](https://deep-paper.org/en/paper/2408.15992/images/cover.png)
在人类认知中,说和听并非孤立存在的岛屿。当我们倾听他人时,我们的大脑会主动预测他们接下来要说什么。相反,当我们说话时,我们通常会模拟听众将如何接收我们的话语,以确保表达清晰。这种双向关系表明,提升其中一项技能应该自然而然地有助于另一项技能。
然而,在人工智能领域,这两种能力——生成 (说) 和理解 (听) ——通常被作为独立的任务进行训练和处理。
在一篇题为 “COGEN: Learning from Feedback with Coupled Comprehension and Generation” (COGEN: 通过耦合理解与生成从反馈中学习) 的精彩论文中,研究人员 Mustafa Omer Gul 和 Yoav Artzi 探索了在 AI 智能体中紧密耦合这两个过程会发生什么。他们证明,通过在训练和推理过程中将理解与生成联系起来,AI 的学习速度可以显著加快,并且能更自然地与人类交流。
本文将详细拆解他们的方法、由此产生的“良性循环”,以及他们在人类用户实验中取得的令人印象深刻的成果。
挑战: 从互动中学习
研究人员将他们的研究置于持续学习 (continual learning) 的背景下。与标准训练 (模型消耗大量静态数据集然后停止学习) 不同,持续学习涉及智能体与世界 (或用户) 互动、接收反馈、自我更新并重复该过程。
为了测试这一点,作者使用了一个名为七巧板 (Tangrams) 的抽象视觉刺激指称游戏 (Reference Game) 。
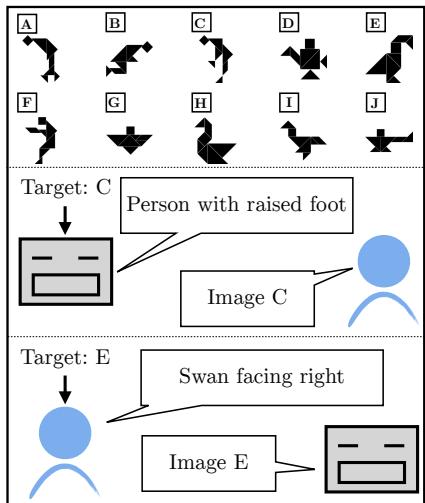
如图 1 所示,游戏涉及两名玩家:
- 说话者 (Speaker) : 看到一个目标图像 (例如图像 C) ,必须描述它。
- 听者 (Listener) : 看到一排图像,必须根据描述识别出目标。
这个设置看似简单,实则困难。这些图像是没有标准名称 (不像“猫”或“汽车”) 的抽象形状。用户必须发挥创造力,将其描述为“一个跳跃的人”或“一只朝右的天鹅”。AI 模型扮演这两个角色,与人类伙伴互动。目标是观察模型是否能仅凭二元反馈: 成功 (伙伴猜对了) 或失败 (他们猜错了) ,随着时间的推移提高其沟通技巧。
核心方法: 耦合理解与生成
解决这个问题的标准方法是训练两个独立的策略: 一个用于猜测图像 (理解) ,另一个用于描述图像 (生成) 。作者认为这种方法效率低下。相反,他们提出了 COGEN , 这是一个使用单个大型语言模型 (LLM) ——具体来说是 IDEFICS2-8B——来处理这两个任务的系统,并通过特定机制将它们耦合在一起。
整个工作流程是一个互动和训练的循环:
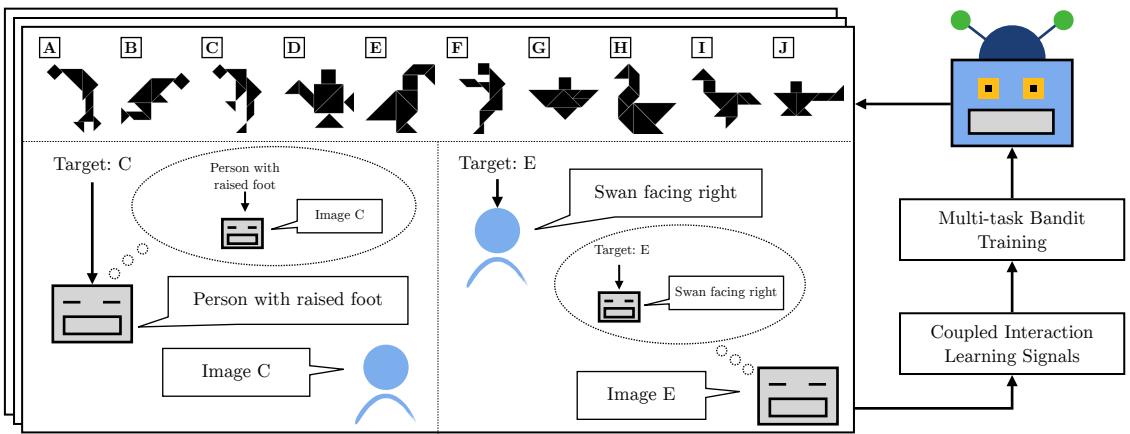
如图 2 所示,模型在部署阶段 (与人类玩游戏) 和训练阶段之间交替进行。创新的关键在于利用“思维气泡” (推理对方的角色) 和反馈信号来耦合这两种技能。
