](https://deep-paper.org/en/paper/2406.19415/images/cover.png)
GPT-4 和 Gemini 等大型语言模型 (LLM) 的兴起彻底改变了我们与信息交互的方式。我们提出复杂的问题,而这些模型能生成流畅、类似人类的回答。然而,机器中存在一个幽灵: 幻觉 (Hallucination) 。 众所周知,LLM 经常自信满满地将虚假信息陈述为事实。
对于英语使用者来说,我们已经开发了复杂的工具来捕捉这些谎言。其中一个黄金标准是 FActScore (Fine-grained Atomic Evaluation of Factual Precision,事实精度的细粒度原子评估) ,这是一种旨在将长篇生成文本分解为独立事实并逐一验证的指标。
但世界并不只讲英语。随着多语言 LLM 的激增,一个关键问题出现了: 当我们切换语言时,我们核查真相的能力还能保持吗?
在研究论文 “An Analysis of Multilingual FActScore” 中,来自 KAIST、Kensho Technologies 和 Adobe Research 的研究人员深入探讨了这个问题。他们拆解了 FActScore 流程,观察其在西班牙语、阿拉伯语和孟加拉语中的表现。他们的发现揭示了一个严酷的现实: 我们依赖的用于监管 AI 真实性的工具在非英语环境中显著变弱,这很大程度上是由于缺乏高质量资源造成的。
本文将带你了解他们的分析,解释 FActScore 是如何工作的,为什么它在低资源语言中会失效,以及我们能做些什么来修复它。
1. 核心问题: 多语言世界中的真实性
在深入研究方法论之前,我们需要了解其中的利害关系。当一个 LLM 用英语生成一位名人的传记时,它可以访问大量的训练数据。当我们想要验证这篇传记时,我们拥有高质量的自动化工具和全面的英文维基百科。
然而,语言通常根据“资源层级”——即该语言可用的数字数据量——进行分类:
- 高资源 (High-Resource) : 英语、西班牙语、法语、中文。
- 中资源 (Medium-Resource) : 阿拉伯语、印地语。
- 低资源 (Low-Resource) : 孟加拉语、斯瓦希里语、乌尔都语。
研究人员假设,事实核查指标的可靠性与这些资源层级相关。如果一个 LLM 用孟加拉语生成传记,而我们的自动事实核查器也依赖孟加拉语数据,它能捕捉到幻觉吗?还是它自己也会产生幻觉?
为了验证这一点,作者选择了三种不同的语言来代表这一光谱:
- 西班牙语 (es): 高资源。
- 阿拉伯语 (ar): 中资源。
- 孟加拉语 (bn): 低资源。
2. 背景: FActScore 如何工作
要理解论文的批评,你首先需要了解他们批评的工具。FActScore 不是对整篇文档给出一个简单的二元“真/假”标签。它是一个细粒度的管线流程。
真理方程
FActScore 的核心思想是衡量精确度 (precision) : 模型提出的原子主张 (atomic claims) 中有百分之多少得到了知识源的支持?
在数学上,它看起来像这样:

这里,\(A^{\mathcal{E}}(x)\) 代表从文本 \(x\) 中提取出的“原子事实”集合。该函数返回这些事实中为真 (由指示函数 \(\mathbb{1}\) 表示) 的平均比例。
当整体评估一个模型 (如 GPT-4) 时,我们会取一组提示词的期望值:
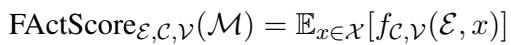
四步管线
这个数学定义转化为一个包含四个组件的具体软件管线。研究人员仔细审查了每一个组件:
- 主体模型生成 (Subject Model Generation) : LLM (例如 GPT-4) 生成长篇文本,比如一篇传记。
- 原子事实抽取 (Atomic Fact Extraction) : 一个独立的模型将该文本分解为简短的、单陈述的句子 (原子) 。
- *例如: * “贝拉克·奥巴马 1961 年出生于夏威夷” \(\rightarrow\) “贝拉克·奥巴马出生于夏威夷” 和 “贝拉克·奥巴马出生于 1961 年。”
- 检索 (Retrieval) : 系统搜索知识源 (通常是维基百科) ,以找到与每个原子事实相关的段落。
- 事实评分 (Fact Scoring) : 一个自动裁判 (通常是另一个 LLM) 阅读检索到的段落,并判定原子事实是否得到支持。
作者的目标是找到“瓶颈”——这四个步骤中的哪一步导致系统在多语言环境中失效?
