](https://deep-paper.org/en/paper/2408.14192/images/cover.png)
深度学习已经改变了计算机视觉领域,但其成功通常依赖于大量的标注数据。在 ImageNet 这样的大规模数据集上训练的模型可以准确分类数千种物体——但当我们想用少量样本来教模型一个新概念时,会发生什么呢?例如,仅凭五张照片来识别一种稀有鸟类。这个挑战定义了小样本学习 (FSL) 。
人类可以从一个例子中进行泛化,但深度模型在数据有限时通常表现不佳,容易过拟合。 基于度量的小样本学习方法通过学习一个特征空间来解决这一问题,在该空间中相似的图像会聚集在一起。新的“查询”图像通过在该空间中寻找最接近的已标记“支持集”样本来进行分类。
然而,这些方法面临一个长期存在的问题: 背景噪声 。 每张图像不仅包含主体,还包含各种背景元素——鸟儿所栖的树枝、脚下的草地或背后的天空。当模型学习“鸟”这个概念时,它可能会错误地将背景与鸟本身联系起来。我们该如何教它专注于主体而忽略干扰呢?
最近的一篇研究论文 Feature Aligning Few Shot Learning Method Using Local Descriptors Weighted Rules 提出了一个巧妙的解决方案。作者提出了一种名为 FAFD-LDWR 的方法,它能够智能过滤掉不相关的视觉信息。通过对齐支持图像和查询图像的关键局部描述符,该方法聚焦在有判别力的图像区域上,从而在多个基准测试中提升了分类准确率。
在本文中,我们将逐步探讨 FAFD-LDWR 的工作原理。
背景杂波的问题
现代视觉模型通过分析图像的更小区域来生成局部描述符——即表示局部区域的特征向量。这样可以保留细粒度的细节,但同时也捕捉到不相关的区域。

图 1. 与图像类别相关 (红色) 和不相关 (黄色) 的区域。
每张图像都包含与关键语义区域 (如羽毛、鸟喙) 相关的描述符,以及与杂乱背景 (如树枝、草地) 相关的描述符。同等对待所有描述符会引入大量噪声。
以往的方法常将全局与局部特征结合,以减轻这一问题,但这些方法增加了模型复杂度。而 FAFD-LDWR 则直接过滤掉不相关描述符,对齐图像中有用的部分,从而实现更清晰的类别区分。
FAFD-LDWR 方法: 三阶段的处理流程
FAFD-LDWR 框架如下图所示,通过三个模块实现精确的小样本分类: 提取特征、精炼特征并过滤噪声。
- 嵌入特征提取 – 使用神经网络骨干生成局部描述符。
- 交叉归一化 – 以自适应多层归一化保留判别性细节。
- 动态加权规则的局部描述符 (LDWR) – 评估描述符的重要性并过滤噪声。

图 2. FAFD-LDWR 流水线概览。
让我们逐一解析各个组件。
步骤 1: 提取局部描述符
FAFD-LDWR 首先将图像输入卷积神经网络 (Conv-4 或 ResNet-12) ,生成大小为 \( C \times H \times W \) 的局部描述符张量,其中 \(C\) 为通道数。
\[ \mathcal{A}_{\phi}(I) = [\mathbf{x}^1, ..., \mathbf{x}^N] \in \mathbb{R}^{C \times N} \]其中 \(N = H \times W\)。每个 \(\mathbf{x}^i\) 表征图像的一个特定区域。这种表示能够保留空间关系,对于细粒度识别任务至关重要。
步骤 2: 用于更优特征表示的交叉归一化
归一化有助于稳定训练并平衡特征尺度。然而,常见的 L2 归一化可能会削弱对类别判别十分关键的细节。FAFD-LDWR 引入了交叉归一化 , 利用自适应权重结合空间级与通道级的方法。
