](https://deep-paper.org/en/paper/2407.02646/images/cover.png)
为什么语言模型有时表现得像天才,有时又像神秘的黑箱?可解释性机理 (Mechanistic Interpretability,MI) 试图通过逆向工程来回答这个问题,探究这些模型实际计算的内容——深入到神经元、注意力头以及连接它们的回路。本文将近期的一篇综述《基于 Transformer 的语言模型的可解释性机理实用综述》 (A Practical Review of Mechanistic Interpretability for Transformer-Based Language Models) 提炼为一份以任务为中心的实践指南,旨在帮助希望从好奇心出发,迈向可复现研究的学生和从业者。
你将从本指南中获得:
- 一份简明的 Transformer 复习,让你能熟练掌握 MI 的语言。
- MI 研究的三个核心对象 (特征、回路、普遍性) ,以及它们的重要性。
- 主要技术 (logit lens、干预/修补、稀疏自编码器、探测、可视化) 的原理、用法及其局限。
- 一份以任务为中心、循序渐进的“初学者路线图”,涵盖特征、回路和普遍性研究。
- 具体示例、评估技巧,以及对开放问题和未来研究方向的坦诚讨论。
如果你的目标是开展第一次可解释性实验,或希望在阅读论文时更清晰地理解其方法与主张,这篇指南将帮助你自信地做到这一点。
1. Transformer 快速入门 (让 MI 与你同频)
Transformer 通过为每个词元 (token) 维护一个向量表示,并逐层迭代优化该表示来处理词元序列。残差流 (residual stream) 是这些表示在各层之间的序列。
层更新的简要形式:
- 设 \(h_i^l\) 为第 \(l\) 层词元位置 \(i\) 的表示。
- 每层产生一个注意力输出 \(a_i^l\) 和前馈输出 \(f_i^l\)。
- 残差更新常写作: \[ h_i^l = h_i^{l-1} + a_i^l + f_i^l. \]
多头注意力 (Multi-head Attention, MHA) 使每个词元能通过学习的查询/键/值投影整合来自其他位置的信息。前馈 (Feed-forward, FF) 子层通过逐词的 MLP 编码特征或生成模型后续层使用的特征。解嵌入 (unembedding) 矩阵 \(W_U\) 将最终层表示映射到词汇表上的 logits。
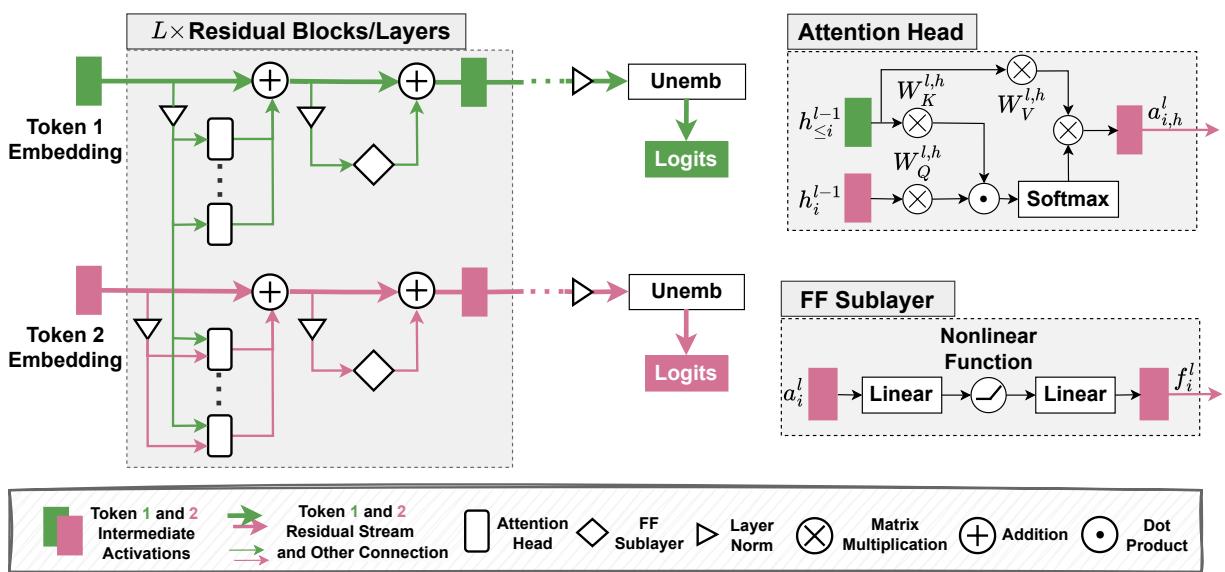
图 1: 基于 Transformer 的语言模型架构——词元流经残差流、注意力头和前馈子层,最后通过解嵌入投影为 logits。
2. 什么是可解释性机理 (MI) ?
