](https://deep-paper.org/en/paper/2408.01046/images/cover.png)
当我们阅读新闻文章或关注复杂的叙事时,我们不仅仅是孤立地处理一个个句子。我们会本能地寻找联系。我们会问自己: 作者为什么要这么说?这句话回答了关于上一句话的什么问题?
这种认知过程是一个被称为讨论中的问题 (Question Under Discussion, QUD) 的语言学框架的基础。它将语篇视为问题和答案的层级结构。虽然人类可以自然地做到这一点,但教机器解析这些结构是出了名的困难。现有的模型往往难以生成在上下文中合理的问题,或者无法正确地连接句子。
在这篇文章中,我们将探讨 QUDSELECT , 这是由加州大学洛杉矶分校 (UCLA) 和北京大学的研究人员提出的一个新颖框架。该论文提出了一种改进 QUD 解析的方法,从僵化的流水线转向模仿我们评估问题质量的“选择性解码”策略。
理解问题: 什么是 QUD?
在深入了解架构之前,我们需要理解这项任务。QUD 解析是一种语篇分析形式。其核心思想是,文本中的每一个句子 (除第一句外) 都可以被视为对前文中某个句子触发的隐含问题的回答。
让我们分解一下术语:
- 锚句 (Anchor Sentence) : 前文中触发问题的句子。
- 问题 (QUD) : 连接锚句与当前句子的隐含问题。
- 答句 (Answer Sentence) : 正在处理的当前句子,它回答了生成的问题。
QUD 的三条黄金法则
对于一个有效的 QUD 结构来说,仅仅生成任意问题是不够的。理论语言学定义了必须满足的三个具体标准:
- 答案兼容性 (Answer Compatibility) : “答句”必须确实回答了该问题。
- 已知性 (Givenness) : 问题不应引入新信息 (幻觉) 或“泄露”答案。它应该只包含上下文中存在或常识中的概念。
- 锚句相关性 (Anchor Relevance) : 问题必须与锚句相关。它应该感觉像是对刚才所说内容的自然追问。
为了形象化这一点,请看下面关于电影《阿甘正传》 (Forrest Gump) 的示例文本。

在图 1 中,注意句子 3 (“这是自 1960 年代以来获得提名最多的…”) 是如何连接到句子 1 (“《阿甘正传》是一部…”) 的。隐含的问题是“哪部电影获得的奥斯卡提名最多?”这种结构揭示了论证的逻辑流向。该图还强调了有效性检查: S2 回答了问题吗?是的。问题是否仅依赖于已知上下文?是的。它与 S1 相关吗?是的。
此前方法的局限性
在 QUDSELECT 之前,大多数自动化此过程的尝试都使用流水线方法 (pipeline approach) 。
- 步骤 1: 查看上下文并预测哪个句子作为锚句。
- 步骤 2: 给定该锚句,生成一个问题。
流水线的问题在于缺乏“全局视角”。如果模型在第 1 步选了一个糟糕的锚句,第 2 步也就注定失败。此外,标准语言模型 (LLMs) 生成的的问题往往听起来通顺,但无法满足特定的 QUD 标准——例如,它们可能会包含尚未披露的细节 (违反了已知性) 。