3. 方法论: 原生数据 vs. 翻译数据
这篇论文的主要贡献之一是创建了一个新数据集。以前的工作通常通过简单地将英语数据集翻译成其他语言来评估多语言性能。作者认为这是有缺陷的,因为它引入了来自翻译过程本身的“级联错误”。
为了获得真正的基准,他们创建了两个数据集:
R1: 翻译标注 (The Translated Annotation)
他们使用了原始的英语 FActScore 数据集,并使用谷歌翻译将原子事实和知识源转换为目标语言。这作为一个对照组,但不是黄金标准。
R2: 原生标注 (The Native Annotation)
这是新颖的贡献。他们聘请了西班牙语、阿拉伯语和孟加拉语的母语人士。他们选择了与这些文化相关的传记 (当地政治家、艺术家等) ,而不是仅仅翻译西方人物的传记。
- 使用的主体模型: GPT-4 和 Gemini-Pro-1.0 (GemP)。
- 标注者: 母语人士,他们手动验证生成的事实以创建“基准真相 (Ground Truth) ”。
这个“原生”数据集允许研究人员观察 FActScore 在完全处于目标语言的文化和语言语境中运行时的表现。
4. 深度剖析: 分析组件
研究人员系统地测试了 FActScore 机器的每一个齿轮。让我们看看他们在每个组件中发现了什么。
组件 1: 原子事实抽取
第一步是将复杂的句子分解为简单的事实。如果这一步失败,整个评估就会失败。研究人员在这项任务上比较了三个模型: GPT-3.5、GPT-4 和一个经过微调的开源模型 Gemma。
他们发现,虽然 GPT-4 非常出色,但随着语言资源的减少,性能也会下降。错误的类型也发生了变化。在英语中,错误通常只是关于句子分割得不好。在阿拉伯语和孟加拉语中,模型开始犯归因错误 (grounding errors) ——这意味着提取的事实声称了某些原始句子中根本没有的内容。
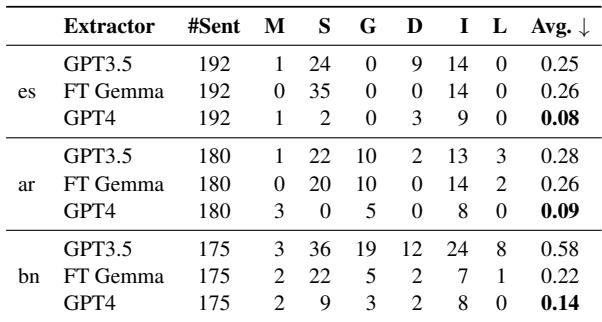
表 2 的关键结论: 注意“Avg” (每句平均错误数) 一列。
- GPT-4 非常稳健 (0.08 - 0.14 的错误率) 。
- GPT-3.5 在孟加拉语上表现非常挣扎 (0.58 的错误率) ,其犯错率是西班牙语的两倍多。
- 微调后的 Gemma (FT Gemma) : 令人惊讶的是,一个专门为此任务微调的小型开源模型在孟加拉语上的表现实际上超过了 GPT-3.5。这表明对于低资源语言中的特定任务,专门的小模型可以击败通用的巨型模型。
组件 2: 事实评分
一旦事实被提取并且证据被检索出来,“LLM 作为裁判”必须做出决定: 真还是假?
研究人员将人类评分 (基准真相) 与 GPT-4、Gemini Pro (GemP)、GPT-3.5 和 Mistral 做出的判断进行了比较。

解读图 1:
- 上图 (FActScore) : 这些显示了估计的真实性得分。对比西班牙语 (es) 列与孟加拉语 (bn) 列。
- GPT-4 (橙线) : 持续高估真实性。它太宽容了。
- GemP (绿线) : 持续低估真实性。它太严格了。
- 下图 (准确率) : 这是最确凿的指标。它衡量 LLM 与人类达成一致的频率。
- 对于西班牙语 (