MI 的核心在于“打开引擎盖”,用可理解的算法术语描述模型的内部计算。与只问“模型输出是什么?”不同,MI 追问“模型是如何计算出这个输出的?”
MI 社区通常围绕三类基本对象开展分析:
- 特征 (Features) — 模型激活中编码了哪些人类可解释的输入或概念?
- 回路 (Circuits) — 模型组件 (神经元、注意力头、FF 块) 如何相互作用以实现特定行为或算法?
- 普遍性 (Universality) — 相同的特征与回路是否会在不同模型、不同初始化、不同任务中出现?
这三大问题引导了多数 MI 研究,并构成了我们稍后介绍的任务中心路线图的基础。
3. MI 的基本对象 (附示例)
特征
特征是激活中编码的某种可解释属性——例如“是法语文本”、“一个实体名称”,或“算术指示符”。特征可以定位到单个神经元、激活空间中的某一方向,或分布式子空间。
回路
回路是模型中实现某种行为的子图 (节点与边) 。例如,Elhage 等人发现了一个玩具模型中的小型归纳回路: 一个头检测之前出现的模式,另一个头利用该信号将词元复制向前。
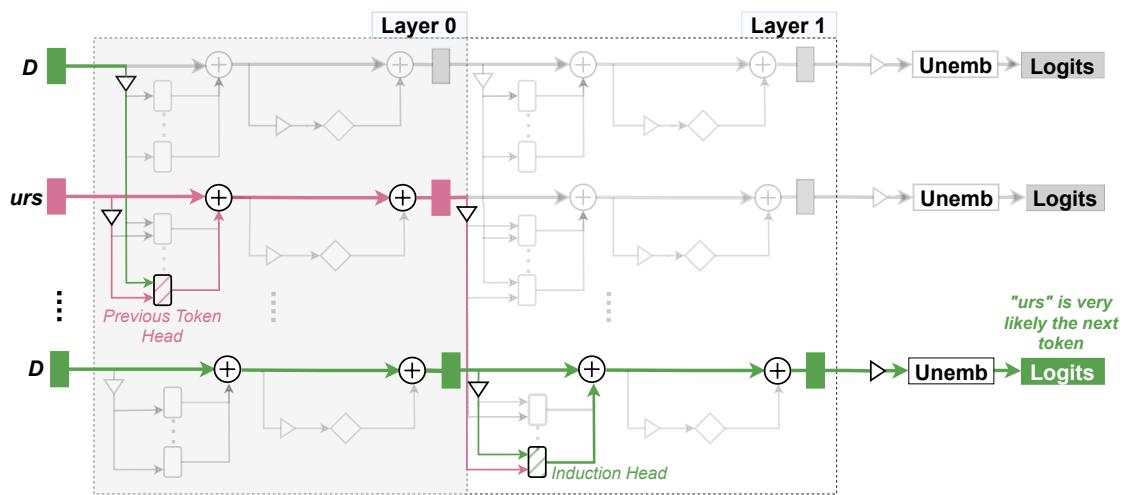
图 2: 归纳回路通过连接前一词元检测头和归纳头,检测并延续重复的子序列。
普遍性
如果我们在 GPT-2 small 中发现一个回路,Gemma 或 Llama 中是否也存在类似的回路?普遍性研究探讨不同模型与任务间的迁移或趋同程度。混合研究结果表明,部分组件 (如归纳头) 屡见不鲜,而某些回路则受初始化与训练细节影响较大。
4. MI 工具箱——核心技术及其作用
