](https://deep-paper.org/en/paper/2406.17969/images/cover.png)
像 GPT‑4 和 Llama 3 这样的大语言模型 (LLMs) 正在改变我们的世界,但一个根本的谜团仍然存在: 它们究竟是如何思考的? 我们知道它们由数十亿个人工神经元组成,但当我们窥探这个数字大脑的内部时,往往只看到一团乱麻。许多神经元是多义性的 (polysemantic) ,也就是说,一个神经元可能会同时响应一系列奇怪且无关的概念——比如红色、棒球运动和悲伤的情绪。
这种复杂性使得理解、预测或信任这些模型变得极其困难。为了解决这一问题,一个名为机制可解释性 (mechanistic interpretability) 的新兴领域试图对大语言模型进行逆向工程。它的终极目标之一是实现单义性 (monosemanticity) ——即每个神经元都对应于一个特定的、可被人类理解的概念: 一个代表“金门大桥”的神经元、一个代表“过去时”的神经元、一个代表“讽刺”的神经元。如果能做到这一点,我们或许就能开始描绘这些系统的内部逻辑。
但这引出了一个重要的问题: 单义性真的对模型性能有益吗?一些研究者认为,强制神经元过度专门化可能反而破坏模型的泛化能力,他们主张多义性那种混乱、重叠的结构或许是实现效率的一种“必要之恶”。
一篇新论文—— 《鼓励还是抑制单义性?从特征去相关的视角重新审视单义性》 (“Encourage or Inhibit Monosemanticity? Revisit Monosemanticity from a Feature Decorrelation Perspective”) ——挑战了这一观点。作者提出,单义性不仅有益,而且是模型与人类偏好对齐的自然结果。他们进一步通过特征去相关 (feature decorrelation) 提出了一种衡量并促进单义性的新方法,为实现更具可解释性且功能更强的模型开辟了道路。
让我们来看看他们的发现。
什么是单义性?为何它如此难以发现?
在深入探讨之前,我们先澄清几个概念:
- 概念 (Concept) : 人类可理解的可解释想法 (例如“爱”、“计算机编程”、“猫”) 。
- 神经元 (Neuron) : 神经网络中的单个计算单元。
- 特征 / 激活 (Feature / Activation) : 神经元或层在处理输入时产生的内部表示。
问题的核心在于神经元与概念之间的关系并不简单。一个多义性神经元 (polysemantic neuron) 会同时响应多个不相关的想法,而一个单义性神经元 (monosemantic neuron) 则与单一概念形成一对一映射。
为了寻找这类稀有且可解释的神经元,研究者通常使用一种称为稀疏自编码器 (Sparse Autoencoder, SAE) 的方法。你可以将它想象成观察神经网络大脑的显微镜: 它将大语言模型内部复杂的激活向量压缩为一个只有少数非零项的稀疏形式,然后再从这一稀疏编码重构原始的激活。
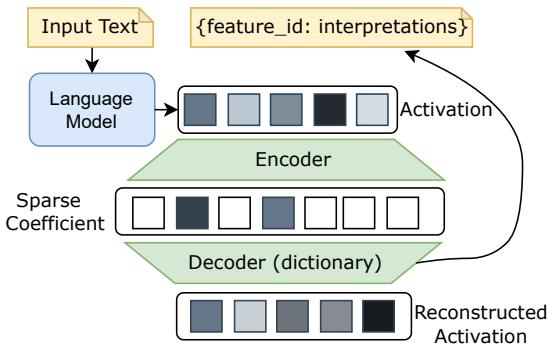
图 1: 稀疏自编码器架构,用稀疏且可解释的特征重构模型激活,用于识别单义性神经元。
理想情况下,稀疏编码中的每个活跃特征都对应一个单一、纯粹的概念。研究者通过分析哪些输入会使某个特征激活,从而手动进行标注 (例如“该特征在处理与法律相关的文本时激活”) 。这是一种强大的方法,但在计算上非常昂贵且耗费人力,因此难以在数百万个神经元规模上推广。这一瓶颈留下了关键问题: 我们应该鼓励还是抑制单义性?
故事的转折: 单义性会损害性能吗?
