](https://deep-paper.org/en/paper/2407.16920/images/cover.png)
大语言模型 (LLM) 是令人惊叹的知识系统,但它们有一个长期存在的缺陷: 世界在不断变化,而它们的内部知识却常常停滞不前。当我们试图教给它们新的事实——比如新当选的领导人或新的科学发现——它们常常会遭受灾难性遗忘,即学习新信息会导致已有知识的丢失。这就像往一个满杯子里倒水——新水会把原来的水挤出去。
持续知识学习 (Continual Knowledge Learning,CKL) 领域旨在让模型在学习新事实的同时保留旧知识。现有的策略——如正则化、架构修改以及基于重放的再训练——在一定程度上能减少遗忘。然而,它们都依赖于同一个低效的基本假设: 训练数据中的每个词元 (token) 都同等重要。
想象一下模型在学习句子 “美国总统是拜登”。在训练过程中,模型在学习 “The president of…” 这类它早已掌握的语法部分上投入的精力,与学习将“拜登”与“美国总统”联系起来的关键事实更新一样多。这种不必要的重复学习浪费了计算资源,甚至可能加剧遗忘。
如果我们能训练模型成为一个更具选择性的学习者,只将精力集中在文档中最有用的词元上,会怎样呢?这个问题启发了论文 《Train-Attention: 通过元学习在持续知识学习中找到重点》。作者提出了 Train-Attention 增强语言模型 (TAALM) ——一个通过元学习动态预测词元重要性的框架。通过应用自适应的“训练注意力”权重,TAALM 能够执行有针对性的知识更新,实现更快的学习并最大限度地减少遗忘。
本文将探讨:
- 传统持续学习方法的核心低效问题。
- Train-Attention 如何利用元学习来预测“有用”的词元。
- 一个新基准测试 LAMA-CKL 的介绍,它揭示了学习与保留之间的权衡。
- TAALM 所取得的最新结果。
挑战: 在不遗忘的情况下学习
持续知识学习 (CKL) 的目标是在两种相互对立的力量之间保持平衡:
- 可塑性 (Plasticity) : 快速吸收新知识的能力。
- 稳定性 (Stability) : 保持已有信息而不遗忘的能力。
传统方法通常分为三类:
- 正则化 (Regularization) : 增加损失惩罚以抑制模型参数相对原始状态的剧烈变化 [Kirkpatrick et al., 2017]。
- 架构方法 (Architectural approaches) : 冻结大部分参数,训练小型的适配器模块 (如 LoRA、K-Adapters) ,以减少干扰。
- 重放 (Rehearsal) : 在训练中混合旧数据与新数据,以强化已学知识。
虽然这些方法在一定程度上有效,但它们都有一个共同的问题——认为每个词元的学习贡献是相等的。