以下是 MI 中最常用的技术、其高层原理及应用时的实际注意事项。
4.1 词汇表投影方法 (Logit Lens 及其变体)
思想 : 取中间激活 (如 \(h_i^l\)) ,应用模型的解嵌入矩阵 \(W_U\) (常需一定对齐) ,并查看得到的 logits。此步骤可提供模型在该层“正在思考什么”的词汇级信号。
优点
- 提供对中间预测的人类可读视窗。
- 便于生成假设: 了解某层倾向哪些词元。
注意事项
- 早期层的基础空间可能不同于最终层,原始投影可能误导。
- 经过调优的透镜或学习型线性转换器 (如 Tuned Lens) 能提高保真度。
- 投影解码的是词元概率,仅能揭示词汇空间中显性特征。
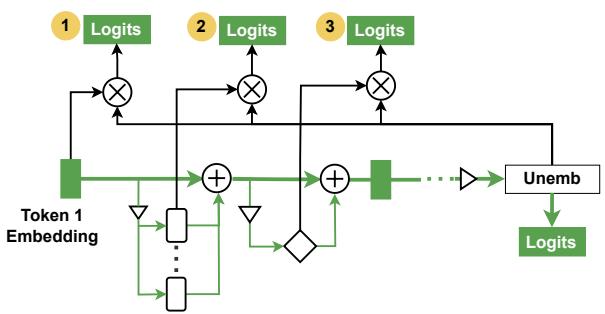
图 4: Logit Lens 实现示意。展示残差流、注意力头输出与前馈子层的投影。
常见变体与扩展
- Tuned Lens / Attention Lens : 学习小型转换器,将中间激活映射至最终层基底。
- Future Lens / Patchscope : 将投影与干预结合,以解码未来词元或潜在特征的信息。
4.2 基于干预的方法 (激活修补 / 因果追踪)
思想 : 把模型视作计算/因果图。分别运行三次——干净、受扰与修补——观察替换激活部分对输出的影响。干预类型包括:
- 噪声消融 : 移除某组件贡献。
- 因果修补 : 在受扰运行中恢复组件的干净贡献。
优点
- 为组件在特定行为中的必要性与充分性提供因果证据。
- 回路定位的核心方法。
典型流程
- 对干净输入运行模型并缓存激活。
- 对受扰输入运行模型并缓存激活。
