](https://deep-paper.org/en/paper/2408.12194/images/cover.png)
如果你最近使用过搜索引擎,你很可能已经从稠密检索 (Dense Retrieval) 技术中受益。与 90 年代寻找精确关键词匹配的搜索引擎不同,现代系统试图理解你查询背后的含义。它们将你的文字转化为一串数字 (向量) ,并寻找具有相似向量的文档。
多年来,这项技术的骨干一直是像 BERT 和 T5 这样的模型。它们在各自的领域表现出色,但也遇到了瓶颈。它们在处理长文档时很吃力,面对新领域 (如法律或医疗文档) 的数据时往往表现不佳,而且训练它们需要海量的标注数据。
但最近,我们见证了像 Llama、Qwen 和 GPT 这样的大型语言模型 (LLM) 的爆发。我们知道它们擅长生成文本,但它们擅长寻找文本吗?
在论文 “Large Language Models as Foundations for Next-Gen Dense Retrieval: A Comprehensive Empirical Assessment” (大型语言模型作为下一代稠密检索的基石: 一项全面的实证评估) 中,研究人员进行了一项大规模研究来回答这个问题。他们测试了超过 15 种不同的模型,看看 LLM 是否能取代传统的编码器。结果令人着迷,并预示着我们构建搜索系统的方式将发生范式转变。
在这篇文章中,我们将剖析他们的方法论、背后的数学原理,以及六个证明“越大可能真的越好”的关键实验。
传统检索的瓶颈
在深入探讨解决方案之前,让我们先了解一下问题所在。
在稠密检索 (DR) 中,目标是将用户的查询 (\(q\)) 和候选文档 (\(p\)) 映射到一个共享的“嵌入空间”中。如果查询和文档在语义上相似,它们的向量在这个空间中应该靠得很近。
为了计算这种“亲密度”,我们通常使用相似度评分。数学原理很直观: 我们取查询的嵌入 (\(h_q\)) 和文档的嵌入 (\(h_p\)),然后计算内积 (或点积) 。
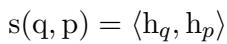
多年来,获取这些 \(h\) 向量的标准方法是使用 BERT。BERT 处理文本 Token 序列 (\(T\)) 并为每个 Token 输出一个向量。为了得到代表整个句子的单个向量,我们通常提取句子开头特殊的 [CLS] (分类) Token 所对应的向量。

虽然有效,但基于 BERT 的模型相对较小 (通常在 5 亿参数以下) 。它们缺乏理解复杂指令所需的“世界知识”,也难以泛化到它们未被明确训练过的主题上。
核心方法: 将 LLM 转变为检索器
研究人员建议用大规模的仅解码器 (Decoder-only) LLM (如 Llama-2 或 Qwen) 来取代 BERT。然而,这存在结构上的差异。BERT 是双向阅读文本的 (一次看到整个句子) 。LLM 是因果的;它们从左到右阅读,预测下一个词。
由于这种因果注意力机制,句子的“含义”累积在最末端。因此,研究人员不是使用起始 Token,而是从 句尾 ([EOS]) Token 提取嵌入。
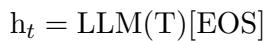
训练过程
你如何教一个原本设计用来写故事或代码的 LLM 变成一个搜索引擎?答案是使用 对比学习 (Contrastive Learning) 。
团队利用了 InfoNCE 损失函数 。 其理念很简单: 给定一个查询 \(q_i\),模型应该最大化其与正例文档 \(p_i^+\) (正确答案) 的相似度得分,同时最小化其与一组负例文档 \(p_j^-\) (错误答案) 的得分。
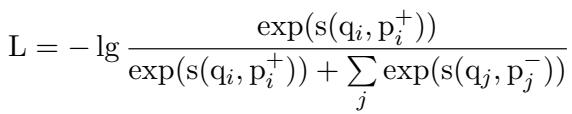
为了使评分更加精确,他们使用了带温度缩放的余弦相似度。温度参数 (\(\tau\)) 有助于控制概率分布的锐度,使模型更具辨别力。
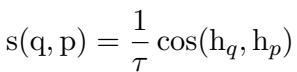
建立了数学基础后,研究人员着手测试了超过 15 个骨干模型,范围从 1 亿参数的小模型到 320 亿参数的庞然大物。他们主要关注两个问题:
- LLM 是否比非 LLM 模型提供了特定的优势?
