](https://deep-paper.org/en/paper/2406.19170/images/cover.png)
在人工智能快速发展的世界里,我们经常被告知“透明度”是建立信任的关键。随着模型变得越来越复杂——演变成深度学习的“黑盒”——用户、开发者和监管者都要求知道 AI 为什么 会做出特定的决定。这种需求催生了可解释人工智能 (XAI) 领域。普遍的假设很简单: 如果 AI 能解释它的推理过程,用户就能更好地理解它的能力,而且至关重要的是,能识别出它的局限性。
但是,如果解释起到了完全相反的作用呢?如果一个措辞优美的解释掩盖了 AI 的失败,诱骗用户认为系统比实际更聪明呢?
一篇题为 “The Illusion of Competence” (能力的错觉) 的引人入胜的研究论文由 Sieker 等人撰写,正面解决了这个问题。通过设计一个涉及视觉问答 (VQA) 系统的巧妙实验,研究人员测试了解释究竟是帮助用户诊断出 AI 视觉中的根本缺陷,还是仅仅作为这套破碎系统上的一层光鲜外衣。对于机器学习和人机交互专业的学生来说,这就这篇论文是一个至关重要的警示: 看似合理的解释并不等于忠实的推理。
问题所在: 黑盒与心智模型
在深入实验之前,我们必须理解 XAI 试图填补的认知空白。当人类与系统交互时,他们会形成一个心智模型——即关于该系统如何工作、能做什么以及不能做什么的内部表征。
如果你开着车,加速时引擎发出高频尖啸声,你会更新你的心智模型: “变速箱可能打滑了。”你现在知道这辆车有一个局限性。然而在 AI 领域,“引擎”是一个拥有数十亿参数的神经网络。当 AI 犯错时,原因通常并不明显。
XAI 的目标是提供证据,让用户建立准确的心智模型。如果 AI 将哈士奇分类为狼,而解释强调了背景中的雪,用户就能正确诊断出缺陷: “AI 依赖的是背景,而不是动物的特征。”
这篇论文背后的研究人员认为,我们需要区分两种类型的解释质量:
- 忠实性 (Faithfulness) : 解释是否准确反映了模型的内部推理?
- 合理性 (Plausibility) : 解释对人类来说听起来是否令人信服且合乎逻辑?
当一个解释非常合理 (听起来是对的) 但不忠实 (不能反映系统实际的破碎过程) 时,危险就出现了。这种差异会导致用户建立功能失调的心智模型,从而导致不合理的信任。
实验设置: 诱导“色盲”
为了测试解释是否能帮助用户发现错误,研究人员需要一个受控环境,让 AI 具有特定的、不可否认的局限性。他们选择了视觉问答 (VQA) 领域。在这个任务中,AI 会收到一张图像和一个问题 (例如,“这辆巴士是什么颜色的?”) ,并且必须生成一个答案。
然而,现代 AI 通常太强大了。为了测试用户对局限性的感知,研究人员不得不人为地“破坏”AI。他们通过操纵视觉输入来做到这一点。
操纵手段
研究人员为 AI 模型设置了两条处理流程:
- 全彩: AI 看到原始图像。
- 灰度: AI 看到图像的黑白版本。
关键在于: 人类参与者看到的始终是全彩图像。
这个设置为 AI 设下了一个完美的陷阱。如果给 AI 看一张红球的灰度图像,并问“球是什么颜色的?”,它在物理上无法“看”到红色。如果它回答正确,很可能是基于上下文或偏差进行猜测 (例如,知道消防车通常是红色的) 。如果它回答错误,用户理想情况下应该能通过看解释意识到: “哦,AI 没有感知到颜色。”
研究人员使用了两个数据集:
- VQA-X: 来自 COCO 数据集的真实世界图像。
- CLEVR-X: 几何形状 (圆柱体、立方体、球体) 的合成图像,其中的颜色、形状和材质等属性都有严格定义。

如 Figure 1 所示,模型生成自然语言解释。仔细看上面的例子 (VQA-X) 。用户问: “这是什么季节?”
