](https://deep-paper.org/en/paper/2406.19934/images/cover.png)
引言
想象一下,给电脑看一张厨房乱糟糟的照片,然后问它: “冰箱上贴的日历显示是哪一年?”
对于人类来说,这是一个多步骤的过程。首先,你会扫视房间找到冰箱。其次,你会寻找冰箱上的日历。第三,你会凑近看清上面的文字。最后,你会根据看到的月份和日期推断出年份。
然而,对于一个标准的视觉语言模型 (VLM) 来说,这就像是一堆混乱的像素。目前大多数 VLM 试图通过“一眼”来解决这个问题,结果往往是自信但错误的“幻觉”。它们缺乏将复杂问题分解为一连串视觉步骤的能力。

如图 1 所示,标准模型 (如 LLaVA-NeXT 或使用简单提示词的 GPT-4o) 可能会基于一般模式产生日期的幻觉。相比之下,我们今天要讨论的方法——由少至多视觉推理 (Least-to-Most Visual Reasoning) ——模仿了人类的过程: 定位冰箱,定位日历,阅读文本,然后解开谜题。
在这篇深度文章中,我们将探讨一篇引人入胜的论文,它为多模态 AI 中的“推理鸿沟”提出了解决方案。研究人员引入了一个即插即用的视觉推理器 (Visual Reasoner) , 或许更重要的是,他们提出了一种新颖的数据合成 (Data Synthesis) 方法,可以从零开始生成高质量的训练数据,从而避开昂贵的人工标注或专有 API 成本。
背景: 为什么 VLM 在逻辑上举步维艰
大语言模型 (LLM) 已经通过“思维链” (Chain-of-Thought, CoT) 等技术掌握了推理能力,即模型会显式地写出其思考步骤。自然,研究人员希望将这种能力带入视觉语言模型 (VLM) 。
然而,视觉推理与文本推理有着根本的不同。
- 工具需求: 视觉推理通常需要在找到答案之前对图像进行操作——放大、裁剪或运行光学字符识别 (OCR) 。
- 数据稀缺: 这是最大的瓶颈。包含逻辑论证的文本文档有数百万份,但包含“视觉推理链”的数据集却寥寥无几 (例如,“第一步: 看那只狗。第二步: 看狗旁边的碗。第三步: 检查碗是否是空的”) 。
标准的 VLM 是在图像-描述对上训练的。它们非常擅长描述图像中有什么,但很不擅长推断事物在复杂序列中为什么或如何关联。这篇论文的作者认为,要解决这个问题,我们需要两样东西: 一种使用工具的新推理范式,以及一种大规模生产数据以教模型如何使用这些工具的方法。