图 1: 标准统一权重 (左) 与 Train-Attention (右) 的比较。后者通过动态学习词元权重,在更新过程中强调重要信息。
在 CKL 场景下,这种低效会进一步放大,因为模型已经掌握了大量世界知识和语法。统一更新每个词元会导致两个问题:
- 加剧遗忘: 过度更新的参数会扭曲之前学习到的事实的内部表示。
- 收敛变慢: 模型浪费算力在重新学习不相关或冗余内容上。
反之,如果模型能选择性地关注那些真正涉及知识更新的词元——例如上例中的 “拜登”——会如何?作者们的假设是:** 聚焦于重要词元会提升 CKL 性能**。实验结果强有力地验证了这一点。
核心思想: Train-Attention 增强语言模型 (TAALM)
TAALM 在标准语言模型训练基础上做出了一个简单却强大的改进: 用由元学习器预测的动态学习权重替换统一的词元权重。
从统一损失到词元加权学习
常规的因果语言模型最小化困惑度 \( PPL_\theta \),定义如下:
\[ PPL_{\theta} = -\frac{1}{N} \sum_{i} \log p(x_i \mid x_{TAALM 将其替换为 词元加权学习 (Token-Weighted Learning,TWL) ,其中每个词元都有自己的权重 \(w_i\):\[ PPL_{\theta}^{TW} = -\frac{1}{\sum_i w_i} \sum_i w_i \log p(x_i \mid x_{
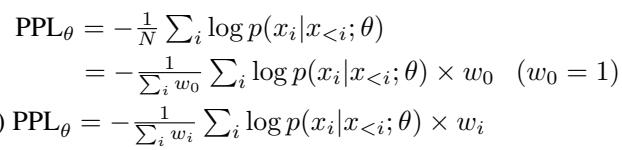
图 2: 标准损失 (统一权重) 与词元加权学习目标的区别。
词元权重反映了一个词元对模型下游任务的资讯价值或有用性。问题由此变成:** 模型如何发现哪些词元是有用的?**
将词元重要性定义为“有用性”
过去的词元选择方法通常以错误率作为信号——预测错误率高的词元被视为重要 [Hou et al., 2022; Lin et al., 2024]。然而,高错误率并不总意味着高价值;难预测的词元可能只是噪声,而非有用知识。
作者提出重新定义词元重要性为有用性 (usefulness) ——即该词元在未来相关任务中的预期效用。直观上,知道美国总统是谁远比巩固语法规则更有价值。
这一重新定义使问题可被重塑为一个元学习 (meta-learning) 任务: 训练模型学习如何学习哪些词元有用。
Train-Attention 的工作原理
TAALM 包含两部分:
- 基础模型 (\( \theta \)) ——负责知识学习的语言模型。
- Train-Attention 模型 (\( \phi \)) ——预测词元重要性权重的元学习器。

图 3: (a) Train-Attention 架构用一个输出单值的“TA 头”替换语言模型的输出层,为每个词元输出一个权重。(b) TAALM 将 Train-Attention 与基础语言模型结合以执行词元加权更新。
Train-Attention 模块结构与 LLM 相似,但将最后的线性层替换为一个轻量级的输出头,为每个词元输出一个介于 [0,1] 的标量——即预测权重。这些权重用于引导基础模型的更新。
元学习循环
训练该元学习器包括两个交替阶段——学习 (learning) 与 求解 (solving) :
预测权重: \( \phi \) 根据数据 \( \mathcal{D} \) 输出词元权重 \( W_{\mathcal{D},\phi} \)。
模拟更新: 基础模型 \( \theta \) 通过一次词元加权训练更新:
\[ \theta' \leftarrow \theta - \alpha \nabla_{\theta} \mathsf{TWPPL}_{\theta}(\mathcal{D}, W_{\mathcal{D},\phi}) \]评估性能: 使用临时模型 \( \theta' \),在相关任务 \( \mathcal{T_D} \) 上测试并计算损失 \( \mathcal{L}_{\theta'}(\mathcal{T_D}) \)。
更新元学习器: 基于该损失更新 \( \phi \):
\[ \phi \leftarrow \phi - \beta \nabla_{\phi} \mathcal{L}_{\theta'}(\mathcal{T_D}) \]

图 4: 元学习通过对齐词元权重,使单步更新将基础模型推向理想性能。

图 5: 系统交替更新 \( \theta \) (基础模型) 与 \( \phi \) (元学习器) 。梯度在两者间流动,从而捕捉高阶依赖关系。
每次对 \( \phi \) 的外层更新后,内部模型 \( \theta' \) 都会重置到初始状态,以确保 \( \phi \) 学到的是通用权重模式,而非记忆具体数据。
训练完成后,冻结的 \( \phi \) 可为任意兼容 LLM 生成词元权重,实现高效的持续知识更新。
新的基准测试: LAMA-CKL
为更准确地评估学习与保留之间的权衡,作者基于 LAMA 数据集 [Petroni et al., 2019] 构建了 LAMA-CKL。此前的基准 (如 TEMPORALWIKI [Jang et al., 2022]) 由于证据重叠,模糊了新旧知识的界限。LAMA-CKL 通过提供两个明确分离的数据集解决了这一问题。