- 在干净运行中替换受扰运行的部分激活 (节点修补) ,或沿特定计算路径替换 (边/路径修补) 。
- 测量 logits、logit 差异或 KL 散度变化。
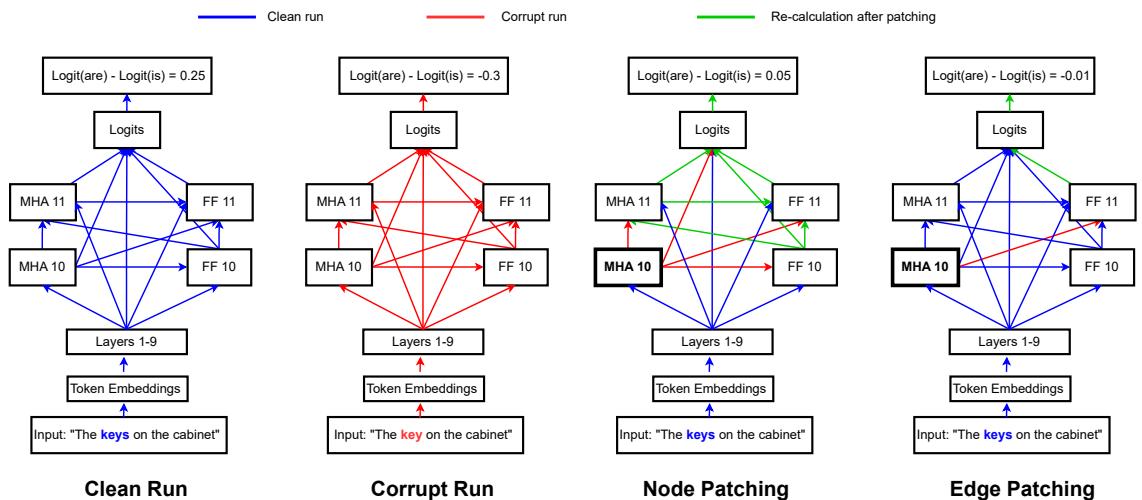
图 5: 节点与边修补示例,说明局部干预如何定位因果组件 (主谓一致性实例) 。
注意事项
- 分布外风险 (OOD) : 激活替换为任意向量可能令模型处于不合理状态。重采样或平均消融可降低风险。
- 粒度关键 : 整神经元修补假设局部表征;子空间修补 (DII/DAS) 揭示分布式编码。
代表进展
- 激活修补与路径修补 (忠实但计算量大) 。
- ACDC、EAP、EAP-IG (更自动化、可扩展的节点/边定位) 。
- Patchscope: 将激活修补到目标模型+提示中,解码其表示含义。
4.3 稀疏自编码器 (SAE)
解决问题 : 叠加 (superposition) ——模型编码的特征数量超过其神经元数,导致神经元多义。
思想 : 训练一个自编码器,将模型激活 \(h\in\mathbb{R}^d\) 映射到高维稀疏向量 \(f(h)\in\mathbb{R}^s\) (其中 \(s>d\)) ,再解码回原来空间以重构 \(h\)。稀疏性惩罚促进单义单元形成。
典型训练损失:
\[ \mathcal{L}(h,\hat h) = \frac{1}{|\mathcal{X}|}\sum_{X\in\mathcal{X}}\Big(\|h(X)-\hat h(X)\|_2^2 + \lambda \|f(h(X))\|_1\Big) \]优点