空间级归一化关注单个描述符的位置:
\[ x_s = \left( \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} \right) \cdot \operatorname{conv1}(\operatorname{map}) + \operatorname{conv2}(\operatorname{map}) \]通道级归一化在空间方向上调整每个特征通道:
\[ x_c = \gamma \times \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta \]两者结果融合为:
\[ x_{CN} = x_s \times \frac{\omega_1}{\omega_1 + \omega_2} + x_c \times \frac{\omega_2}{\omega_1 + \omega_2} \]这种自适应融合既保留局部判别性信息,又增强了鲁棒性——为后续过滤操作打下坚实基础。
步骤 3: 使用局部描述符加权规则 (LDWR) 进行过滤
FAFD-LDWR 的核心是基于局部描述符加权规则的动态过滤。每个描述符根据邻域上下文及与类别原型的相似性获得一个“重要性评分”。
构建邻域表示
为提高稳定性,每个局部描述符 \(q\) 被替换为一个邻域表示 , 该表示为其按余弦相似度选取的 \(k\) 个最近邻的平均值:
\[ \operatorname{similarity}(q, x_i) = \frac{q \cdot x_i}{|q||x_i|} \]\[ N_q = \frac{1}{k} \sum_{i \in NN_k(q)} x_i \]此步骤可平滑噪声并整合上下文信息,从而提高可靠性。
描述符评分与过滤
计算类别原型: 每个类别的原型整合所有描述符,代表一个广义语义中心。
\[ P_c = \frac{1}{|S_c|} \sum_{x \in S_c} f_\theta(x) \]计算相似度得分: 对每个邻域表示 \(N_i\),计算其与类别原型 \(P_c\) 的相似度:
\[ S_{i,c} = \frac{N_i \cdot P_c}{\|N_i\|\|P_c\|} \]聚合重要性并设定阈值: 将各类别的余弦相似度平均以得到描述符的重要性权重:
\[ \overline{\omega}_i = \frac{1}{K} \sum_{c=1}^{K} S_{i,c} \]再计算全局均值与标准差:
\[ \overline{\mu} = \frac{1}{M \times T} \sum_{m=1}^{M} \sum_{n=1}^{T} \overline{\omega}_{n,m} \]\[ \overline{\sigma} = \sqrt{\frac{1}{M \times T} \sum_{m=1}^{M} \sum_{n=1}^{T} (\overline{\omega}_{n,m} - \overline{\mu})^2} \]应用 3σ 规则: 相似度低于 \(\overline{\mu} - \overline{\sigma}\) 的描述符被过滤为噪声:
\[ S_{i,c} < (\overline{\mu} - \overline{\sigma}) \]
过滤以迭代方式进行——先清理支持集描述符,重新计算类别原型后,再过滤查询描述符。
步骤 4: 使用干净的描述符进行分类
过滤完成后只保留有意义的描述符。分类时,比较查询描述符与过滤后的原型之间的余弦相似度,基于最相近的邻居得出结果:
\[ \text{Similarity}(q, \text{category}_i) = \sum_{l=1}^{L} \sum_{j=1}^{k} \cos(\hat{\mathbf{x}}_q^l, m_j^i) \]最终,softmax 将相似度转换为概率分类:
\[ P(c = i|q) = \frac{\exp(\text{Similarity}(q, \text{category}_i))}{\sum_{i=1}^{5} \exp(\text{Similarity}(q, \text{category}_i))} \]这种方法优先关注关键区域 (例如鸟的身体而非周围的树叶) ,从而能够获得更准确的预测。
实验结果: 性能表现如何?
FAFD-LDWR 在三个细粒度小样本基准上进行了测试: CUB-200 (鸟类)、Stanford Dogs 和 Stanford Cars 。 这些数据集都需要关注微小的视觉特征,非常适合验证描述符过滤的效果。
通用小样本性能
使用 ResNet-12 作为骨干网络取得了卓越的结果,在 1-shot 和 5-shot 任务中均超越了 13 种最先进的基线方法。
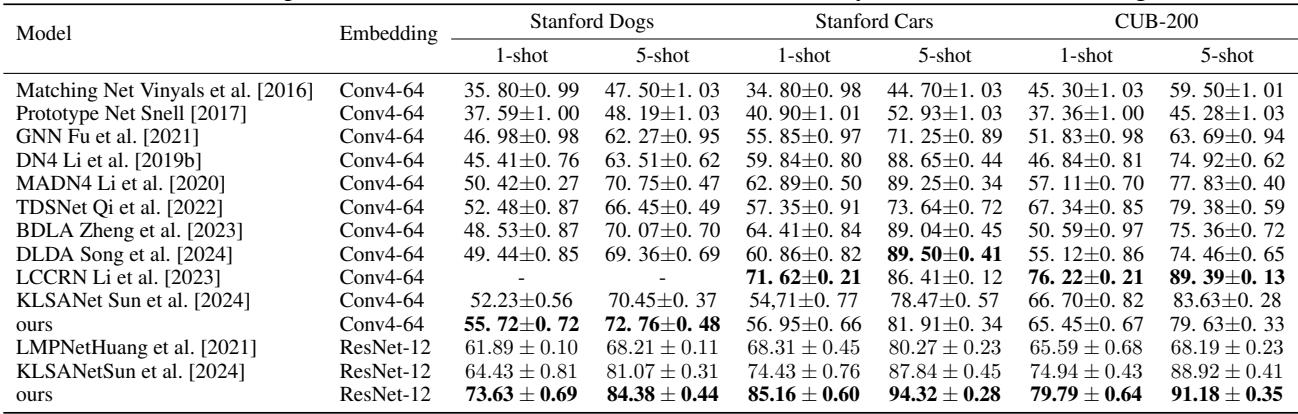
表 1. FAFD-LDWR 在细粒度小样本分类任务中优于以往方法。
ResNet-12 更高的描述符数量使 FAFD-LDWR 的动态加权机制能更好地工作,有效滤除冗余背景区块并精确捕捉判别性特征。
跨域泛化能力
真正的鲁棒性在于跨域适应。FAFD-LDWR 在 miniImageNet 上训练,并在 CUB birds 上测试,这构成了一项具有挑战性的迁移实验。
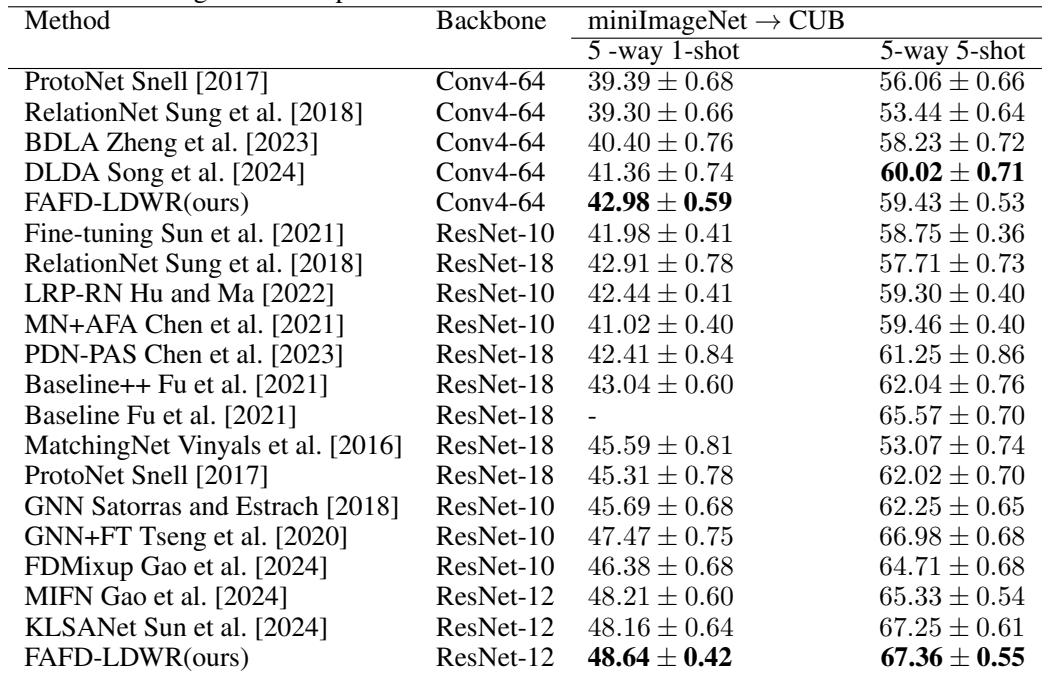
表 2. FAFD-LDWR 在 miniImageNet → CUB 实验中表现优于多种竞争方法。
FAFD-LDWR 聚焦于语义对齐而非数据集特定纹理,因而能够在不同领域间实现出色的可迁移性,体现了强大的通用学习能力。
消融研究: 理解每个模块的作用
研究人员通过消融实验验证了各个创新模块的贡献。
- 邻域表示的效果提升:
使用邻域平均描述符 (
W) 相比原始描述符 (w/o) 提高了准确率。
表 3. 邻域表示对性能的影响。
- 交叉归一化的优势:
用交叉归一化 (CN) 替代标准的 L2 归一化,在 DN4 和 FAFD-LDWR 中均提升了分类性能。
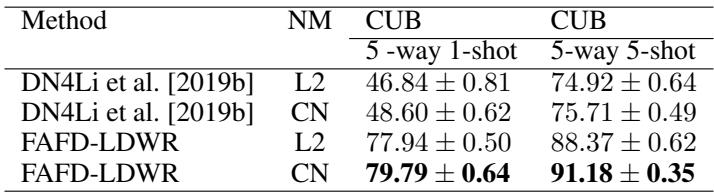
表 4. 交叉归一化相较 L2 归一化的优势。
- 最佳邻居数量:
当邻居数量为
k=10时准确率达到峰值。邻居过少导致平滑不足,而过多则会重新引入噪声。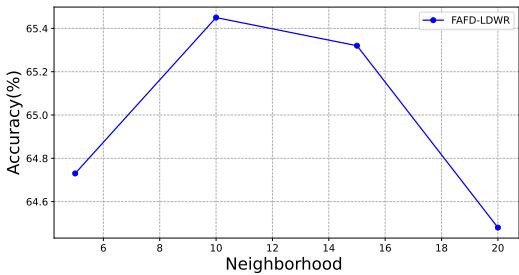
图 3. 准确率与邻域表示中邻居数量的关系。
FAFD-LDWR 一贯显示,通过合理的描述符过滤与归一化策略可以在不增加额外参数的情况下实现显著提升。
结论与关键要点
FAFD-LDWR 方法以简单而强大的方式提升了小样本学习的性能,其核心在于过滤掉不相关的局部描述符 。 它无需复杂架构或繁重优化,而是专注于支持图像与查询图像间的特征语义对齐。
主要洞见:
- 噪声是主要障碍 – 背景区域会稀释基于度量的小样本学习中的判别信号。
- 过滤提升清晰度 – 动态加权选择能有效去除无关描述符并加强特征匹配。
- 自适应预处理至关重要 – 交叉归一化与邻域平均为精确对齐构建了良好的基础。
通过聚焦图像的关键语义区域,FAFD-LDWR 在多个挑战性数据集上实现了最先进的小样本识别性能——为从极少样本中学习开辟了新的可能。