](https://deep-paper.org/en/paper/2407.10385/images/cover.png)
像 GPT-4 这样的大型语言模型 (LLM) 已经征服了文本世界。它们能写诗、调试代码并总结历史。然而,物理世界并不总是用文字说话;它用传感器数据说话。
从智能手表中追踪步数的加速度计,到监测病人节律的心电图 (ECG) ,无处不在的传感技术产生了海量的数值数据流。将这些数据应用于 AI 的传统方法是直接将原始数字输入模型。但是,如果你曾试着阅读包含 10,000 行浮点数的电子表格,你就知道问题所在: 它令人难以招架,处理成本高昂,且难以解释。
在这篇文章中,我们将详细解读一篇引人入胜的论文,题为 “By My Eyes” , 它提出了一个范式转变。如果不强迫 LLM 阅读原始数字,而是让多模态 LLM (MLLM) 像看图片一样“看”数据,会怎么样?
问题所在: “数字之墙”
要理解为什么这项研究是必要的,我们首先需要看看 LLM 如何处理数值序列。直到最近,如果你想让 LLM 根据传感器数据对用户活动 (例如“走路”与“跑步”) 进行分类,你必须将该数据转换为文本提示。
想象一下以 100Hz (每秒 100 次) 采样的传感器读数。仅仅一分钟的数据就会产生数千个数字。将这些数据输入 LLM 会产生两个主要问题:
- Token 税 (The Token Tax) : LLM 是按“Token”收费的。一分钟的原始传感器数据很容易消耗 90,000 个 Token。这不仅速度极慢,而且对于实际应用来说,在经济上也是毁灭性的。
- 上下文限制 (The Context Limit) : LLM 的“上下文窗口”是有限的。如果输入数据太长,模型会“忘记”序列的开头或产生幻觉。
研究人员通过实验测试了这一局限性。他们要求 GPT-4o 对不同长度的序列执行简单的算术 (计算平均值) 和模式识别。
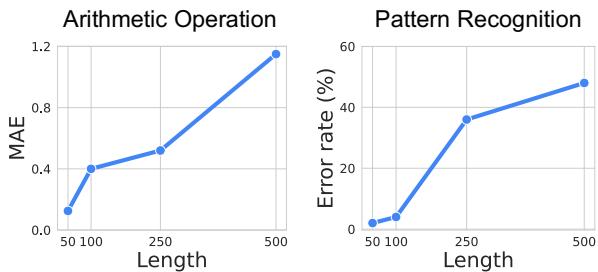
如上方的 图 2 所示,随着序列长度的增加,模型的性能会崩溃。对于模式识别 (右侧图表) ,一旦序列超过几百个数字,错误率就会飙升。模型实际上开始瞎猜了。
视觉解决方案
研究人员提出了一种称为 视觉提示 (Visual Prompting) 的方法。他们不是使用文本,而是将传感器数据转换为视觉图表 (图像) ,并将其提供给经过训练既能理解文本又能理解图像的 MLLM (如 GPT-4o) 。
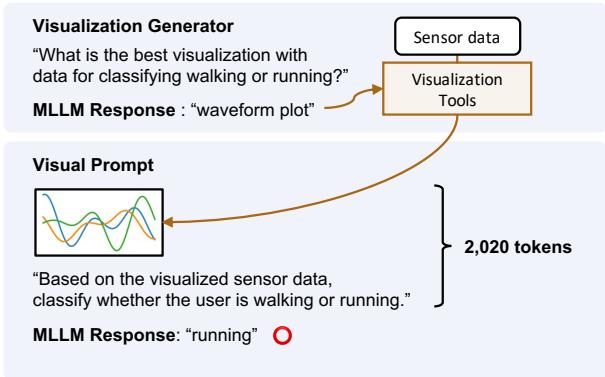
图 1 突显了巨大的差异。
- 基线 (文本) : 一个塞满原始数字 (
[0.65, 0.62, ...]) 的提示。它消耗了近 53,000 个 Token,而且在这个例子中,导致了错误的答案 (“walking”/走路) 。 - 提出的方法 (视觉) : 数据被转换为波形图。MLLM 观察波形的形状,仅使用 2,020 个 Token,并正确识别出活动为“running” (跑步) 。
这种转变在提高准确性的同时,将 Token 使用量减少了 15 倍以上。但这里有个关键点: 仅仅绘制折线图并不总是足够的。不同的传感器需要不同类型的可视化。这就引出了论文的核心创新。
核心方法: 可视化生成器
如果你是信号处理专家,你知道加速度计信号最好看作波形 , 但音频信号可能需要频谱图 (频率的视觉表示) 。MLLM 天生并不知道哪种可视化最适合特定的、未见过的任务。
为了解决这个问题,作者开发了一个 可视化生成器 (Visualization Generator) 。 该系统无需人类专家即可自动创建最佳图表。它分两个阶段工作:
第一阶段: 可视化工具筛选
首先,系统向 MLLM 展示一个可用绘图工具的“菜单” (来自 Matplotlib 或 SciPy 等库) 以及任务描述 (例如,“从 ECG 数据中检测心律失常”) 。
MLLM 将此列表筛选为几个可能的候选者。例如,如果任务涉及心率,它可能会选择“ECG 独立心跳图”和“原始波形”,但舍弃“频谱图”。
第二阶段: 可视化选择 (自我反思)
这是最巧妙的部分。系统使用第一阶段确定的所有候选方法生成图表。然后,它将这些图像反馈给 MLLM 并询问: “这些图像中哪一个最容易让人看清模式?”
