](https://deep-paper.org/en/paper/2407.11784/images/cover.png)
引言
在人工智能快速发展的格局中,多模态大模型 (Multimodal Large Models, MLLMs) ——即能够同时处理和生成文本、图像及视频的 AI——已占据舞台中心。从 GPT-4 到 Sora,这些模型正在不断拓展创造力和功能的边界。然而,在这令人印象深刻的能力背后,潜藏着一个持久的工程瓶颈: 数据与模型开发的“先有鸡还是先有蛋”的问题。
从历史上看,提升 AI 的路径一直是分叉的。一方面是以模型为中心的开发,研究人员沉迷于架构调整和训练算法,通常假设数据是一个固定的变量。另一方面是以数据为中心的开发,工程师清洗和整理海量数据集,往往依赖直觉或启发式规则,而在昂贵的训练运行结束之前,他们并不确切知道这些数据将如何与特定模型相互作用。
这种孤岛式的方法效率低下。这导致了计算资源的浪费和模型的次优表现。如果你花了几周时间根据一条规则清洗数据集,结果这条规则实际上损害了你特定模型的性能怎么办?如果模型架构需要特定类型的数据多样性,而你的清洗脚本却将其过滤掉了怎么办?
在这篇文章中,我们将深入探讨一篇提出解决方案的新研究论文: Data-Juicer Sandbox (Data-Juicer 沙盒) 。 这是一个数据反馈驱动的套件,旨在弥合数据与模型之间的鸿沟,实现系统的“协同开发”工作流。我们将探索这个沙盒如何让研究人员利用真实模型反馈来探测、分析和精炼他们的数据配方 (Data Recipes) ,最终在仅使用一小部分计算资源的情况下实现最先进的结果——包括在 VBench 视频生成排行榜上名列前茅。
问题: 孤立的开发轨迹
要理解 Data-Juicer Sandbox 的重要性,我们首先需要了解当前 MLLM 开发中的摩擦。
训练一个大模型极其昂贵。由于“全量训练”的高昂成本,开发者通常将数据处理视为模型介入之前发生的预处理步骤。他们可能会根据通用统计数据 (如图像分辨率或文本长度) 应用过滤器来去除“低质量”图像或文本。
然而,“质量”是主观的,且依赖于模型。一个为 CLIP 模型 (图文匹配) 优化的数据集,其所需的特征可能与为 Diffusion Transformer (文生视频) 优化的数据集截然不同。当这两条开发轨道——数据和模型——互不沟通时,你会得到:
