](https://deep-paper.org/en/paper/2406.19593/images/cover.png)
引言
想象一下,向 AI 展示一张某种稀有鸟类停在树枝上的照片,然后问: “这种鸟的迁徙路线是什么?”
像 GPT-4V 或 LLaVA 这样的标准多模态大语言模型 (MLLM) 可能会正确识别出这只鸟。然而,如果关于其具体迁徙的细节在预训练数据中并不常见,模型可能会产生“幻觉”——自信地编造一条并不存在的迁徙路线。这是 AI 中一个长期存在的可靠性问题: 模型擅长“看”,但它们并不总是“知道”所看到的一切。
在纯文本 AI 中,我们通过 检索增强生成 (RAG) 来解决这个问题。我们给模型提供一份包含事实的参考文档 (上下文) ,模型则根据该文本进行回答。但是,针对 图像 做这件事——即上下文增强视觉问答 (Context-Augmented VQA) ——要困难得多。为什么?因为缺乏训练数据。目前根本没有足够多自然存在的数据集能将图像、复杂问题以及回答该问题所需的特定文本文档结合在一起。
这就轮到 SK-VQA (合成知识视觉问答) 登场了。在一篇新的研究论文中,来自英特尔实验室和亚马逊的团队提出了一个新颖的解决方案: 如果数据不存在,那就 生成它 。 通过使用涉及 GPT-4 的全自动流程,他们创建了一个包含超过 200 万个视觉问答对并配有详细上下文文档的海量数据集。
在这篇文章中,我们将深入探讨 SK-VQA 是如何构建的,为什么合成数据是解锁更强多模态 RAG 系统的关键,以及实验揭示了 AI 推理未来的哪些可能性。
问题: 多模态 RAG 中的数据瓶颈
要理解 SK-VQA 的价值,我们首先需要了解 基于知识的视觉问答 (KB-VQA) 的现状。
在标准的 VQA 中,你可能会问: “这辆车是什么颜色的?”答案就在像素数据中。而在 KB-VQA 中,你会问: “是谁制造了这辆车,该型号是在哪一年停产的?”答案需要图像本身之外的外部知识。
为了训练模型做到这一点,我们需要三元组数据:
- 图像: 视觉输入。
- 上下文: 包含外部知识的文本文档 (例如,维基百科片段) 。
- 问答 (Q&A) : 一个需要同时对 图像 和 文本 进行推理的查询。
现有数据集的局限性
现有的数据集 (如 InfoSeek 或 OK-VQA) 试图填补这一空白,但它们存在显著的局限性:
- 维基百科依赖性: 它们通常从维基百科实体开始,然后搜索对应的图像。这不仅将数据限制在“有维基百科页面的事物”上,还忽略了大量的视觉概念。
- 缺乏多样性: 问题通常是使用刻板的模板创建的 (例如,“[实体] 的 [属性] 是什么?”) ,这无法捕捉自然语言的多样性。
- 规模: 这种特定三元组结构的自然数据非常稀缺。
