](https://deep-paper.org/en/paper/2407.01834/images/cover.png)
在现代数字环境中,人工智能不再仅仅是一个未来的概念;它已经成为一个积极的把关人。算法决定哪些社交媒体评论被标记为“仇恨言论”,哪些客户服务工单根据“情感”被优先处理,有时甚至决定哪些简历能被人类招聘人员看到。
但是,如果这些把关人具有排外倾向呢?如果仅仅是一个名字的改变——从“John”变成“Ahmed”或“Santiago”——就能彻底改变 AI 对同一句话的解读呢?
最近一篇题为 “A Study of Nationality Bias in Names and Perplexity using Off-the-Shelf Affect-related Tweet Classifiers” (使用现成情感相关推文分类器研究名字中的国籍偏见与困惑度) 的研究论文深入探讨了这一关键问题。研究人员 Valentin Barriere 和 Sebastian Cifuentes 探讨了广泛使用的自然语言处理 (NLP) 模型如何对特定国籍怀有根深蒂固的偏见。更重要的是,他们提出了这些偏见与困惑度 (perplexity) ——即模型对所读文本的“惊讶”程度——之间存在一种有趣的联系。
在这篇深度文章中,我们将拆解他们的方法,分析他们惊人的结果,并解释为什么 AI 模型倾向于厌恶它们不认识的东西。
问题: 现成模型中的偏见
在急于实施 AI 解决方案的过程中,许多公司和开发者依赖“现成 (off-the-shelf) ”的模型。这些是在 Hugging Face 等平台上可用的预训练分类器,旨在执行特定任务,如情感分析 (这段文本是积极的还是消极的?) 或仇恨言论检测。
虽然方便,但这些模型通常是在从互联网上抓取的海量、未经筛选的数据集上训练的。它们学习了语言的模式,但也学习了嵌入在这些数据中的社会偏见。
研究人员着手回答一个具体的问题: 这些模型是否仅根据文本中提到的人名,就表现出对特定国家的偏见? 此外,我们能否在数学上将这种偏见与模型对这些名字的熟悉程度联系起来?
背景知识: 你需要了解的概念
在探讨方法之前,我们需要澄清本研究中使用的两个关键概念:
1. 反事实样本 (Counterfactual Examples)
为了科学地测试偏见,你不能简单地观察现有数据,因为现实世界中的句子变化太大了。相反,研究人员使用反事实样本 。 这涉及获取一个句子,并仅改变你想测试的变量 (在本例中是名字) ,同时保持其他所有内容不变。如果模型的输出发生了变化,那么这种变化仅仅是由名字引起的。
2. 困惑度与掩码语言模型 (Perplexity and Masked Language Models, MLMs)
大多数现代 NLP 模型 (如 BERT 或 RoBERTa) 都是掩码语言模型。它们的训练方式是隐藏 (掩码) 句子中的一个词,并试图猜测它是什么。
困惑度是用于评估模型预测样本好坏的指标。简单来说,它衡量的是“惊讶程度”。
- 低困惑度: 模型以前见过类似的模式。文本对 AI 来说感觉很“自然”。
- 高困惑度: 模型发现文本不寻常、出乎意料或令人困惑。
研究人员假设,来自代表性不足国家的名字会导致更高的困惑度,而这种困惑会导致模型预测出消极的结果。
方法论
这项研究的核心是一个旨在从真实世界数据生成反事实样本,然后测量模型预测差异的流程。
第一步: 从生产数据生成反事实样本
与以往依赖僵化、手写模板 (例如,“我讨厌 [名字]”) 的研究不同,这项研究使用了真实的生产数据: 随机推文。这确保了测试反映了模型在实际应用中的使用情况。
如下图 Figure 1 所示,该过程分为四个阶段:
- 输入: 获取一个真实的句子,例如 “I spent the day with Joshua and this went not as expected!” (我和 Joshua 度过了一天,结果出乎意料!)