- 资源利用效率低下: 在对模型学习没有实际帮助的数据上进行训练。
- 次优结果: 因为数据配方没有针对模型的特定需求进行调整,从而错失了性能提升的机会。
Data-Juicer Sandbox背后的研究人员认为,我们需要一个“沙盒实验室”——一个安全、成本可控的环境。在这里,我们可以在扩大规模之前,进行许多小型实验,以了解数据算子 (Operators, OPs) 与模型性能之间的相互作用。
解决方案: 沙盒实验室架构
Data-Juicer Sandbox 充当中间件层。它位于原始数据处理 (由 Data-Juicer 系统处理) 和模型训练框架 (如 PyTorch 或特定的模型实现,如 LLaVA 或 EasyAnimate) 之间。
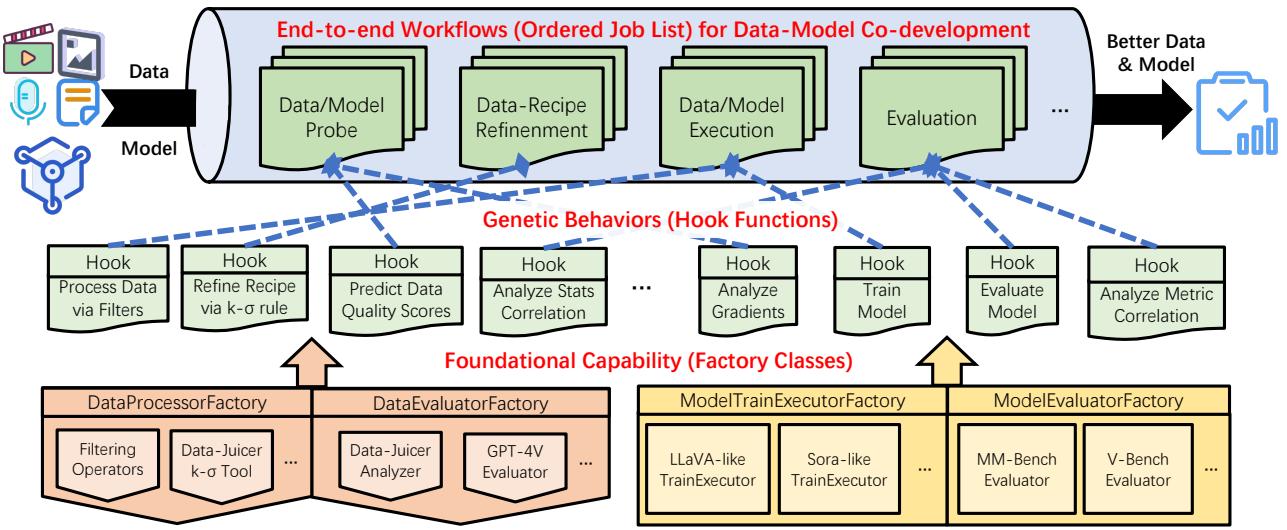
如上面的架构图所示,沙盒是分层编排的:
- 工作流 (顶层) : 定义好的作业序列,例如“探测数据” \(\rightarrow\) “精炼配方” \(\rightarrow\) “训练模型” \(\rightarrow\) “评估”。
- 行为 (中层) : 这些是定义特定动作的钩子函数 (Hook Functions) ,例如计算数据统计与模型损失之间的相关性,或应用特定的过滤器。
- 能力 (底层) : 负责核心任务的工厂类——过滤数据、计算指标 (如困惑度或美学评分) 以及执行训练循环。
这种结构允许用户“即插即用”不同的模型和数据策略,而无需重写整个代码库。
核心方法: 探测-分析-精炼 (Probe-Analyze-Refine)
这篇论文的核心是 探测-分析-精炼 工作流。这是应用于 AI 训练的科学方法。沙盒不是猜测哪些数据是好的,而是系统地验证假设。

让我们逐步分解这个工作流,如上图所示。
第一阶段: 利用单算子数据池进行探测
开发者通常会问的第一个问题是: “哪些数据处理算子 (OPs) 真正重要?”
过滤数据的方法有几十种: 按文本长度、按图像纵横比、按“美学评分”、按文本与图像的匹配程度 (CLIP 分数) 等。为了找出哪些因素驱动性能,沙盒创建了 单算子数据池 (Single-OP Data Pools) 。
- 获取完整的原始数据集 \(\mathcal{D}\)。