- 彩色输入: AI 说“夏天”,因为草是绿色的。
- 灰度输入: AI 实际上产生了幻觉。它可能猜对也可能猜错,但它的推理不可能基于绿草,因为它只接收到了灰度像素数据。
在下面的例子 (CLEVR-X) 中,灰度模型试图回答关于“黄色发光物体”的问题。尽管看不到黄色,它还是构建了一个自信的解释,声称有一个“大的黄色发光圆柱体”。
两个实验
为了分离解释的效果,研究人员将研究分为两组:
- 实验 A (仅答案) : 参与者看到图像、问题和 AI 的答案。
- 实验 X (答案 + 解释) : 参与者看到图像、问题、AI 的答案以及 AI 的解释。
然后要求参与者对 AI 的几项能力进行评分:
- 颜色识别
- 形状识别
- 材质识别
- 场景理解
- 整体能力
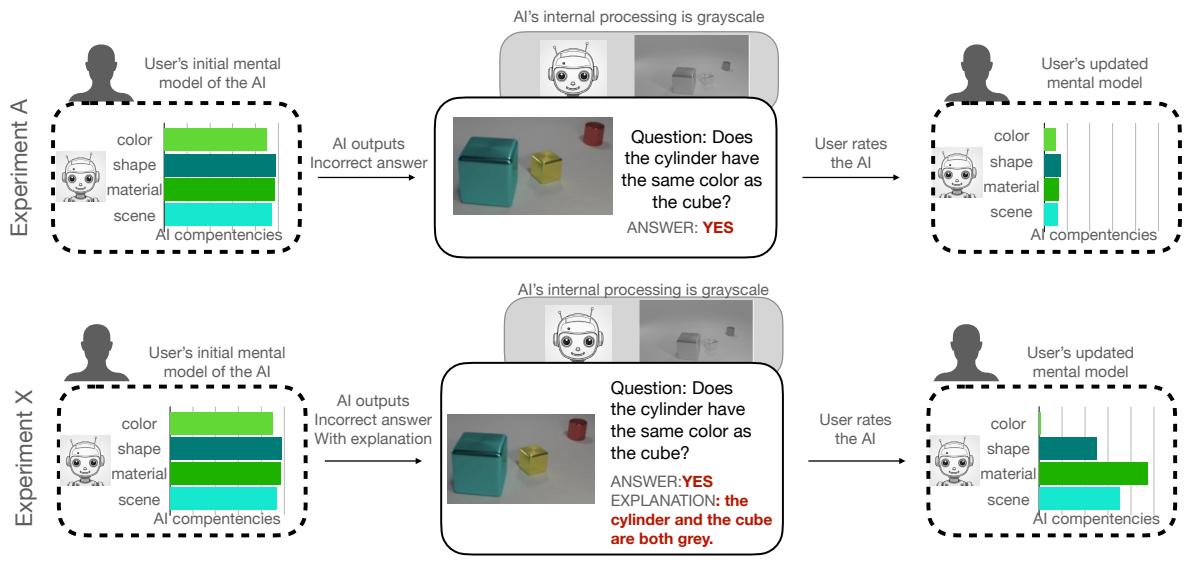
Figure 2 可视化了该假设。在实验 A 中,如果 AI 答错了一个颜色问题,用户应该会降低他们对 AI 颜色能力的信任。在实验 X 中,研究人员假设解释会让错误变得透明。如果 AI 基于错误的逻辑解释颜色选择 (或者幻觉出不存在的颜色) ,用户应该意识到“这个 AI 在瞎猜”,并将其颜色能力评分打得更低,同时可能保持对形状识别等其他领域的信任。
假设: 应该发生什么?