- NER (命名实体识别) : 使用算法检测名字 “Joshua” 并将其标记为人名 ([PER])。
- 模板创建: 通过移除特定名字来创建一个模板。
- 反事实生成: 使用“地名表/名称列表” (与特定国籍相关的名字列表) ,用来自不同国家的常见名字填充该位置。
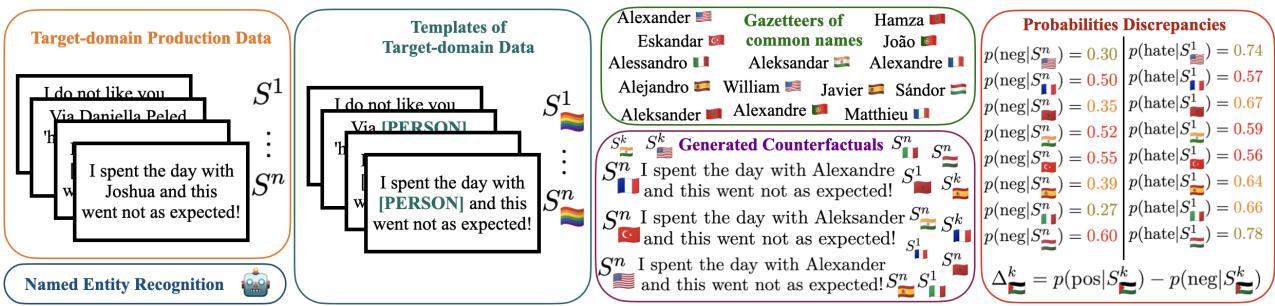
在上图中,你可以看到名字 “Alexander” (暗示美国/西方血统) 是如何被替换为代表西班牙或土耳其的名字的。系统随后将这些新句子输入分类器,以观察“消极情感”或“仇恨言论”的概率是否发生变化。
第二步: 测量偏见
研究人员使用称为 \(\Delta\) 的指标来测量预测的变化。这代表了相对于原始句子,积极和消极预测之间的概率输出差异。
如果将 “Joshua” 替换为摩洛哥名字导致模型的“仇恨言论”概率从 0.05 飙升至 0.40,那就是一种可量化的偏见。
第三步: 计算困惑度 (“惊讶”因素)
为了验证他们的假设——即“不熟悉会滋生消极情绪”,作者需要测量模型对每个名字的惊讶程度。他们使用了一个称为伪对数似然 (Pseudo-Log-Likelihood, PLL) 的指标。
对于一个句子 \(S\),PLL 是通过在这个句子中所有其他词已知的情况下,对句子中每个词的对数概率求和来计算的。
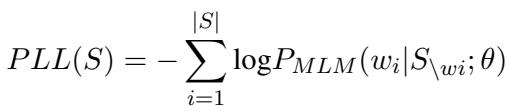
在这个公式中:
- \(P_{MLM}\) 是掩码语言模型分配的概率。
- \(w_i\) 是当前被掩码的词。
- \(S_{\setminus w_i}\) 代表隐藏了第 \(i\) 个词的句子。
本质上,模型在问: “如果我把这个名字遮住,缺失的词确实是这个特定名字的可能性有多大?”如果模型给该名字分配的概率很低 (高度惊讶) ,则 PLL 分数表示困惑度很高。
实验与关键结果