- 选择一个特定的算子 (例如
图像 NSFW 过滤器) 。 - 根据算子的统计数据处理数据并将其分为几组 (桶) : 低、中 和 高。
- 在这些特定的分组 (以及一个随机对照组) 上训练小型“探测”模型。
- 评估模型。
如果在“高美学评分”数据池上训练的模型明显优于随机基准,你就知道美学质量是该特定模型任务的关键因素。如果表现更差,你可能过滤掉了必要的多样性。
研究人员在各种任务中运行了这个探测阶段。下表总结的结果显示,不同的任务需要截然不同的数据配方。
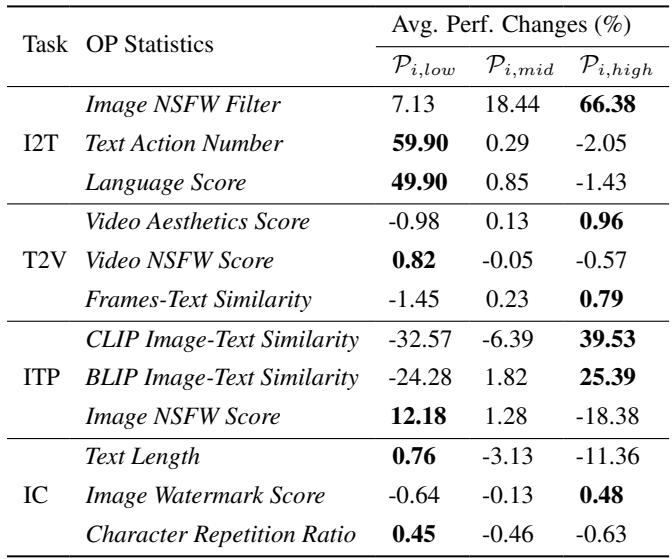
关键洞察: 注意在图生文 (I2T) 任务中,图像 NSFW 过滤器 (高) 在某些指标上相对于基准带来了巨大的 +66.38% 的提升。然而,对于其他任务,影响各不相同。这证实了“一刀切”的数据清洗方式是不存在的。
第二阶段: 分析多算子配方
一旦知道了哪些单个算子有效,接下来的诱惑就是简单地组合所有“好”的算子。然而,研究人员发现 组合顶级算子并不总是能产生更好的结果。
有时,两个过滤器可能是冗余的 (过滤掉相同的数据) 。其他时候,它们可能是相互矛盾的。为了解决这个问题,沙盒使用了 相关性分析 。
通过计算不同数据统计与模型指标之间的皮尔逊相关系数,系统可以识别哪些算子是正交的 (独立的) ,哪些是相关的。
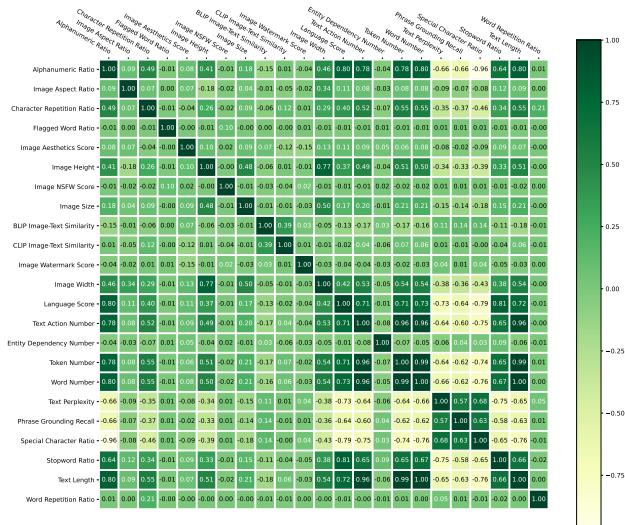
在上面的相关性矩阵中,绿色表示正相关,红色表示负相关。沙盒利用这些数据对算子进行聚类。策略是从不同的聚类中挑选表现最好的算子,以确保你在多个不重叠的维度上改进数据 (例如,一个算子针对视觉质量,一个针对文本复杂度,一个针对对齐) 。
研究人员通过创建“配方”对此进行了测试。有趣的是,他们发现简单地堆叠前 3 名算子有时比起只使用第 1 名算子反而会损害性能。这凸显了数据交互的复杂性——使用多个标准过于激进地过滤可能会降低数据多样性,导致模型无法泛化。
第三阶段: 精炼与扩展 (数据金字塔)
在确定了算子的最佳组合 (“配方”) 后,最后一步是扩展。但这里存在一个权衡: 当你应用更多过滤器以获得更高质量时,剩下的数据就会变少。
沙盒通过 金字塔形数据池 方法来解决这个问题:
- 金字塔顶端: 质量极高,过滤严格,体量小。