这种稀缺性使得训练 MLLM 有效利用检索到的上下文变得困难。模型还没有“学会”如何看着图像并同时阅读文档来寻找答案。
解决方案: SK-VQA
研究人员推出了 SK-VQA , 这是迄今为止最大的 KB-VQA 数据集。他们没有去网络上搜刮稀缺的数据,而是选择了合成数据。

如 图 1 所示,该数据集提供了一张图像 (例如,比佛利希尔顿酒店) ,一份生成的上下文文档 (历史、建筑师、所有者) ,以及几组 QA 对,迫使模型将视觉信息 (识别建筑物) 与文本信息 (识别建筑师) 联系起来。
1. 生成流程
SK-VQA 的核心创新在于其生成方法。研究人员使用一个强大的基础模型 (GPT-4) 同时作为知识库和数据标注器。
该过程如下运作:
- 输入: 将一张图像输入 GPT-4。
- 上下文生成: 要求 GPT-4 撰写一篇关于该图像的“维基百科风格”的文章。
- QA 生成: 在同一步骤中,要求 GPT-4 生成需要对图像和生成的文本进行推理的问题。
这种方法解除了图像必须拥有现有维基百科页面的限制。如 图 2 所示,这使得数据集能够摄取来自不同来源的图像: 历史照片、体育快照、自然摄影,甚至是合成图像。
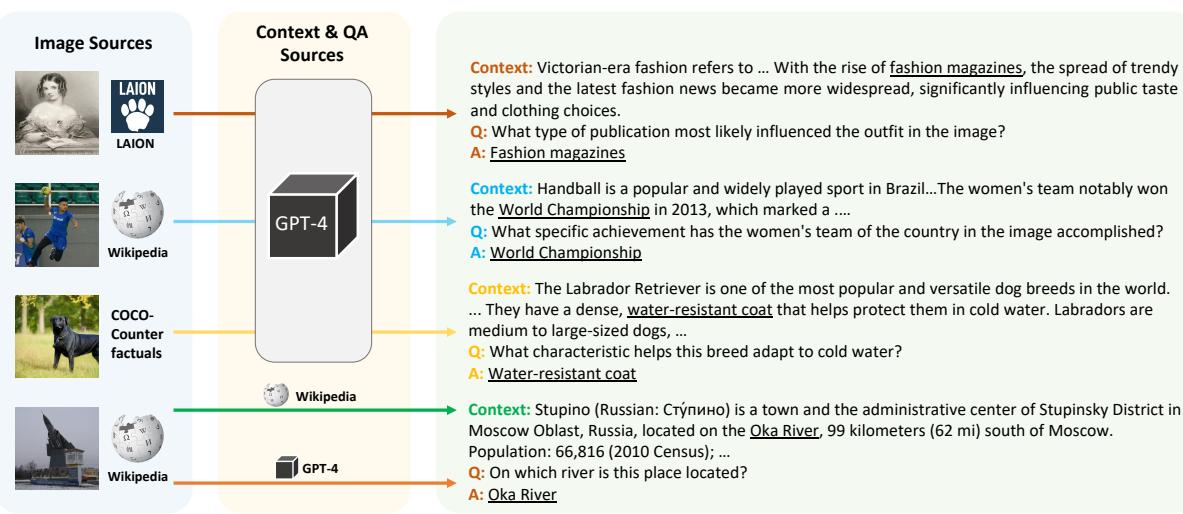
在 图 2 中,请注意多样性。系统通过生成关于时尚杂志的上下文来处理维多利亚时代的照片,或者通过解释防水皮毛等生物适应性来处理狗的照片。这种多样性是用基于模板的搜刮方法无法实现的。
2. 提示工程以确保质量
生成合成数据存在“垃圾进,垃圾出”的风险。如果提示 (prompt) 很弱,生成的数据就会充满噪声或微不足道。作者精心设计了一个特定的提示,以确保生成高质量、有难度的问题。

图 3 展示了所使用的确切提示。关键约束包括:
- “避免提及图像中物体的名称” (防止问题本身泄露答案) 。
- “问题应通过对维基百科文章的推理来回答” (强制执行 RAG 要求) 。
- “答案不应是图像中的任何物体” (迫使模型去查看文本寻找答案) 。
这种精心的提示设计确保了在该数据上训练的模型实际上是在学习 多模态推理,而不仅仅是基于物体识别进行猜测。
3. 数据集构成与规模
与以往的工作相比,SK-VQA 的规模是巨大的。研究人员结合了来自以下来源的图像:
- LAION: 来自网络的海量图像-文本对数据集。
- Wikipedia (WIT): 标准维基百科图像。
- COCO-Counterfactuals: 旨在具有迷惑性的合成图像。
最终的数据集包含超过 200 万个 QA 对 。
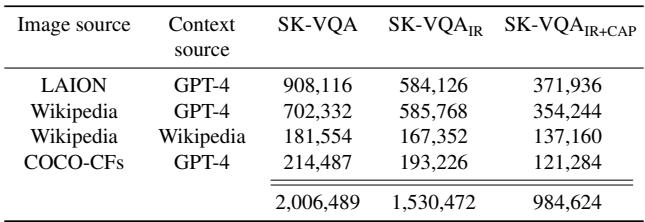
表 1 列出了详细数据。研究人员还创建了两个经过过滤的子集以确保质量:
- SK-VQA\(_{IR}\) (图像引用过滤) : 他们删除了 GPT-4 明确提到“在这张图像中……”或“如图所示……”的上下文文档。现实世界的百科全书不会引用你正在查看的特定 JPEG 图片,因此删除这些内容使文本更真实。
- SK-VQA\(_{IR+CAP}\) (上下文答案存在性) : 这个更严格的过滤器确保问题的答案明确作为字符串存在于上下文文档中。
前所未有的多样性
最引人注目的统计数据之一是 独特问题 的数量。在许多数据集中,问题是重复的 (例如,成千上万个“这是哪一年建成的?”) 。
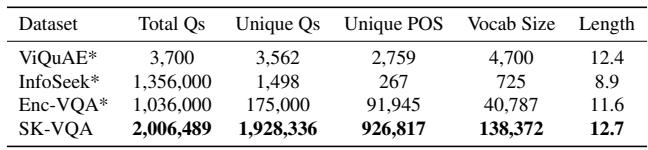
表 2 突出了这一差异。虽然 InfoSeek 拥有 130 万个 QA 对,但它只有大约 1,500 个 独特 问题。相反,SK-VQA 拥有近 190 万个独特问题 。 这种语言多样性对于防止模型记忆模板至关重要。
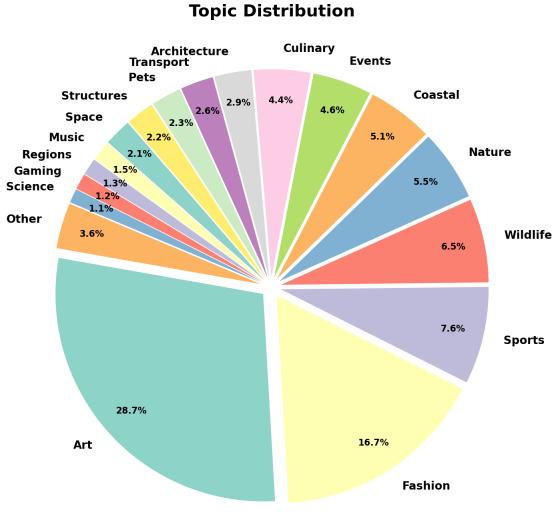
此外,涵盖的 主题 也非常广泛。与那些侧重于著名地标或名人的数据集 (重实体) 不同,SK-VQA 广泛涵盖了艺术、时尚、野生动物和自然。
4. 质量保证
我们能信任合成数据吗?作者进行了人工评估来验证质量。
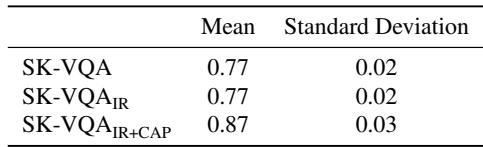
表 3 显示,人工标注者达到了很高的准确率 (在严格过滤的集合上为 87%) ,证实了问题是可回答的,且生成的上下文是相关的。他们还进行了自动化的“LLM 作为裁判”评估,发现超过 90% 的生成答案相对于生成的描述在事实上是正确的。
实验: SK-VQA 能提升模型性能吗?
对数据集的终极测试在于它是否能训练出更好的模型。研究人员使用最先进的 MLLM (如 LLaVA、PaliGemma 和 Qwen-VL) 进行了广泛的实验。
1. 零样本评估
首先,他们测试了现有的“现成”模型在没有任何特定训练的情况下在 SK-VQA 上的表现。
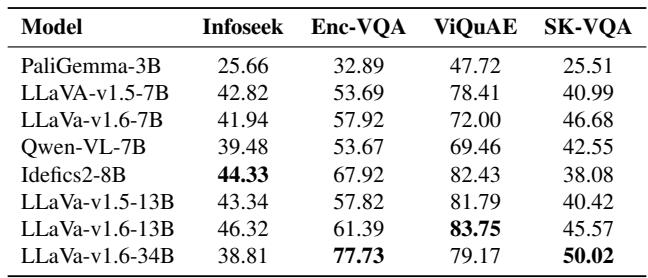
表 4 显示 SK-VQA 是一个高难度的基准测试。像 LLaVA-v1.6-34B 这样的模型在较旧的数据集 (如 ViQuAE) 上表现相对较好 (79% 准确率) ,但在 SK-VQA 上显著下降 (50% 准确率) 。这表明 SK-VQA 捕捉到了当前模型尚未掌握的推理复杂性水平。
2. 微调与泛化
这是最关键的实验。研究人员在 SK-VQA 上微调模型,并将其与在现有数据集 (InfoSeek 和 Enc-VQA) 上微调的模型进行比较。
目标是 域外 (OOD) 泛化 。 如果你在数据集 A 上训练,你在数据集 B 上的表现会变好吗?这是健壮模型的标志。
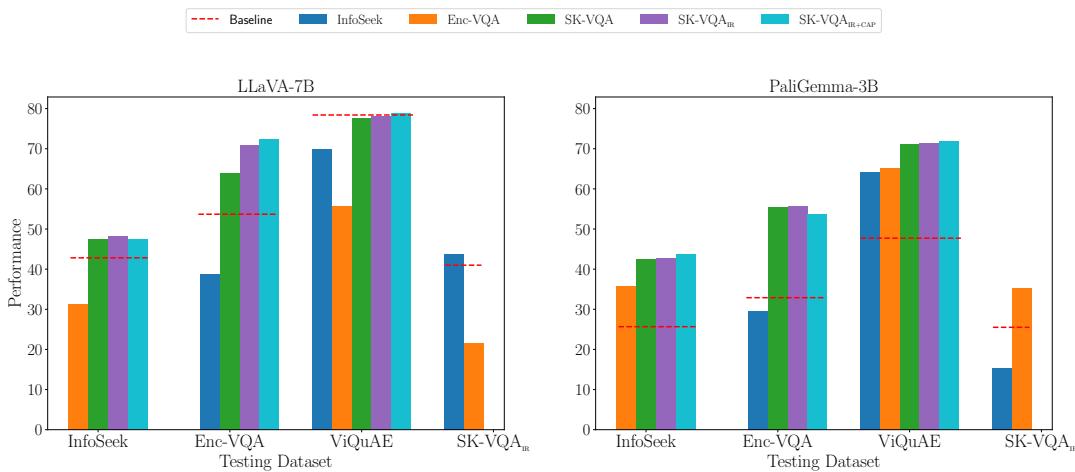