- 规模 (参数量) 和预训练数据量是否重要?
让我们来看看结果。
实验 1: 域内准确率
第一个测试是在检索的“主场”进行的: MS MARCO 数据集。这是一个包含真实网络搜索查询的海量集合。研究人员想知道这些模型在标准搜索数据上训练和测试时的表现如何。
比较对象包括传统模型 (BERT, T5) 和现代 LLM (Llama, Gemma, Qwen) 。
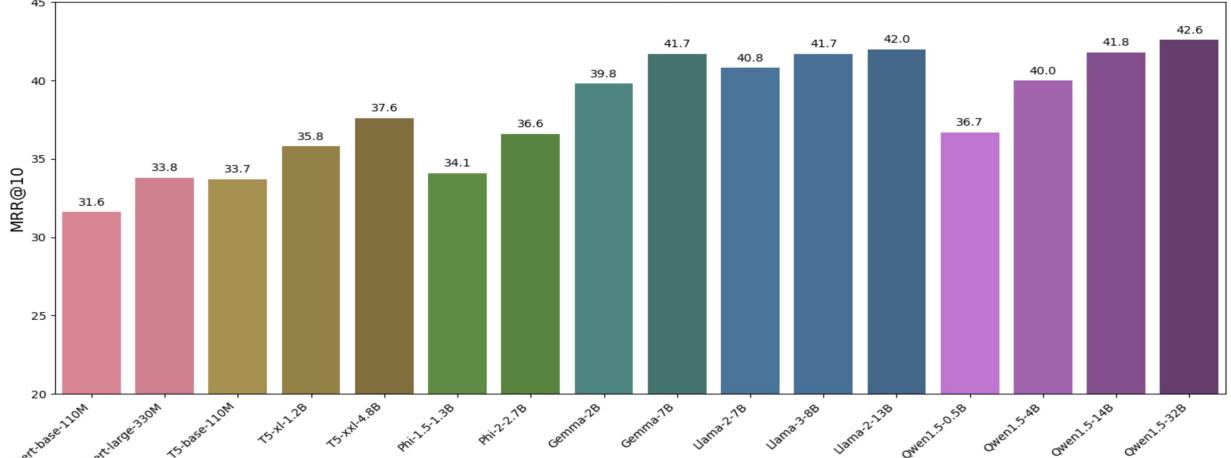
如上图 1 所示,趋势非常明显: 扩大规模能提升性能 。
看看 Qwen1.5 系列 (紫色柱状条) 。微小的 0.5B 模型得分约为 36.7。随着规模扩大到 4B、14B,最后到 32B,性能稳步攀升至 42.6。
