](https://deep-paper.org/en/paper/2407.15489/images/cover.png)
迷失在翻译中?为什么机器翻译可能是多语言 AI 的秘密武器
如果你一直在关注自然语言处理 (NLP) 近年来的爆发,你可能对这些重量级选手并不陌生: BERT、GPT 和 T5。这些模型彻底改变了机器理解人类语言的方式。最近,焦点已经转移到了多语言模型上——这些系统能够同时理解和生成数十种甚至数百种语言的文本。
然而,在这个领域存在着一场科学上的“比较危机”。当一个新的多语言模型发布时,它通常在各个方面都与之前的模型不同: 它有不同的架构,在不同的数据集上训练,参数数量不同,使用的训练目标也不同。当模型 B 表现优于模型 A 时,是因为架构更好吗?还是仅仅因为它接受了更多数据的训练?
在论文 “A Comparison of Language Modeling and Translation as Multilingual Pretraining Objectives” (语言建模与翻译作为多语言预训练目标的比较) 中,来自赫尔辛基大学和南布列塔尼大学的研究人员着手解决这个“苹果与橙子”式的比较问题。他们创建了一个严格控制的环境来回答一个基本问题: 教模型在语言之间进行翻译,是否比标准的单语言建模能创造出更好的语言“理解”能力?
在这篇文章中,我们将剖析他们的方法,探索他们比较的具体架构,并分析为什么“机器翻译”可能是预训练基础模型中一个被低估的强大工具。
问题所在: 苹果、橙子和梨
要理解这篇论文的重要性,我们需要先看看现代语言模型 (LMs) 通常是如何进行预训练的。一般来说,根据它们的目标 (模型在训练期间试图实现什么) ,它们分为两大阵营:
- 单语言目标 (Monolingual Objectives) : 模型观察语言 A 中的文本,并试图预测语言 A 中缺失的单词或下一个单词。它可能对许多种语言都这样做,但在训练过程中很少看到语言之间的显式联系。
- 跨语言目标 (Cross-lingual Objectives) : 模型被明确展示了语言 A 与语言 B 之间的关系 (例如,通过翻译对) 。