早期研究认为,抑制单义性——即促进多义性神经元——可能提高模型容量。该结论来自对不同规模的 Pythia 系列模型中“单义性代理指标”的分析,结果显示较大的模型似乎具有更低的单义性分数。由此推断,多义性可能是模型规模化的一种高效权衡。
新论文通过将同一代理指标应用于 GPT‑2 模型系列重新检验了这一结论。结果却讲述了不同的故事。
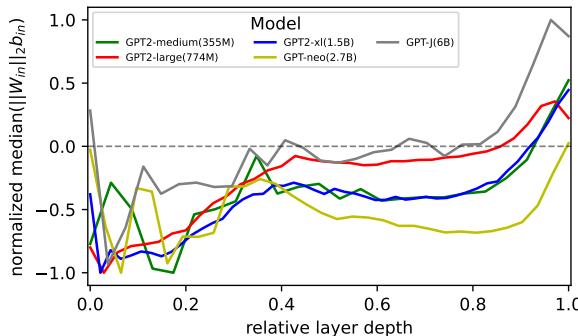
图 2: GPT‑2 不同变体的单义性代理指标。缺乏明确趋势表明模型大小与单义性之间并无一致关系。
如上图所示,拥有 15 亿参数的 GPT‑2 XL 模型表现出较强的单义性,而拥有 27 亿参数的 GPT‑Neo 模型则较弱。没有一致规律,这意味着跨模型比较不可靠——不同架构和训练过程交织影响了结果。那么,我们是否可以改从单个模型内部观察单义性随学习的变化?
新视角: 将单义性视作特征去相关
为了“从内部”探索单义性,作者引入了叠加理论 (superposition theory) 的概念。当模型编码的特征数量多于神经元数量时,就会出现叠加: 每个神经元表示多个重叠的特征。这种重叠——即共享激活或特征间的相关性——正是多义性的核心。
相反, 去相关特征 (decorrelated features) 是独立且正交的信号。在一个完全单义的系统中,神经元各自独立地表示唯一特征。
由此得到一个实际可行的代理指标: 内部激活之间的相关性 。 低相关性 → 高单义性;高相关性 → 多义性。
数学上,如果两个神经元权重向量 \( \mathbf{W}_i \) 和 \( \mathbf{W}_j \) 正交,则最小化它们的点积
\[ \sum_{j \neq i} (\mathbf{W}_i \cdot \mathbf{W}_j)^2 \]会导致激活去相关。在线性假设和输入归一化的条件下,有:
\[ \mathbf{Z}^{\top}\mathbf{Z} = \mathbf{X}^{\top}\mathbf{W}^{\top}\mathbf{W}\mathbf{X} \approx \mathbf{D} \]其中 \( \mathbf{D} \) 是对角矩阵——代表完全去相关 (单义) 的特征。因此,激活相关矩阵 \( \mathbf{Z}^{\top}\mathbf{Z} \) 越接近单位对角矩阵,单义性越高。
对齐与单义性的惊人联系
