](https://deep-paper.org/en/paper/2407.06322/images/cover.png)
大型预训练模型——如 CLIP、GPT 和 ViT——已成为现代人工智能的支柱,实现了几年前还无法想象的成果。然而,这些系统都有一个根本性的弱点: 它们是静态的。一旦在庞大但固定的数据集上完成训练,它们就难以在不丢失已学知识的情况下吸收新信息。这种现象被称为 灾难性遗忘 , 它阻碍了真正自适应和智能系统的发展。
想象一下,你教一个 AI 模型识别鸟类。它能完美识别知更鸟和麻雀。但当你随后训练它识别鱼类时,它却“忘记”了如何辨别知更鸟。这种新旧学习之间的冲突正是 持续学习 (Continual Learning, CL) 的核心挑战: 让模型在吸收新知识的同时,仍能保留已学的内容。
传统的持续学习方法试图在训练过程中防止遗忘——要么通过正则化保持重要权重稳定,要么通过重放旧数据 (这会引发隐私问题) 。然而,Marczak 等人近期发表的题为 《MAGMAX: 利用模型合并实现无缝持续学习》 的研究提出了一种全新的思路。 MAGMAX 并不在训练阶段与灾难性遗忘“对抗”,而是专注于在训练结束之后合并和巩固知识。其策略结合了顺序微调和基于 最大幅度选择 的巧妙模型合并技术,在多个持续学习基准中达到了最先进的性能。
让我们来拆解这一突破背后的关键理念。
背景: 持续学习的组成要素
在深入了解 MAGMAX 之前,先来理解一些基础概念。
持续学习的设置
在持续学习中,模型会依次遇到一系列任务 \( \{D_1, D_2, \ldots, D_n\} \),并逐个学习它们。在训练任务 \(D_t\) 时,模型只能看到当前任务的数据——不会重放或重新访问过去的任务。这种情况被称为 *无样本 (exemplar-free) * 场景,适用于由于隐私或存储限制无法保留旧数据的应用。
目标是生成一个在所有已学任务上表现良好的单一模型。
微调策略
当调整一个具有初始参数 \( \theta_0 \) 的大型预训练模型 (LPM) 时,有两种常见的微调方式:
- 独立微调 (Ind FT) : 每个任务都从相同的预训练权重 \( \theta_0 \) 开始,分别训练出独立的任务特定模型。
- 顺序微调 (Seq FT) : 每个新任务建立在前一个任务的模型之上——即任务 \(D_t\) 的训练从 \( \theta_{t-1} \) 开始。这样可以在任务间迁移知识,但通常会导致灾难性遗忘。
任务向量与模型合并
模型合并是迁移学习与持续学习中备受关注的概念。它不重新训练模型,而是结合不同模型所学习到的更新。这些更新通过 任务向量 表示:
\[ \tau_i = \theta_i - \theta_0 \]每个任务向量表示模型在学习任务 \(D_i\) 时权重的变化。通过合并多个任务的向量,我们可以创建一个同时具备这些任务知识的新模型——无需再次训练。诸如简单平均或加权插值等策略已有尝试,但由于参数更新冲突常造成性能下降。
MAGMAX 的动机
MAGMAX 的研究者提出了两个关键假设来指导他们的方法。
假设 1: 最大的变化最关键
在微调过程中,部分参数变化剧烈,而另一些几乎未变。研究人员假设, 高幅度变化 对任务最为重要。
为验证此观点,他们微调模型并对任务向量进行剪枝,仅保留部分参数——要么是幅度最高的 (“top‑k”) ,要么是幅度最低的 (“bottom‑k”) ,要么是随机选取的。
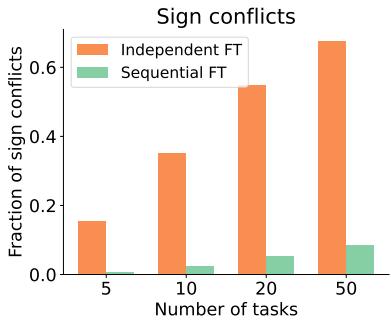
图 2: 仅保留 20% 幅度最高的参数,其性能几乎与完整微调相同,证明较大的参数更新最具影响力。
结果非常明确: 仅保留 20% 幅度最高的参数,准确率与使用全部参数几乎一致;相反,随机或低幅度选择则需要更多参数才能达到类似效果。这验证了 大的权重更新捕捉了任务学习的核心 。
假设 2: 顺序微调可减少冲突
合并不同任务训练的模型时,参数可能发生冲突——某些任务会增加某个权重,而另一些则会减少它。这些 符号冲突 会造成干扰,降低合并性能。
作者假设,顺序微调 自然能减少这些冲突,因为不同任务间的更新趋于一致。
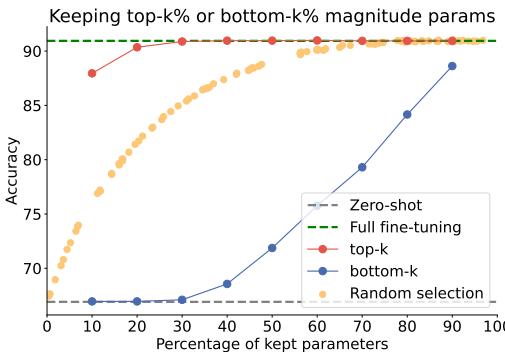
图 3: 顺序微调产生的参数符号冲突显著少于独立微调,使模型更容易合并。
实验验证了这一点: 顺序微调始终能产生更协调的、符号冲突更少的任务向量。
MAGMAX 方法: 最大幅度合并
基于这些见解,研究者提出了 MAGMAX——一个两步式持续学习算法,结合顺序微调与最大幅度合并。
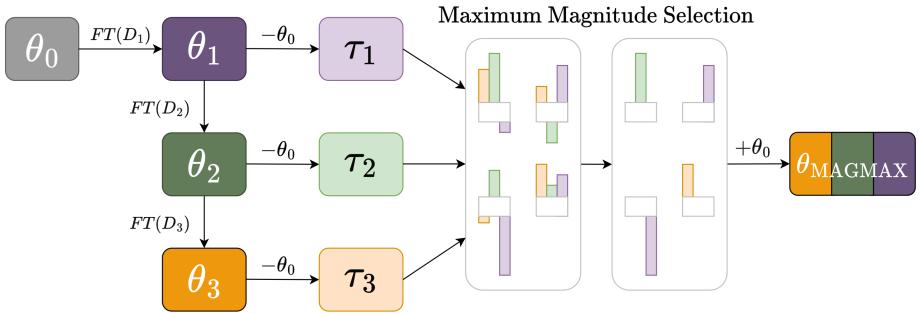
图 1: MAGMAX 概览。模型顺序地在多个任务上微调生成任务向量,再通过最大幅度策略合并成整合的多任务模型。
MAGMAX 学习新任务 \(D_t\) 的过程如下:
顺序适应: 模型以先前微调的权重 \( \theta_{t-1} \) 为起点,通过新任务的数据训练得到 \( \theta_t \)。
知识整合:
- 为已见任务建立任务向量: \( \tau_i = \theta_i - \theta_0 \),其中 \( i = 1, \ldots, t \)。
