](https://deep-paper.org/en/paper/2407.10930/images/cover.png)
引言
在快速发展的大语言模型 (LLM) 领域,工程师和研究人员在试图提升模型性能时,往往面临一个两难的选择: 是应该花时间设计更好的提示 (Prompt Engineering) ,还是应该收集数据来微调模型权重 (Fine-tuning) ?
传统上,这被视为一个“非此即彼”的决定。提示工程轻量且易于迭代,而微调虽然资源密集,但通常更为强大。然而,最新的研究表明,我们要么可能看错了方向。如果这两种截然不同的优化策略不是竞争对手,而是统一流水线中互补的步骤呢?
来自斯坦福大学的一篇引人入胜的新论文《Fine-Tuning and Prompt Optimization: Two Great Steps that Work Better Together》 (微调与提示优化: 双剑合璧,效果更佳) 提出了一种新颖的方法: BetterTogether 。 研究人员证明,通过交替进行提示模板优化和模型权重微调,我们可以获得显著优于单独使用任何一种方法的结果。
本文将探讨如何通过这种交替过程让 LLM “自学”,从而带来巨大的性能提升——在某些复杂的推理任务中提升高达 60%。
背景: LM 程序 (LM Programs) 的兴起
要理解这种方法为何具有革命性,我们首先需要看看现代 NLP 系统是如何构建的。我们已经超越了简单的“聊天机器人”交互模式 (即用户提问,模型立即回答) 。今天,我们构建的是 LM 程序 。
LM 程序是一个流水线,其中语言模型充当执行各种子任务的独立模块。最常见的例子是检索增强生成 (RAG) 。在一个 RAG 流水线中,系统可能首先生成一个搜索查询,检索文档,过滤这些文档,最后根据检索到的上下文回答用户的问题。
优化挑战
优化这些流水线是出了名的困难。在标准的神经网络中,我们的每一步都有“标签”,并且可以使用反向传播 (梯度下降) 来更新权重。但在模块化的 LM 流水线中:
- 没有中间标签: 我们通常只知道最终答案是否正确。我们没有中间步骤的真实数据 (例如,搜索查询是否完美?我们不知道) 。
- 离散步骤: 模块之间的通信是自然语言 (文本) ,这打断了梯度流。你无法轻易地将误差反向传播过一个句子。
传统上,开发者使用像 DSPy 这样的框架来优化这些模块的提示 (\(\Pi\)) 。其他人可能会尝试微调底层模型的权重 (\(\Theta\)) 。这篇论文的作者认为,要真正最大化性能,我们必须协同优化 \(\Theta\) 和 \(\Pi\)。
核心方法: BetterTogether
BetterTogether 方法的核心假设简单而深刻: LLM 可以自学以更好地完成任务,且更好的模型可以利用更复杂的提示。
研究人员将优化问题视为通过调整模型权重 \(\Theta\) 和提示 \(\Pi\),在数据集 \(X\) 上最大化某个指标 (如准确率) 。
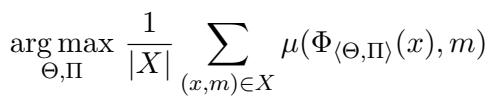
如上图公式所示,目标是找到权重 (\(\Theta\)) 和提示 (\(\Pi\)) 的配置,以最大化所有样本的平均性能指标 \(\mu\)。
算法: 交替优化
BetterTogether 算法避免了试图一次性优化所有内容的复杂性。相反,它在两个特定操作之间交替进行: BootstrapFewShotRS (用于提示) 和 BootstrapFinetune (用于权重) 。
以下是系统如何自我提升的逐步逻辑:
- 初始提示优化 (\(\Pi\)) : 系统从基础模型开始。它通过流水线运行训练样本。它寻找“成功”的运行——即流水线得出正确最终答案的实例。它提取这些成功运行中的中间步骤,并将它们转化为“少样本 (few-shot) ”示例包含在提示中。