QUDSELECT 框架
研究人员提出了一种整合这些不同步骤并显式强制执行理论标准的解决方案。他们的框架 QUDSELECT 包含两大创新: 通过指令微调进行的联合训练 (Joint Training via Instruction Tuning) 和选择性解码 (Selective Decoding) 。
创新点 1: 联合训练
QUDSELECT 没有将锚句预测和问题生成分开,而是训练模型同时完成这两项任务。研究人员将任务重新表述为一个指令微调问题。
他们向模型输入上下文和目标“答句”。指令要求模型输出格式化的字符串:
“句子 [Answer ID] 由句子 [Anchor ID] 锚定,回答了‘[Question]’的问题。”
通过强迫模型一口气预测锚句和问题,模型学会了寻找好的触发点与提出好的问题之间的依赖关系。
创新点 2: 选择性解码
这是论文的核心贡献。即使进行了联合训练,LLM 仍可能生成次优问题。为了解决这个问题,作者引入了一种先选择后验证的推理策略。
QUDSELECT 不是采用模型最可能的一个输出,而是生成多个候选项,并根据我们之前讨论的三个理论标准对其进行评分。
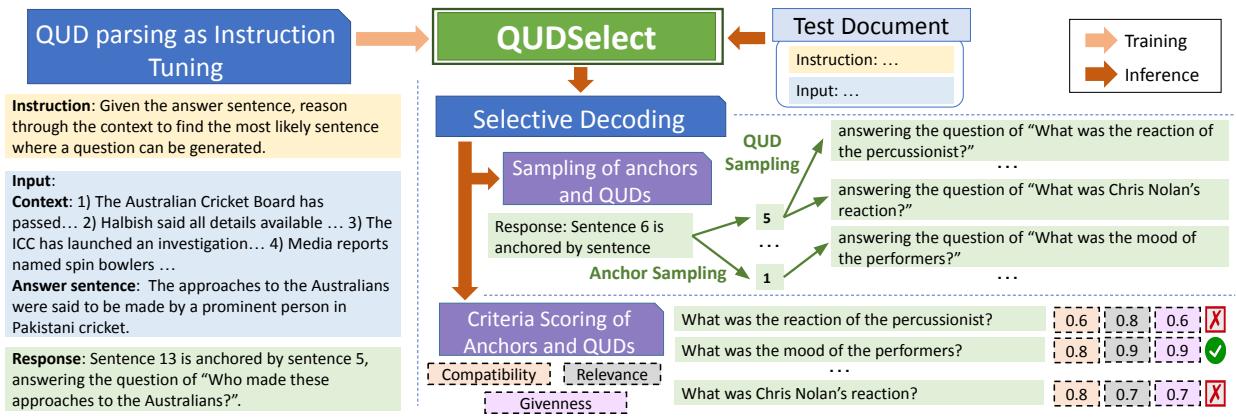
如图 2 所示,过程如下:
- 采样: 模型使用集束搜索 (beam search) 生成多对 (锚句,问题) 候选项。它采样不同的潜在锚句,并针对每个锚句采样不同的潜在问题。
- 标准评分: 每个候选对都通过三个特定的评分函数 (详见下文) 。
- 选择: 将分数相加,总分最高的候选项被选为最终的 QUD。
标准是如何评分的?
研究人员需要一种无需人工干预即可在推理过程中自动化“黄金法则”的方法。他们为每个标准实现了巧妙的、无需训练的评分器:
- 答案兼容性评分器:
- *方法: * 他们将其视为自然语言推理 (NLI) 任务。
- 实现: * 使用现成的 NLI 模型,他们检查答句蕴含 (entails) *问题的概率。如果答案暗示问题是有效的,则分数较高。
- 已知性评分器:
- *方法: * 重叠度测量。
- 实现: * 他们比较问题中的实词 (名词、动词等) 与上下文。如果问题包含上下文中没有*出现的词 (且不是常见停用词) ,则可能是在产生幻觉或泄露答案。分数基于基于上下文的单词百分比。
- 锚句相关性评分器:
- *方法: * 焦点重叠。
- *实现: * 他们提取问题的“焦点” (通常是主要的名词短语) ,并检查其与锚句的单词重叠情况。如果问题询问的是锚句中提到的内容,则是相关的。
实验与结果
为了验证该框架,作者在 DCQA 数据集上测试了 QUDSELECT,这是一个包含新闻文章和问题的语篇理解标准基准。他们将框架应用于开源模型 (LLaMA-2-7B, Mistral-7B) 和闭源模型 (GPT-4) 。
性能指标
评估非常严格,既使用了自动指标 (训练用于判断 QUD 质量的分类器) ,也使用了人工评估 (专家标注员) 。