- 揭示原本叠加纠缠的特征。
- 提供候选特征字典,支持开放式特征发现。
注意事项
- 稀疏性与重构保真度间存在权衡。
- 可解释性评估需人工标注或 LLM 打分;SAE 特征未必被模型实用化。
- 新变体 (TopK、JumpReLU、Gated SAE、Matryoshka) 改善稀疏—保真度平衡,或发现层次化特征。
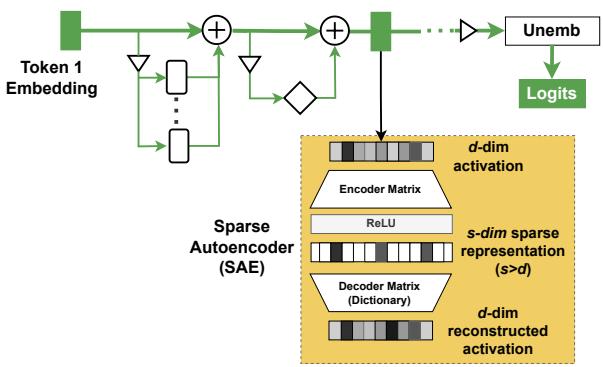
图 6: SAE 架构示意: 编码器 → 稀疏 s 维表示 → 解码器重构为 d 维。
4.4 探测与可视化 (重要但有限)
- 探测 (Probing) : 在激活上训练分类器 (通常为线性) 来检测预设属性。快速且信息丰富,但仅体现相关性。
- 可视化工具 : 注意力热图、词元高亮、仪表盘 (如 CircuitsVis、Neuronpedia) 可辅助形成假设,但需用因果方法验证。
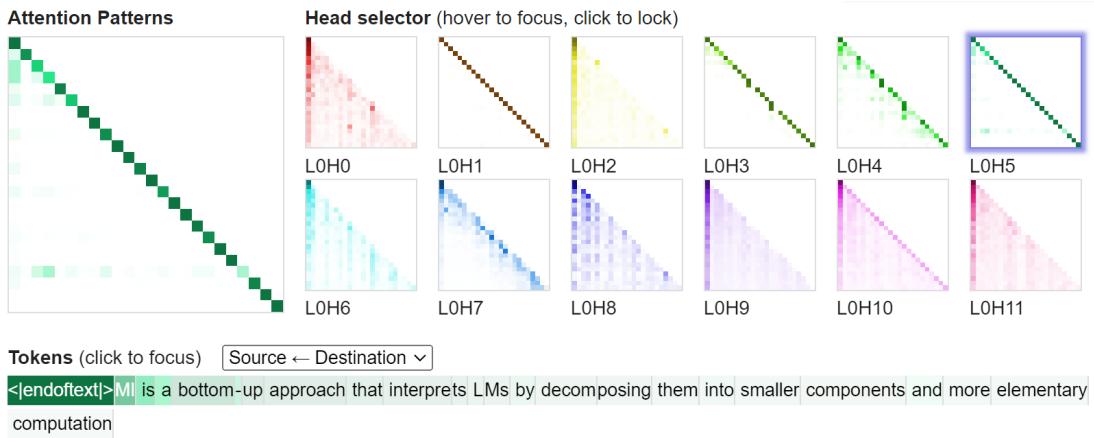
图 8: 注意力可视化界面示例,展示不同注意力头及其关注模式。
这些技术及其权衡的简表可见于综述图表 2。
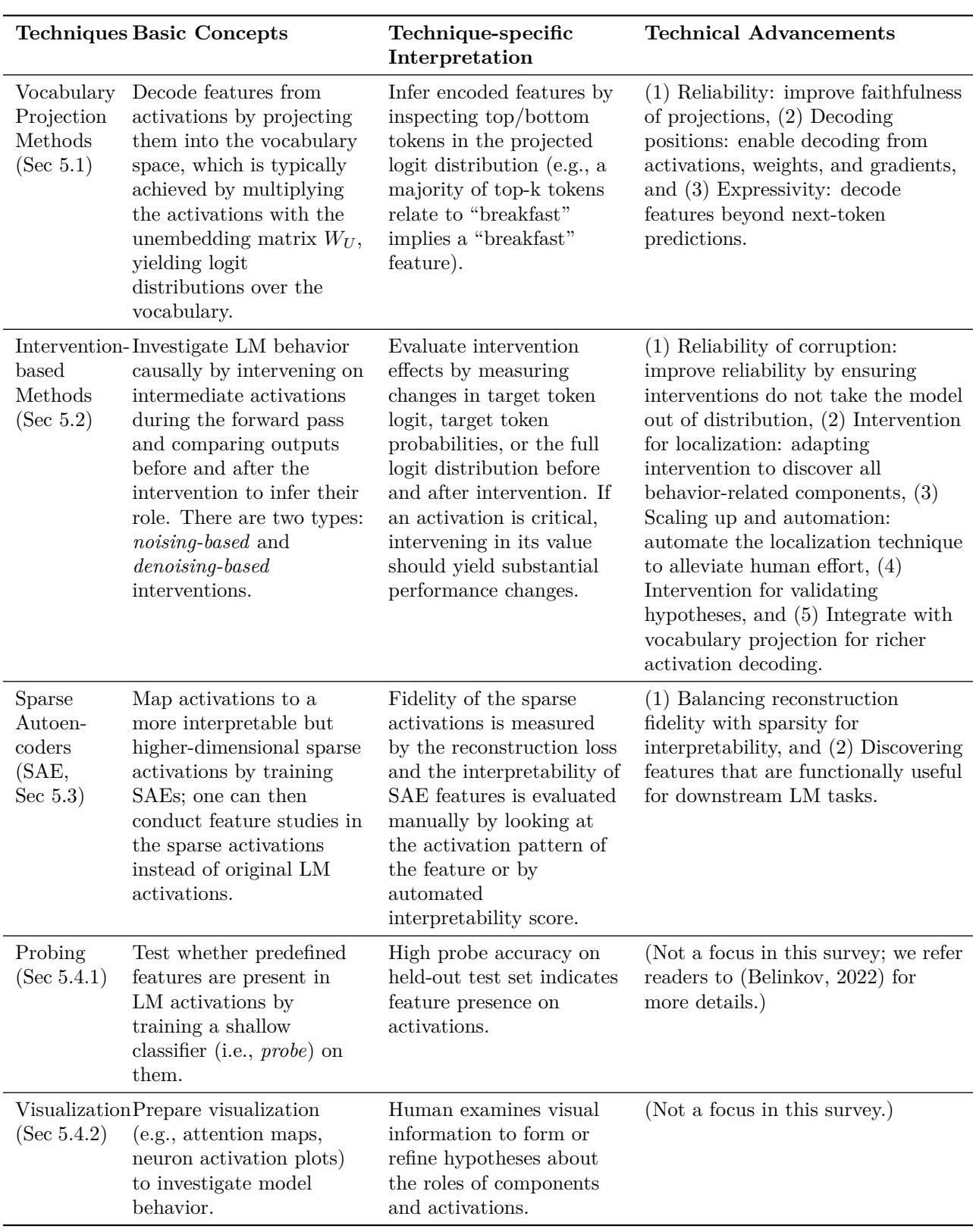
图 (表) : 技术概览——logit lens、干预、SAE、探测与可视化的优缺点。
5. 初学者任务中心 MI 路线图
该综述的核心实践贡献是“初学者路线图”,按任务 (特征、回路、普遍性) 组织 MI 研究,提供可执行的工作流。以下为简化可操作版。
5.1 特征研究——两条路径
特征研究问: “这个激活编码了什么?”