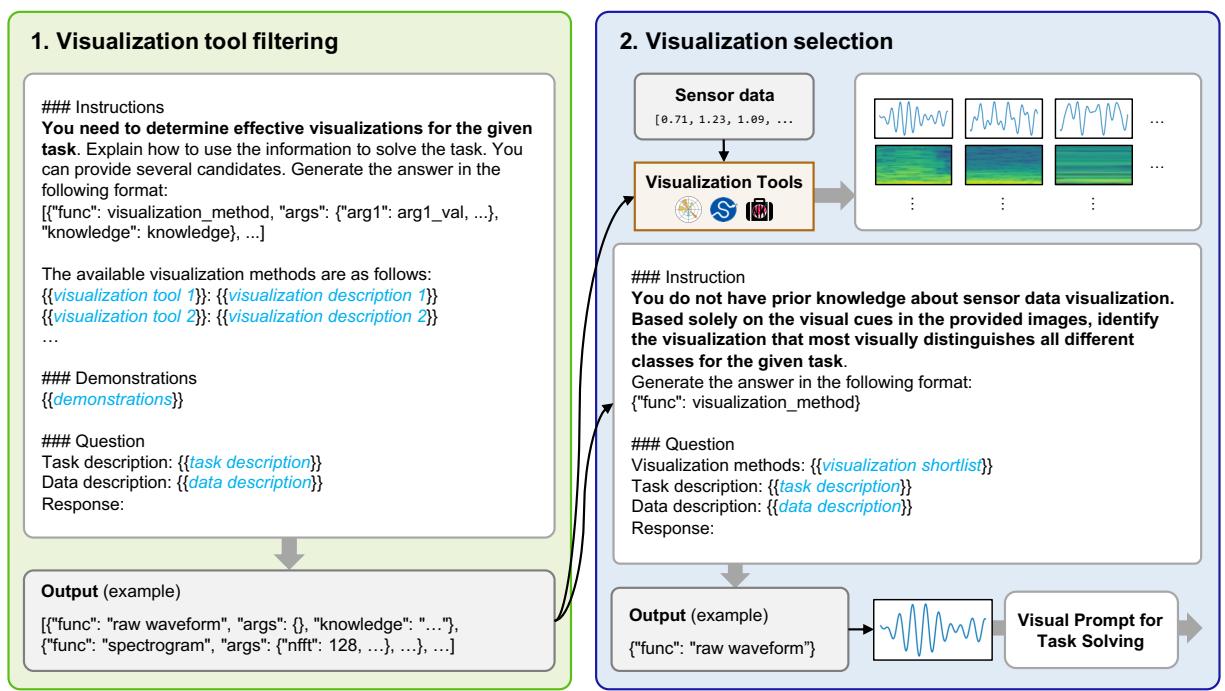
如 图 4 所示,模型充当了自己的评论家。它可能会看着原始波形觉得太乱,看着频谱图觉得太抽象,最后选定一个能清晰突出数据特征的特定信号图。
一旦选定了最佳可视化类型,就会构建最终的 视觉提示 (Visual Prompt) 。 这个提示包括:
- 可视化的目标数据: 我们想要分类的传感器读数。
- 少样本示例 (Few-Shot Examples) : 标有正确答案的参考图像 (例如,一张“走路”信号的图像和一张“跑步”信号的图像) ,以此教模型寻找什么。
- 指令: 指导模型如何解释视觉内容的文本。
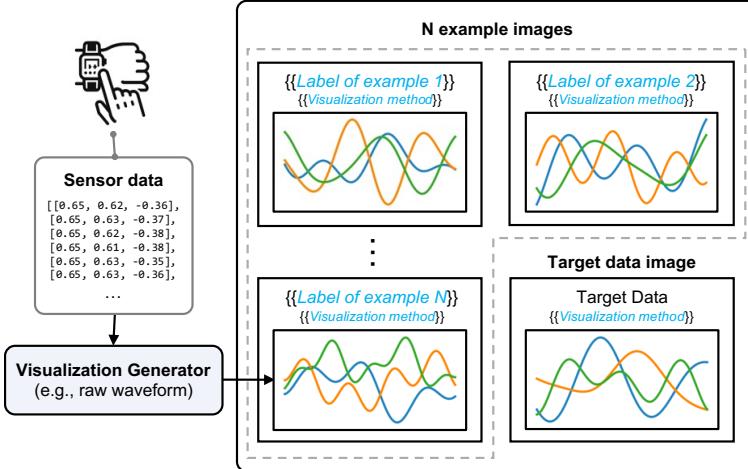
图 3 展示了这个提示的剖析结构。它结合了图像处理的高效性和 LLM 的推理能力。