核心方法
研究人员提出了一个包含两个主要部分的综合系统: 由少至多视觉推理推理引擎和由少至多合成数据生成流水线。
第一部分: 由少至多视觉推理
核心思想是不再将视觉问答 (VQA) 视为单步分类任务。相反,模型充当一个“推理器” (表示为 \(\mathcal{M}_R\)) ,将主要问题 \(Q\) 分解为一系列子问题和工具调用。
这是一个迭代过程。在每一步 \(k\),推理器观察当前的图像状态 \(I_k\),考虑之前的步骤历史,并决定下一步做什么。
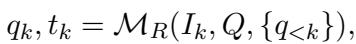
这里,\(q_k\) 是下一个子问题 (例如,“日历在哪里?”) ,\(t_k\) 是选择用来回答该问题的工具。
工具集
推理器不仅仅是“思考”;它还会行动。作者定义了一组包含四个特定工具的集合,涵盖了大多数视觉推理需求:

- 定位 (Grounding) : 找到一个物体并返回其裁剪后的图像。这允许模型“聚焦”注意力。
- 高亮 (Highlight) : 对图像进行遮罩以突出显示特定物体。这对计数任务至关重要 (例如,“高亮显示所有划船的人”) 。
- OCR: 从图像中读取文本。
- 回答 (Answer) : 也就是奇迹发生的地方。该工具调用外部现成的 VLM,基于处理后的图像回答特定的子问题。
推理循环
当推理器选择一个工具并获得结果 (\(r_k\)) 时,图像本身可能会为下一步进行更新。例如,如果工具是“定位”,下一步的输入图像 (\(I_{k+1}\)) 将是裁剪区域,而不是完整的原始图像。
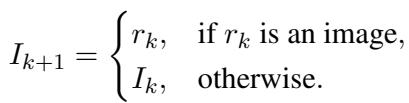
这使得模型能够在解决问题的过程中迭代地“放大”,去除干扰性的背景噪声。
第二部分: 由少至多合成 (数据引擎)
上述架构非常强大,但它需要专门的数据集来训练。我们需要成千上万个 (图像, 复杂问题, 推理路径) 的示例。大规模人工创建这些数据是不可能的。
作者引入了一种自底向上 (bottom-up) 的合成方法。他们不是拿一个复杂的问题并试图将其分解 (自顶向下) ,而是从图像中最小的细节开始,基于它们向上构建复杂的问题。
