](https://deep-paper.org/en/paper/2408.13654/images/cover.png)
引言
我们正处于大型语言模型 (LLM) 的黄金时代。像 GPT-4 这样的系统展现出了惊人的能力,能够生成代码、创作诗歌,甚至通过律师资格考试。然而,如果你曾经尝试用 LLM 解决复杂的逻辑谜题或多步演绎任务,你可能已经注意到了表面之下的裂痕。
LLM 表现得有点像一个试图完全在脑子里心算复杂数学题的学生。它们在直觉和模式匹配方面非常出色,但当一个问题需要同时记住五个不同的事实、应用特定的规则,然后利用该结果推导出新的事实时,它们往往会步履蹒跚。它们会产生关系幻觉或弄丢变量。
今天,我们将深入探讨一篇引人入胜的研究论文,题为 “Symbolic Working Memory Enhances Language Models for Complex Rule Application” (符号工作记忆增强语言模型的复杂规则应用能力) 。研究人员提出了一种新颖的“神经符号 (Neurosymbolic) ”框架,为 LLM 提供了它们迫切需要的东西: 一个结构化的外部工作记忆。通过结合 LLM 的语言灵活性与符号逻辑 (特别是 Prolog) 的严格精确性,他们创建了一个显著优于标准思维链推理的系统。
在本文中,我们将拆解 LLM 如何在复杂演绎中失败、真正的“符号工作记忆”是什么样子的,以及这个新框架如何弥合神经网络与经典逻辑之间的鸿沟。
问题所在: 当“一步步思考”还不够时
要理解解决方案,我们首先需要诊断问题。目前大多数提高 LLM 推理能力的技术都依赖于 思维链 (Chain-of-Thought, CoT) 提示。也就是我们要模型“一步步思考”。虽然这对许多任务有效,但 CoT 有一个主要弱点: 它完全依赖模型的内部状态来跟踪事实。
推理主要由两种能力组成:
- 规则落地 (Rule Grounding) : 识别哪条规则适用于当前可用的哪些事实。
- 规则执行 (Rule Implementation) : 实际应用该规则以得出新的结论。
LLM 通常擅长执行 (生成结论的文本) 。但它们在 落地 方面却出奇地差——具体来说,就是跟踪长串事实并弄清楚当下哪些是相关的。
当信息非按顺序呈现时,这个弱点就会暴露无遗。如果你给 LLM 一个完美按时间顺序排列的故事,它表现尚可。但如果你打乱事实——这更接近现实世界的数据检索场景——其表现就会崩溃。

如上文 图 1 所示,研究人员分析了 GPT-4 在 CLUTRR 数据集 (一个亲属关系推理任务) 上的表现。
- 粉色柱 (顺序) : 事实按顺序给出 (A 是 B 的父亲,B 是 C 的姐妹……) 。模型表现良好。
- 深蓝色柱 (非顺序) : 事实被打乱了。
注意那急剧的下降。对于需要 5 步推理的任务,准确率从超过 90% (顺序) 下降到近 70% (非顺序) 。模型并没有丧失推理能力;它丧失的是对上下文的跟踪。它无法有效地使规则“落地”,因为它被无序事实的噪音淹没了。
解决方案: 外部工作记忆