也许最惊人的发现是 LLM 始终优于非 LLM 模型 。 即使是较小的 LLM (如 Gemma-2B) 也比最大的传统模型 (如 T5-xxl) 表现更好,尽管它的参数更少。这表明 LLM 接触到的高质量预训练数据 (数万亿 Token) 使它们在理解语言细微差别方面从根本上优于老一代的 BERT。
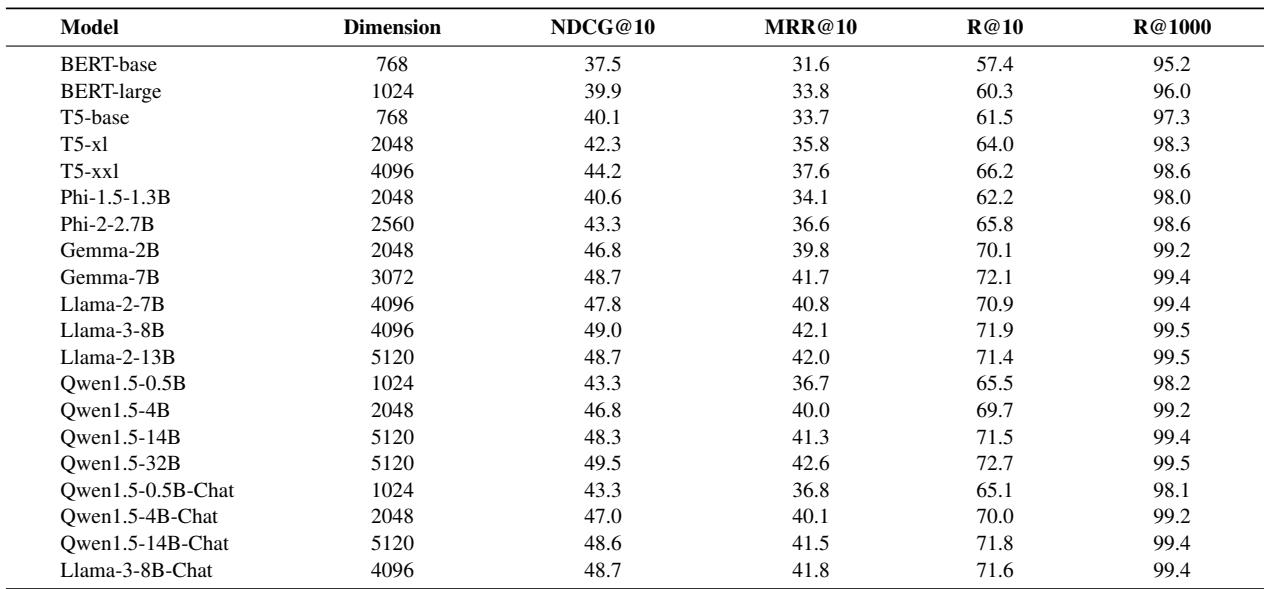
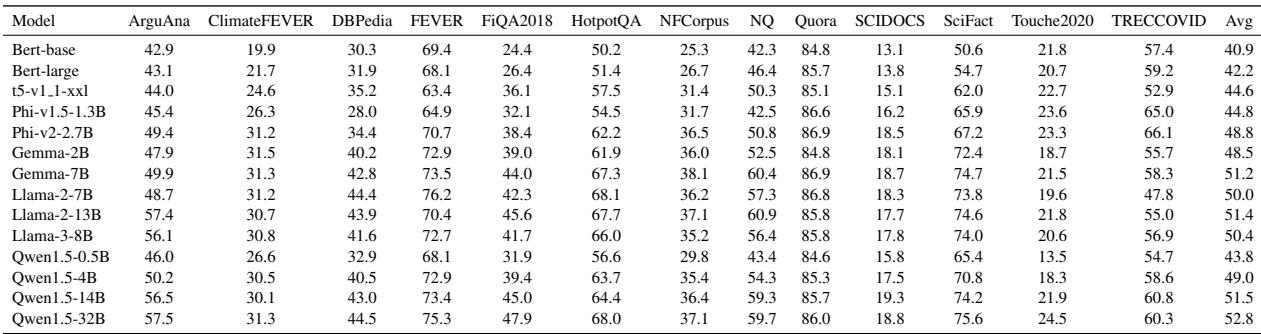
对于那些对原始数据感兴趣的人,下表详细列出了每个测试模型的具体指标 (NDCG@10 和 MRR@10) 。
实验 2: 数据效率
深度学习最大的槽点之一就是需要海量的标注数据。LLM 能否用更少的数据学得更快?