- 权重微调 (\(\Theta\)) : 一旦提示被优化,系统就会生成一组新的训练数据。它记录成功运行期间每个模块的输入/输出。这创建了一个由模型自己生成的高质量合成数据集。然后,使用 LoRA 在这些数据上微调模型权重。
- 第二轮提示优化 (\(\Pi\)) : 现在模型权重已经调整过,模型的行为会有所不同。它变得更聪明,更符合任务要求。算法再次运行提示优化步骤。因为底层模型更好了,它可以生成质量更高的少样本示例,从而进一步完善提示。
这种循环 (\(\Pi \rightarrow \Theta \rightarrow \Pi\)) 创造了一个正反馈循环。提示优化过滤掉了糟糕的推理,为微调创造了干净的数据。微调将这种推理能力固化到权重中。最后的提示优化则打磨了交互过程。
深入解析: 模块
为了直观地了解其工作原理,我们来看看研究中使用的具体程序。作者在三个不同的任务上实施了这一策略: HotPotQA (多跳推理) 、GSM8K (数学) 和 Iris (分类) 。
多跳推理 (HotPotQA)
HotPotQA 是一项复杂的任务,要求模型跨多个文档查找信息。这不仅仅是一个问题;它是一系列的推理步骤。
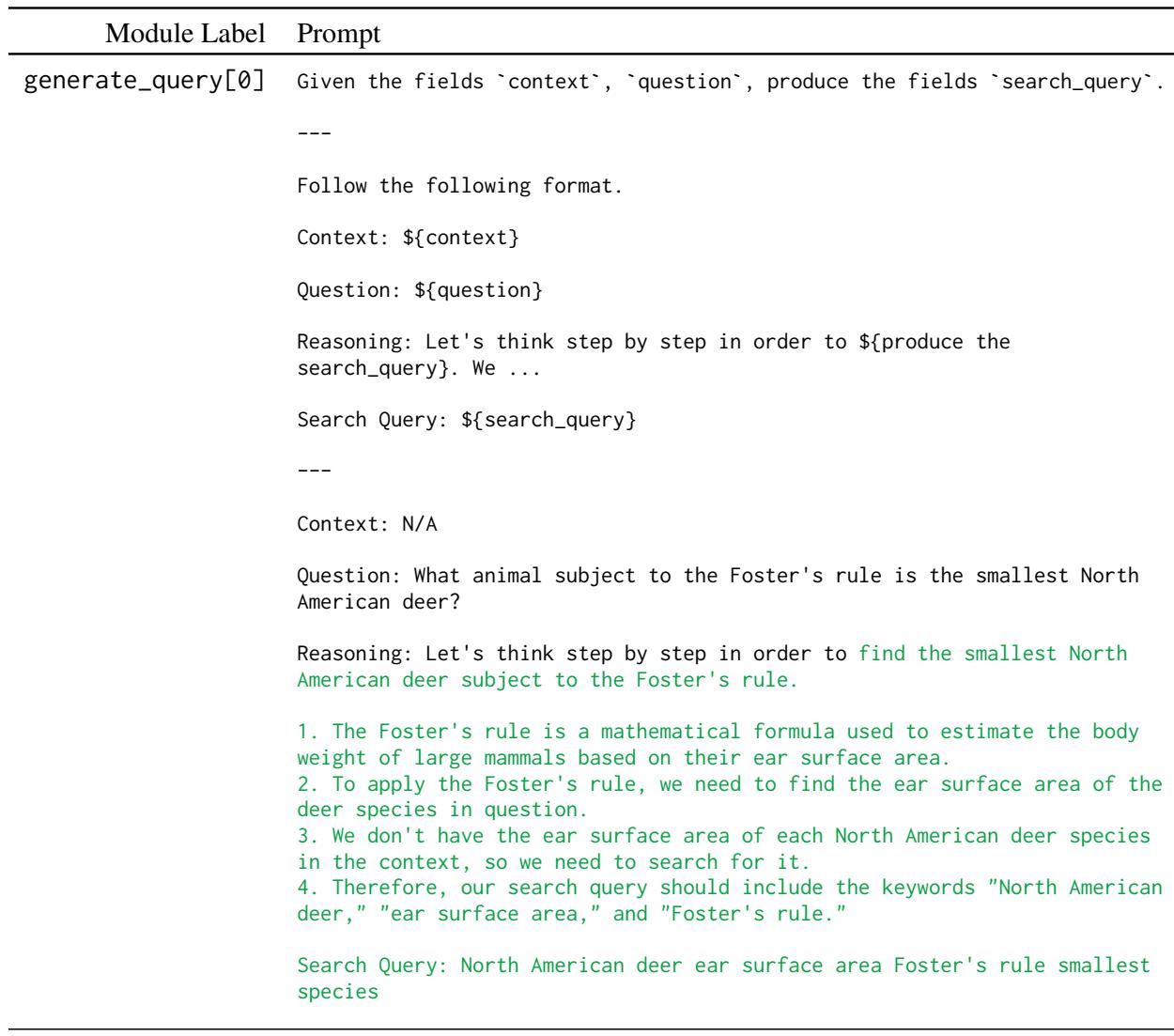
在图 1 (上图) 中,你可以看到“提示” (\(\Pi\)) 的复杂性。它不仅仅是一条指令。它由多个模块组成: generate_query (搜索维基百科) 和 generate_answer。
- 第 1 步: 模型根据问题生成搜索查询。
- 第 2 步: 它阅读上下文,并在需要时生成另一个查询 (多跳) 。
- 第 3 步: 它综合出最终答案。
手动优化这个过程是一场噩梦。通过使用 BetterTogether 方法,系统会自动找到最佳示例放入这些提示模板 (即绿色的“Reasoning”部分) ,然后微调模型以更好地遵循这些模式。
算术推理 (GSM8K)
数学推理需要不同类型的精确度。模型必须遵循严格的思维链才能得出正确的数字。
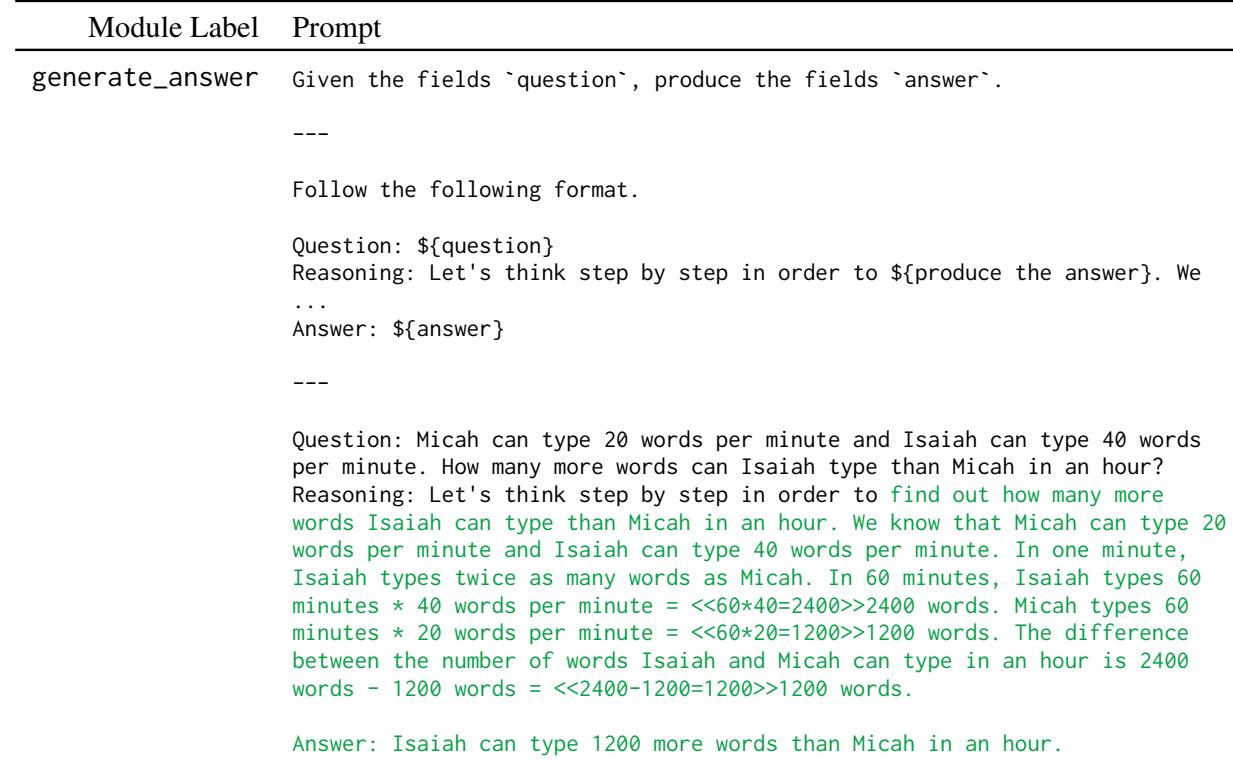