提示实际上长什么样?
为了让你具体了解 MLLM “看到”了什么,请看下图。这是用于识别主要人类活动 (HHAR 任务) 的视觉提示。
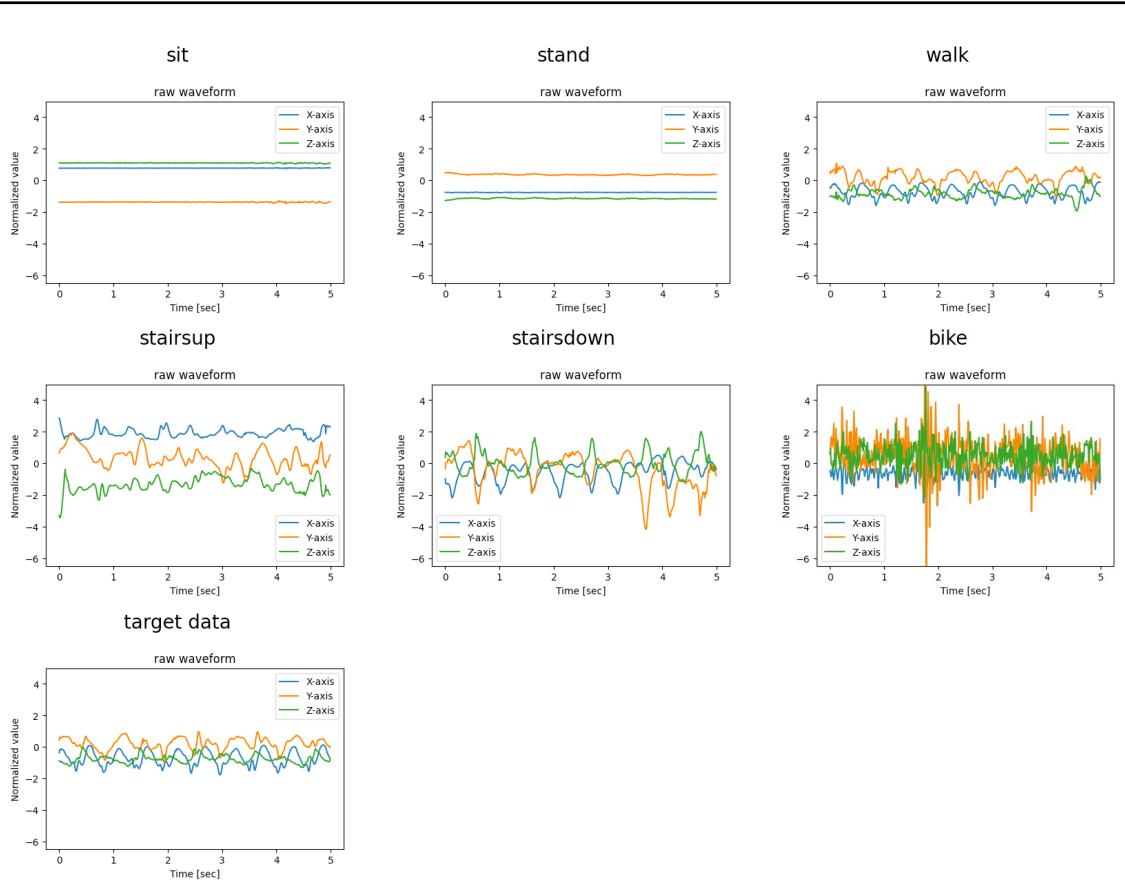
模型获得了清晰的坐、站、走等视觉示例,并被要求将底部的“目标数据”与最相似的视觉模式进行匹配。对于多模态模型来说,这比比较数千个浮点数要直观得多。
实验与结果
研究人员在涉及四种不同模态的 九个感知任务 上测试了这种方法:
- 加速度计: 人类活动识别 (走路、骑车等) 。
- ECG (心电图) : 心律失常检测。
- EMG (肌电图) : 手势识别 (测量肌肉电活动) 。
- 呼吸: 压力检测。
他们将视觉提示方法与标准的纯文本提示 (原始数字) 甚至专门为这些任务训练的监督学习模型进行了比较。
