](https://deep-paper.org/en/paper/2406.16620/images/cover.png)
想象一下,你正试图在一份 24 小时的监控录像或一部信息量巨大的三小时电影中寻找一个特定的细节——也许是角色把香烟掉在地上的那一刻,或者是仅仅出现两秒钟的汽车车牌。作为人类,你不会记住视频的每一个像素。相反,你会观看视频,对情节形成大致印象,当被问及具体问题时,你会拖动时间轴,“倒带”到相关部分去检查细节。
这种动态过程对人类来说是直观的,但对人工智能来说却极具挑战性。虽然大语言模型 (LLMs) 已经进化为能够“看到”图像的多模态大语言模型 (MLLMs) ,但它们在处理长视频时仍面临巨大困难。电影或全天候监控录像中的海量数据超出了大多数模型的上下文窗口。
传统的解决方案包括将视频切割成关键帧或将其总结为文本,但这会导致显著的信息丢失。如果摘要生成器认为掉落的香烟不重要,那么这条信息就永远丢失了。
OmAgent 应运而生,这是由 Om AI Research 和浙江大学的研究人员开发的一个新框架。OmAgent 复制了人类理解视频的认知过程。它结合了一个复杂的记忆检索系统和一个“分治 (Divide-and-Conquer) ”代理,该代理能够自主规划任务,并且——最关键的是——在记忆模糊时使用“倒带 (Rewinder) ”工具回看原始视频片段。
在这篇深度文章中,我们将探讨 OmAgent 是如何实现这一点的,它超越了简单的视频摘要,实现了真正的复杂视频理解。
挑战: 记忆瓶颈
要理解为什么需要 OmAgent,我们首先需要看看目前的 AI 是如何处理视频的。
- 视频 LLMs (Video LLMs) : 一些模型是从头开始在视频数据上训练的。虽然对短片 (几秒或几分钟) 有效,但它们的计算成本昂贵,并且难以在数小时的镜头中保持上下文。
- 多模态 RAG (检索增强生成) : 这是处理大数据的行业标准。视频被分成块,存储在数据库中,AI 仅根据你的问题检索“相关”的块。
标准多模态 RAG 的问题在于分段缺口 (segmentation gap) 。 当连续的视频流被切成离散的块并转换为向量嵌入时,时间的流动被打断了。存在于这些片段缝隙之间的信息,或者在最初的场景文本描述中未捕捉到的细微细节,变得无法检索。