假设是: 翻译 (一种显式的跨语言信号) 应该能强迫模型学习更深层的语义表示。如果一个模型知道法语中的 “chat” 和英语中的 “cat” 指的是同一个概念,那么它就学到了一些关于世界的深刻知识,而不仅仅是法语或英语的语法。
然而,证明这一假设很困难,因为现有的模型如 mBERT (掩码语言模型) 和 mT5 (编码器-解码器) 差异太大,无法公平比较。这篇论文消除了这些变量。
受控环境
研究人员主要关注两个变量: 模型架构和预训练目标 。 为了确保公平竞争,他们控制了其他所有因素:
- 相同数据: 所有模型都在完全相同的数据集上训练,即 UNPC (联合国平行语料库) 和 OpenSubtitles 的组合。
- 相同大小: 所有模型都使用了 12 层、512 个隐藏维度和 8 个注意力头。
- 相同分词: 共享的 100k BPE (字节对编码) 词汇表。
- 相同算力: 所有模型都训练了 600k 步。
本研究选择的语言包括阿拉伯语 (AR) 、中文 (ZH) 、英语 (EN) 、法语 (FR) 、俄语 (RU) 和西班牙语 (ES) 。
数据约束
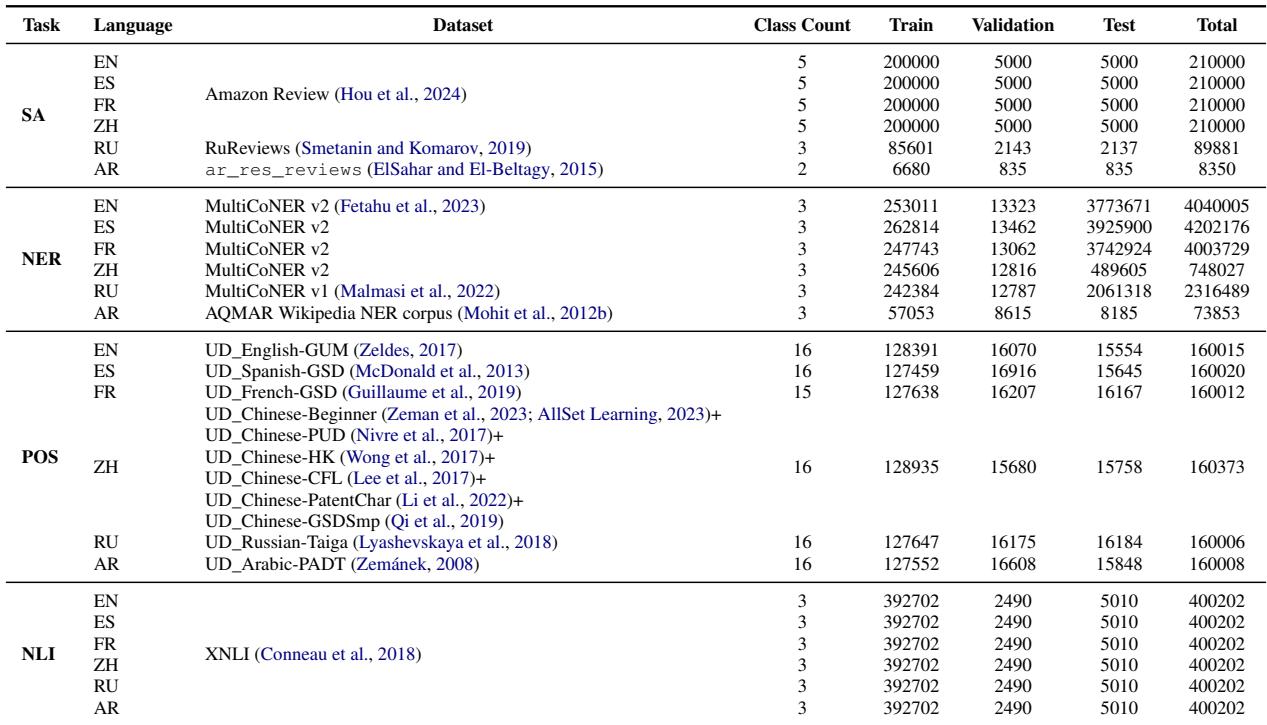
值得注意的是他们数据选择的严谨性。要将翻译目标与单语言目标进行比较,你需要双语文本 (bitexts) (两种语言对齐的句子) 。
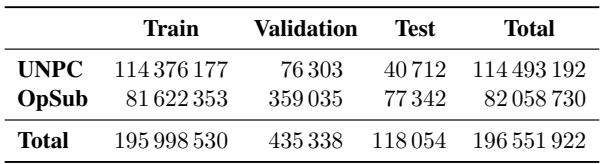
如表 4 所示,研究人员使用了大量的句子对——总共超过 1.96 亿行。至关重要的是,他们确保了用于翻译模型的每一份文档也同样可用于单语言模型。如果一份文档存在三种语言版本,他们会贪婪地将其分配给代表性最差的语言对以平衡数据,确保没有模型拥有不公平的数据优势。
参赛选手: 五种模型,两大类别
研究人员将他们的模型分为双栈模型 (Double-Stack,即像 BART 或 T5 这样的编码器-解码器架构) 和单栈模型 (Single-Stack,即像 BERT 这样的仅编码器或像 GPT 这样的仅解码器架构) 。
让我们来看看他们比较的五种具体目标。
1. 双栈模型 (编码器-解码器)
这些模型由两个主要块组成: 处理输入的编码器和生成输出的解码器。
