](https://deep-paper.org/en/paper/2407.02987/images/cover.png)
引言
大型语言模型 (LLM) 的快速演进带来了能力出众的对话助手、编程伙伴和创意写作者。然而,这种能力伴随着一个显著的隐患: 如果没有仔细的对齐,这些模型可能会生成有毒、冒犯性或非法的内容。虽然“安全微调” (如基于人类反馈的强化学习) 有所帮助,但它并非灵丹妙药。“越狱” (Jailbreaks) ——旨在绕过安全过滤器的精心设计的提示词——仍然是一个持续存在的威胁。
为了应对这一问题,业界转向了护栏 (guardrails) : 即独立的专用模型,用于监控对话并标记有害内容。问题在于?运行一个巨大的 LLM 本来就在计算上非常昂贵。仅仅为了监管第一个模型而运行第二个巨大的模型通常是不可能的,尤其是在手机或笔记本电脑等资源受限的设备上。
这造成了一个两难境地: 我们是为了效率而牺牲安全性,还是将强大的 AI 限制在巨大的服务器农场中?
在三星英国研发中心 (Samsung R&D Institute UK) 最近的一篇论文中,研究人员提出了一种优雅的解决方案,称为 LoRA-Guard 。 通过利用参数高效微调 (Parameter-Efficient Fine-Tuning) ,特别是低秩自适应 (LoRA) ,他们创建了一个将内容审核直接集成到聊天模型中的系统。结果是一个护栏系统,与现有解决方案相比,其参数开销减少了 100-1000倍 , 使得稳健的端侧审核成为现实。
背景: 安全的代价
在深入了解 LoRA-Guard 的架构之前,有必要了解 LLM 安全的现状以及这篇论文所解决的具体瓶颈。
对齐的局限性
标准的 LLM 经历了海量文本语料库的预训练,随后是指令微调和安全对齐。尽管如此,模型表现得像“随机鹦鹉”——它们会被欺骗。攻击者使用角色扮演 (“扮演一个反派……”) 、加密 (用摩尔斯电码或 Base64 编码提示词) 或逻辑干扰等策略来绕过安全训练。这使得外部验证步骤变得必要。
护栏模型问题
业界的标准应对措施是部署一个护栏模型 (Guard Model) (如 LLaMA-Guard) 。这是一个专门微调用于将文本分类为安全或不安全的独立 LLM。