OmAgent 通过确保 AI 不仅仅依赖于静态摘要来解决这个问题。它赋予 AI 行动、调查和验证的代理能力。
OmAgent 架构
OmAgent 通过协同工作的两个主要机制运行:
- Video2RAG: 一个预处理管道,将视频转换为结构化的“长期记忆”。
- DnC 循环 (分治循环) : 一个智能代理循环,将复杂的用户查询分解为可解决的子任务。
让我们逐一拆解。
1. Video2RAG: 构建基础
在代理回答问题之前,必须将视频处理成 AI 可以有效查询的格式。OmAgent 将其视为一个“视频到检索增强生成” (Video2RAG) 问题。
该系统没有将整个视频输入给 LLM (这会超出 Token 限制) ,而是处理视频以创建一个知识数据库 。
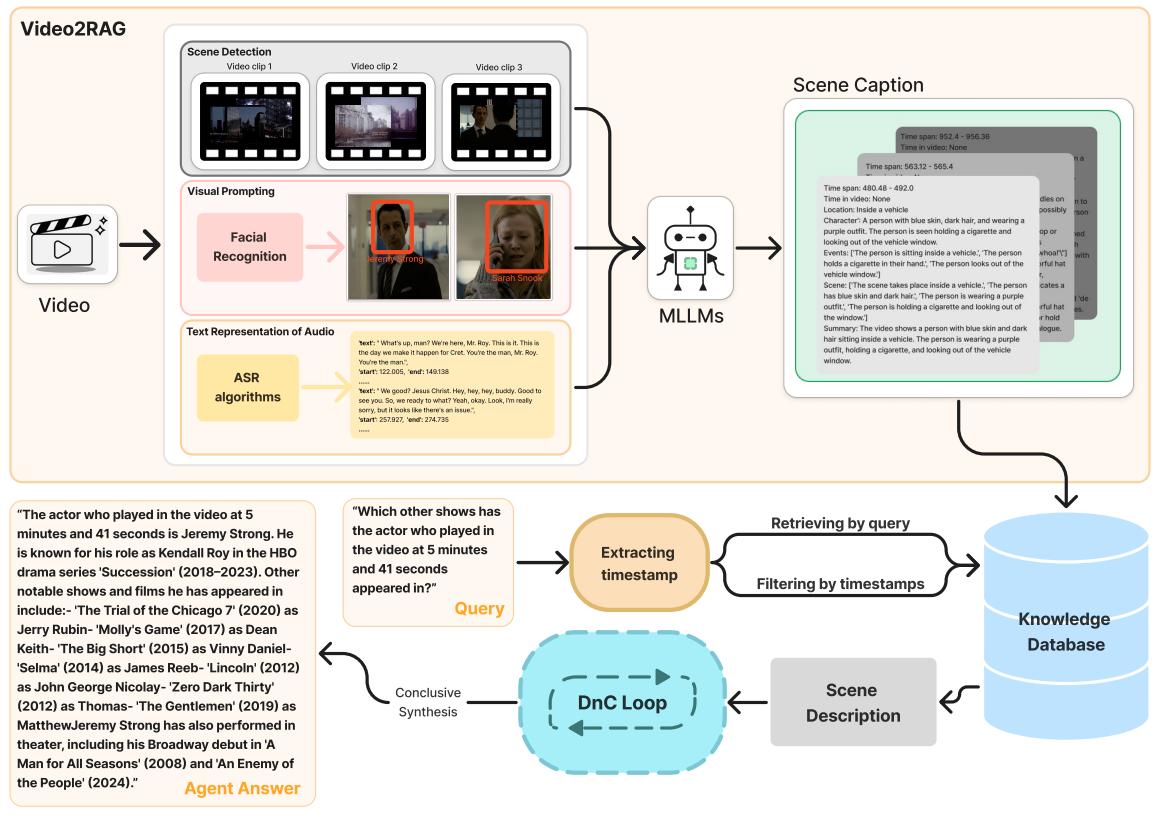
如图 1 所示,该过程涉及几个复杂的步骤:
- 场景检测 (Scene Detection) : 根据视觉变化对视频进行分段。如果场景太短,则将其与其他场景合并。从每个片段中均匀采样 10 帧。
- 算法提取: 系统不仅查看像素;它还运行专门的算法。
- ASR (自动语音识别) : 将对话转换为文本。
- 说话人分离 (Speaker Diarization) : 识别谁在说话。
- 视觉提示 (Visual Prompting) : 这是一个巧妙的补充。系统使用人脸识别来识别角色,并在图像上绘制带有文本标签的边界框。这有助于 MLLM 在拥挤的场景中识别特定人物。
- 场景描述生成 (Scene Captioning) : MLLM 接收这些带注释的帧和音频文本,为每个片段生成密集的结构化说明。研究人员指示模型捕捉特定维度: 时间 (早上/晚上) 、地点、角色动作以及按时间顺序排列的事件列表。
- 向量存储: 这些丰富的说明被向量化并存储。至关重要的是,系统保留了原始时间戳 , 这作为代理稍后使用“倒带”工具的地图。
2. 分治 (DnC) 循环
这是 OmAgent 的“大脑”。受递归编程算法的启发,DnC 循环允许代理处理对于单步推理来说过于复杂的问题。