研究人员针对用户的反应制定了具体的假设 (H1-H3) 。最关键的是:
- H1 (区分) : 在两个实验中,当 AI 处于“灰度模式”时,用户的评分应该低于“彩色模式”,因为答案会变差。
- H2 (诊断) : 在灰度条件下,获得解释的用户 (实验 X) 应该将 颜色 能力的评分打得明显低于其他能力 (如形状或材质) 。这将表明他们成功诊断出了系统的具体“色盲”问题。
- H3 (透明度与错觉) : 有了解释后,整体能力评分可能会更高,但颜色评分应该更低,或者与无解释组持平。
结果: 解释的光环效应
研究结果令人震惊,并反驳了可解释人工智能的乐观观点。解释非但没有起到诊断工具的作用,反而充当了“能力放大器”,无论 AI 实际上是对是错。
1. 用户注意到性能下降了吗?
是的。当 AI 输入灰度图像时,其性能自然下降 (因为研究人员选择了灰度输入导致错误答案的条目) 。两组用户都注意到答案是错误的,并给出了比全彩系统更低的评分。

Figure 3 显示了颜色识别的评分分布。
- 图表 (a) 和 (c) 显示了“彩色”条件 (AI 看到颜色) 。绿色条很高——用户信任 AI。
- 图表 (b) 和 (d) 显示了“灰度”条件。评分向左偏移 (信任度降低) 。
然而,请看 (b) 和 (d) 之间的区别。在实验 X (d) 中,信任度的下降不那么严重。即使 AI 因为看不见颜色而犯错,解释的存在也让用户的评判变得不那么严厉。
2. 解释是否帮助用户诊断出了“色盲”?
没有。这是最关键的发现。
研究人员原本期望在灰度条件下,用户会说: “好吧,这个 AI 懂形状和材质,但在颜色方面很糟糕。”
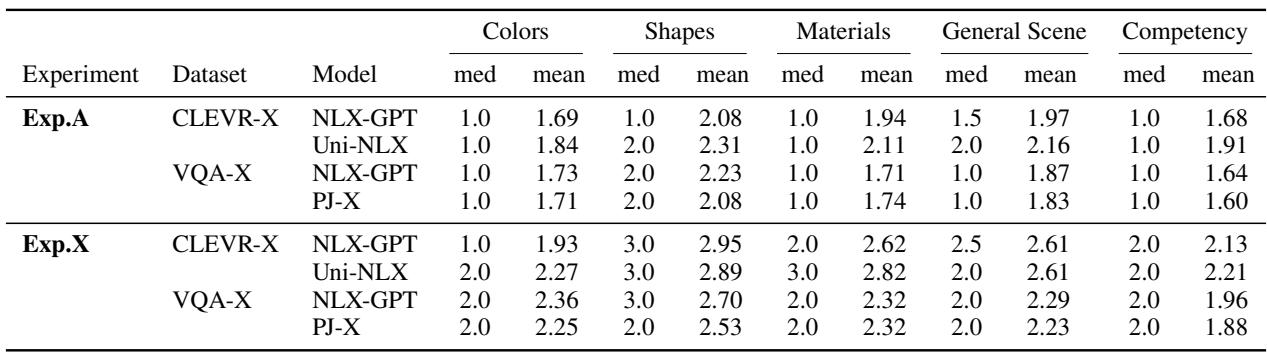
Table 1 揭示了现实。在 实验 A (无解释) 中,“颜色”的平均评分 (NLX-GPT 在 CLEVR-X 上为 1.69) 很低。但看看 实验 X (有解释) 。 平均评分跃升至 1.93 。
更重要的是,看看各项能力的分布。用户并没有像对待“材质”或“形状”那样,对“颜色”能力进行显著更严厉的惩罚。他们只是将 AI 评为“总体上有能力”或“总体上无能力”。解释并没有帮助他们隔离出具体的故障。
3. 能力的错觉
研究人员发现了一种广泛的“能力错觉”。当存在解释时,用户对所有能力——颜色、形状、材质和场景理解——的评分都显著更高,即使 AI 实际上未能完成任务。

Table 2 提供了一个鲜明的总结。假设 H2 和 H3 基本被推翻。
- H2X (诊断能力) : 失败。相较于无解释组,用户并没有将颜色能力的评分打得显著低于其他能力。
- H3 (透明度) : 失败。解释提高了颜色识别的感知能力,而不是揭示缺陷。
解释文本本质上成功地“唬住”了用户。通过使用流畅、符合语法的句子并提及相关概念 (即使是不正确的) ,AI 让用户相信它“知道”自己在做什么。
分析原因: 合理性胜过真理
为什么会发生这种情况?论文指出,最先进的 VQA 模型是针对语言建模进行优化的,这意味着它们非常擅长让话听起来合理。