借助这一代理指标,作者研究了单义性在偏好对齐 (preference alignment) 中的变化。偏好对齐是一种微调过程,使模型倾向于人类偏好的输出。他们重点研究了直接偏好优化 (Direct Preference Optimization, DPO) , 该方法以成对响应 (一个偏好,一个拒绝) 训练模型,从而调整内部奖励函数。
将 DPO 应用于多个 GPT‑2 变体后,作者发现 DPO 持续提升单义性,尤其在早期层中更明显。
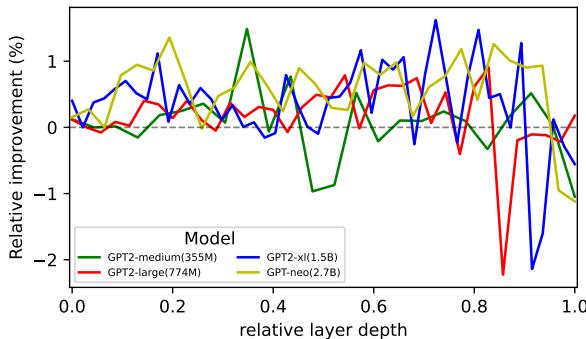
图 3: DPO 训练后单义性代理指标的相对变化。DPO 在 GPT‑2 模型中提升单义性,尤其在早期层。
进一步验证时,他们用 DPO 训练了 Llama 2 , 并测量其内部的特征去相关性 。 结果非常显著。
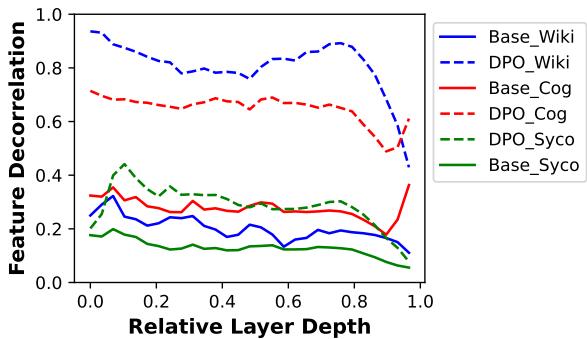
图 4: Llama 2 中的特征去相关性。DPO 在多个数据集上显著增强去相关性——表明单义性得到提升。
这证明了一个重要结论: 对齐训练会自然促使模型向单义性发展。换言之,模型不仅变得更符合人类偏好,同时也形成了更清晰、更可解释的内部表示。
DecPO: 让模型更智能、更可解释的简单正则化器
既然 DPO 已能促进单义性,为什么不进一步强化这一效应?作者提出了一个变体——去相关策略优化 (Decorrelated Policy Optimization, DecPO) , 在 DPO 目标函数中新增一个小的正则化项,用于直接惩罚相关激活:
\[ \mathcal{L}_{\text{dec}} = ||\mathbf{z}\mathbf{z}^{\top} - \mathbf{I}||_F^2 \]该项鼓励特征多样且非冗余。虽然简单,却极具成效。
结果: 更高的去相关性、稀疏性与可解释性
DecPO 快速提升了特征去相关性,超过 DPO,并在长时间训练中减少了过拟合。
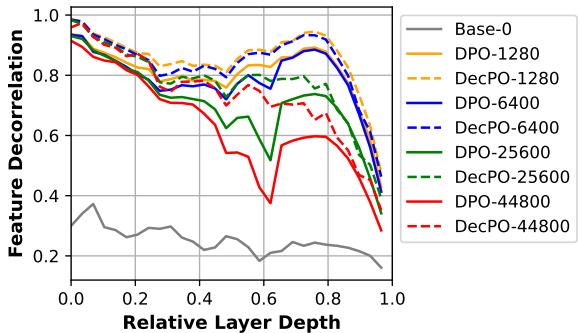
图 5: 微调过程中的特征去相关性。DecPO 保持更高的去相关性,并显著缓解训练后期过拟合。
接着,他们测量了激活稀疏性 (activation sparsity) ,即神经元激活方差。稀疏模式代表单义性: 每个概念仅激活少数特定神经元。
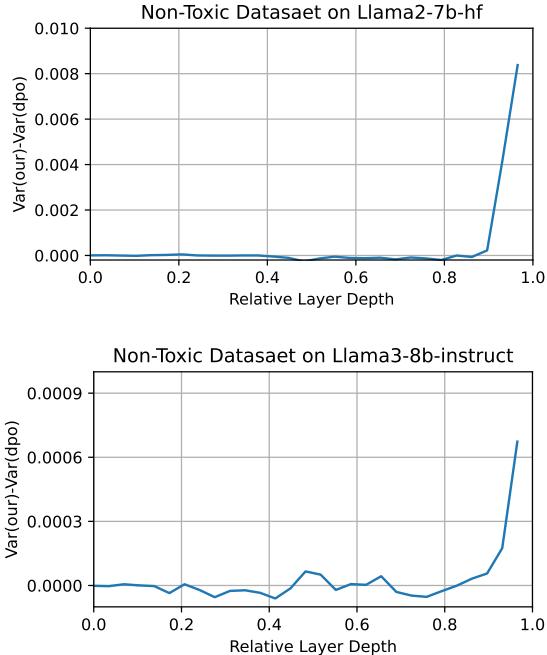
图 6: DecPO 与 DPO 激活方差差异。更高方差反映更大稀疏性,进而表示更高单义性。