路径 A: 目标特征研究 (已有假设)
- 假设生成 : 选择特定特征 (如“是 Python 代码”、“含人名”) 。
- 假设验证 :
- 探测 (训练探针) ——若有标注数据,效果佳。
- Patchscope / DII / DAS——当怀疑特征存在于子空间或需因果证据时使用。
- 评估 : 测量探针准确率、干预效应幅度或 DAS 对齐度。记住探针仅揭示相关性;因果需修补验证。
路径 B: 开放特征发现 (无先验假设)
- 观察 :
- 使用 logit lens / tuned lens 查看某表示偏向的候选词元。
- 可视化神经元或 SAE 特征激活,收集高激活上下文。
- 训练 SAE 提取潜在单义特征。
- 解释 :
- 由人工标注员或 LLM 解释器将特征映射为自然语言描述。可混合: LLM 提标签,人类复核。
- 评估 :
- 忠实性 : 重构损失、修补/导向实验 (操纵特征是否改变输出?) 、探针表现。
- 可解释性 : 人工或 LLM 打分的一致性。
辅助界面
- 早期神经元标注界面展示高激活片段与促发词元 (有助发现 base64 或语言相关神经元) 。
- Neuronpedia 与 SAE 仪表盘整合诊断工具 (激活直方图、顶级词元、导向测试、自动解释) ,降低人工工作量。

图 10: 示例界面展示一个对 base64 类词元强激活的神经元。
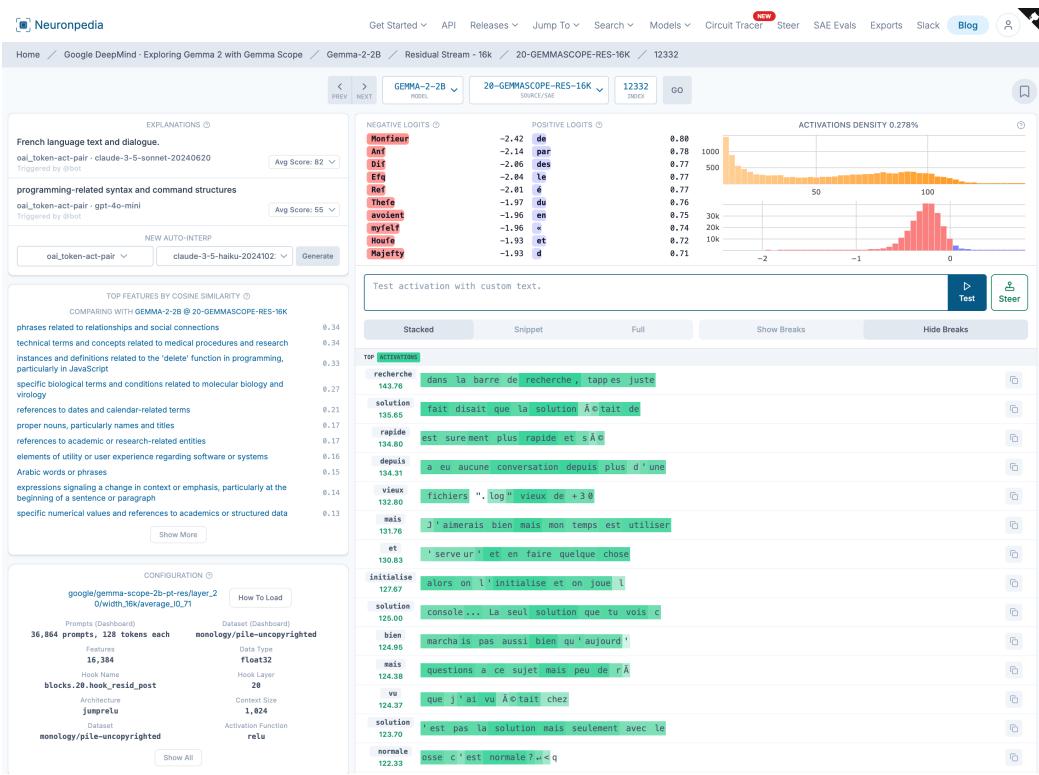
图 11: Neuronpedia 式仪表盘,用于特征解释,含自动解释与导向测试。
5.2 回路研究——发现路径
回路研究问: “哪个子图实现了这种行为,如何实现?”
- 选择明确稳定的模型行为 (在数据集上表现优异) ,例: IOI、算术、归纳序列补全。
- 定义计算图 :
- 指定节点 (注意力头、FF 输出、SAE 特征) 与边 (残差流连接) ,粒度影响可解释性与成本。
- 定位 :
- 用激活修补与路径修补测量必要性与充分性。
- 需规模化时用自动化工具 (ACDC、EAP-IG) 。
- 解释 :
- 结合可视化与词汇投影生成假设。
- 以目标干预验证假设 (例如,消融是否移除预期效应) 。
- 评估 :
- 忠实性 : 子回路是否复现行为?
- 最小性 : 组件是否必要?
- 完整性 : 在真实扰动下,回路是否涵盖所有贡献组件?
示例: GPT-2 small 中的 IOI 回路
- 定义注意力头为节点的、位置相关计算图。
- 路径修补定位,“名称移动头”复制正确实体。
- 验证假设: 测量复制率,用 logit lens 检查 OV 输出,高前 5 词元召回率证实复制功能。
5.3 普遍性研究——发现的通用程度
流程
- 定义范围: 研究特征或回路?