图 5 讲述了一个令人信服的故事。让我们看看左侧的 LLaVA-7B 图表:
- 红线: 模型的基线表现 (无训练) 。
- 蓝色柱 (InfoSeek 训练) : 在 InfoSeek 上表现良好 (域内) ,但在其他数据集上表现不佳。
- 橙色柱 (Enc-VQA 训练) : 在 Enc-VQA 上表现良好,在其他地方表现不佳。
- 紫色/粉色柱 (SK-VQA 训练) : 这些模型显示出 在所有数据集上的持续改进 。
这证明了 SK-VQA 教会了模型一种可泛化的技能——如何使用上下文——而不仅仅是帮助它记忆特定的数据集模式。
3. 现实世界 RAG 模拟
在现实世界中,完美的文本段落并不总是直接递到你手上的。你必须从海量数据库中检索它。研究人员模拟了这种“开放检索”设置,模型必须从前 10 个检索到的段落中挑选出正确的信息。
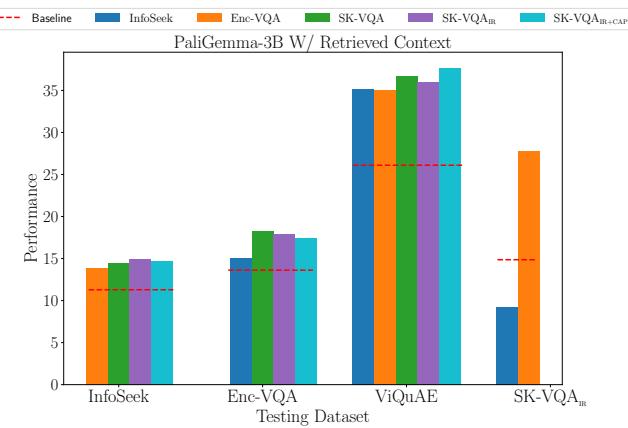
图 6 展示了 PaliGemma 模型在这种 RAG 设置下的结果。 SK-VQA 训练的模型 (紫色/粉色) 在域外任务 (ViQuAE 和 InfoSeek) 上始终优于基线和竞争对手。这证实了合成训练数据让模型为现实世界检索任务中的噪声和模糊性做好了准备。
4. 图像来源重要吗?
作者还分析了图像来源 (维基百科 vs. LAION vs. 合成) 是否影响训练。
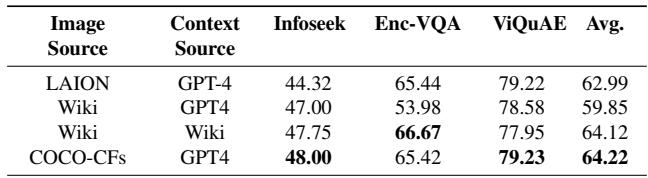
表 5 显示了一个有趣的发现: 在配对 GPT-4 上下文的合成图像 (COCO-CFs,第 4 行) 上进行训练实际上产生了极好的结果,与使用真实的维基百科图像相当甚至更好。这表明,对于训练推理能力而言, 高质量的合成数据可以像现实世界数据一样有效 , 这可能同时解决数据隐私和稀缺问题。
结论
SK-VQA 论文代表了多模态大语言模型向前迈出的重要一步。它通过实现视觉语言任务的有效检索增强生成 (RAG),解决了“幻觉”和知识缺口问题。
关键要点:
- 合成数据是可行的: 我们可以使用现有的强大模型 (GPT-4) 生成高质量、大规模的训练数据,绕过网络搜刮的局限性。
- 多样性为王: 通过打破对维基百科链接图像的依赖,SK-VQA 引入了比以前的基准测试更多的语言和视觉多样性。
- 更好的泛化能力: 在 SK-VQA 上训练的模型不仅仅是学习数据集;它们学习了上下文增强推理的 技能,从而提高了它们在完全不同的数据集上的表现。
随着 MLLM 继续融入现实世界的应用——从医学影像到个人助理——将视觉理解建立在文本事实基础上的能力将至关重要。SK-VQA 提供了实现这一目标的路线图和燃料。
SK-VQA 数据集已在 Hugging Face Hub 上公开,供有兴趣推动多模态 AI 边界的研究人员和学生使用。