es),准确率很高 (约 80%) 。 - 对于孟加拉语 (
bn),GPT-3.5 和 Mistral 的准确率显著下降。 - 即使是最强的模型 (GPT-4) 也显示出随着资源层级下降,可靠性也在下降。
这证明我们不能盲目地信任一个 LLM 在低资源语言中为另一个 LLM 评分。
组件 3: 知识源
这篇论文或许最深刻的部分是对维基百科的批评。标准的 FActScore 流程使用维基百科作为真理之源。
- 假设: 孟加拉语的维基百科比英语维基百科规模小得多,细节也少得多。因此,许多真实的事实会被标记为“假”,仅仅因为它们不在孟加拉语维基百科中。
为了验证这一点,他们将实体分类为“本土流行” (例如,著名的孟加拉作家) 与“国际流行” (例如,贝拉克·奥巴马) 。
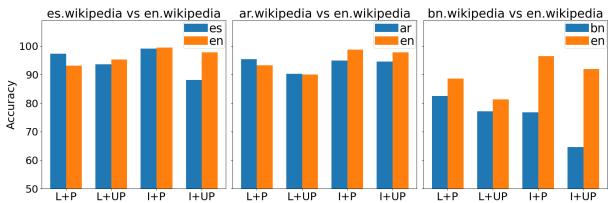
图 2 的洞察:
- 蓝色柱 (本土 Wiki) : 使用母语维基百科的准确率。
- 橙色柱 (英语 Wiki) : 使用英语维基百科的准确率。
看最右边的孟加拉语 (bn) 部分。橙色柱几乎总是高于蓝色柱,即使对于本土人物也是如此。这表明孟加拉语维基百科非常稀疏,以至于即使是针对孟加拉语特有的话题,查阅英语维基百科通常也更好。这对于发展中国家的自动化评估来说是一个主要限制。
组件 4: 检索器
检索器是寻找相关段落的搜索引擎。如果检索器找不到证据,评分器就会错误地将事实标记为假。
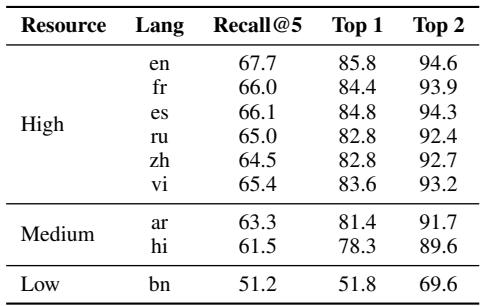
表 3 分析: 该表衡量 Recall@5 (在前 5 个结果中找到正确段落) 。
- 高资源 (es, fr, ru): 召回率约为 66%。
- 低资源 (bn): 召回率降至 51% 。
这就意味着 15% 的下降,对于孟加拉语来说,系统有一半的时间是在盲目操作。即使证据存在,它也找不到。
5. 翻译是答案吗?
自然语言处理 (NLP) 中一个常见的变通方法是“翻译-测试 (Translate-Test) ”。为什么不把孟加拉语文本翻译成英语,然后在那里运行评估呢?
研究人员使用他们的 R1 和 R3 (翻译后) 数据集对此进行了测试。
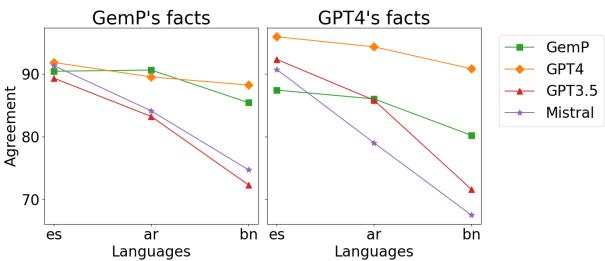
图 3 显示了在原生文本与翻译文本上进行评估的一致性。
- 对于 GemP 和 GPT-4 , 线条相对平坦,这意味着无论是否翻译,它们都是一致的。
- 对于 GPT-3.5 和 Mistral , 在孟加拉语 (
bn) 上的表现断崖式下跌。
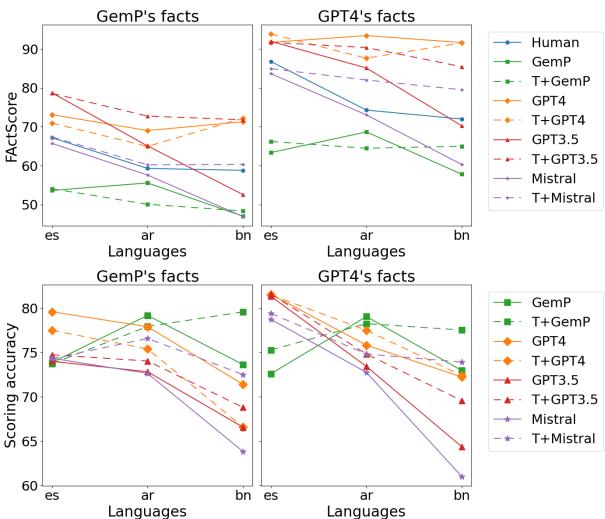
图 4 提供了一个细微的差别。虚线 (翻译) 有时表现得比实线 (原生) 更好,特别是对于像 GPT-3.5 这样较弱的模型在阿拉伯语和孟加拉语中 (左下角图表) 。
为什么? 因为英语工具 (检索器、评分器) 要好得多,以至于它们抵消了翻译引入的错误。然而,依赖翻译是有风险的,因为它引入了直译可能遗漏或扭曲的文化细微差别。
6. 错误分析: 当模型对分数产生幻觉
为什么 GPT-4 会高估真实性 (如图 1 所示) ?研究人员进行了定性错误分析来找出原因。
