](https://deep-paper.org/en/paper/2406.16694/images/cover.png)
引言
像 GPT-4 和 Llama 这样的大型语言模型 (LLM) 已经彻底改变了我们与技术交互的方式。它们是令人难以置信的通才——能够写诗、调试代码以及总结历史。然而,当你把这些通才放入一个高度专业化的环境中——比如程序化广告、法律咨询或高等数学——它们的表现往往会遇到瓶颈。
为了解决这个问题,研究人员和工程师通常使用一种称为持续预训练 (Continual Pre-Training, CPT) 的过程。理想情况下,你采用一个基础模型,并持续使用特定领域的文档 (即“领域内”数据) 对其进行训练。但在这种标准方法中存在两个显着的问题:
- 数据稀缺: 与通用网络上可用的数万亿 token 相比,高质量的领域特定数据非常稀少。一家广告代理商可能只有几十亿 token 的内部数据,这对于 LLM 来说不过是沧海一粟。
- 缺乏任务感知: 原始文档 (如一堆法律合同或广告点击数据库) 并不是“教科书”。它们包含原始信息,但没有明确教模型 如何 使用这些信息来解决特定问题,比如重写查询或解方程。
在这篇文章中,我们将深入探讨一种名为 TRAIT (面向任务的领域内数据增强) 的新框架。该方法提出了一个巧妙的解决方案: 我们不仅可以向模型灌输原始文本,还可以从网络上筛选大量相关数据,并生成合成的“教科书”来教模型如何思考。
背景: 为什么标准适配会失败
在理解 TRAIT 之前,我们需要看看为什么当前的方法会举步维艰。
当一个 LLM 进行预训练时,它会消耗整个互联网的数据。它学习语法、事实和推理模式。当我们想要让它专业化时,我们会给它喂食领域数据。然而,之前的研究表明,仅仅让模型“接触”新词汇是不够的。
如果你正在为广告领域训练一个模型,你可能会给它一个广告文案和着陆页的数据集。但模型不一定知道 为什么 某个广告文案与某个搜索查询相匹配。它只是看到了这种相关性。
此外,由于领域数据非常稀缺,模型经常会发生“灾难性遗忘”——它们对少量新数据过拟合,从而失去了通用的推理能力。TRAIT 框架通过将数据不仅视为“待阅读的文本”,而是视为“待学习的课程”来解决这些问题。
核心方法: TRAIT
TRAIT 框架由两个独特但互补的策略组成: 领域内数据选择 (解决稀缺性问题) 和面向任务的合成篇章生成 (解决任务感知问题) 。