如上图所示,generate_answer 模块经过优化,可生成逐步的推理轨迹。在 “BetterTogether” 流水线中,微调步骤确保模型学会算术逻辑,而提示优化则确保模型正确构建输出结构以供解析器使用。
分类 (Iris)
有趣的是,研究人员还在标准的 Iris (鸢尾花) 分类数据集上测试了这一点,看看该方法在非语言任务 (根据测量数据预测花朵品种) 上是否有效。

即使在这里,将分类视为语言程序也能让模型对花瓣长度和宽度进行“推理” (如生成的绿色文本所示) ,从而比标准方法提高了准确率。
实验与结果
研究人员使用三种不同的大语言模型评估了他们的方法: Mistral-7b、Llama-2-7b 和 Llama-3-8b 。 他们将 “BetterTogether” 策略与三个基准进行了比较:
- 零样本 (Zero-shot) : 开箱即用的模型。
- 仅提示优化 (Prompt Opt Only, \(\Pi\)) : 仅优化提示。
- 仅权重优化 (Weight Opt Only, \(\Theta\)) : 仅微调。
组合策略的优势
结果令人信服。几乎在所有任务和模型中,结合提示优化和微调都击败了单独的策略。
主要发现:
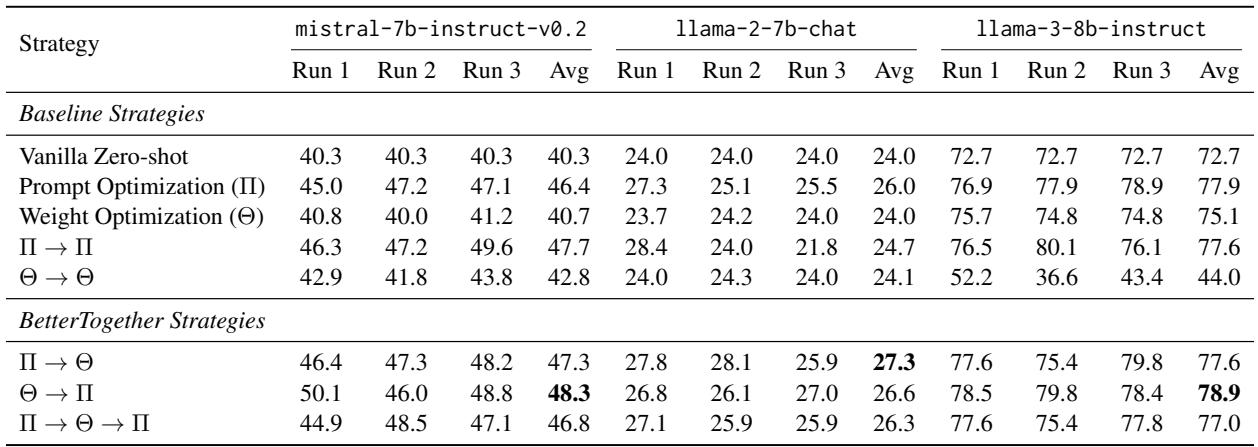
- HotPotQA: 这个任务见证了最显著的收益。例如,在 Llama-2-7b 上,“BetterTogether” 策略 (\(\Pi \rightarrow \Theta \rightarrow \Pi\)) 达到了近 35% 的准确率 , 而仅权重优化只有 12.2% 。
- GSM8K: 虽然数学通常较难仅通过提示来改进,但组合方法挤出了额外的收益,推高了准确率,超过了单独微调的效果。
我们可以在下面看到这些运行的详细分类。
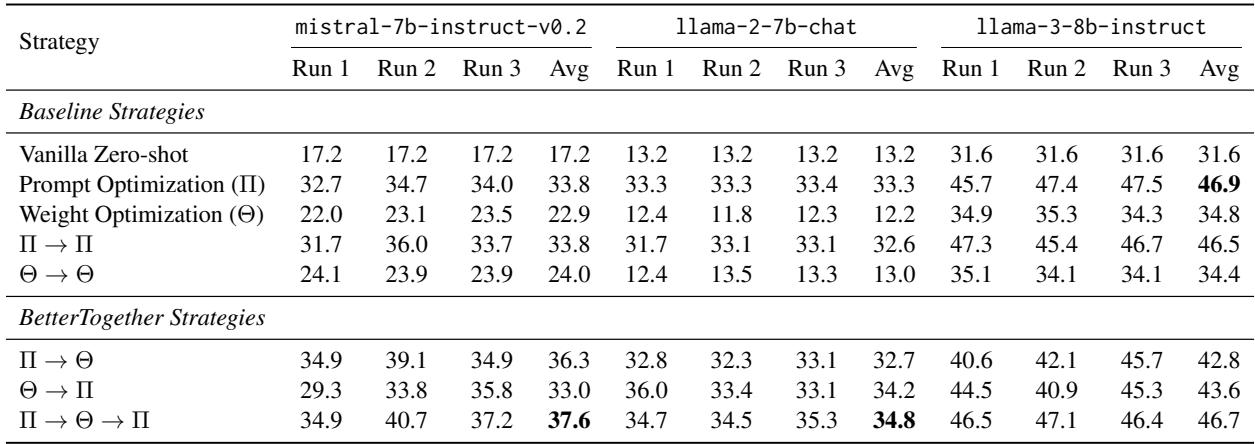
