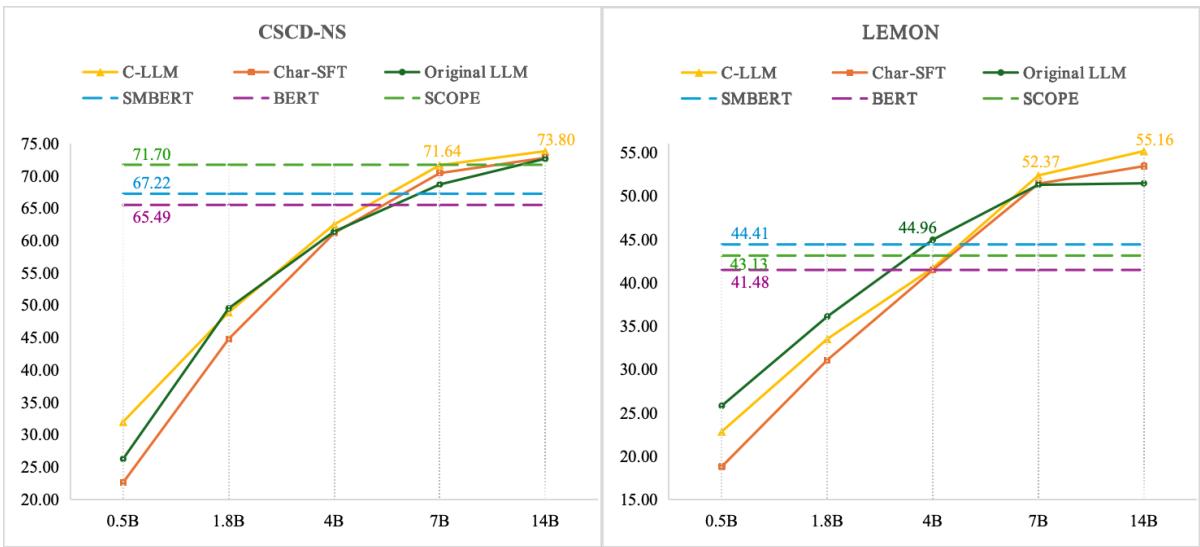
图 4 展示了扩展趋势。 红线 代表 C-LLM。
- 在左图 (CSCD-NS 数据集) 上,随着模型规模从 0.5B 增加到 14B 参数,C-LLM 始终保持领先。
- C-LLM 与“原始 LLM” (蓝线) 之间的差距表明,字符级方法解锁了单纯依靠参数数量无法轻易实现的性能。
分析“原因”: 长度与发音
这个方法真的解决了我们在引言中讨论的具体约束问题吗?
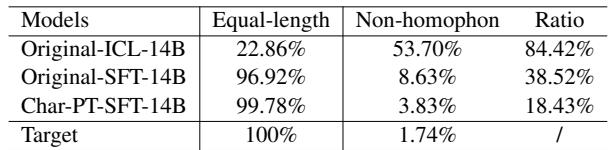
表 4 证实了假设:
- 等长性: 原始模型仅在 96.92% 的情况下保持了正确的句子长度。C-LLM 将其提升至 99.78%——几乎完美。
- 非同音错误: 原始模型在 8.63% 的情况下做出“随机”猜测 (非同音错误) 。C-LLM 将此降低到了 3.83% 。
这证明了通过强制模型逐字操作,它变得更加“保守”且精确,遵循了中文拼写的严格规则。
权衡: 推理速度
没有哪种方法是完美的。通过将词拆分为单个字符,文本的序列长度增加了。由于 LLM 每次生成一个 token,逐字生成句子比逐词生成要花费更长的时间。

如 表 5 所示,测试集的 token 数量 (#Tokens) 从 8.3 万增加到了 12.7 万。因此,推理时间增加了大约 22% 。
然而,作者指出了一个有趣的副作用: 推测性解码的 接受率 (AR) 增加了。因为任务变简单了 (主要是复制字符) ,“草稿模型” (用于加速生成的较小模型) 在猜测下一个 token 时更加准确,这有助于缓解部分速度损失。
结论
论文 “C-LLM: Learn to Check Chinese Spelling Errors Character by Character” 为架构设计提供了令人信服的一课。它提醒我们“大未必总是好”——有时,“结构对齐”更好。
标准 LLM 尽管具有推理能力,但在中文拼写纠错方面却受到阻碍,因为它们的分词器抽象掉了需要纠正的最小单位 (字符) 。通过回归到更简单的字符级视角,C-LLM 将模型的感知与任务的现实对齐了。
关键要点:
- 粒度至关重要: 分词不仅仅是预处理步骤;它从根本上定义了模型可以轻松操作的内容。
- 约束是关键: CSC 之所以困难是因为长度和发音约束。字符级 token 自然地强制执行了长度约束。
- 适应性: 我们可以通过持续预训练和微调,将强大的通用 LLM 改造为适应特定粒度。
对于学生和研究人员来说,C-LLM 提供了一个很好的例子,展示了如何分析模型的具体错误 (如图 2 中的语音不匹配) ,并导向一个针对性的架构解决方案,从而推动技术最前沿的发展。