在服务器环境中,这是可控的。你先将用户的提示词传输给护栏模型。如果通过,再发送给聊天模型。然而,对于端侧 AI , 内存是稀缺的。如果你的手机加载一个 80 亿参数的聊天模型都很吃力,它肯定无法同时加载另一个独立的 80 亿参数的护栏模型。这种冗余是低效的,因为聊天模型和护栏模型共享许多相同的基础知识——它们都理解英语语法、语义和概念。
LoRA (低秩自适应) 登场
LoRA 最初是为高效微调而设计的技术。LoRA 不会在训练期间更新巨大神经网络中的所有权重,而是冻结预训练权重。然后,它向每一层注入一对小的、可训练的秩分解矩阵。
从数学上讲,如果某层具有权重 \(W\),LoRA 会添加一个小的更新 \(\Delta W\),计算为 \(B \times A\),其中 \(B\) 和 \(A\) 是非常窄的矩阵。由于 \(B\) 和 \(A\) 很小,可训练参数的数量大幅下降,通常降至原始模型大小的 1% 以下。
LoRA-Guard 方法
LoRA-Guard 的核心创新在于意识到我们不需要一个独立的模型来保证安全。我们可以利用聊天模型自身对语言的理解来监管自己,利用 LoRA 仅在需要时将其引导至审核任务。
双路径架构
LoRA-Guard 采用了双路径设计 。 它将 LLM 视为骨干,具有两种截然不同的操作模式,这两种模式共享绝大多数参数。
- 生成路径 (Generative Path) : 这是标准的聊天模式。输入经过冻结的 Transformer 权重 (\(W\)) ,并通过标准的语言建模头输出以生成回复。
- 守护路径 (Guarding Path) : 这是安全模式。输入经过相同的冻结 Transformer 权重 (\(W\)) ,但在 LoRA 适配器 (\(\Delta W\)) 的作用下并行运行。输出不路由到语言头,而是路由到一个专门的分类头 , 该头输出有害性评分。
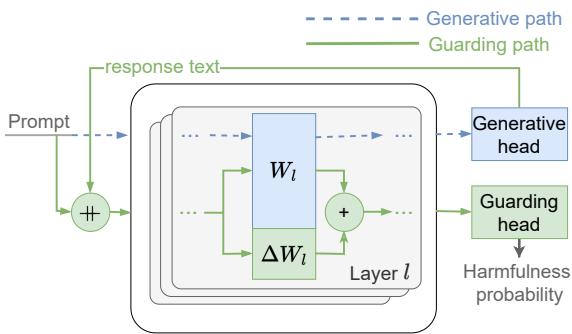
如上图 1 所示,该架构允许一种“切换”机制。
- 当用户输入提示词时,系统激活守护路径 (绿线) 。模型计算安全评分。
- 如果提示词安全,系统切换到生成路径 (蓝色虚线) 。适配器被停用,模型使用其原始、未更改的权重生成回复。
- 最后,系统可以切换回守护路径,在向用户显示之前检查模型自己的回复。
为什么这很巧妙