上表 (HotPotQA 结果) 突出了该方法的一致性。注意 \(\Pi \rightarrow \Theta \rightarrow \Pi\) 这一行。它在不同模型中始终处于顶尖水平。这验证了“三明治”方法的有效性: 优化提示以获得好数据,微调模型,然后再次优化提示以适应新模型。
同样,对于 GSM8K (上图) ,组合策略始终徘徊在最高性能水平。值得注意的是,对于数学任务,单纯的微调 (\(\Theta\)) 非常有效,但增加提示优化层 (\(\Theta \rightarrow \Pi\)) 进一步突破了界限,特别是对于 Llama-3-8b 模型。
为什么这行得通?
作者认为,提示优化充当了一个过滤器。当我们训练模型 (微调) 时,我们要基于正确的推理来训练它。如果我们只是运行一个原始模型,它可能会产生许多错误的答案,或者带有糟糕推理过程的正确答案。
通过首先优化提示,我们增加了模型生成高质量、正确推理轨迹的可能性。当我们随后在这些轨迹上进行微调时,我们实际上是将模型的“最佳状态”蒸馏到其权重中。
结论
“BetterTogether” 论文为 NLP 系统工程的未来提供了一个实用的路线图。它让我们摆脱了“提示 vs 微调”的二元选择,转向统一的优化生命周期。
对于学生和从业者来说,要点很明确:
- 不要满足于其一: 如果你有一个模块化流水线,只优化提示或只微调都会错失性能提升的机会。
- 让模型自学: 你不一定总是需要海量的外部数据集。你可以通过提示模型成功,然后在这些成功案例上进行训练,从而引导 (bootstrap) 出你自己的训练数据。
- 顺序很重要: \(\Pi \rightarrow \Theta \rightarrow \Pi\) 的顺序特别强大,因为它在训练前清洗数据,并在训练后完善接口。
随着 LLM 继续被集成到复杂的软件流水线中,像 BetterTogether 这样自动优化整个系统 (包括权重和代码) 的策略,很可能会成为行业标准。