例如,如果你问: “视频中 5 分 41 秒出现的那个演员还出演过哪些其他节目?”,标准模型可能会产生幻觉或失败,因为它需要三个不同的步骤: 找到帧、识别人脸和搜索网络。
OmAgent 通过 征服者 (Conqueror) 和 划分者 (Divider) 模块来处理这个问题。
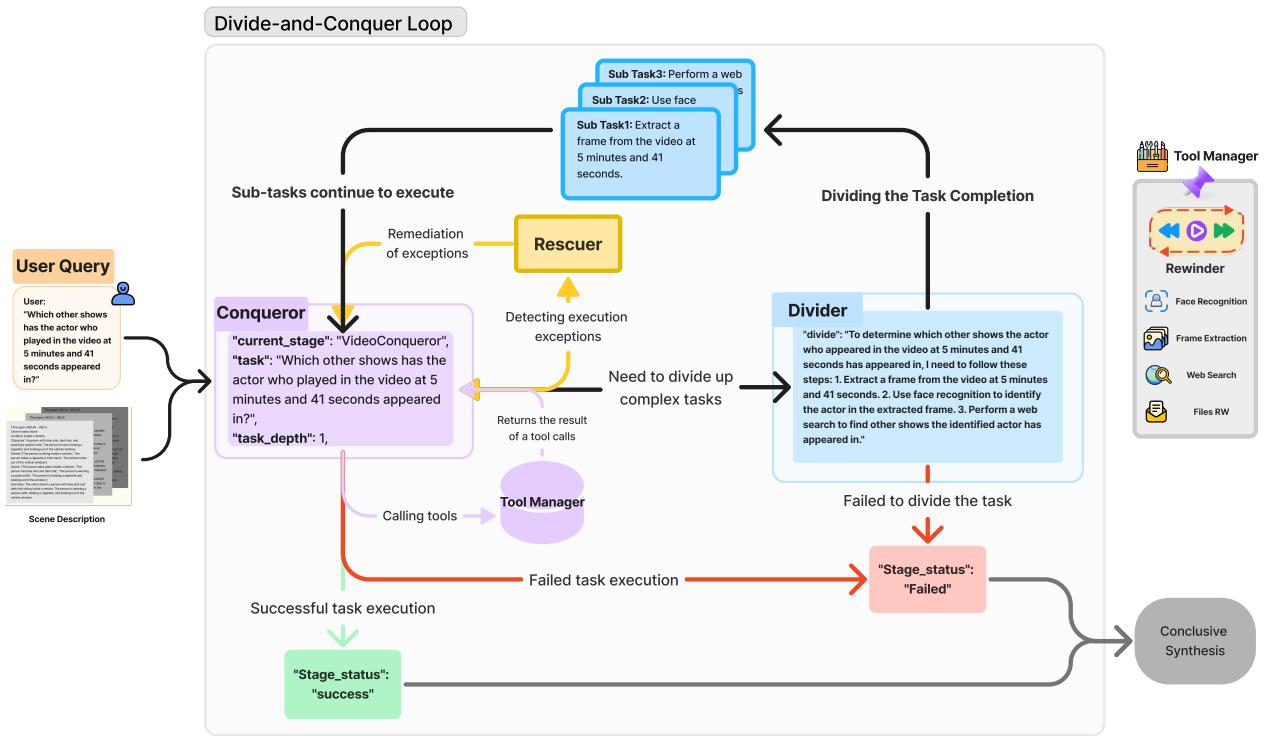
如图 2 所示,工作流是递归的:
- 征服者 (Conqueror) : 这是入口点。它分析任务。
- 如果任务很简单,它会直接解决 (例如,“现在几点了?”) 。
- 如果需要工具 (如网络搜索或视频查找) ,它会调用该工具。
- 如果任务太复杂,它会将其传递给 划分者 。
- 划分者 (Divider) : 该模块将复杂任务分解为逻辑子任务。对于上面的“演员”问题,它会将查询拆分为:
- 子任务 1: 提取 05:41 的帧。
- 子任务 2: 执行人脸识别。
- 子任务 3: 搜索网络以查找该演员的影视作品列表。
- 任务树 (Task Tree) : 这些子任务被组织成树状结构。系统递归地执行它们。
- 救援者 (Rescuer) : 代理经常会失败——也许缺少 Python 库或工具超时。救援者是一个错误处理模块,它尝试修复运行环境或重试任务,确保循环不会崩溃。
“倒带 (Rewinder) ”工具
OmAgent 最独特的功能是 倒带器 (Rewinder) 。
在标准的 RAG 系统中,一旦视频被处理成文本/向量,原始视频通常会被从工作流中丢弃。然而,OmAgent 将人类拖动视频播放进度条的能力抽象为一种工具。
如果代理意识到存储的场景描述过于模糊,无法回答问题 (例如,“角色眨了三次眼吗?”) ,它可以自主决定使用倒带器。它从 Video2RAG 阶段识别的特定时间戳检索原始帧,并以全新的视角重新分析它们。这有效地弥合了高效存储 (文本) 与高保真验证 (视觉) 之间的差距。
案例研究: OmAgent 实战
让我们看看这是如何利用热门电视剧《继承之战》 (Succession) 的数据在实践中发挥作用的。
案例 1: 外部知识整合
问题: “视频中 5 分 41 秒出现的那个演员还出演过哪些其他节目?”