结果令人印象深刻。如下表 1 所示,QUDSELECT 显著优于基线流水线方法和标准提示方法。
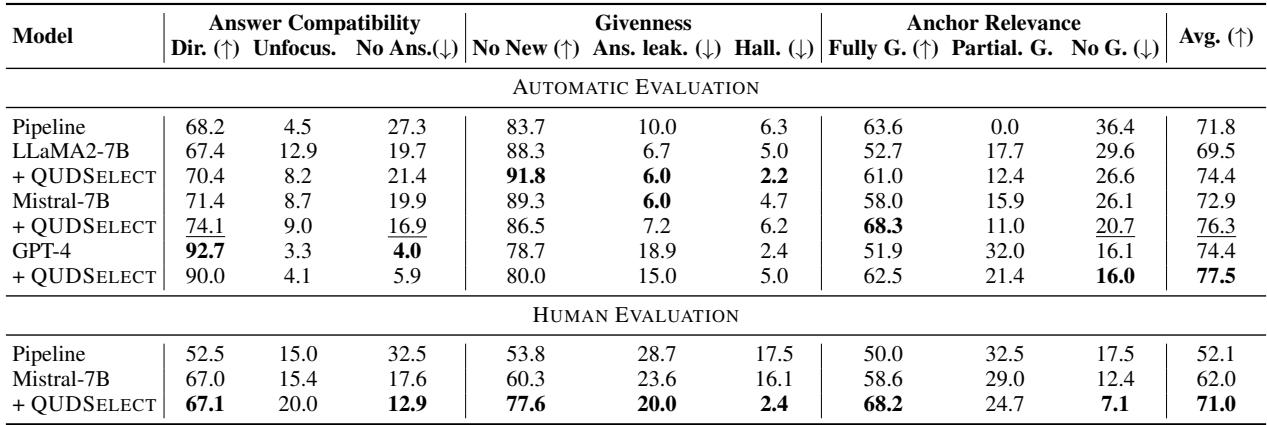
结果的关键要点:
- 击败流水线: 在人工评估中,配备 QUDSELECT 的 Mistral-7B 模型得分为 71.0% , 而流水线基线仅为 52.1% 。
- 优于 GPT-4: 有趣的是,带有 QUDSELECT 的开源 Mistral 模型在多项指标上接近或超过了标准 GPT-4 提示的效果,证明了较小的模型配合更好的解码策略可以实现越级表现。
- 一致性: 在所有三个标准 (答案兼容性、已知性和锚句相关性) 上都能看到改进。
采样更多候选项有帮助吗?
人们可能会问: 我们需要采样多少个候选项才能获得好的结果? 研究人员进行了超参数分析,将候选项数量 (\(k\)) 从 1 增加到 20。
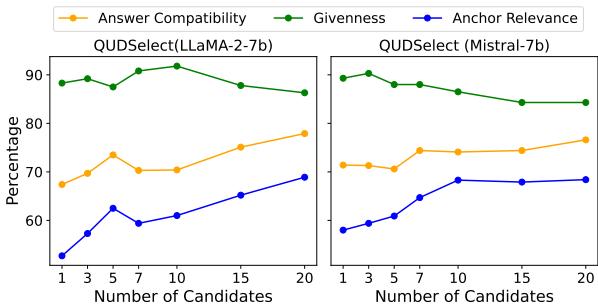
图 3 揭示了一个明显的趋势。随着候选项数量的增加, 答案兼容性 (橙线) 和锚句相关性 (蓝线) 稳步提高。
已知性 (绿线) 有一个轻微的权衡,随着 \(k\) 的增加略有下降。作者认为,为了在相关性和可回答性方面获得显著收益,这是很小的代价。他们在主要实验中将 \(k=10\) 选为最佳平衡点。
定性分析: 眼见为实
数字固然重要,但例子更能说明问题。让我们看看 QUDSELECT 和标准流水线模型在真实新闻片段上的直接比较。

在表 2 中,我们看到了流水线方法的明显失败模式。
- 流水线错误: 对于句子 \(s_3\),流水线模型生成了“格伦 (Glenn) 认为……是什么?”标注者将其标记为“非答案”和“答案泄露”。它本质上是对“格伦” (出现在句子 2 中) 产生了幻觉,即使锚句是句子 2,但生成的问题并不适合句子 3 中的答案。
- QUDSELECT 的成功: 对于同一个句子,QUDSELECT 生成了“为什么美国出口……很重要?”这个问题由文本直接回答,只使用了已知概念,并且完全基于锚句。
这种比较突显了评分标准如何过滤掉标准模型经常产生的“幻觉”或不相关问题。
结论与启示
QUDSELECT 论文为 NLP 研究人员和学生展示了重要的一课: 模型架构不是一切;推理策略至关重要。
通过将 QUD 解析重构为联合任务并应用选择性解码 , 作者无需巨大的模型即可实现最先进的结果。他们展示了我们可以通过生成多个选项并以算法选择最佳选项,来“引导”LLM 遵守理论语言学约束 (答案兼容性、已知性、相关性) 。
为什么这很重要?
理解语篇结构是 NLP 的下一个前沿领域。如果计算机能够理解连接句子的问题,它们就能:
- 更好地总结: 通过理解讨论的要点。
- 更准确地进行事实核查: 通过验证某个主张是否真正回答了上下文的隐含问题。
- 生成更连贯的文本: 通过确保生成的每个句子都在逻辑上紧承上一句。
QUDSELECT 为实现这些目标提供了一条稳健的、基于理论的路径,证明了有时获得正确答案的最佳方法是生成几个选项并检查你的结果。