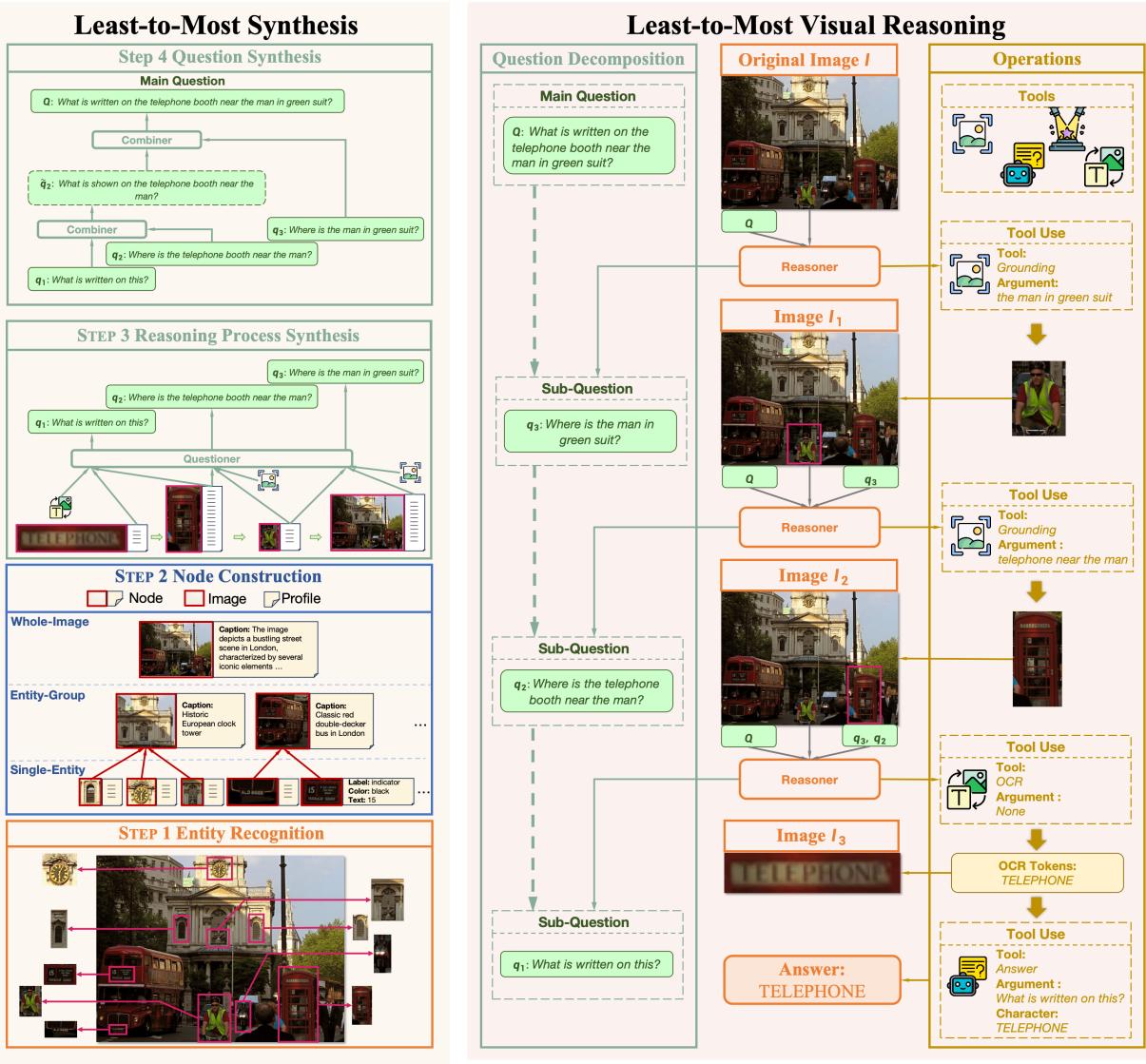
如图 2 (左) 所示,合成流水线有四个独特的阶段:
第一步: 实体识别
首先,系统需要知道图像中存在什么。它使用一个目标检测模型 (具体是 Deformable DETR) 来识别实体。它本质上是对一切进行编目: “有一个人”,“有一辆公交车”,“有一个钟”。
第二步: 节点构建
这一步将视觉信息转换为基于文本的结构化数据,称为“节点”。这是一个明智之举,因为它允许后续的合成过程由纯文本 LLM 处理 (它们比 VLM 更快、更聪明) 。
他们创建了三种类型的节点:
- 单实体节点: 一个特定的物体 (例如,红色的公交车) 。系统提取颜色、位置和上面写的任何文本等属性。
- 实体组节点: 一组物体。一个图像描述模型 (BLIP) 生成关于它们如何交互的描述。
- 全图节点: 全局视图,由 VLM (LLaVA) 生成描述以提供上下文。
第三步: 推理过程合成
现在系统开始玩“连点成线”的游戏。它采样一条节点链,并使用 LLM (“提问者”) 在它们之间生成逻辑链接。
例如,如果节点 A 是“男人”,节点 B 是“电话亭”,提问者可能会生成一个子问题,如“男人附近有什么?”,答案指向电话亭。

提问者生成从一个节点移动到下一个节点所需的子问题 \(q_m\) 和工具参数 \(\hat{t}_m\)。通过将这些链接起来,系统创建了一个多步推理路径: 找到男人 -> 找到电话亭 -> 阅读电话亭上的文字。
第四步: 问题合成
最后,系统需要触发整个链条的“主问题”。另一个 LLM (“组合器”) 获取子问题序列,并将它们合并为一个单一的、自然的语言查询。
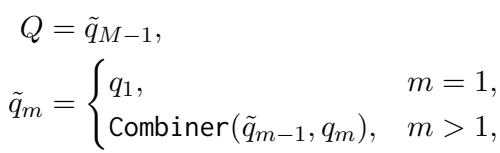
如果子问题是“男人在哪里?”、“他旁边是什么?”和“上面的文字说什么?”,组合器输出: “穿绿色西装的男人附近的电话亭上写着什么?”
可视化数据构建
为了具体说明这一点,让我们看一个涉及便当盒的例子。

在图 8 中,系统识别出杏仁、西兰花和盒子结构。它为这些物品构建节点。然后它合成了一条推理路径:
- 找到绿色食物 (西兰花) 。
- 向西兰花的左边看以找到杏仁。
- 识别装有杏仁的容器。
最终合成的问题变得很复杂: “位于绿色食物左侧的杏仁所在的盒子里有什么?”