1. 准确性与效率
结果是决定性的。视觉提示在几乎所有类别中都优于文本提示。
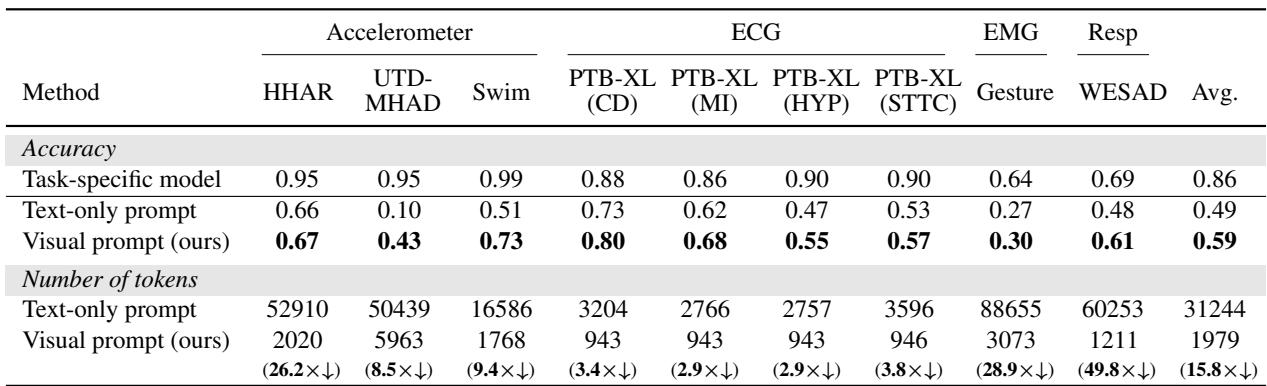
表 1 (上图) 总结了发现:
- 准确性: 视觉提示的准确率比文本提示平均高出 10% 。 在复杂活动识别 (UTD-MHAD) 中,准确率从 10% (文本) 跃升至 43% (视觉) 。
- 成本: Token 的减少是巨大的。用于 EMG (肌肉) 数据的文本提示每次查询需要超过 88,000 个 Token。而视觉等效项呢?仅需 3,073 个 Token。对于该特定任务,这几乎是成本的 29 倍减少 。
2. 可视化策略重要吗?
你可能会想: 难道我们就不能对所有数据都用标准的折线图吗?为什么我们需要那个花哨的“可视化生成器”?