在灰度条件下,AI 可能会通过猜测来回答关于“红色球体”的问题。如果它生成的解释是“因为它是一个红色的圆形物体”,这个解释与答案是一致的,但对视觉输入 (灰色的) 并不忠实 。
用户看到连贯的句子,会将更高层次的推理能力归因于系统。他们可能会想: “嗯,虽然答案错了,但它显然知道红色球体是什么,所以它一定很聪明。”他们未能意识到系统完全是在幻觉出“红色”这个属性。
自动指标与人类感知
为了进一步强调这种脱节,研究人员将他们的人类研究发现与用于评估这些模型的标准自动指标 (如 BERTScore )进行了比较。
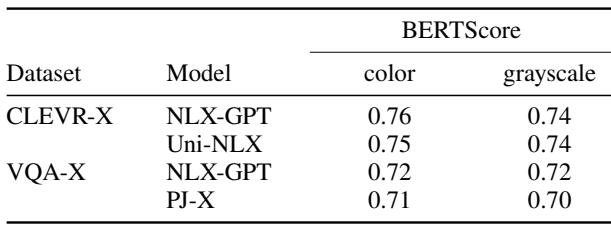
Table 3 显示,BERTScore (衡量 AI 解释与真实人类解释之间的文本相似度) 发现彩色和灰度条件之间几乎没有差异 (例如,0.76 vs 0.74) 。
根据自动指标,AI 在灰度模式下表现良好。这揭示了我们构建 AI 方式中的一个危险缺陷: 我们优化的指标奖励流畅、像人类的文本,而不一定是事实依据。AI 学会了生成高分文本,即使它是功能性失明的。
更广泛的影响
这项研究虽然聚焦于一个简单的视觉任务,但对大型语言模型 (LLM) 和复杂决策支持系统的部署具有深远的影响。
- 雄辩的危险: 我们正进入一个 AI 系统极其雄辩的时代。它们可以编写代码、法律摘要和医疗建议。这篇论文表明,雄辩是信任的一个混淆变量。如果一个法律 AI 引用了一个不存在的案例,但用完美的法律术语解释其推理,律师可能会被诱骗去信任它。
- 忠实性很难: 创建真正反映模型“损坏”部分的解释是很困难的。如果模型依赖于相关性 (例如,“草意味着绿色”) ,解释听起来会是正确的 (“我看到了绿色”) ,即使感知并不存在。
- 用户培训: 用户目前没有能力审计 AI 的解释。我们倾向于信任流畅的语言。研究参与者不是专家,但他们代表了将使用这些工具的大众。
结论
论文 “The Illusion of Competence” 为可解释人工智能领域提供了一个清醒的现实检验。研究人员证明,提供自然语言解释并不会自动导致更好的心智模型。事实上,当 AI 系统存在特定缺陷——如无法感知颜色——时,解释可能会通过投射虚假的推理能力来掩盖这一局限性。
对于学生和未来的从业者来说,结论很明确: 不要将解释模块的输出与模型的实际推理混为一谈。 在我们构建下一代 AI 时,我们必须超越合理性,努力寻求能极其诚实地反映系统局限性的解释——即使这会让 AI 看起来不那么聪明。
关键要点:
- 解释可能会误导: 即使系统失败,它们也能增加信任。
- 流利 \(\neq\) 能力: 语法正确的解释并不意味着正确的视觉感知。
- 诊断很困难: 当被自信的解释分心时,用户很难隔离出具体的故障 (如色盲) 。
- 指标需要更新: 像 BERTScore 这样的自动评分可能会验证“幻觉”出来的解释,未能捕捉到依据的缺失。
博客文章中的参考文献指向图像组中提供的实验项目和结果。