图 6: LAMA-CKL 工作流程——模型在“待学习”数据上训练,并在每个周期后测试“待学习” (可塑性) 与“不能忘” (稳定性) 两类任务。
- 待学习集 (TO-LEARN set) : 500 个模型最初答错的时变事实 (测试可塑性) 。
- 不能忘集 (NOT-TO-FORGET set) : 500 个模型最初答对的非时变事实 (测试稳定性) 。
每个周期包括在待学习集上训练,然后在两集合上测试。该基准衡量四个指标:** Top Acc**、Epoch、NF Acc 以及 Total Knowledge (Top + NF) 。理想系统应学得快、忘得少。

图 7: 词元权重热力图显示 Train-Attention 优先关注实体类词元,而非通用语法。
实验结果
LAMA-CKL 性能表现

图 8: TAALM 在“待学习”准确率上迅速提升,并在“不能忘”准确率上保持良好稳定性。

表 1: TAALM 在 4 个周期内实现最高准确率 (0.429) 和最大总知识容量,超越所有基线方法。
TAALM 仅用 4 个周期就达到了 0.429 的“待学习”准确率,是次优方法 (RHO-1) 的三倍,收敛速度提升四倍。同时,TAALM 能有效保留已有知识——在可塑性与稳定性间实现了最优平衡。
距离最优解有多近?“神谕”实验
作者测试了理论上限: 手动仅为事实对象词元分配权重 1——即“神谕 (Oracle) ”版本。

图 9: TAALM (绿色) 几乎达到“神谕” (橙色) 的上限性能,实现其最大学习能力的约 78%。
结果表明,词元加权学习比标准微调显著提升,而 TAALM 达到“神谕”方法最高准确率的 78.2%,证明元学习能有效逼近最优权重分配。
与其他方法的协同作用
Train-Attention 在损失层级操作,因此能够轻松与现有方法 (如 K-Adapter、Mix-review、RecAdam) 结合。结合后,所有基线方法同时展现更强的学习与稳定性,凸显了 TAALM 的通用性。
TEMPORALWIKI 上的性能表现
TAALM 在标准 CKL 基准 TEMPORALWIKI 上同样表现优异。虽然主要训练于 LAMA-CKL,但在不同时间领域上仍具备良好泛化能力。

表 2a: 无论知识是否变化,TAALM 在各时间段 (0910、1011、1112) 均取得最低困惑度。

表 2b: TAALM 在 K-Adapter 架构下保持最佳性能,验证了其跨架构的稳健性。
TAALM 在所有实验设置下都表现卓越,再次证明了学习词元“有用性”能够捕获可迁移的模式。
LAMA-CKL 的意义
已有基准 (如 TEMPORALWIKI) 因数据重叠与规模庞大 (每时期含数十万文档) 而无法清晰呈现可塑性–稳定性权衡。LAMA-CKL 通过拆分变异与不变子集,并基于精心筛选的小规模多周期数据进行训练,清晰展现了可解释的学习动态。
结论与展望
Train-Attention 的洞察优雅而简洁: 并非每个词都值得同等关注。通过将词元重要性重新定义为有用性并以元学习预测这些权重,TAALM 教会模型在学习时关注关键点。它带来了:
- 更快的新知识学习速度。
- 最小化已有知识遗忘。
- 与现有 CKL 方法兼容并产生协同效应。
Train-Attention 标志着迈向随世界变化而演化的自适应 LLM 的重要一步。虽然其训练依赖于成对数据–任务样本,未来研究可探索更广泛领域——例如通过搜索或合成任务生成自动构造此类样本。
通过优化模型如何学习,而非仅关注学什么,TAALM 代表了一种范式转变: 让 LLM 不仅更大,更能成为更聪明的学习者。