第一部分: 领域内数据选择
由于特定领域的数据很少,作者转向了最大的可用来源: 通用网络。其假设是,在海量数据集 (如 Common Crawl) 中,存在着与目标领域高度相关的文本片段,即使它们没有被标记为该领域。
为了挖掘这些数据,研究人员使用了 FastText 分类器 。 过程如下:
- 选取一小部分已知的领域内数据 (例如广告) 。
- 选取一组通用的非领域内数据。
- 训练一个轻量级分类器来区分这两者。
- 在海量的通用网络语料库 (包含数万亿 token) 上运行此分类器。
这个过程识别出了数十亿个“看起来像”目标领域的 token。但数量并不是一切。为了确保质量,研究人员应用了一个“教育价值”过滤器——本质上是一个确保所选文本具有信息量且结构良好的指标,而不仅仅是噪音。
结果如何? 对于广告领域,他们最初只有 10 亿 token 的内部数据,通过这种方法,他们从网络上额外筛选出了 150 亿 token 的高质量相关数据。这种大规模的知识注入解决了数据稀缺问题。
第二部分: 面向任务的合成篇章生成
这才是 TRAIT 真正的创新之处。拥有原始数据固然好,但拥有解释 如何解决问题 的数据更好。研究人员开发了一个流程来生成看起来像结构化推理练习的合成训练样本。
TRAIT 不再是在简单的输入-输出对上训练模型,而是生成包含以下内容的复杂“篇章”:
- 多个问题: 来自不同下游任务的问题 (例如,一个关于查询重写,一个关于相关性) 。
- 特定问题段落: 对如何解决每个具体问题的详细分解。
- 启示段落 (The Enlightenment Paragraph) : 一个总结,将不同问题之间的点连接起来。
通过示例理解
让我们看看这如何应用于两个截然不同的领域: 广告 (“以实体为中心”的领域) 和数学 (“以知识为中心”的领域) 。
广告领域 (以实体为中心)
在广告或金融等领域,重点通常是从多个角度理解特定的实体 (如产品或公司) 。
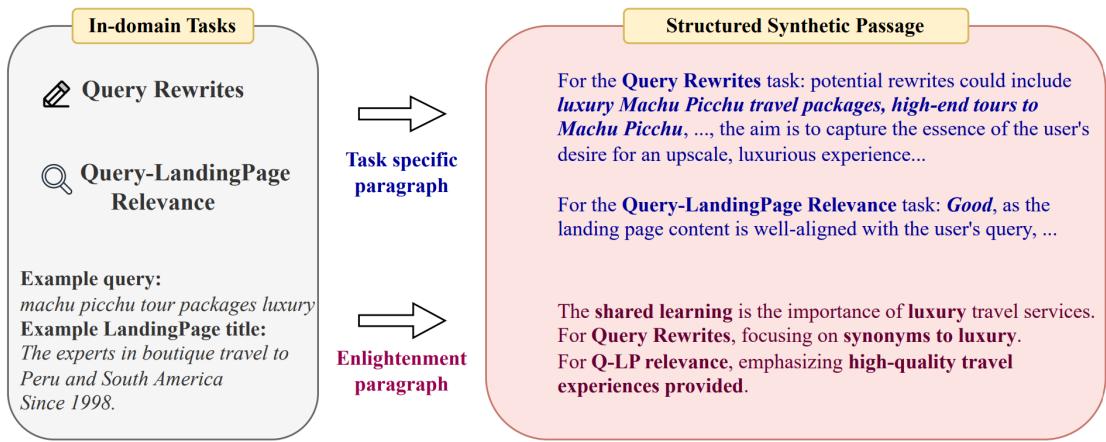
如图 1 所示,系统获取一个用户查询 (“马丘比丘豪华旅游套餐”) 。然后,它生成一个同时处理两个不同任务的训练篇章:
- 查询重写: 它解释了如何改写查询 (例如,“高端旅游”) 。
- 相关性: 它解释了为什么特定的着陆页是一个很好的匹配。