这种自底向上的方法确保数据是无幻觉的 (因为它基于检测到的物体) 且具有成本效益 (使用开源模型) 。利用这种方法,作者创建了包含 50,000 个视觉推理示例的 VIREO 数据集。
实验与结果
作者在 VIREO 数据集上微调了一个 LLaVA-1.5-7B 模型作为“推理器”。然后,他们将这个推理器插入到各种其他 VLM (即“回答”工具) 中,包括 BLIP-2、InstructBLIP 和基础 LLaVA 模型。
评估涵盖了四个主要基准: GQA (关系) 、TextVQA (阅读文本) 和 TallyQA (计数,分为简单和复杂) 。
主要性能
结果令人信服。如表 2 所示,添加视觉推理器全面提升了性能。
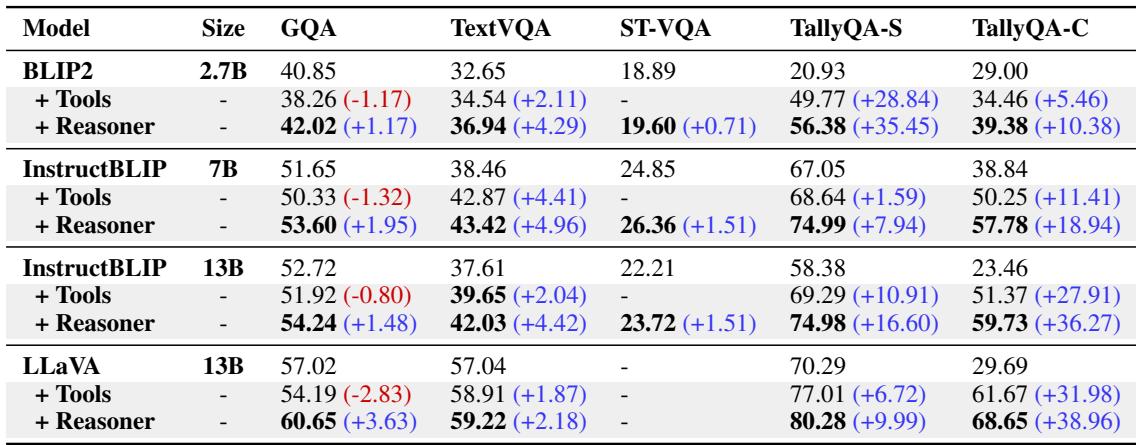
结果的关键要点:
- 一致的收益: 无论基础模型是小型的 (BLIP-2 2.7B) 还是大型的 (InstructBLIP 13B) ,推理器都提高了准确性。
- 巨大的计数改进: 看看 TallyQA 的分数。对于 LLaVA-13B,TallyQA-Complex 的性能从 29.69% 跃升至 68.65% 。 这是一个巨大的飞跃,主要归功于“高亮”工具,它允许模型在计数时视觉标记物品,而不是猜测。
- 阅读能力: TextVQA 的分数也显著提高,证明将“阅读这个”任务分解为“定位文本 -> 运行 OCR -> 解释”优于端到端的阅读。
扩展数据
一个逻辑问题是: 合成方法具有可扩展性吗?如果我们生成更多数据,模型会变得更聪明吗?
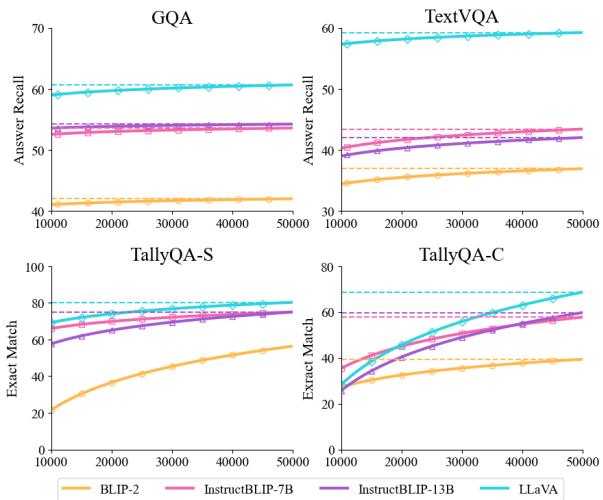
图 3 证实,将 VIREO 数据集从 1k 扩展到 50k 个示例会导致性能稳步上升。虽然存在一些边际收益递减,但这一轨迹表明合成数据是通往更好推理能力的可行路径。
我们需要所有工具吗?