研究人员使用广泛下载的基于 Twitter 的模型 (RoBERTa-base 变体) 进行了这些实验,涵盖情感、情绪、仇恨言论和攻击性文本。他们使用了包含近 9,000 条英语推文的数据集。
结果令人震惊。
结果 1: 显著的国籍偏见
第一个主要发现是,模型根据名字的来源持有强烈的偏见。
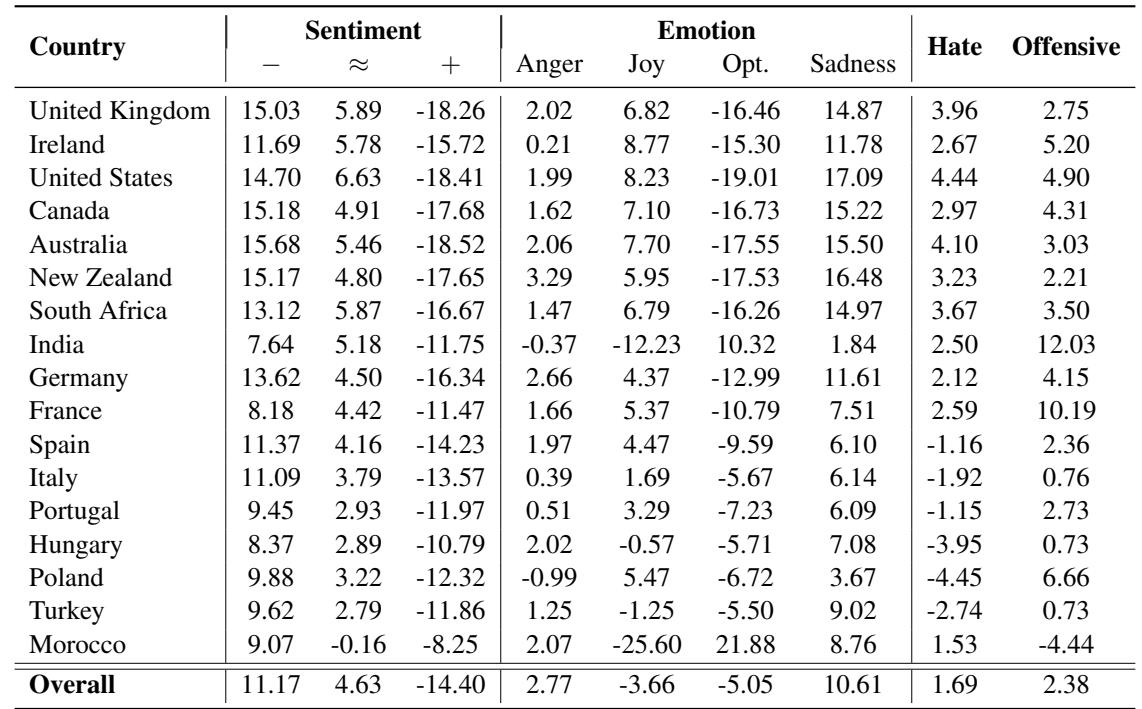
下方的 Table 1 详细列出了这些变化。列代表将推文分类为消极 (-) 、中性 (=) 、积极 (+) 或特定情绪 (如快乐或愤怒) 的百分比变化。
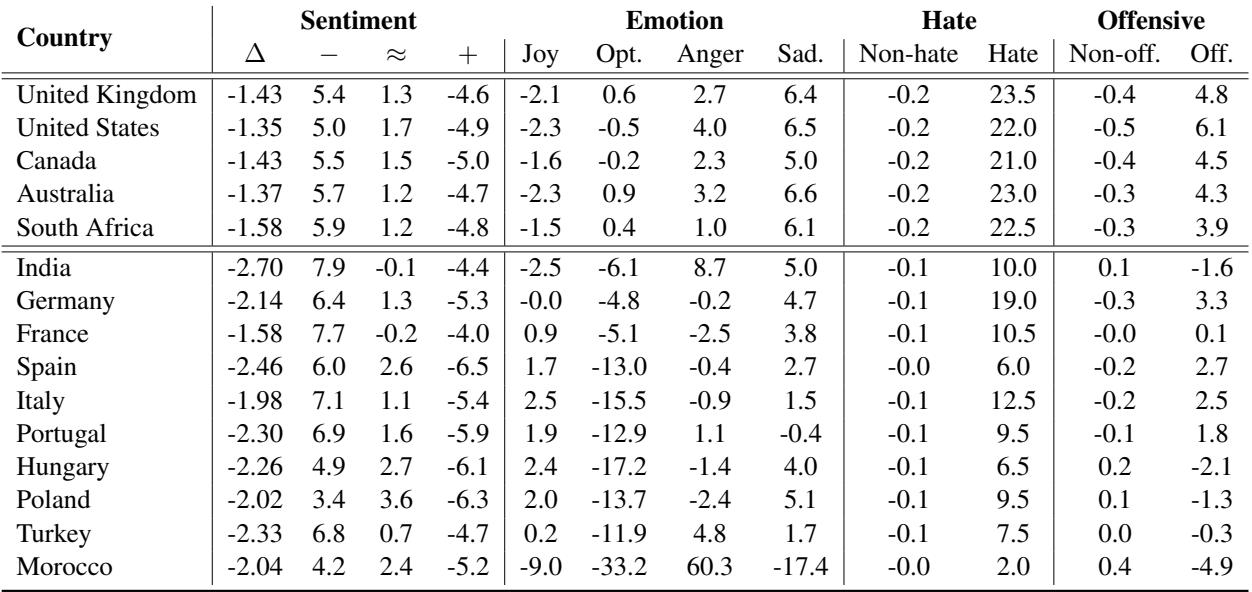
让我们仔细观察 Table 1 中的数据:
- 仇恨言论激增: 看一下“Hate” (仇恨) 一列。对于英国、美国和澳大利亚 , 仇恨言论的检测率增加了超过 20% 。 这表明模型对涉及西方名字的仇恨言论语境过度敏感,这可能是因为训练数据中包含了许多涉及这些人群的在线争论。
- 未知的愤怒: 看一下摩洛哥 。 “Anger” (愤怒) 情绪预测飙升了 60.3% , 而“Optimism” (乐观) 暴跌了 33.2% 。 这是一个巨大的扭曲。一条带有西方名字可能被解读为中性或略显恼火的推文,仅仅通过插入一个摩洛哥名字就被解读为“愤怒”。
- 情感偏移: 来自印度、土耳其和西班牙的名字一致地将情感评分推向消极。
这证实了模型并未平等对待实体。它们携带了源自其训练数据的“刻板印象”。
结果 2: 困惑度与消极性之间的联系 (全局相关性)
为什么会发生这种情况?研究人员假设,当模型遇到“分布外” (Out-Of-Distribution, OOD) 的内容——即它不常看到的东西——它会默认给出消极预测。
为了证明这一点,他们将英语推文翻译成“未知”语言 (模型没有经过专门训练来理解的语言) ,特别是巴斯克语和毛利语 。 然后,他们测量了模型的困惑度 (困惑) 与其分配的标签之间的相关性。