至关重要的是,请看图的右下角: 启示段落 。 它综合了这些信息。它告诉模型 为什么 这些答案是正确的: “共同的学习点是旅游服务中豪华和个性化方面的重要性。”
这明确地教导模型识别核心意图 (豪华 + 旅游) ,而不仅仅是死记硬背关键词。
数学领域 (以知识为中心)
在数学中,“实体” (具体的数字) 不如“知识” (公式或逻辑) 重要。
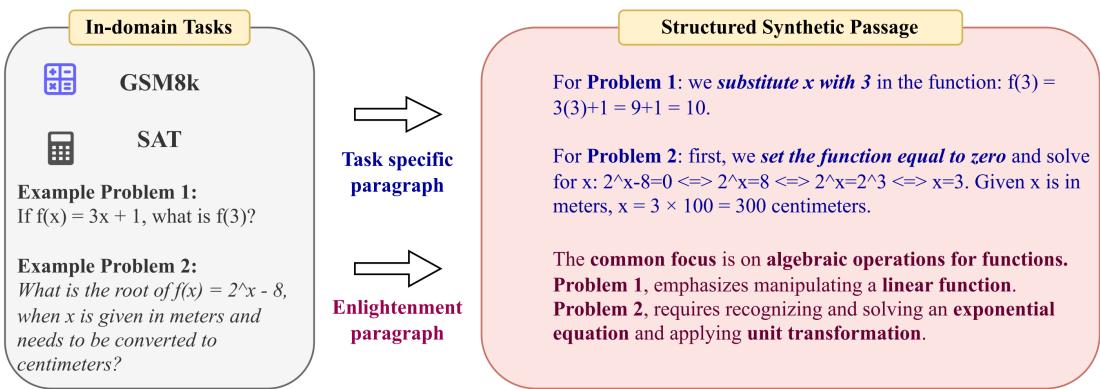
在图 2 中,我们看到两个完全不同的数学问题。一个是关于函数的 (来自 GSM8k 数据集) ,一个是关于单位换算的 (来自 SAT 数据集) 。
生成的篇章解决了这两个问题,但启示段落起到了关键作用。它指出这两个问题都需要“函数的代数运算”。它教导模型,尽管表面上存在差异,但底层的数学推理是可迁移的。
两阶段训练策略
作者发现,一次性将所有这些数据扔给模型并不是最优解。他们设计了一个两阶段的训练策略:
- 第一阶段 (知识获取) : 模型在 领域内数据 (原始数据 + 从网络中筛选的大量数据) 上进行训练。这建立了一个坚实的领域知识基础。
- 第二阶段 (任务对齐) : 模型在 合成的面向任务篇章 上进行训练。这教导模型如何将刚刚学到的知识应用到实际问题中。
实验与结果
为了证明这个框架的有效性,研究人员将其应用于 Mistral-7B 模型。他们将 TRAIT 与标准基线进行了比较,包括随机采样 (随机选取网络数据) 和 DSIR (一种流行的重要性采样方法) 。
可视化数据差距
为什么这种数据选择是必要的?下面的可视化有助于解释数据的分布。
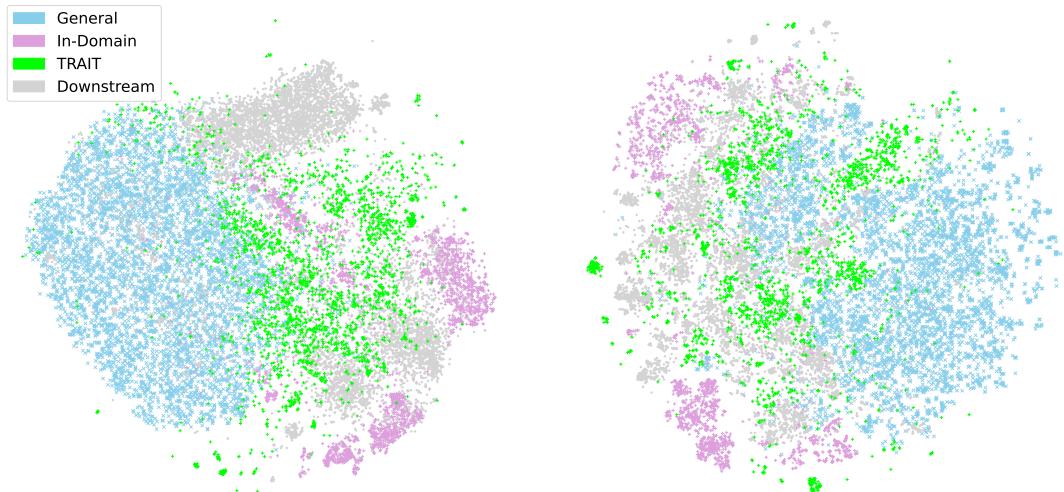
在图 3 (散点图) 中,你可以看到这种脱节。“通用”数据 (浅蓝色) 巨大但分散。“领域内”数据 (紫色) 是一个微小的簇。“下游”任务 (灰色) 是原始领域内数据无法完全覆盖的簇。
然而, TRAIT 数据 (绿色) 成功地弥合了这一差距,覆盖了下游任务所在的区域。这一视觉确认证明了数据选择和生成策略有效地针对了正确的信息空间。
广告任务上的表现
在广告领域的改进是显著的。研究人员在 7 个不同的任务上评估了模型,范围从生成广告标题到确定相关性。
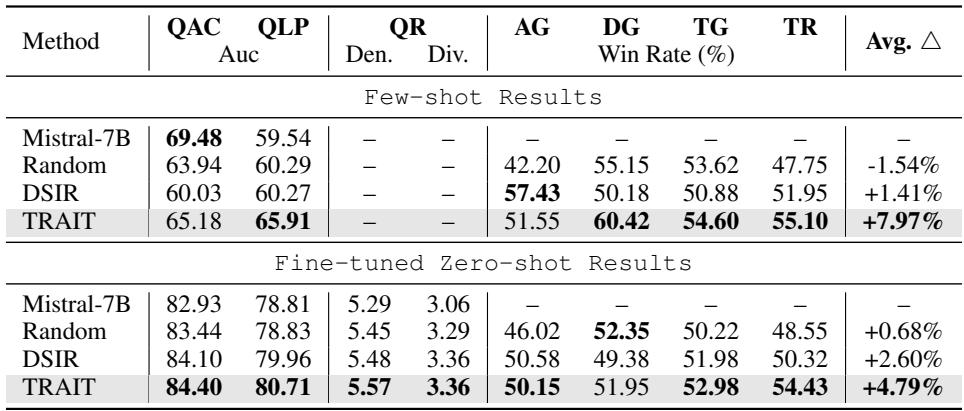
如表 1 所示,TRAIT 优于所有基线。
- 平均提升: 比基础 Mistral 模型高出 8%,比最佳基线 (DSIR) 高出 2.2%。