为了解决这个问题,作者从人类认知中汲取了灵感。当我们解决复杂的逻辑问题时,我们不会只盯着墙壁看;我们会把事情写下来。我们在大脑之外创建了一个“工作记忆”。
研究人员建议为 LLM 增加一个专门的 工作记忆 模块。与简单的文本记事本不同,这种记忆是结构化的。它以 两种格式同时 存储信息:
- 自然语言 (NL) : 可读文本 (例如,“Thomas is the grandson of James”) 。
- 符号形式: 逻辑友好的格式,特别是 Prolog 谓词 (例如,
grandson_of(Thomas, James)) 。
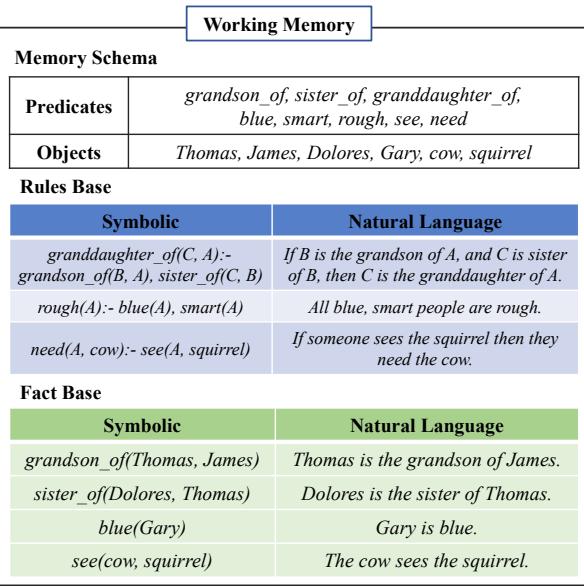
图 2 展示了这个双重存储系统。
记忆模式 (Memory Schema) (顶部) 充当字典,定义允许的对象 (人、物品) 和谓词 (关系,如 sister_of 或 needs) 。
规则库 (Rules Base) 和 事实库 (Fact Base) (底部) 存储实际的逻辑谜题。请注意,每个条目都有一个供 LLM 使用的文本版本和一个供逻辑算法使用的符号版本。这种双重性是核心创新。它允许系统利用精确的计算机代码来寻找联系 (符号化) ,同时利用 LLM 来理解和生成内容 (自然语言) 。
神经符号框架
那么,系统实际上是如何解决问题的呢?它使用一个包含三个主要阶段的循环过程: 记忆初始化、规则落地和规则执行。
这是一种 神经符号 (Neurosymbolic) 方法。“神经”指的是神经网络 (即 LLM) ,而“符号”指的是逻辑编程。

图 3 概述了整个工作流程。让我们分解每个阶段。
1. 工作记忆初始化
当系统收到一个问题 (上下文和查询) 时,它不会直接开始猜测。首先,它解析文本。 该框架将上下文分解为句子,并使用 LLM 提取 事实 和 规则 。
- *输入: * “Harold bought a dress for his daughter Marie.” (Harold 给他的女儿 Marie 买了一件裙子。)
- *提取: * LLM 识别这是一个事实,并将其转换为符号形式
father_of(Harold, Marie)(源自给女儿买裙子的语境) 。
至关重要的是,系统会动态构建 记忆模式 。 如果它遇到一个新的关系,比如“roommate_of (室友) ”,它会将其添加到模式中,以确保整个推理过程中的命名一致性。
2. 符号规则落地 (“符号”部分)
这是该框架与标准 LLM 提示分道扬镳的地方。系统不再问 LLM“接下来适用哪条规则?”,而是使用 符号规则落地 。
因为事实和规则是以符号形式存储的 (例如 sister_of(A, B)) ,系统可以运行确定性算法来检查匹配项。它执行两种类型的匹配:
- 谓词匹配 (Predicate Matching) : 规则是否需要“姐妹”?我们有关于“姐妹”的事实吗?
- 变量匹配 (Variable Matching) : 事实中的具体人物 (对象) 能否在不产生矛盾的情况下填入规则的变量 (A, B, C) 中?