- 2-LM (BART 去噪) : 使用标准的 BART 目标。输入文本被破坏 (单词被掩盖或打乱) ,模型必须重建原始的干净文本。它一次只在一种语言内操作。
- 2-MT (机器翻译) : 给定源语言 (例如法语) 的句子,模型必须生成目标语言 (例如英语) 的翻译。这提供了强大、显式的跨语言信号。
2. 单栈模型
这些模型只包含一个 Transformer 栈。
- MLM (掩码语言建模) : 仅编码器模型 (如 BERT) 。输入中的某些 token 被隐藏为
[MASK]token,模型必须根据上下文猜测它们是什么。 - CLM (因果语言建模) : 仅解码器模型 (如 GPT) 。模型读取一个序列并预测下一个单词。它只能“看到”当前位置左侧的单词。
- TLM (翻译语言模型) : 这是 CLM 的一种变体。模型输入的是一个句子及其连接在一起的翻译。然后,它在这个长双语序列上执行因果语言建模 (预测下一个单词) 。
目标的可视化
这些目标之间的区别可能比较抽象,所以让我们看看模型在训练期间到底看到了什么。
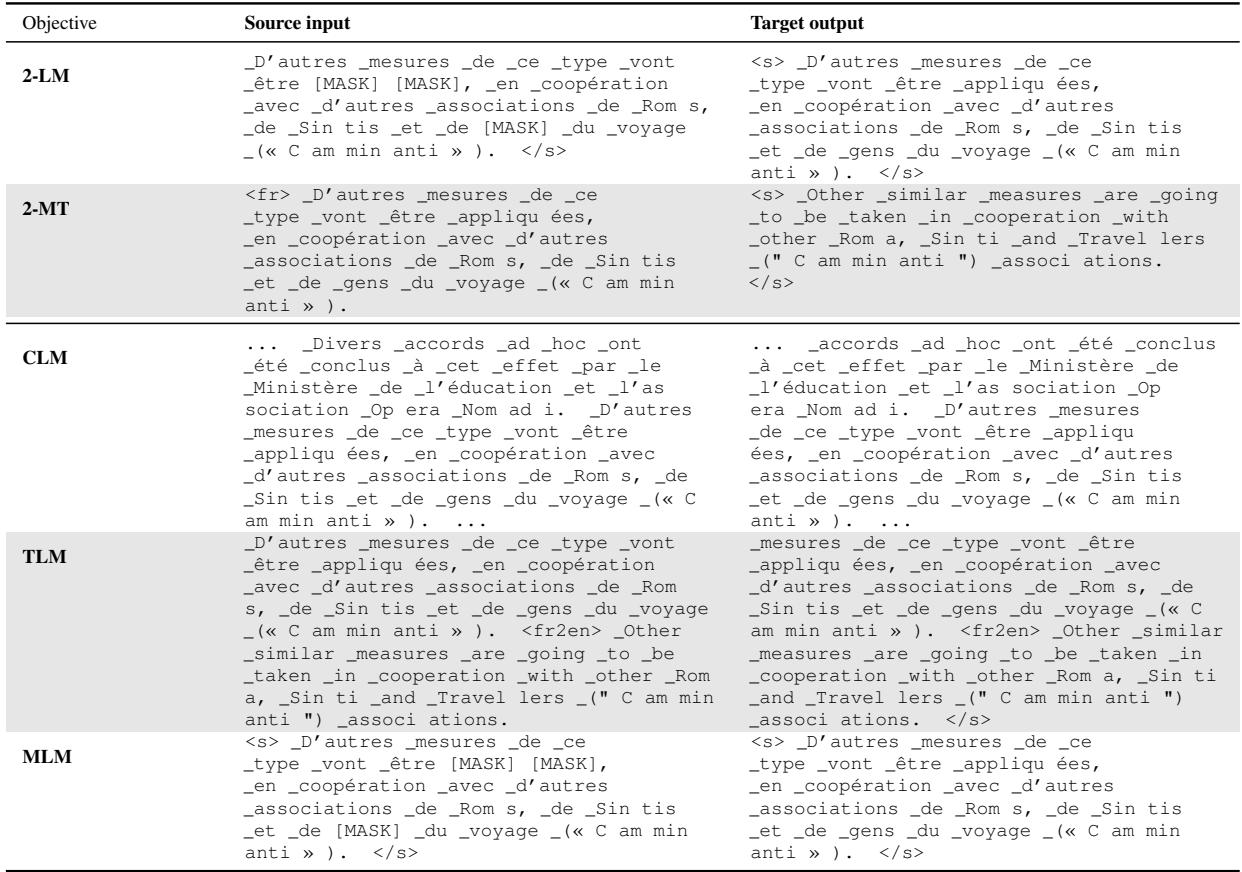
表 3 提供了一个具体的例子,展示了相同的底层数据是如何针对每个目标进行格式化的:
- 2-LM: 注意输入中有
[MASK]token。目标输出是干净的原始法语句子。 - 2-MT: 输入是法语;目标输出是英语。模型必须理解含义才能成功。
- MLM: 与 2-LM 类似,但这是一个仅编码器架构。它直接预测被掩盖的单词,而不是生成一个全新的序列。
- CLM: 模型读取连续的文本流并预测下一个 token。
- TLM: 模型读取法语句子,然后是一个分隔符 token,然后是英语句子,逐个 token 进行预测。
评估策略: 探测 (Probing) 与微调 (Fine-tuning)
如何确定哪个模型“更好”?研究人员在下游任务 (情感分析、命名实体识别 NER、词性标注 POS 和自然语言推理 NLI) 上使用了两种不同的评估方法:
- 探测 (Probing) : 你“冻结”预训练模型。不允许模型的权重发生变化。你只在模型的输出之上训练一个小的分类器。
- *这测试的是什么: * 模型在预训练期间学到的表示的原始质量。模型是否在没有额外帮助的情况下自然地理解情感或语法?