- 一致性: 它在几乎所有类别中都获胜,从查询-广告相关性 (QAC) 到标题生成 (TG) 。
数学任务上的表现
数学领域的结果甚至更加惊人。众所周知,如果没有大规模的监督微调,LLM 很难提高数学推理能力。
TRAIT 在 9 个不同的数学基准测试中实现了 7.5% 的平均准确率提升 。 在极具挑战性的 MATH 基准测试中,它将性能提高了超过 15% 。 这表明“启示段落”在逻辑密集的领域特别有效,在这些领域,抽象出底层技术是解决新问题的关键。
为什么它有效? (消融实验)
是数据选择的作用?还是合成数据的作用?参考表 4 (包含在上方图 3 的图片中) ,我们可以看到分解:
- 基础 Mistral: 良好的基线。
- + 原始数据: 小幅提升 (+1%) 。
- + 筛选数据: 更大的提升。
- + 合成数据 (TRAIT) : 最大的跳跃 (~5%) 。
这证实了虽然更多的数据有帮助,但合成数据的结构——特别是面向任务的指导——是性能提升的主要驱动力。
训练中的“顿悟”时刻
最有趣的发现之一是模型如何随着时间推移进行学习。
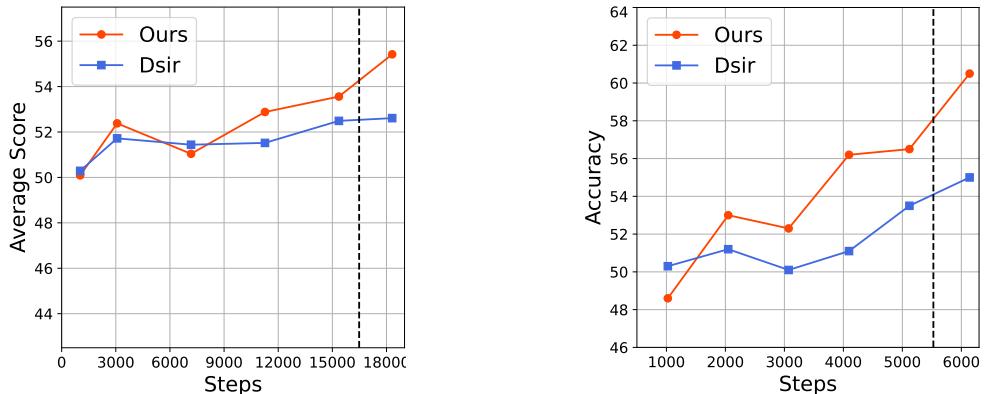
图 4 显示了训练曲线。请看“Ours” (TRAIT) 的曲线。
- 在第一阶段 (图表的左侧) ,性能波动或缓慢上升。这是知识获取阶段。模型正在阅读“教科书”。
- 突然,出现了一个急剧的峰值 (图表的右侧) 。这对应于第二阶段 , 即引入合成的面向任务篇章的时候。
这反映了人类的学习过程: 你可能读了一本书并理解了概念,但一旦你开始做练习题,你解决考试问题的能力就会突飞猛进。
结论
TRAIT 论文为专业化 LLM 的未来描绘了一幅引人注目的路线图。它强调,在处理特定领域时,数据“越大越好”的方法是不够的。我们需要面向任务的数据。
通过智能地从开放网络中选择数据来补充稀缺性,并使用 LLM 编写它们自己的“操作手册” (带有启示段落的合成篇章) ,我们可以创建不仅知识渊博,而且能力超群的模型。
对于学生和研究人员来说,关键的收获是训练数据中结构的重要性 。 “启示段落”的概念——明确教导模型寻找不同问题之间的联系——是一种强大的技术,它推动模型从死记硬背走向真正的推理。随着我们迈向法律、医学和工程领域更专业的 AI 智能体,像 TRAIT 这样的框架将在弥合通用能力与专家表现之间的差距方面发挥至关重要的作用。