研究人员跟踪了三个模型——BERT-large、Qwen-0.5B 和 Llama-2-7B——在训练步骤中的性能变化。
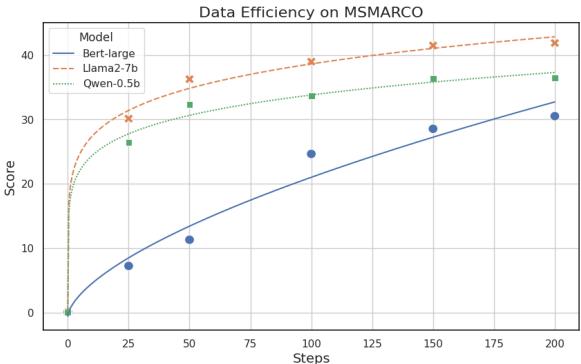
图 2 展示了学习速度上的巨大差距。
- 蓝线 (BERT-large) 爬升艰难,需要许多步才能达到不错的得分。
- 橙线 (Llama-2-7B) 几乎立即飙升。
仅仅经过 100 个训练步,Llama 模型就已经大幅超越了 BERT 模型。这意味着,如果你有一个只有很少标注数据的专业领域 (例如公司内部的私有数据库) ,使用较大的 LLM 骨干网络很可能会比试图从头微调一个 BERT 模型更快地获得好结果。
实验 3: 零样本泛化能力
在见过的数据上表现出色很容易。真正的智能测试是 零样本泛化 (Zero-Shot Generalization) : 在模型从未见过的任务上表现出色。
研究人员选取了在 MS MARCO (网络搜索) 上训练的模型,并立即在 BEIR 基准测试 上对其进行测试,该基准测试包括检索医学论文、财务建议和事实核查等多样化任务。
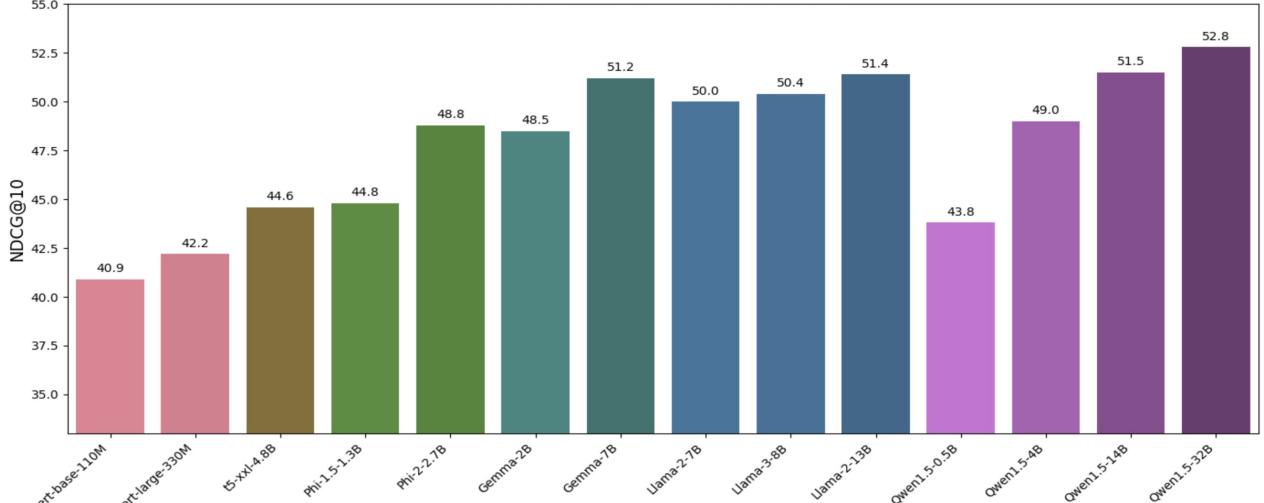
图 4 显示了这 13 个未见过任务的平均性能。在这里,模型大小与性能之间的相关性是不可否认的。
- BERT-base 得分为 40.9。
- Qwen1.5-32B 得分为 52.8。
在零样本检索的世界里, 参数量为王 。 更大的模型在预训练期间可能“阅读”了更多的医学、金融和技术文本,因此无需任何微调就能将这些知识泛化到检索任务中。
有关这些模型在特定数据集 (如 “ClimateFEVER” 或 “HotpotQA”) 上的表现细分,请参阅下表:
实验 4: 长文本检索
像 BERT 这样的传统模型有一个硬性限制: 它们通常一次只能处理 512 个 Token (单词/片段) 。如果文档比这更长,模型就必须将其截断,可能会丢失文本末尾的关键信息。
然而,LLM 通常是基于巨大的上下文窗口 (4096 个 Token 或更多) 进行训练的。研究人员通过在 NarrativeQA 数据集上进行测试,来验证这种预训练能力是否能转化为检索能力,该数据集涉及在长篇故事中寻找答案。