图 4 清晰地展示了这个逻辑检查过程。
- 第一行 (谓词匹配) : 规则需要
sister_of和brother_of。事实 F1 是grandson_of,所以被丢弃。事实 F2 是sister_of,所以匹配。 - 第二行 (变量匹配) : 规则需要一个链条: \(A \to B \to C\)。系统检查事实中的对象 (Mary, John, James) 是否能连接在一起形成该链条。F4 (Clarence 和 Timmy) 被丢弃,因为它们无法连接到现有的链条中。
这一阶段过滤掉了噪音。LLM 永远不会被无关事实分心,因为符号引擎只会向它提供在数学上契合的特定规则和事实。
3. 基于 LLM 的规则执行 (“神经”部分)
一旦符号引擎确定了 规则 X 和 事实 Y 与 Z 是下一个逻辑步骤,它就会将它们移交给 LLM。
为什么要在这里使用 LLM?为什么不直接用代码解决? 因为现实世界的规则和事实往往是微妙的。纯符号求解器可能会因为轻微的语法不匹配而崩溃。而 LLM 是灵活的。
系统提示 LLM: “给定规则 X 和事实 Y/Z,新的结论是什么?” LLM 以自然语言和符号形式生成新的事实。这个新的事实被写回工作记忆中,循环往复。
动态模式构建
这个过程中一个微妙但至关重要的部分是记忆模式的构建方式。你不能在一个事实中有“父亲 (father) ”,在另一个事实中有“爸爸 (dad) ”——符号引擎不会知道它们是一样的。

图 6 展示了系统如何处理这个问题。它在写入任何内容之前都会执行 模式查找 。 如果一个概念已经存在,它就使用现有的符号。如果是新的,它就添加进去。这确保了符号记忆保持清晰和连贯,防止了在长对话中经常困扰 LLM 的“碎片化”问题。
实验结果
添加这个“数字草稿纸”真的有效吗?研究人员将该框架与几个基线进行了对比测试,包括标准的 Scratchpad-CoT 和其他符号方法 (如 Logic-LM) 。
他们使用了四个数据集:
- CLUTRR: 亲属关系逻辑谜题。
- ProofWriter: 抽象逻辑推理。
- AR-LSAT: 复杂的约束满足问题 (源自法学院入学考试) 。
- Boxes: 跟踪在容器间移动的物体 (状态跟踪) 。
整体性能
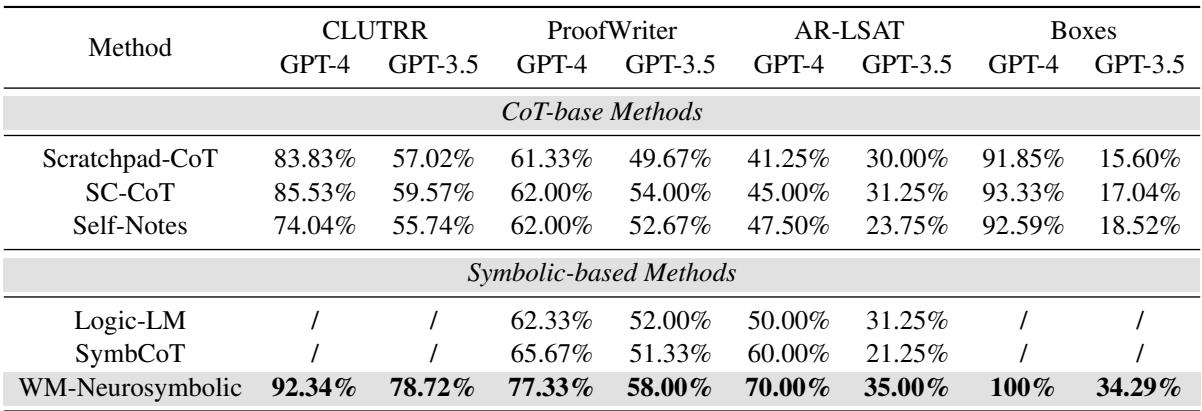
表 1 展示了主要结果。提出的方法 (WM-Neurosymbolic) 位于最后一行。
- 优势: 它在所有方面都显著优于思维链 (CoT) 方法。
- AR-LSAT: 看一下 GPT-4 的 AR-LSAT 列。标准 CoT 仅达到 41-45%。而神经符号方法跃升至 70% 。 在这一以难度著称的 AI 任务上,这是巨大的提升。