最后,他们通过将主要 MLP 维度映射回词汇表的词元,验证这种稀疏性是否带来更可解释的神经元。
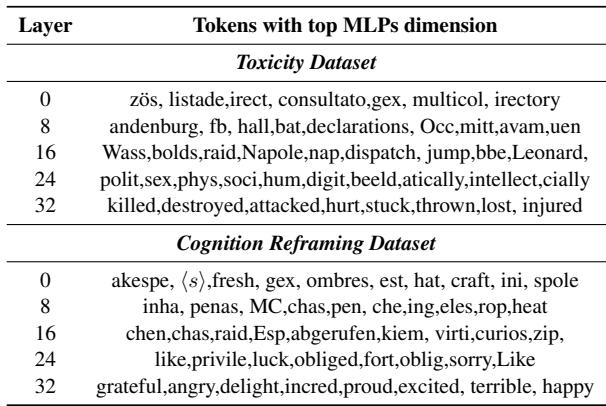
表 1: 不同模型深度下与主要 MLP 维度相关的代表性词元。更深层对应更清晰、任务相关的概念,如 暴力 (毒性) 和 情感 (认知重构) 。
早期层输出的词元杂乱无意义,而深层则形成了明显语义簇——毒性任务中聚焦暴力与失落,认知重构任务中聚焦情绪。模型确实“雕刻”出了代表人类可理解特征的神经元。
回报: 更高的对齐性能
鼓励单义性不仅在理论上优雅,而且在实践中带来性能提升。与 监督微调 (SFT) 、DPO 和 SimDPO 等基线相比,DecPO 在三项对齐任务中均表现最佳: 毒性降低、认知重构、谄媚抑制。
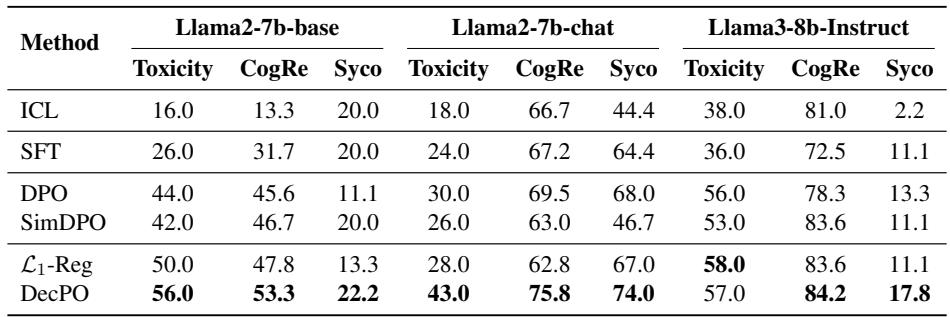
表 2: 偏好对齐结果。DecPO 相较标准 DPO 在各数据集上实现一致性提升——最高达 13 %。
DecPO 防止了“捷径学习” (shortcut learning) ,即模型仅记住表面模式以赢得偏好比较。通过强制特征的多样性和正交性,它防止奖励操纵 (reward‑hacking) ,使神经元真正对应语义差异。
这一点反映在奖励差距 (reward margin) 上——模型对优劣响应的评分差值。
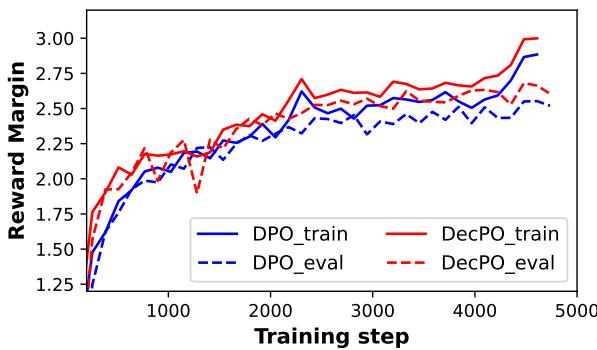
图 7: 训练过程中的奖励差距。DecPO 保持更大差距,展现对偏好与非偏好响应更自信的区分。
更宽的奖励差距意味着模型在可接受与不可接受输出之间形成更清晰边界——这正是对齐训练追求的目标。
结论: 可解释性与能力的双赢
这项研究以全新视角重新定义了机制可解释性。它挑战了“多义性不可避免甚至有利”的观点,并提供了有力证据表明单义性更为理想——而且对齐过程自然推动其提升。
通过特征去相关的视角,研究者不仅提出了理论联系,还提供了实践方法 DecPO,以促进可解释神经元的形成。DecPO 让模型既更易理解,又更好地与人类价值观保持一致。
这一发现意义深远: 可解释性与模型能力并非此消彼长,而是相辅相成。当我们帮助模型以人类可理解的方式组织其内在知识时,也在帮助它变得更稳健、更公平、更高效。
完全解码大语言模型黑箱的旅程仍漫长,但这项工作是充满希望的一步。鼓励单义性不仅帮助我们理解模型,也可能让模型更好地理解我们。