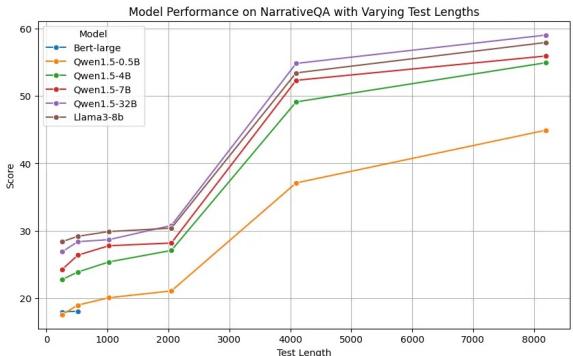
图 3 揭示了 LLM 的明显优势。
- BERT (蓝线) : 直线平躺。它根本无法处理更长的上下文。
- LLM (紫色/绿色线) : 随着文本变长 (最高达 8000 Token) ,大型 LLM (如 Qwen-32B) 的性能实际上在提升或保持明显的高位。
这种能力消除了工程师通常为了支持长文档搜索而必须构建的复杂“分块 (chunking) ”策略的需求。
实验 5: 基于指令的检索
搜索不仅仅是“关键词”。有时你想要摘要;有时你想要事实;有时你想要反面论点。
“基于指令的检索”涉及在查询前添加自然语言指令,例如 “给定一个金融问题,检索最能回答该问题的用户回复。”
研究发现这里有一个明显的分水岭:
- LLM: 添加指令后性能 提升 。 它们理解了意图。
- BERT/非 LLM: 性能 下降 。 指令充当了“噪声”,混淆了模型。
这表明基于 LLM 的检索器提供了新的灵活性。你只需更改提示词即可自定义搜索行为,而无需重新训练模型。
实验 6: 多任务学习
最后,研究人员考察了 多任务学习 。 过去,训练单个模型同时进行网络搜索、重复检测和事实核查,通常会导致“样样通,样样松”的局面——与单任务专家相比,性能通常会下降。
研究发现,虽然性能下降仍然存在,但 增加模型规模缓解了这个问题。 一个巨大的 LLM 有足够的容量来学习多个相互冲突的任务,而不会“忘记”如何做其他任务。这为构建单一的、通用的嵌入模型铺平了道路,使其能够处理组织中的每一个搜索任务。
结论与要点
在稠密检索中从 BERT 过渡到 LLM 不仅仅是一个趋势;它是能力的巨大飞跃。这篇论文的实证证据强调了三个主要结论:
- 规模很重要: 增加参数和预训练数据量能持续提高准确率、数据效率和泛化能力。
- 泛化是杀手级应用: LLM 的最大优势不仅仅是它们在网络搜索上稍微准确一点,而是它们在零样本任务和处理长文档方面要好得多。
- 多功能性: LLM 可以理解指令并处理多项任务,提供了前几代检索器根本无法比拟的灵活性。
对于进入信息检索领域的学生和从业者来说,信息很明确: 搜索的未来建立在大型语言模型的基础之上。虽然计算成本更高,但数据需求的效率和卓越的性能使 LLM 成为下一代搜索技术的明确选择。