实验表明,可视化的类型会产生巨大的差异。
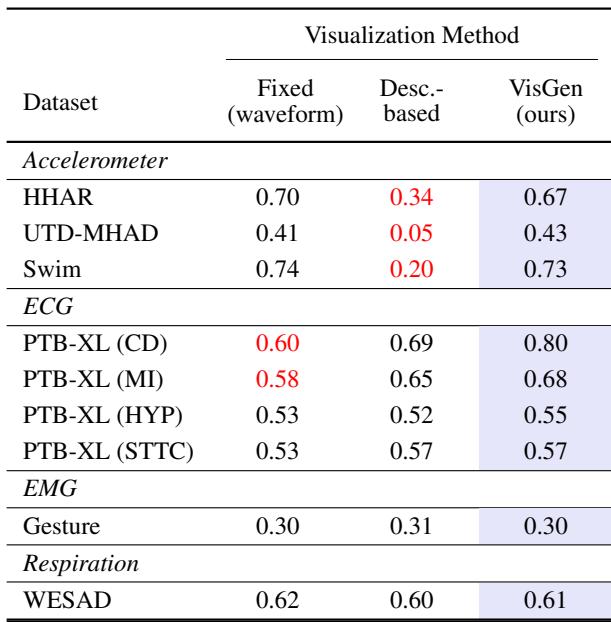
表 2 比较了三种方法:
- 固定 (波形) : 总是使用原始折线图。
- 基于描述: 让 LLM 仅根据文本描述 (不看数据) 猜测最佳图表。
- VisGen (本文方法) : 论文的方法,让 LLM 看到图表后进行选择。
注意表中的 ECG (心脏) 任务。“固定”的原始波形表现不佳 (0.60 准确率) 。“VisGen”方法得分显著更高 (0.80) 。为什么?因为原始 ECG 数据充满噪声且复杂。
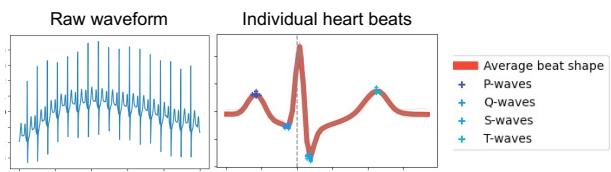
图 7 完美地说明了这一点。 (左侧的) “原始波形”只是一条弯弯曲曲的线。而可视化生成器自动选择的 (右侧的) “独立心跳”图,通过叠加心跳显示平均形状,并标记了特定波 (P、Q、S、T) 。这种经过处理的视觉效果使 MLLM 更容易检测出心律失常等异常情况。
3. 解决方案的多样性
可视化生成器证明是动态的。它并不是对所有任务都选择同一种类型的图表。
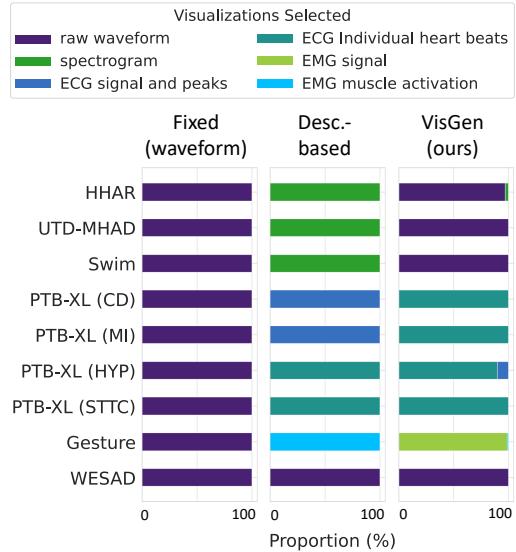
图 6 显示了所选可视化的分布。对于加速度计 (HHAR) ,它坚持使用原始波形。对于肌肉数据 (Gesture) ,它更喜欢“EMG 信号”图。对于心脏数据 (PTB-XL) ,它经常选择“独立心跳”。这种适应性是该方法成功的关键——它量身定制了 AI 观察数据的“镜头”。
结论与启示
“By My Eyes” 论文提出了一个令人信服的论点,即改变我们与多模态 LLM 交互的方式。通过将传感器数据视为 视觉信息 而不是 文本统计数据 , 我们可以释放这些模型在医疗监测和智能设备等现实世界应用中的潜力。
以下是主要收获:
- 一图胜千数: 对于传感器数据,视觉提示比文本提示便宜得多 (Token 数减少 15.8 倍) 且更准确。
- 上下文为王: 可视化数据使我们能够绕过在文本分析长时序数据时困扰我们的上下文窗口限制。
- 自动化是可能的: 我们不需要人类专家为每个新传感器手工绘制图表。MLLM 有能力“看”着选项并自己选择最佳的可视化策略。
随着 MLLM 视觉能力的不断提高,这种方法预示着一个未来: AI 智能体可以通过图表直观地“阅读”物理世界,就像医生看 X 光片或工程师看地震仪一样。它架起了 LLM 的数字智能与传感器模拟现实之间的桥梁。