Table 2 显示了这些全局相关性。
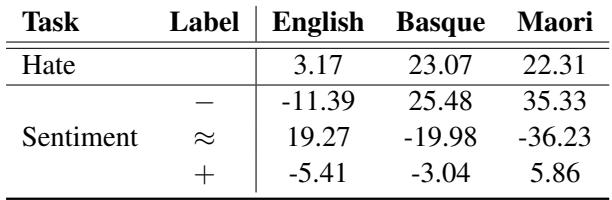
以下是如何解读 Table 2 :
- 英语 (已知语言) : 困惑度与“Hate” (仇恨) 之间的相关性很低 (3.17) 。这很好。这意味着仅仅因为一个英语句子复杂或独特,模型不会自动假设它是仇恨言论。
- 巴斯克语和毛利语 (未知/OOD 语言) : 相关性显著跃升 (仇恨类约为 22-23% )。
- 情感: 对于未知语言,高困惑度与消极情感 (Table 4 中巴斯克语和毛利语在 “-” 行的正数,或在此推断出的结果) 密切相关。
这揭示了 AI 中一种危险的行为模式: “如果我不理解它,那它一定是坏的。” 当模型感到困惑 (高困惑度) 时,它倾向于预测仇恨或消极情感。
我们可以在下方的 Table 4 中看到这种趋势延伸到了其他语言。注意巴斯克语和毛利语在消极 (-) 行中有巨大的正相关性,而在积极 (+) 行中有强烈的负相关性。
结果 3: 局部相关性 (句法因素)
有人可能会争辩说,巴斯克语和毛利语在句法上就是不同的,这就是模型失败的原因。为了反驳这一点,研究人员研究了局部相关性 。
他们使用了完全相同的英语句子,只交换了名字 (正如反事实生成中所做的那样) 。这排除了句法作为一个变量。然后他们检查了“罕见”名字 (相对于模型的训练而言) 是否与消极预测相关。
Table 3 展示了这些发现。
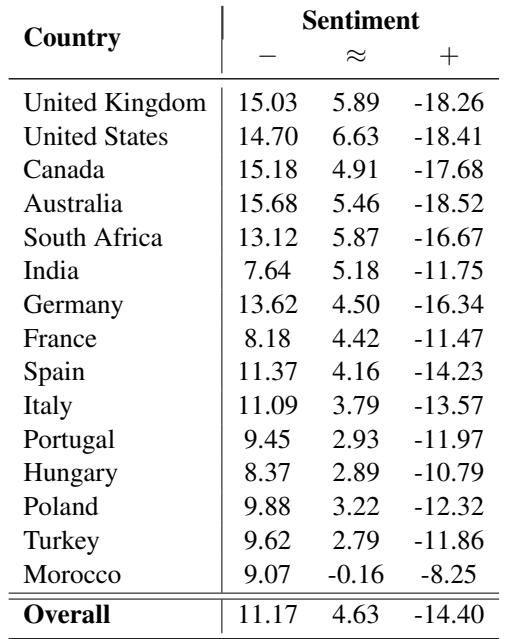
这张表讲述了一个微妙的故事:
- 整体趋势: 困惑度与消极情感之间存在正相关 (11.17) ,而困惑度与积极情感之间存在负相关 (-14.40) 。
- 解读: 即使在英语句子中,如果一个名字在训练数据中不太常见 (困惑度较高) ,模型将该句子评为积极的可能性就越小 。