这种设计同时解决了两个主要问题:
- 内存效率: 由于守护路径与生成路径共享主 Transformer 权重 (\(W\)) ,你只需将微小的 LoRA 适配器和分类头加载到内存中。这消除了对第二个千兆字节级模型的需求。
- 性能保留: 为安全微调模型的一个常见问题是“灾难性遗忘”——模型过于专注于安全,以至于失去了创造性聊天的能力。在 LoRA-Guard 中,基础权重 (\(W\)) 是冻结的 。 生成路径与原始模型完全相同,确保聊天质量零降级。
训练策略
研究人员使用 BeaverTails-30k 数据集训练了 LoRA 适配器和分类头,该数据集包含标有 14 类危害 (如仇恨言论、暴力、金融犯罪) 的提示词-回复对。
训练期间使用的损失函数是两个目标的组合:
- 二元分类: 内容是安全还是不安全?
- 多标签分类: 存在哪些具体的危害类别 (如果有) ?
至关重要的是,LoRA 适配器仅应用于注意力机制中的查询 (Query) 和键 (Key) 投影矩阵,使参数数量保持在极低的水平。
实验与结果
研究人员使用 LLaMA-3 变体 (1B、3B 和 8B 参数) 作为基础模型评估了 LoRA-Guard。他们将性能与最先进的基线进行了比较,包括 LLaMA-Guard-3 (全尺寸的独立模型) 。
效率与有效性
最显著的结果是模型大小与检测能力之间的关系。
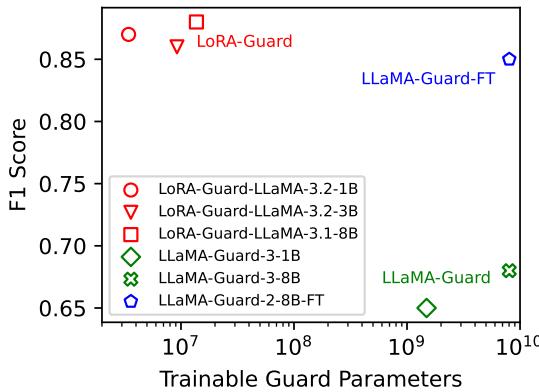
图 2 展示了效率上的突破。X 轴代表可训练护栏参数的数量 (对数刻度) ,而 Y 轴显示 F1 分数 (准确性的度量) 。
- 最右侧的绿色标记代表传统的护栏模型 (LLaMA-Guard) 。它们需要数十亿个参数。
- 最左侧的红色标记代表 LoRA-Guard 模型。
请注意,LoRA-Guard 模型获得了相似的、在某些情况下甚至更优的 F1 分数,同时使用的参数数量减少了几个数量级 。 具体来说,参数开销减少了 100 到 1000 倍。对于移动开发者来说,这就是一个能运行的应用程序和一个会让手机崩溃的应用程序之间的区别。
详细的危害检测
该系统不仅擅长二元的“安全/不安全”切换;它在对特定类型的危害进行分类方面也很有效。
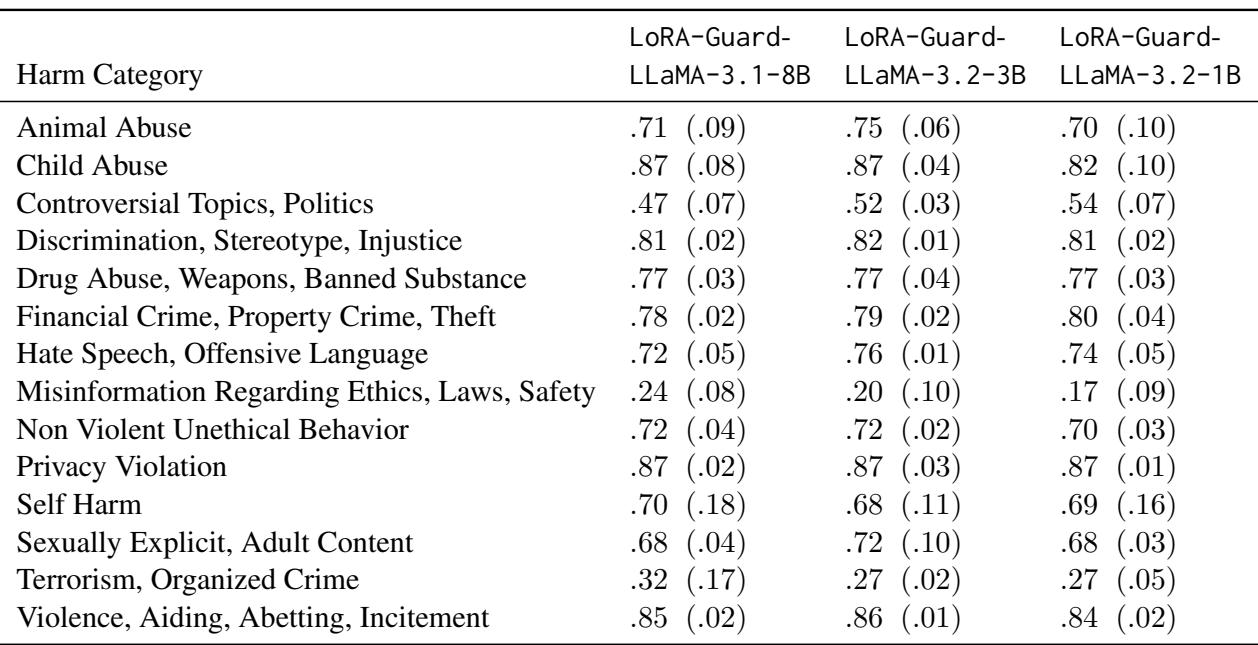