作者介绍了实现这种耦合的两个主要策略: 联合推理 (Joint Inference) 和数据共享 (Data Sharing) 。
1. 数学基础: 上下文赌博机
在深入探讨耦合之前,我们需要了解模型是如何学习的。由于反馈只是“成功/失败”而不是修正后的句子,这被视为一个上下文赌博机 (Contextual Bandit) 问题。该模型使用 REINFORCE 算法优化其策略。
当模型接收到奖励信号 \(r\) (其中 \(r=1\) 表示成功,\(r=-1\) 表示失败) 时,它使用以下梯度更新来更新其参数 (\(\theta\)) :
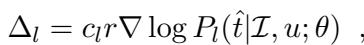
这里,\(\Delta_l\) 代表理解 (听者) 任务的更新。这里的一个关键组件是 \(c_l\),一个用于稳定训练的系数。当模型失败 (\(r=-1\)) 时,如果概率已经很低,简单地压低概率可能会导致不稳定。作者使用了一种逆倾向评分 (IPS) 截断方法:
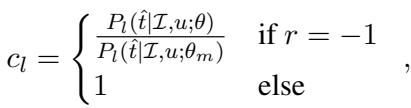
这确保了负面样本有助于学习,而不会使模型不稳定,这是人类反馈强化学习中的常见问题。
2. 策略 A: 数据共享 (向伙伴学习)
第一个主要创新是数据共享 。 在标准设置中,生成模型仅从其自身的成功生成中学习。如果它说“奇怪的鸟”并且赢了,它就会强化“奇怪的鸟”。
但是如果 AI 扮演的是听者角色呢?如果人类伙伴说“跳舞的鹅”,而 AI 正确识别了目标,那么 AI 刚刚获得了一个高质量的数据点: 对于这张图片,“跳舞的鹅”是一个有效的描述。
作者将其形式化: 每当互动成功 (\(r=1\)) 时,将理解数据转换为生成训练数据 (反之亦然) 。
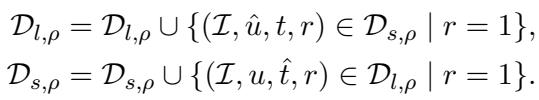
在这个公式中:
- \(\mathcal{D}_{l, \rho}\) 是第 \(\rho\) 轮的理解数据集。
- \(\mathcal{D}_{s, \rho}\) 是生成 (说话者) 数据集。
- 并集操作 (\(\cup\)) 意味着从一个任务中获得的有效样本被添加到另一个任务的训练集中。
这为何重要: 这防止了模型发展出自己的“外星语言”。通过不断摄取人类编写的成功描述 (在聆听阶段) 并利用它们来训练其说话能力,模型的语言保持了接地气和类人的特征。
3. 策略 B: 联合推理 (三思而后言)
第二个策略发生在游戏过程中,而不只是训练期间。它基于理性言语行为 (Rational Speech Act, RSA) 框架。
当 AI 充当听者时,它不仅仅依赖其听者模型 (\(P_l\)) 。它还会咨询其内部的说话者模型 (\(P_s\)) 。实际上,它会问: “如果我是说话者并想要描述图像 \(t\),我有多大可能会说出话语 \(u\)?”
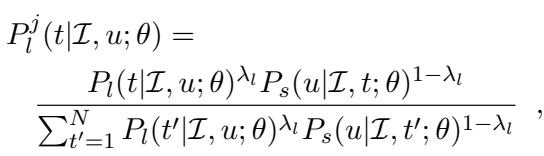
这个公式显示了联合概率 \(P_l^j\)。它结合了:
- 字面听者概率 (\(P_l\)) : 描述与图像匹配吗?