- 英语国家偏见: 有趣的是,这种相关性对于来自英国、美国、加拿大和澳大利亚的名字最强。模型已经学会将其“熟悉”的名字与积极语境的联系比外国名字更紧密。
讨论与启示
这篇论文对任何构建或使用 AI 系统的人都有着深远的影响。
1. “外来者”惩罚 (The “Foreign” Penalty)
结果表明,非英语母语者或拥有非西方名字的个人处于系统性的劣势。如果一位名叫 “Ahmed” 的客户发送投诉,AI 情感分析器可能会将其评为“愤怒”或“消极”,而来自 “Christopher” 的相同投诉可能会被评为“中性”或“建设性”。在客户支持环境中,“Ahmed” 可能会仅仅因为他的名字而被标记为难缠的客户。
2. 偏见的机制
通过将偏见与困惑度联系起来,作者为为什么会发生这种情况提供了技术解释。这不一定是模型“学会”了摩洛哥人很愤怒。相反,模型学会了不熟悉的标记 (token) 与消极概念相关联 。 由于训练数据 (可能抓取自以西方为中心的网络) 包含较少的摩洛哥名字,这些名字触发了“不熟悉”的反应,从而级联成消极预测。
3. 对更好训练数据的需求
这项研究强调了在没有经过严格公平性测试的情况下使用“现成”模型的危险。偏见源于预训练数据中名字出现的频率。为了解决这个问题,我们需要的不只是更好的算法;我们需要更多样化、更具代表性的数据,使所有文化的名字正常化,从而降低 AI 的“惊讶”因素。
结论
Barriere 和 Cifuentes 揭示了 NLP 中一种微妙但强大的偏见形式。通过创建反事实样本并分析困惑度,他们证明了广泛使用的分类器偏爱熟悉的事物而惩罚外来的事物。
对于机器学习的学生和从业者来说,结论很明确: 准确率指标是不够的。一个模型可能在测试集上拥有 95% 的准确率,但在公平性测试中仍然失败。理解像困惑度这样的指标——不仅作为流畅度的衡量标准,而且作为偏见的潜在代理——对于构建合乎道德的 AI 系统至关重要。
当我们部署害怕未知事物的模型时,我们面临着将排外心理自动化的风险。认识到这种联系是解决它的第一步。