- 金字塔底端: 质量较低,过滤宽松,体量巨大。
研究人员提出了一个关键问题: 是在大量平庸数据上训练更好,还是重复使用高质量数据多次更好?

结果 (如上图 3 所示) 令人震惊。
- 图生文 (a): 重复高质量数据 (红线) 明显优于添加次优数据 (蓝线) 和完整基准数据集 (绿线) 。
- 缩放定律 (Scaling Laws): 对于图文预训练 (c),他们观察到了明显的幂律缩放。随着他们在高质量子集上增加计算量 (训练更多 epoch) ,性能持续线性上升。
这意味着, 数据质量往往比数据数量更重要 , 前提是你愿意在这些高质量数据上进行更长时间的训练 (多个 epoch) 。
案例研究与关键结果
为了证明沙盒在现实世界中有效,作者将其应用于三个截然不同且难度极高的多模态任务。
1. 文生视频生成: 荣登榜首
最令人印象深刻的结果来自文生视频 (T2V) 实验。视频生成以难度大和计算昂贵而著称。
团队从一个基础模型 (T2V-Turbo/VideoCrafter-2) 开始,应用了沙盒工作流。
- 探测: 他们发现视频特定的算子 (如
视频运动得分和视频美学) 比文本算子重要得多。 - 精炼: 他们创建了一个仅包含 22.8 万个高质量视频的数据集 (仅为典型训练集的一小部分) 。
- 结果: 他们训练了一个名为 “Data-Juicer (DJ)” 的模型,该模型在 VBench 排行榜上获得了第一名 , 击败了像 Gen-3 和 Kling 这样的商业及闭源模型。
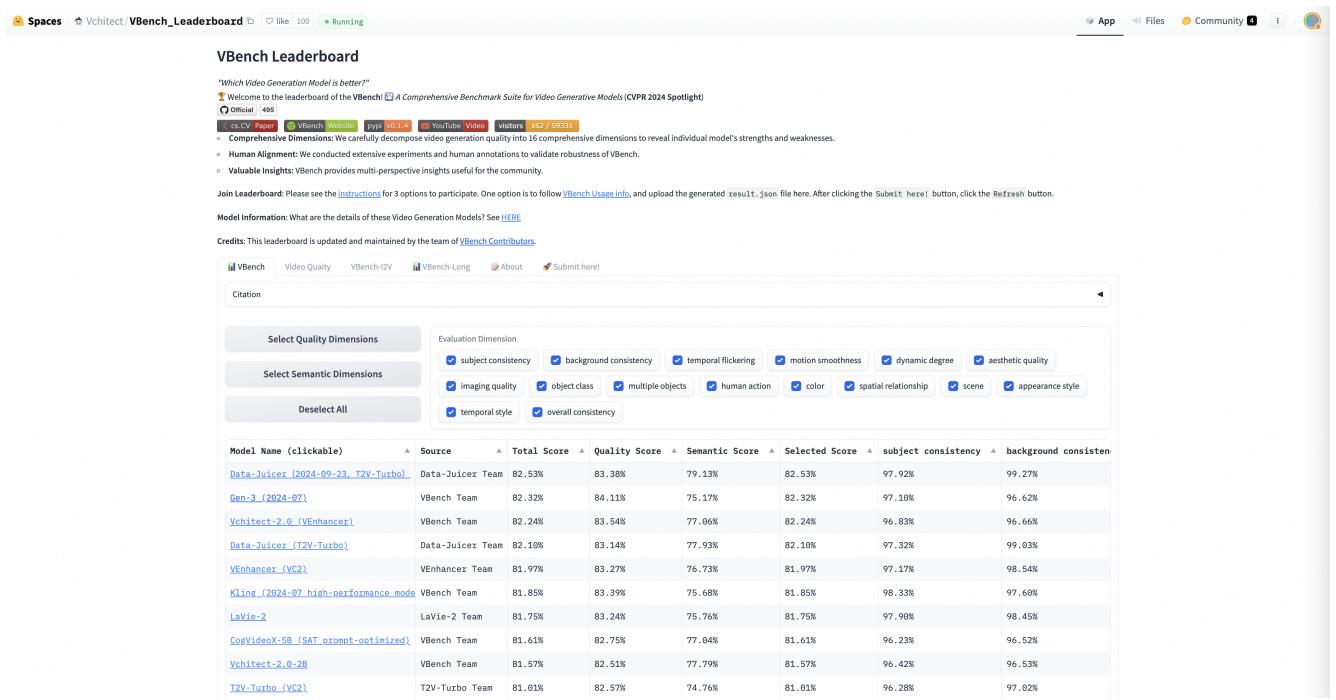
这次胜利不仅是原始性能的胜利,更是效率的胜利。通过使用沙盒精确识别哪些视频值得训练,他们以比竞争对手少得多的计算量实现了最先进的结果。
2. 图生文: MGM 模型
对于图生文生成 (例如,“描述这张图片”) ,他们使用 Mini-Gemini (MGM) 模型进行了实验。
利用沙盒的洞察,他们构建了一个训练集,其大小仅为 原始不重复实例的 1/10 。 通过在这个高质量子集上训练 (并重复使用) ,他们超越了在完整的海量数据集上训练的基准模型。
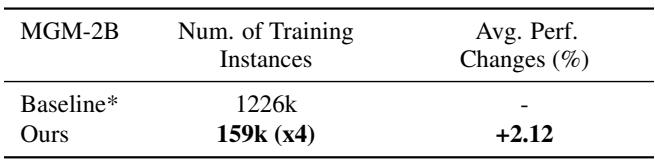
这一结果挑战了盛行的“大数据”观念。它表明,我们目前输入 MLLM 的数据中有很大一部分可能实际上是干扰模型的噪声。