- 对于每个参数 \( p \),选择各任务向量中 绝对值幅度最大 的更新: \[ \tau^{p}_{MAGMAX} = \arg\max_i |\tau_i^p| \]
- 将合并后的任务向量按因子 \( \lambda \) 缩放并应用到原始预训练模型: \[ \theta_{MAGMAX} = \theta_0 + \lambda \cdot \tau_{MAGMAX} \]
在实现上,只需同时存储两个对象: 最新检查点 \( \theta_t \) 和持续更新的合并向量 \( \tau_{MAGMAX} \),从而保持恒定的内存占用并能高效扩展至更多任务。
实验: 检验 MAGMAX
作者在多个基准上验证了 MAGMAX——包括 CIFAR100、ImageNet-R、CUB200 和 Cars , 并与传统持续学习方法 (LwF、EWC) 以及合并基准 (Model Soup (Avg)、Task Arithmetic (TA)、TIES-Merging (TIES)) 比较。
类增量学习 (CIL)
每个新任务引入新的类别,模型必须在学习这些新类的同时保持先前类的性能。
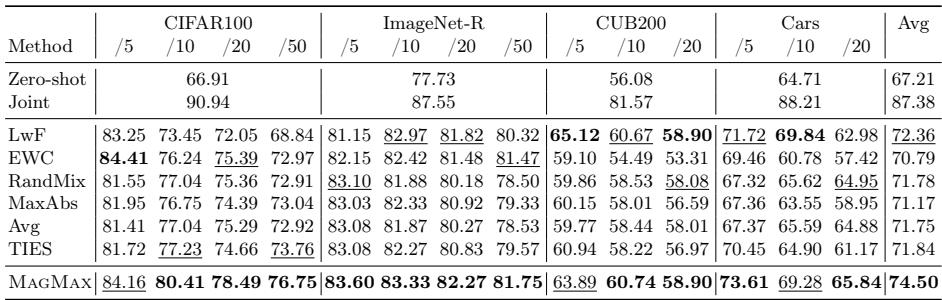
表 1: 在 CIFAR100、ImageNet-R、CUB200 和 Cars 数据集上,MAGMAX 取得了最佳或次佳性能,超越其他持续学习与模型合并方法。
在不同任务数量与数据集粒度下,MAGMAX 始终表现优异,平均准确率较次优方法提升 2.1%。简单基准如 ‘Avg’ 与 ‘RandMix’ 表现虽好,但仍不及 MAGMAX。
为分析 MAGMAX 如何应对遗忘,作者绘制了训练过程中的任务表现可视化。
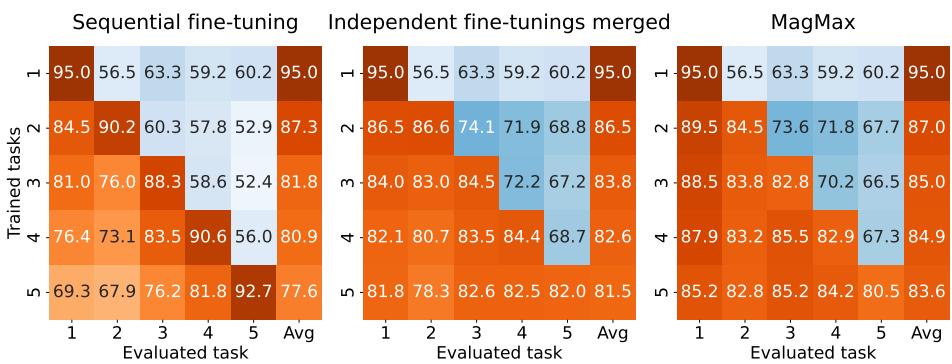
图 4: 顺序微调单独使用时遗忘严重 (左) ,独立合并有所改善 (中) ,MAGMAX 实现了最小遗忘与最高准确率 (右) 。
MAGMAX 在新任务上取得高性能的同时保留了早期任务的准确率,展示了出色的多任务保持能力。
域增量学习 (DIL)
在 DIL 中,任务共享类别但领域不同——如在素描、照片和绘画中识别同类物体。
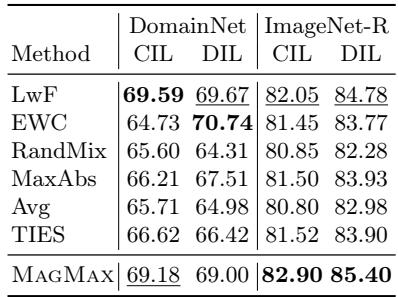
表 2: 在域增量场景中,MAGMAX 的性能优于其他基于合并的方法,与传统持续学习技术相当或更好。
MAGMAX 不仅在合并策略中领先,还能与传统持续学习技术比肩,显示出强大的跨领域适应性。
为什么最大幅度选择有效
研究者进一步分析了选择幅度最大的参数为何如此奏效。