- 模型无关性: 该框架同时提高了 GPT-4 和功能较弱的 GPT-3.5 的性能,表明该架构能帮助较弱的模型“超常发挥”。
为什么它有效? (消融研究)
为了证明引擎的每个部分都是必要的,研究人员进行了消融研究 (系统地移除框架的部分以观察哪里会出问题) 。
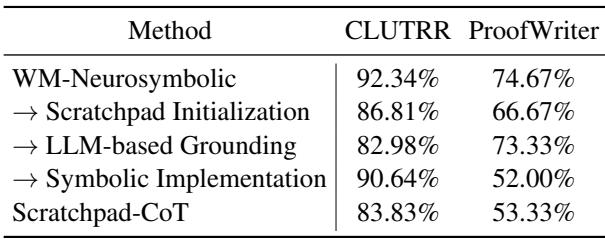
表 2 显示了剥离特征后会发生什么:
- 草稿纸初始化: 如果你使用简单的草稿纸代替结构化的模式初始化,CLUTRR 上的准确率下降了约 6%。
- 基于 LLM 的落地: 这是最能说明问题的结果。如果你用 LLM 仅仅“猜测”适用哪条规则来代替 符号 落地 (变量匹配算法) ,准确率大幅下降 (在 CLUTRR 上从 92% 降至 83%) 。这证实了 LLM 并不擅长在大海捞针中找到规则。
- 符号执行: 如果你试图强制执行过程纯粹为符号化 (无 LLM 推理) ,性能也会下降。混合方法是最好的。
在长推理链上的鲁棒性
最后,作者观察了模型如何处理日益增加的复杂性。随着推理步骤数量的增加,大多数模型都会崩溃。
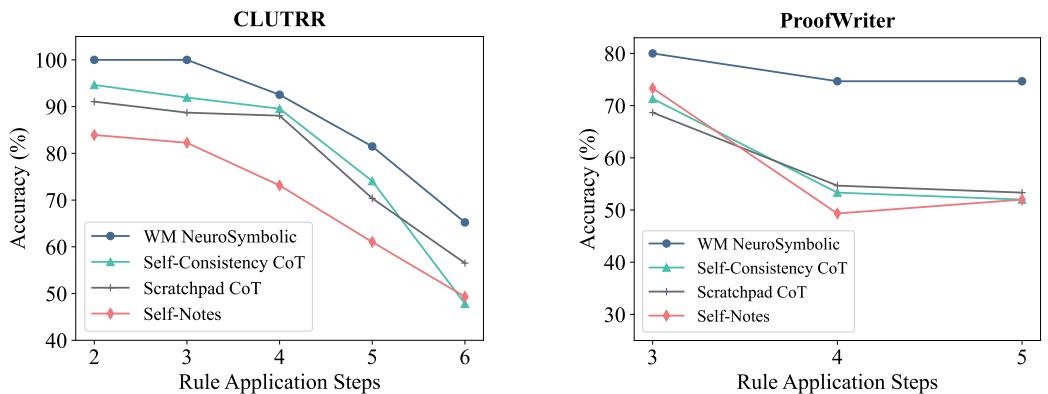
图 5 绘制了准确率与推理步骤数量的关系图。
- 左图 (CLUTRR) : 蓝线 (WM Neurosymbolic) 保持平稳且处于高位,接近 90-100%,即使步骤增加到 6 步也是如此。其他线 (标准提示方法) 则急剧下降。
- 右图 (ProofWriter) : 趋势相似。该框架非常稳定。因为工作记忆分担了认知负荷,所以随着链条变长,LLM 不会感到“疲倦”或困惑。
为什么这很重要
这篇论文代表了 AI 推理进化的关键一步。我们正在摒弃“无论提示多么巧妙,单一提示都能解决一切”的观念。
通过不把 LLM 视为整个大脑,而是视作连接到结构化内存 (RAM) 和逻辑引擎 (ALU) 的处理单元 (CPU) ,我们获得了两全其美的效果:
- 精确性: 符号记忆防止模型遗忘事实或将规则应用到错误的人身上。
- 灵活性: LLM 处理将自然语言转化为逻辑这一繁琐过程。
“神经符号”的未来表明,实现真正 AI 推理的道路不仅仅是把模型做大,而是给它们提供合适的工具和架构来组织它们的思想。
关键要点
- LLM 在多步推理中难以进行 规则落地 (找到正确的规则) ,尤其是在数据无序的情况下。
- 符号工作记忆 以双重格式 (语言 + 逻辑) 存储事实,以实现精确跟踪。
- 该框架将过程分离为 符号匹配 (用于精确性) 和 LLM 执行 (用于推理) 。
- 这种混合方法在复杂的逻辑推理基准测试中取得了最先进的结果,显著优于标准的思维链提示。