- 选择变量维度: 模型规模、架构、种子、数据。
- 跨模型进行特征/回路分析,比较结果:
- 特征普遍性 : 在共享数据集上比较激活向量 (皮尔逊相关或最近邻匹配) 。
- 回路普遍性 : 检查功能等效组件与算法相似性 (如不同模型是否实现相同 Name Mover 模式) 。
- 评估 : 相似度分布、重叠指标与算法等效的定性分析。
实证发现
- 神经元层面的特征普遍性有限 (跨种子仅 1–5%) ,但 SAE 派生特征在部分研究中表现出更好跨模型对齐。
- 部分组件 (如归纳头) 反复出现,而其他回路随初始化与训练不同而变化。
6. 案例研究——将路线图付诸实验
文献中的几个典型例子展示了路线图的实际应用。
- 目标探测示例 (Gurnee 等)
- 假设 : “是法语文本”特征存在于 FF 激活中。
- 流程 : 建立标注数据 → 提取激活 → 训练带自适应阈值的稀疏探针 → 用 F1/精确率/召回率评估 → 跨层和模型测试普遍性。
- 开放 SAE 示例 (Bricken 等)
- 无假设发现于玩具模型。
- 流程 : 训练 SAE → 在界面展示顶级激活、词汇投影与导向 → 人工标注特征并评估解释性。
- IOI 回路示例 (Wang 等,2022)
- 选择 IOI 任务 → 定义注意力头构成的图 → 用路径修补定位节点与边 → 结合注意图与 logit lens 探针,解释头为名称移动器与抑制器 → 验证忠实性与最小性。
7. MI 的主要发现 (现阶段总结)
一些反复出现的发现与主题:
- 神经元常为多义性;特征多分布或叠加,而非孤立单元。
- 叠加假说 : 模型可用线性组合编码超过神经元数的特征。
- SAE 揭示许多似单义特征,但其忠实性与功能重要性仍待验证。
- 注意力头往往有专职角色 (复制、归纳、检测、抑制) ,且特定任务可发现多个由头+FF 构成的回路。
- FF 子层常充当“键值存储”: 首矩阵生成键,次矩阵存值并投射为 logits。
- 归纳头等结构在不同模型与尺度中反复出现;其他回路则随初始化与训练细节变化。
- 训练动态 : 相变与“顿悟” (grokking) 现象常对应新回路形成。
- 应用包括模型导向、去偏 (消除伪特征) 与安全监控 (检测潜空间中与安全相关方向) 。
综述中的神经元与回路表格总结了这些发现,详见原文图表。
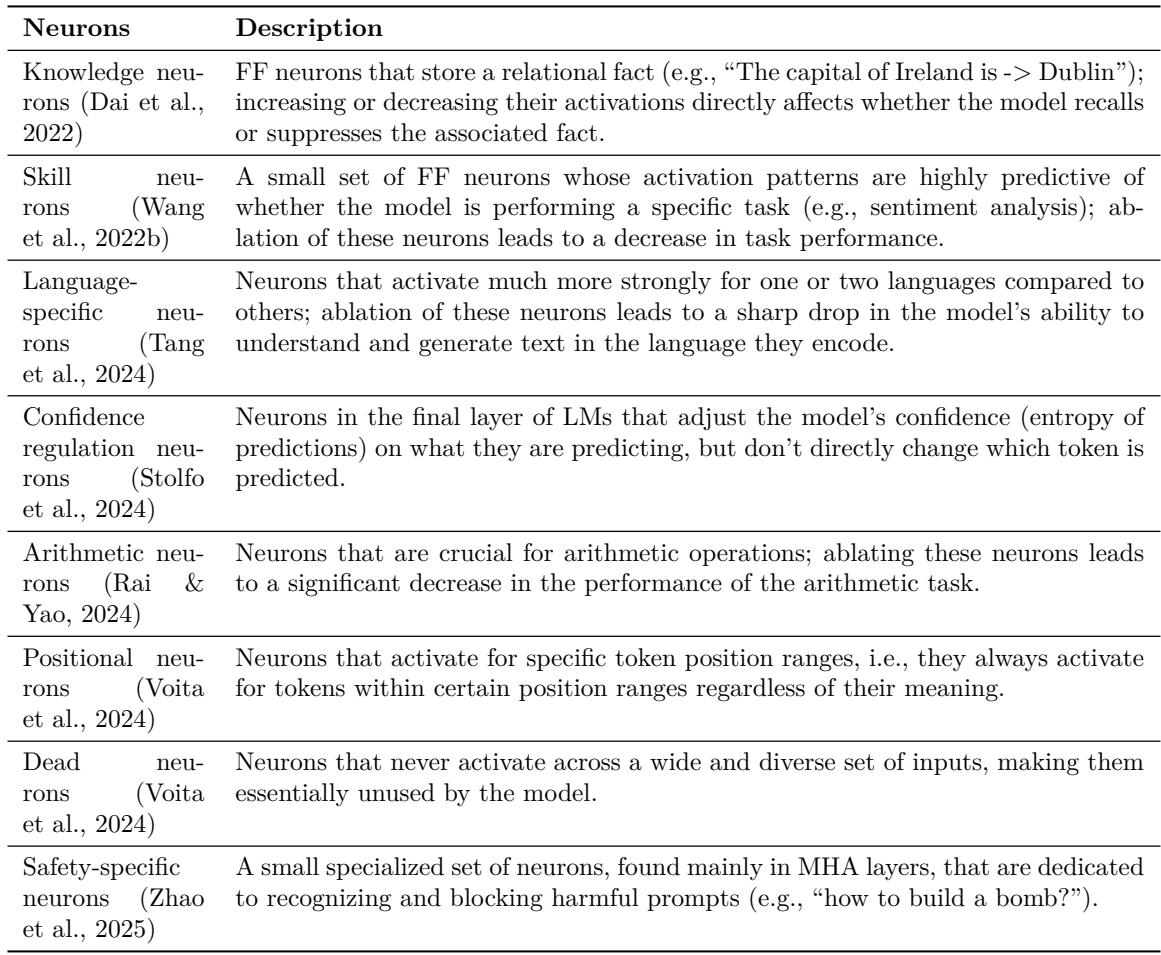
图 12: SAE 特征界面,展示用于评估与标注候选特征的诊断信息。
8. 评估、陷阱与最佳实践
模型解释极具挑战,下列建议基于综述总结与社区经验:
- 用因果方法支撑因果主张 。 探针证明“存在”,干预证明“使用”。
- 修补激活时警惕 OOD 效应——重采样消融或均值消融较零/随机消融更稳健。
- 精心选粒度——粗粒计算图 (层级组件) 廉价但可遗漏位置依赖行为;细粒揭示细节但成本更高。
- 多法交叉验证 : 词汇投影 + 干预 + SAE 联合降低误判。
- 注重自动化 : EAP-IG、ACDC 加速定位,但需用因果测试核实自动结果。
- 双轴评估可解释性 : 忠实性 (机制是否因果驱动行为) 与可理解性 (人类能否稳定标注与推理) 。
- 利用合成基准 (如 Tracr) 验证工具链 , 并在自然模型上检验——合成成功不保证真实通用性。
9. 开放挑战与未来方向
MI 综述揭示若干兼具技术深度与实践意义的开放问题:
- 可扩展性 : 如何在有限算力下扩展忠实回路发现与 SAE 训练到十亿级参数模型?
- 假设生成自动化 : 探索主要靠人类直觉;半自动化、人机协同的假设生成可加速研究。
- 忠实性评估 : 现有基准 (Tracr、RAVEL、MIB、SAEBench) 有用,但需统一、可泛化的忠实性、完整性与可解释性指标。
- SAE 局限 : 更优架构、层次字典 (Matryoshka SAE) 、端到端训练以连接特征检测与行为影响是前沿方向。
- 从特征到命题 : 解码更高级语义 (如“我支持 X”) 或许更契合安全需求。
- 实用性 : 从描述发现转向可用于模型对齐、鲁棒性或编辑的工具仍是活跃前沿。
10. 实践清单——开启你的 MI 研究
若你打算今天下午即可开展 MI 实验,这里有一份简明清单:
- 选择一个明确的行为 (高准确率任务) 或聚焦的特征问题。
- 选择能孤立该行为的模型与数据集。
- 决定计算图粒度 (头、FF、SAE 特征) 。
- 通过可视化、logit lens 或初步探测生成假设。
- 用因果干预定位 (节点/边修补、路径修补) ,必要时用 EAP-IG/ACDC 自动化。
- 结合词汇投影与目标性干预解释组件。
- 评估忠实性 (干预是否恢复行为) 、最小性 (组件是否必要) 与完整性。
- 记录并共享数据集、脚本与修补流程。可复现性在 MI 研究中至关重要。
可解释性机理已从一系列探索性技术成长为成熟、任务中心化的工具箱。本文所依据的综述是该领域的优秀地图: 它不宣称问题被彻底解决,但为新手提供了结构化路径——如何提出好问题、选择合适工具并严格评估主张。若你是一名希望理解、调试或对齐语言模型的学生、研究员或从业者,MI 提供语言与方法,帮助你让不透明的模型逐步变得透明——一次一个回路。