- 微调 (Fine-tuning) : 你允许模型中的所有参数在针对新任务的训练过程中进行更新。
- *这测试的是什么: * 模型的适应性。模型能否有效地重组自身以解决特定问题?
关键结果
结果揭示了架构与目标之间迷人的相互作用。事实证明,没有单一的“最佳”目标——这完全取决于你使用的架构。
发现 1: 对于编码器-解码器,翻译为王
当观察双栈模型 (BART 风格架构) 时,结果是决定性的。
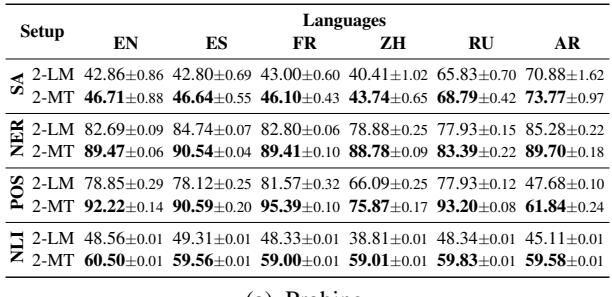
表 1 显示了探测实验的准确率。在几乎所有的语言和任务中, 2-MT 模型 (在翻译上训练) 的表现一致优于 2-LM 模型 (在去噪上训练) 。
- 解读: 翻译的显式信号迫使编码器-解码器比简单地去噪文本更有效地对齐不同语言的表示。如果你正在构建一个用于多语言任务的编码器-解码器模型,翻译数据是非常有价值的。
发现 2: 单栈模型的意外
单栈模型的结果更加微妙,并挑战了传统观念。
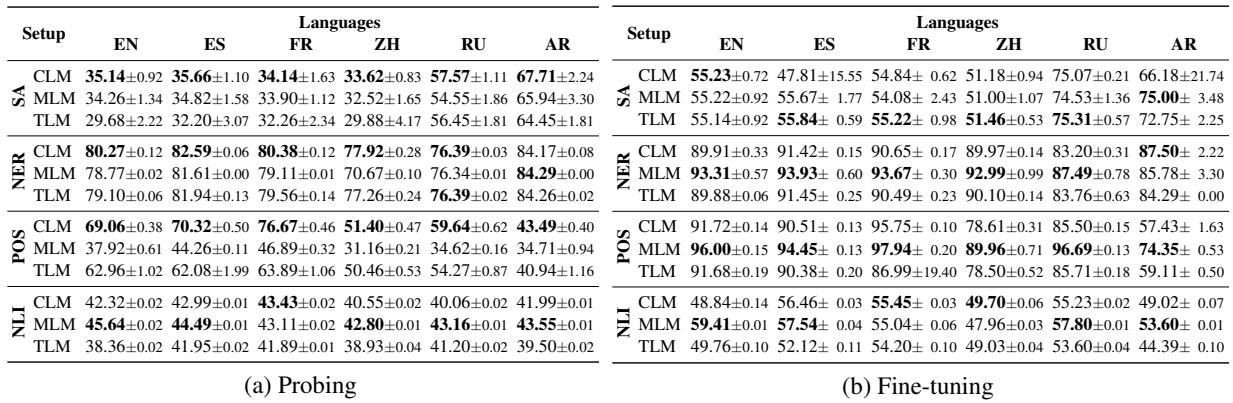
表 2 强调了单栈模型的探测准确率。
- CLM 的冲击: 因果语言模型 (GPT 风格) 在探测场景中表现出奇地好,经常击败掩码语言模型 (BERT 风格) 。这是反直觉的,因为 BERT 模型是双向的 (它们可以看到整个句子) ,这通常有助于理解像 NER 或 POS 标注这样的任务。
- TLM 的失望: 尽管可以使用翻译数据,但 TLM (翻译语言模型) 并没有在单栈类别中占据主导地位。它并没有持续优于标准的 CLM。
发现 3: 微调拉平了差距
虽然探测告诉我们模型的原始知识,但微调告诉我们它的实用效用。
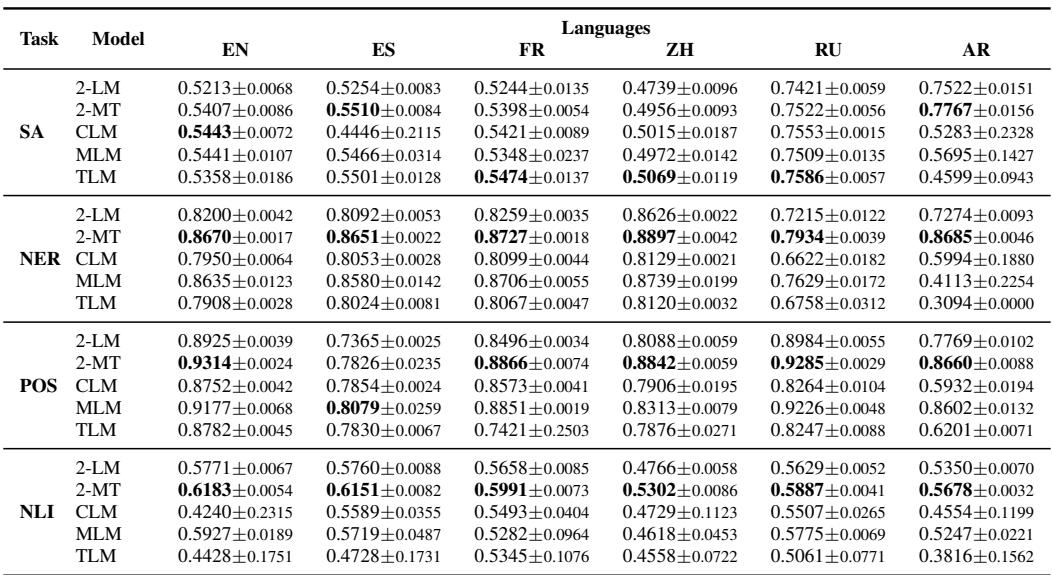
表 7 显示了微调后的 Macro F1 分数。在这里,格局发生了变化:
- MLM 的复苏: 虽然 MLM (BERT) 在探测中表现不如 CLM,但在微调时它变得非常有效,特别是对于词性标注 (POS) 和命名实体识别 (NER)。
- 2-MT 的主导地位: 机器翻译模型 (2-MT) 即使在微调后仍然是表现最好的模型之一。它在许多类别中取得了最高分,这表明它在预训练中学到的“翻译直觉”提供了一个坚实的基础,很容易适应特定任务。
这为什么重要?
这就为 NLP 的学生和研究人员提供了几个关键的启示:
1. 架构决定目标
你不能简单地说“翻译是最好的预训练目标”。它是最好的目标,前提是你使用的是编码器-解码器架构。如果你使用的是仅解码器架构,标准的因果语言建模可能就足够了。这种架构与目标之间的耦合在更广泛的讨论中经常被忽视。
2. 翻译的力量
最重要的发现是 2-MT 模型的强大。在基于海量单语言网络文本 (CommonCrawl) 训练的“基础模型”时代,这项研究表明我们可能并未充分利用平行数据。 一个学会翻译的模型是被迫去学习语义的。它不能仅仅依赖于单词彼此相邻的统计模式;它必须理解金融背景下的 “bank” (银行) 与河流背景下的 “bank” (河岸) 翻译是不同的。
3. 控制变量的重要性
最后,这篇论文也是优秀实验设计的教程。通过严格控制数据集的大小和重叠 (如下方的 表 4 和 表 5 所示) ,作者确保了他们的结论在数学上是有效的。
如果他们只是简单地比较预先下载的 mBERT 和预先下载的 mT5,结果将毫无意义,因为训练数据是不同的。
结论
研究人员得出的结论是, 多语言翻译是一个高效但探索不足的预训练目标。虽然业界竞相开发越来越大的单语言模型,但这篇论文表明,翻译中发现的显式跨语言信号能构建更优越的表示,特别是对于编码器-解码器模型。
对于设计自己模型的学生来说: 如果你能获得平行数据 (双语文本) ,使用翻译目标可能会给你的模型带来简单的去噪或语言建模无法比拟的“语义提升”。多语言 AI 的未来可能不仅仅在于阅读更多文本,而在于学会翻译它。