这需要将视觉数据与外部世界知识联系起来。

首先,系统检索相关上下文。Video2RAG 过程已经生成了场景的描述,但具体答案 (演员的其他节目) 并不在视频中。

DnC 循环启动。如下面的代理输出所示,系统分解了任务:
- 提取: 隔离 5:41 的视频片段。
- 识别: 识别演员为 Jeremy Strong。
- 搜索: 使用网络搜索工具查找他的影视作品列表。
- 综合: 将这些发现结合成最终答案。
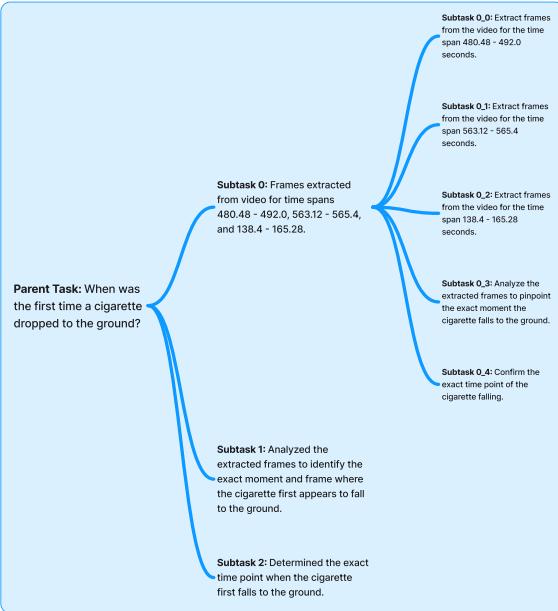
案例 2: “大海捞针”
问题: “香烟第一次掉到地上是在什么时候?”
这是一个视觉敏锐度测试。文本摘要可能会说“他抽了一支烟”,但很少会说“他在 02:32 把烟掉了”。

系统依靠场景描述来缩小搜索范围。

使用 DnC 循环 (回顾代理输出图像中的图 3/4) ,代理意识到仅凭描述无法回答这个问题。它制定了一个检查特定时间间隔的计划。它使用 倒带器 从候选时间戳 (例如 480s - 492s) 中提取帧,并专门分析它们以寻找“掉落”动作。最终它成功定位了 00:02:32 这一事件。
实验结果