3. 图文预训练: 缩放定律
最后,他们研究了 CLIP 模型 (用于连接文本和图像) 。他们证实,从小规模“探测”实验中获得的洞察可以迁移到更大规模的场景。适用于小型 ViT-B-32 模型的配方,在扩展到更大的架构和更长的训练周期时同样有效。这种“可迁移性”至关重要,因为它验证了沙盒的核心前提: 你可以在小型模型上吸取低成本的教训,并将其应用于昂贵的大型模型。
超越过滤: 多样性与生成式精炼
沙盒不仅仅是删除坏数据。它还提供了分析 多样性 的工具。
利用分析工具,研究人员生成了词云,根据 NSFW 分数可视化数据池的内容。

他们发现,“高 NSFW”池不仅包含露骨内容,还包含其他地方罕见的特定语义类别 (如美容、纹身和艺术) 。这就解释了为什么图生文模型 (需要识别一切) 受益于“高 NSFW”数据——它增加了多样性。相比之下,文生视频模型 (需要生成美观的内容) 在这些数据上训练时表现受损。
此外,沙盒支持 生成式映射器 (Generative Mappers) 。 这些算子不仅过滤数据,还会改变数据。例如,使用扩散模型根据标题重新生成嘈杂的图像,或使用字幕模型重写糟糕的描述。
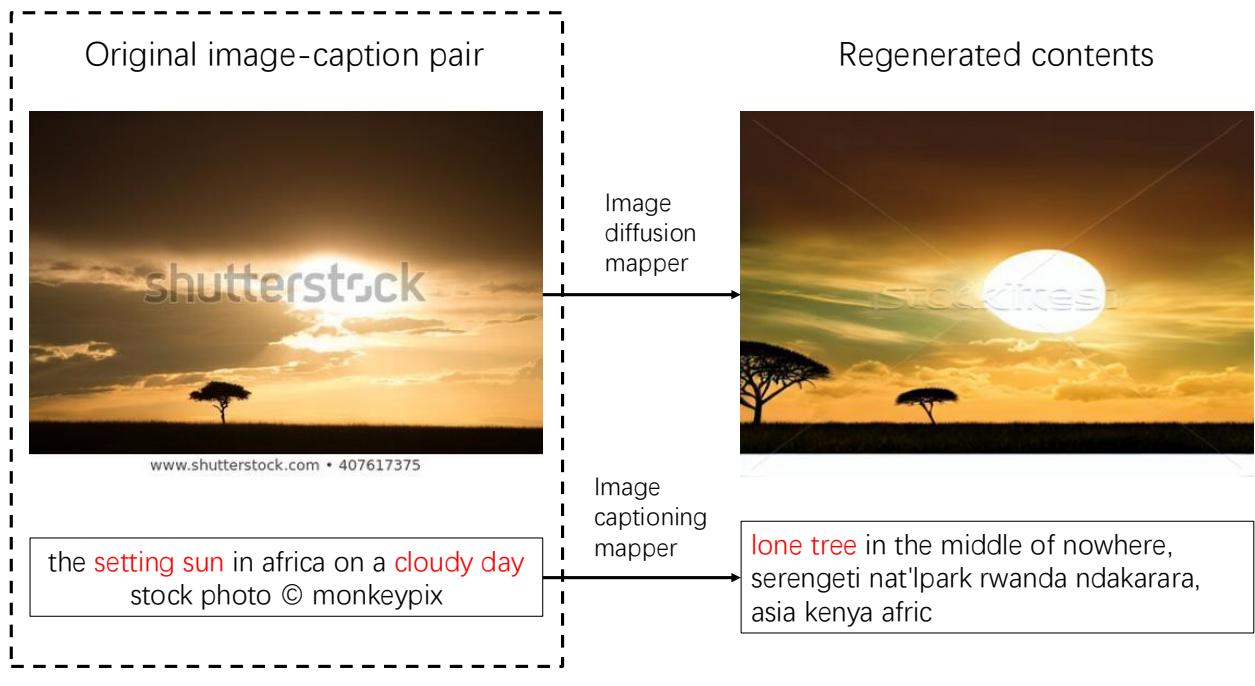
如上所示,沙盒可以将低质量的输入“升级改造”为高质量的训练样本,有效地凭空创造出更好的数据。
结论
Data-Juicer Sandbox 代表了从基于直觉的 AI 开发向基于证据的 协同开发 的转变。通过提供一个结构化的环境来探测、分析和精炼数据配方,它将数据清洗这门“玄学”转化为一门严谨的工程学科。
这项工作的主要收获是:
- 数据-模型耦合: 真空中不存在“完美的数据集”。最好的数据完全取决于模型架构和目标任务。
- 效率制胜: 你并不总是需要更多的数据。你需要的是更好的数据。重复高质量数据往往胜过增加更多低质量数据。
- 可迁移的洞察: 在沙盒中通过小型、低成本实验学到的经验教训,可以可靠地扩展到最先进的模型训练中。
随着多模态模型的规模和复杂性不断增长,像 Data-Juicer Sandbox 这样的工具将变得至关重要。它们让研究人员能够在无限的数据可能性空间中导航,确保未来的海量计算资源是用于从信号中学习,而不是在噪声中空转。