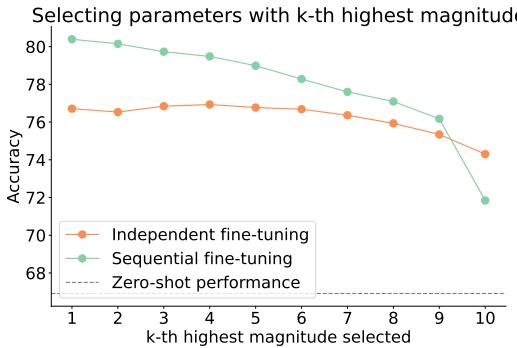
图 5: 选择绝对值最大的参数 (k=1) 在顺序微调中表现最佳。
在顺序微调中,选择最高幅度参数始终带来最佳结果;随着选择转向较小幅度 (k 值增大) ,准确率下降——这表明大的参数更新是有效学习的关键指标。
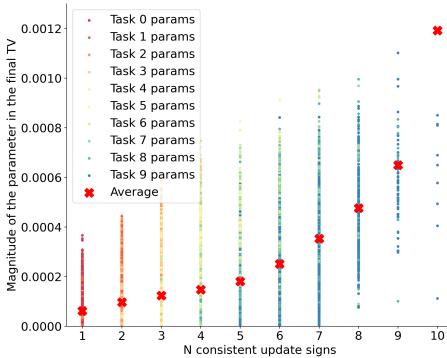
图 6 与图 7: 在任务间更新方向一致的参数具有更高幅度 (左) 。在合并时,后期任务向量贡献最大,因为它们累积了之前的知识 (右) 。
进一步实验发现:
- 在各任务间更新方向一致的参数幅度更高;
- 在顺序微调的合并过程中,后期任务向量贡献更大,证明知识随着任务进行逐步积累。
移除早期任务向量影响微乎其微,因为其信息已嵌入后期向量中。
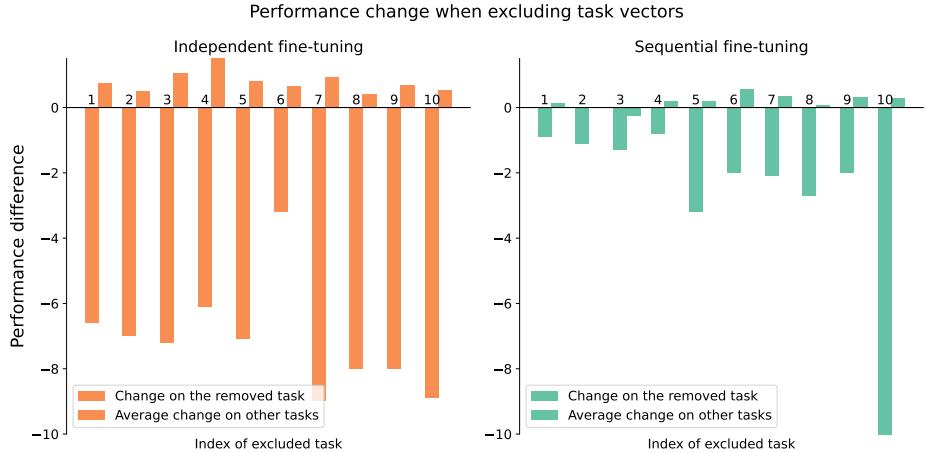
图 8: 顺序微调使模型在排除早期任务向量时仍保持稳健,证明后期阶段有效保留了知识。
扩展思路: 提升其他方法
MAGMAX 的两大原则——顺序微调与最大幅度合并——不仅自身有效,也能改进其他方法。
1. 模型合并增强现有持续学习技术
将 MAGMAX 的合并步骤应用于传统方法 (如 LwF 和 EWC) ,显著提高了它们的表现。
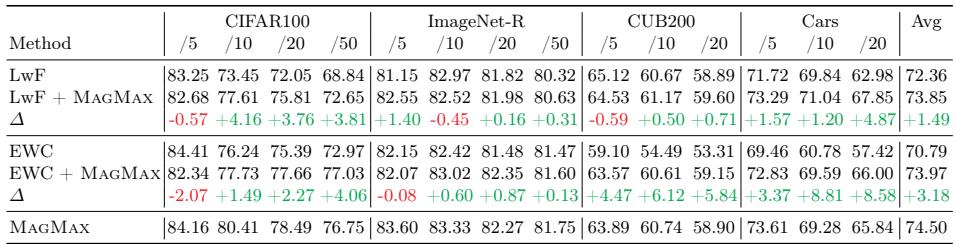
表 3: 整合 MAGMAX 合并步骤提升了基于正则化的持续学习方法 (LwF、EWC) ,表明合并能有效整合训练后的知识。
2. 顺序微调提升所有合并策略
将顺序微调与其他合并算法 (如 RandMix、Avg、TIES) 结合后,所有基准的表现均有所提升。
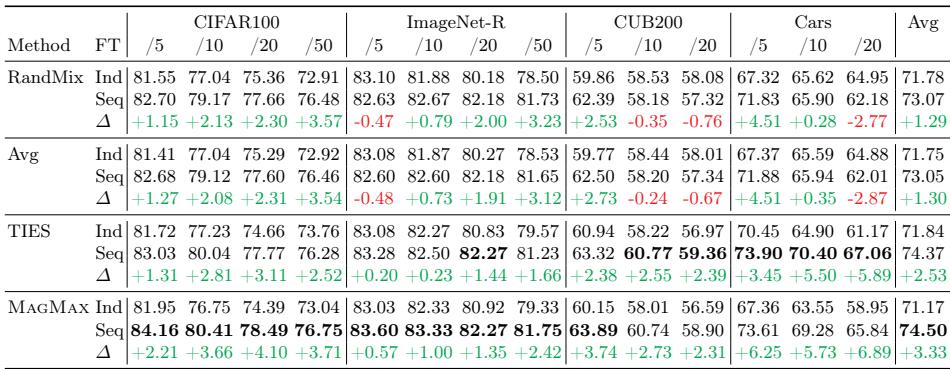
表 4: 顺序微调能持续改善各类合并策略的结果,凸显其普适性。
顺序微调与按幅度合并的协同效应普遍显著——即使任务间相似度极低亦如此。
结论: 终身学习的新路径
MAGMAX 以优雅的方式解决了一个延续数十年的难题。通过将关注点从训练过程中防遗忘转向训练之后知识整合,它重新定义了大型预训练模型的持续学习方式。
其成功由两大核心原则驱动:
- 顺序微调 : 对齐各任务间的更新,减少冲突,保持兼容性。
- 最大幅度选择 : 识别跨任务最重要且一致的参数变化。
通过这两项理念,模型能够自然地演进,而不丢失既有知识。
其意义远超本方法。MAGMAX 展示了 模型合并或将成为下一代持续学习系统的基石——具备简洁、高效与韧性。在探索 永不遗忘 的智能体之路上,MAGMAX 照亮了一条清晰而充满希望的前进方向。