表 2 (上图) 按类别细分了性能。该模型在检测诸如暴力、虐待儿童和侵犯隐私等明确危害方面表现出高熟练度 (AUPRC > 0.8) 。
然而,查看假阳性率 (FPR) 同样重要。一个将所有内容都标记为不安全的护栏会让模型变得无法使用。
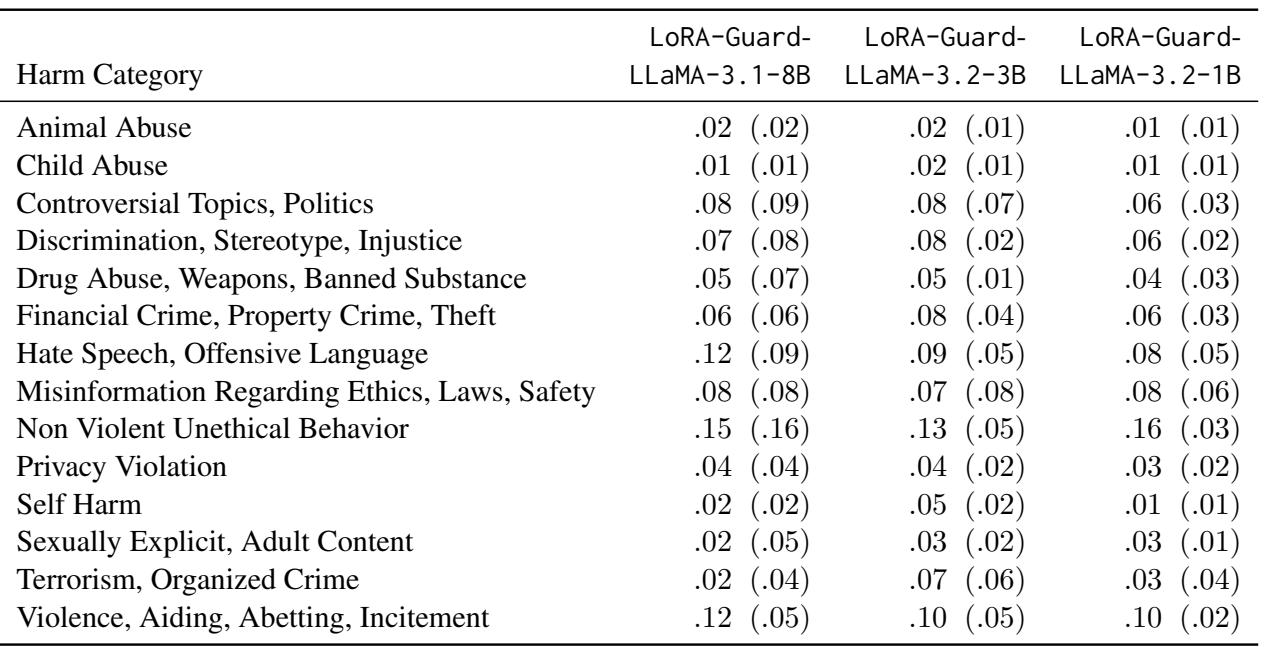
如表 3 所示,特定类别的假阳性率仍然非常低 (大部分低于 5-8%) 。这表明该模型是精确的: 当它将某事标记为“暴力”时,那很可能确实是暴力。
分布偏移的挑战
没有模型是完美的。研究人员在“分布外”数据上测试了 LoRA-Guard——这些数据集看起来与训练数据集不同。他们使用了 ToxicChat , 这是一个包含现实世界用户对话的数据集,其中通常包含俚语、微妙的毒性或越狱尝试。
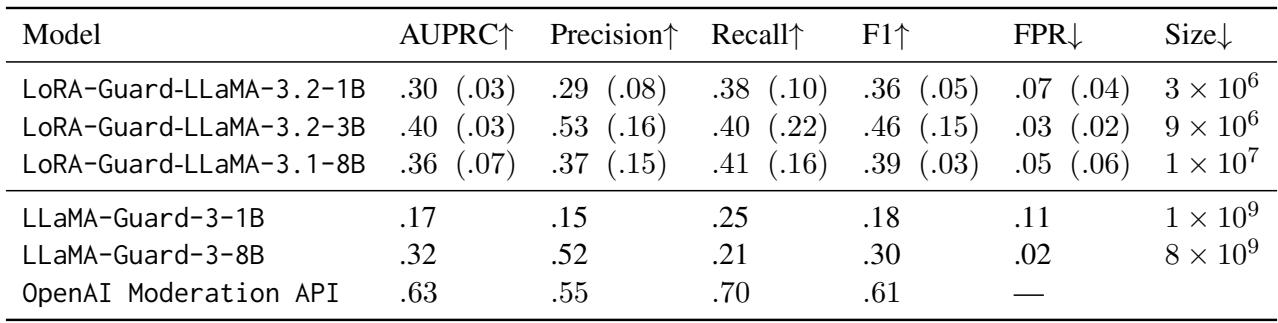
表 5 揭示了几乎所有当前安全模型共有的局限性。当从训练数据 (BeaverTails) 转移到更狂野的 ToxicChat 数据集时,性能显著下降。虽然 LoRA-Guard 在这项任务上与大得多的 LLaMA-Guard-3 相比具有竞争力,但与 OpenAI Moderation API 相比,所有模型都表现挣扎。这强调了虽然架构 (LoRA-Guard) 是高效的,但用于训练的数据仍然需要多样化和全面,以应对现实世界的不可预测性。
结论与启示
LoRA-Guard 代表了安全 AI 实际部署向前迈出的重要一步。通过使用低秩适配器将“守护”能力与“生成”能力解耦,研究人员证明了安全性不一定以巨大的计算资源为代价。
关键要点:
- 巨大的效率提升: LoRA-Guard 使得内容审核所需的活跃参数比独立护栏模型少 100-1000 倍。
- 无性能惩罚: 由于基础模型被冻结,聊天能力与原始模型完全保持一致。
- 端侧可行性: 这种架构对移动和边缘计算特别有影响,在这些场景下加载第二个模型是不可能的。
对于进入该领域的学生和研究人员来说,这篇论文强调了参数高效微调 (PEFT) 的价值,不仅在于让模型适应新任务,还在于架构能够高效多任务处理的系统。随着我们迈向在设备上本地运行的 AI 智能体,像 LoRA-Guard 这样的技术可能会成为确保这些智能体既有帮助又无害的标准。