他们发现 GPT-4 存在上下文不忠实 (Contextual Unfaithfulness) 的问题。
- 规则: * 评分器应该仅*基于检索到的维基百科段落进行判断。
- *现实: * GPT-4 忽略了段落,使用了它自己的内部训练记忆。
如果 GPT-4 “知道”某个事实是真的,它就会将其标记为“支持”,即使检索到的段落对此只字未提。虽然这看起来很有帮助,但它破坏了该指标的目的,即验证基于来源的依据。
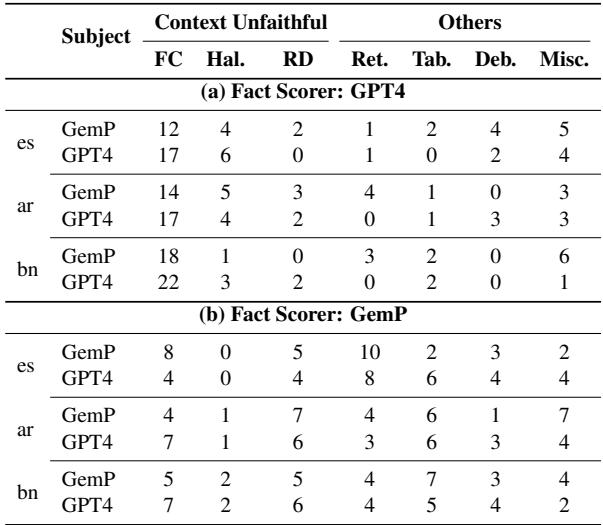
表 4 强调了上下文不忠实是 GPT-4 的主要错误 (第一行) ,而检索错误是 GemP 的主要问题。
7. 缓解措施: 我们如何修复它?
论文不仅仅提出了问题;它还提供了解决方案。作者认识到瓶颈在于知识源 (稀疏的维基百科) 和检索器 。
他们提出了三种缓解策略来改善低资源语言中的 FActScore:
- 扩展上下文 (k=20): 检索 20 个段落,而不是仅仅 8 个。
- Google 搜索 (互联网) : 使用 Google API 搜索整个互联网,而不是维基百科。
- LLM 生成 (GPT-4 的内部知识) : 使用 GPT-4 生成一篇关于该实体的背景文章,并使用那篇文章作为证据。 (基本上是利用 GPT-4 的内部知识作为文档) 。
缓解措施的结果
结果是颠覆性的。

表 22 提供了具体例子。在西班牙语的例子中,维基百科没有提到 Spivak 关于翻译的著作。然而, Google 查询 API 找到了她写的关于该主题的书籍,使模型能够正确地将该事实标记为真。
定量结果 (在论文的表 5 和表 6 中讨论) 显示:
- 扩展上下文 略有帮助。
- LLM 生成 在高/中资源语言中有显著帮助。
- Google 搜索 是最终的赢家。它将孟加拉语的准确率从约 60% 提高到了 86.8% 。
这证明了模型的“智能”并不是唯一的问题; 信息的可用性才是瓶颈。当我们让模型访问开放的互联网而不是有限的维基百科时,即使在低资源语言中,它们也能成为称职的事实核查员。
8. 结论与启示
论文 “An Analysis of Multilingual FActScore” 为 AI 社区敲响了警钟。当我们急于部署多语言模型时,我们的评估指标仍然是以英语为中心的。
主要收获:
- 评估中的不平等: 目前的工具惩罚低资源语言。一篇符合事实的孟加拉语文本可能会仅仅因为孟加拉语维基百科规模小或检索器弱而获得较低的 FActScore。
- 维基百科的天花板: 维基百科不足以作为全球事实核查的知识库。我们必须整合更广泛的网络或经过验证的本地数据库。
- 内部知识偏差: 像 GPT-4 这样的强模型经常忽略提供的证据,这使得它们在严格的“依据”任务中成为不可靠的裁判,除非经过仔细的提示。
- 修复方案已存在: 通过从静态的维基百科转储转向动态的互联网搜索 (Google API) ,我们可以大幅提高多语言评估的公平性和准确性。
对于进入该领域的学生和研究人员来说,这篇论文强调了构建模型只是战斗的一半。 验证它需要对模型所处的数据生态系统有深刻的理解。随着 AI 走向全球,我们的基准测试也必须走向全球——不仅仅是在翻译上,而是在其基础设计上。