作者进行了一项消融研究,以查看哪些工具最重要。
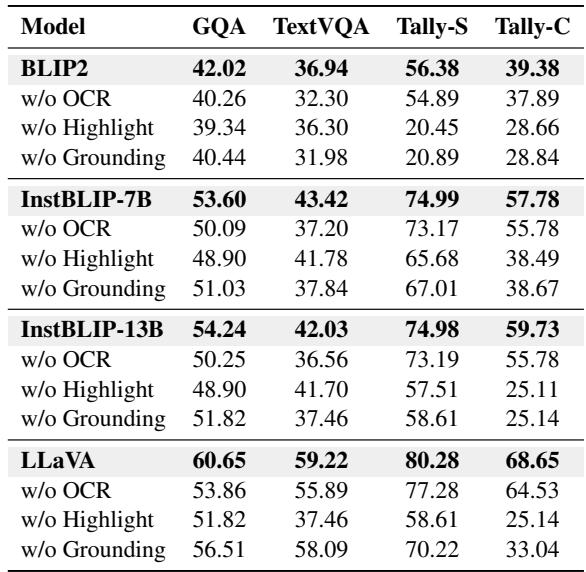
表 3 的结果具有启示性:
- 高亮是计数之王: 移除高亮工具导致 TallyQA-Complex 分数暴跌 (例如,InstructBLIP 从 59.73 降至 25.11) 。
- OCR 对文本至关重要: 移除 OCR 严重损害了 TextVQA 的性能。
- 协同作用: 移除任何单一工具都会降低性能,表明推理器成功学会了根据需要在工具之间切换。
案例研究
让我们看看模型的实际运行情况,以领会“由少至多”的逻辑。
案例 1: 阅读文本 (甜甜圈招牌) 在这个例子中,模型需要阅读一个招牌。它不仅仅是猜测。它首先定位物体 (巨大的甜甜圈招牌) ,然后应用 OCR,最后回答。

案例 2: 复杂关系 (自行车) 这里,问题询问一辆特定自行车的颜色: “穿橙色衣服的男人的自行车”。标准模型可能只是描述任何一辆自行车。推理器则:
- 定位“穿橙色衣服的男人”。
- 定位“男人附近的自行车”。
- 识别那辆自行车的颜色。

案例 3: 计数 (划船者) 计数对 AI 来说是出了名的难。在这里,推理器使用高亮工具屏蔽背景并严格聚焦于船上的人,得出了正确的计数 8。

结论与启示
论文《从少到多》 (From the Least to the Most) 为多模态 AI 中最大的两个问题提供了一个令人信服的解决方案: 推理能力的缺乏和推理数据的匮乏。
通过将视觉推理视为一个模块化、工具辅助的过程 , 作者表明即使是较小的开源模型也能达到最先进的结果。推理器充当一个复杂的“管理者”,将任务委派给专门的工具 (如 OCR) 或通用工作者 (回答 VLM) 。
然而,或许最重要的贡献是数据合成流水线。通过证明我们可以使用标准目标检测器和 LLM 自底向上地构建复杂、高质量的推理链,这项工作为大规模、可扩展的训练集打开了大门。我们不再需要等待人类标注数百万张图像来教计算机如何思考。我们只需合成课程即可。
这种即插即用的方法预示着未来 AI 系统将不再是单体的“黑盒”,而是能够思考、规划并使用工具逐步探索视觉世界的模块化系统。