研究人员将 OmAgent 与几个强基线进行了评估,包括纯 Video2RAG (无代理循环) 和涉及帧提取配合语音转文本 (STT) 的标准方法。他们创建了一个包含超过 2,000 个问题的新基准数据集,涵盖剧集、电影、纪录片和 Vlog。
不同视频类型的表现
结果表明,OmAgent 始终优于基线。
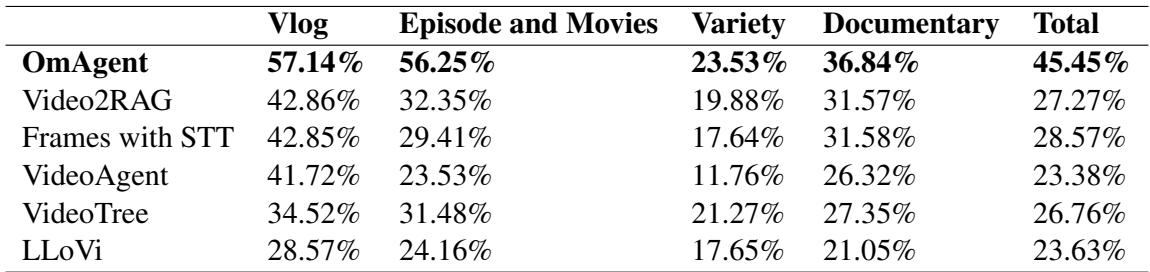
如表 2 所示,OmAgent 的总准确率达到了 45.45% , 明显高于 Video2RAG (27.27%) 和帧配合 STT (28.57%)。这种差距在“剧集和电影”中尤为明显,这可能是因为这些格式需要跟踪随时间变化的复杂情节和角色互动——这正是 DnC 循环擅长的任务。
详细问题分析
研究人员将问题分为四类: 推理、事件定位 (查找时间戳) 、信息总结和外部知识。
表 4、5 和 6 提供了 OmAgent 成功的定性示例。
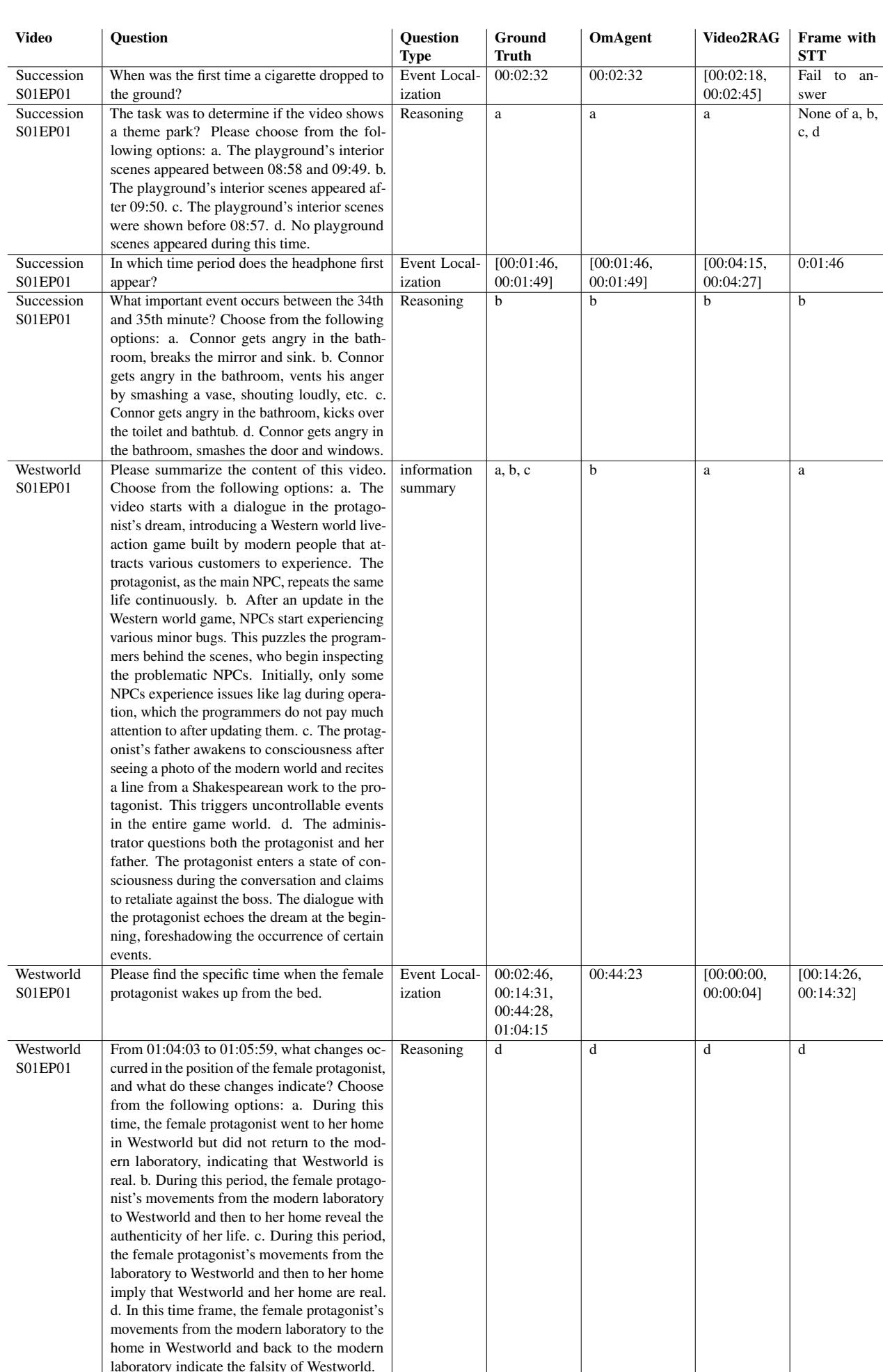
在表 4 (《继承之战》) 中,注意第一个问题: “香烟第一次掉到地上是在什么时候?”
- OmAgent: 00:02:32 (正确)
- Video2RAG: [00:02:18, 00:02:45] (模糊范围)
- Frame with STT: 失败
这种精确度凸显了倒带工具的威力。Video2RAG 系统依赖预生成的摘要,只能给出大致的时间范围。OmAgent 则回到录像中获取精确的秒数。
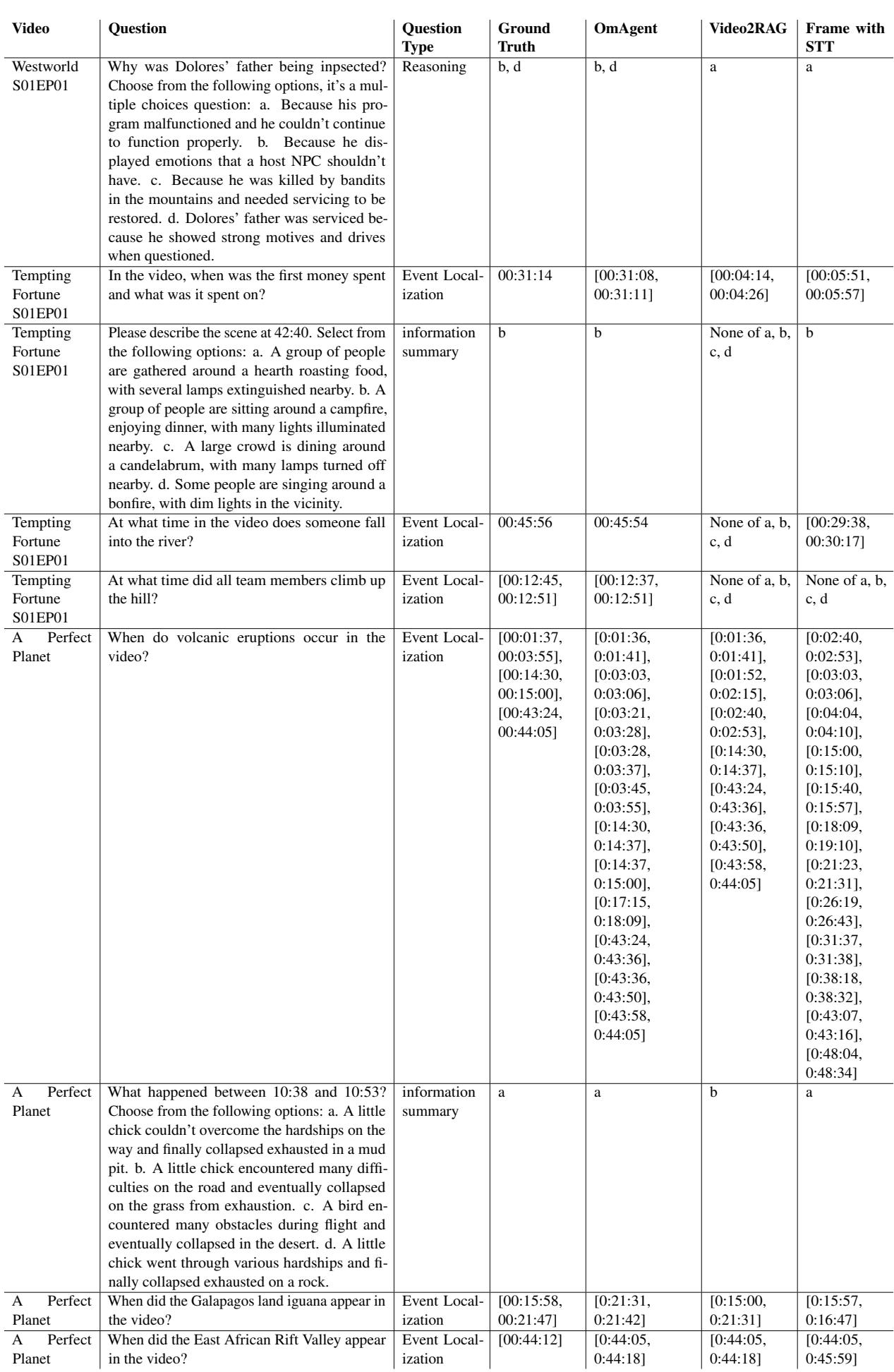
在表 5 (《西部世界》) 中,系统处理了复杂的总结 (问题 1) 和精确的定位 (问题 2) 。对于问题“请找出女主角从床上醒来的具体时间”,OmAgent 识别出了确切的时间戳 (00:44:23) ,而基线模型偏差了数分钟或完全失败。
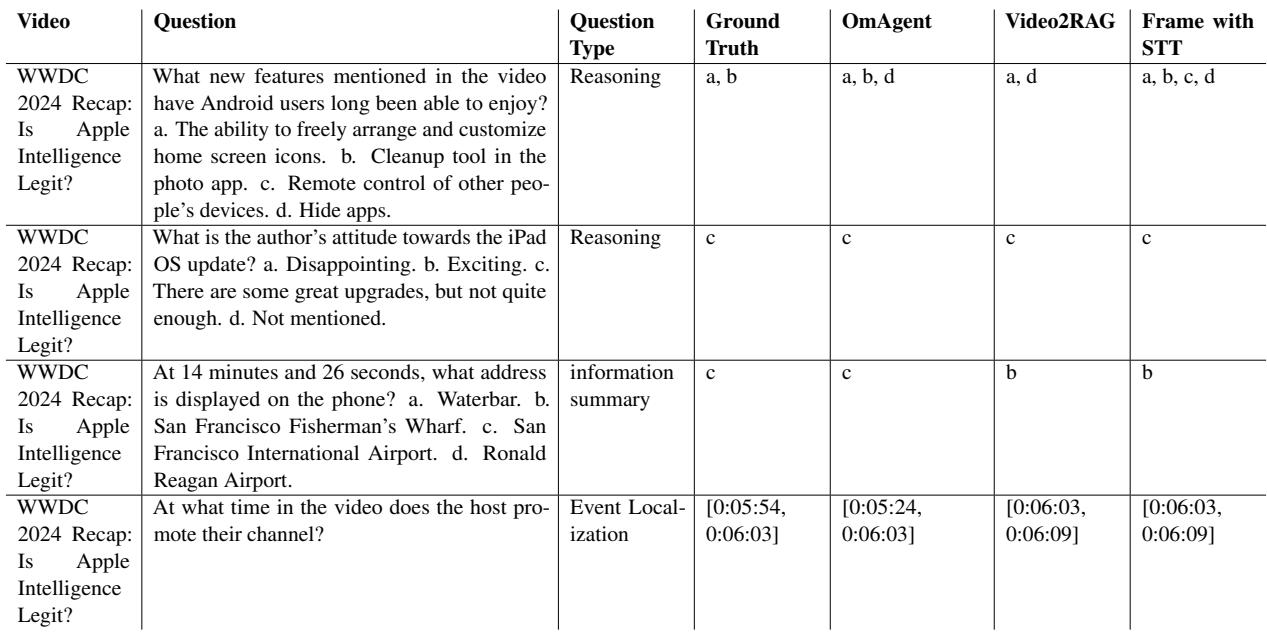
表 6 显示了在“WWDC 2024 回顾”视频上的结果。这测试了代理处理信息性内容的能力。在推理任务 (问题 1) 中,OmAgent 正确识别了视频中提到的多个功能 (a, b) ,而其他模型则产生了额外的幻觉选项或遗漏了细节。
为什么 OmAgent 会赢: “通才”优势
研究人员还在通用问题解决基准上测试了 OmAgent,如 MBPP (Python 编码任务) 和 FreshQA (现实世界问答) 。
OmAgent 搭配 GPT-4 在 MBPP 上达到了 88.3% 的成绩,在 FreshQA 上达到了 79.7% , 超过了单独的 GPT-4 甚至先进的 XAgent 框架。这证明该架构不仅擅长看电影;救援者机制和严谨的分治逻辑使其成为一个强大的通用问题解决者。
结论与未来展望
OmAgent 代表了使 AI 真正实现“多模态”的重要一步。通过承认当前的上下文窗口无法处理全长电影,研究人员构建了一个模拟人类行为的系统: 扫描、总结、规划和倒带。
主要要点是:
- 不要仅依赖摘要: “倒带”工具允许代理根据事实真值验证细节,显著减少幻觉。
- 递归规划有效: 将视频任务分解为子树 (提取 -> 识别 -> 搜索) 比线性思维链提示更能处理复杂性。
- 视觉提示辅助检索: 用算法数据 (如人脸框) 注释图像有助于 MLLM “聚焦”于正确的细节。
虽然该系统仍有局限性——它有时在精确的时间戳精度和视听同步方面会遇到困难——但它为视频分析的未来提供了蓝图。无论是搜索数千小时的安全录像,还是仅仅在看电视时问“那个演员演过什么电影?”,OmAgent 都为 AI 像理解文本一样深刻理解动态影像开辟了道路。