- 说话者概率 (\(P_s\)) : 说话者实际上会用这个描述来形容这张图像吗?
这种加权组合 (由 \(\lambda\) 控制) 允许模型进行语用推理,过滤掉荒谬的解释或那些虽然技术上匹配但极不可能使用的描述。
实验结果
研究人员在 Amazon Mechanical Turk 上部署了该系统进行了四轮持续学习。他们比较了 FULL 系统 (联合推理 + 数据共享) 与消融版本 (无联合推理,无数据共享) 以及 BASELINE (基线,两者皆无) 。
性能提升
结果非常明显。耦合系统显着优于基线和未耦合的变体。
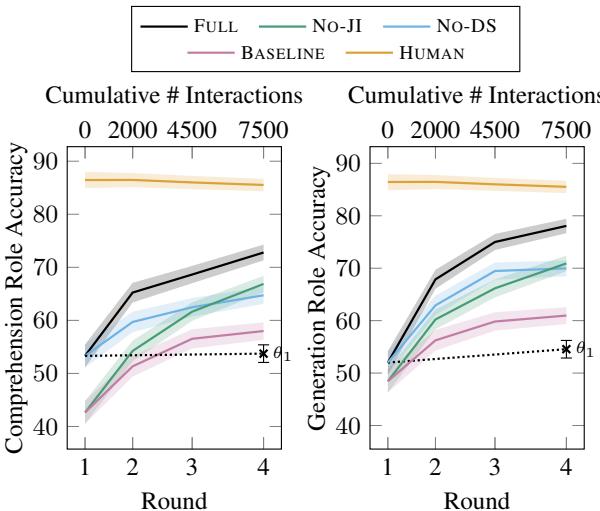
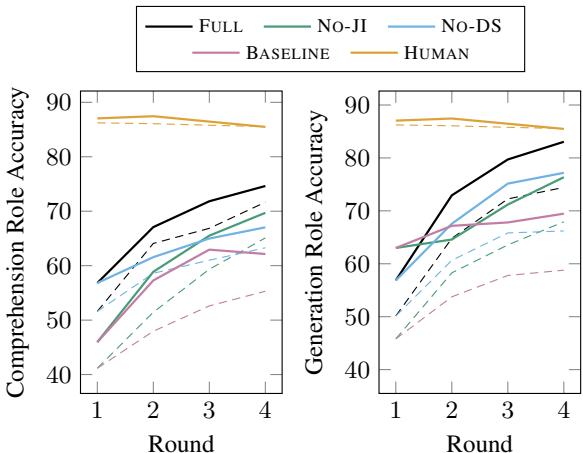
在图 3 中,请看黑线 (FULL) 与粉色虚线 (BASELINE) 的对比。
- 理解 (左) : FULL 模型稳步提升,最终比基线高出近 15%。
- 生成 (右) : 差距更大。FULL 模型达到了近 80% 的准确率,而基线难以突破 60%。
一个有趣的观察是, No-JI (无联合推理) 和 No-DS (无数据共享) 的线条位于中间。这证明了两种机制都独立地对成功做出了贡献。
数据效率
数据共享最强大的好处之一是它为模型提供了“免费”数据。
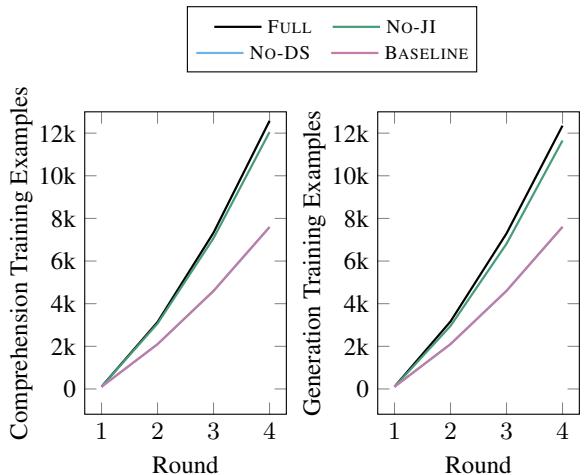
图 8 显示了训练样本的数量。由于 FULL 模型 (黑线) 有效地在任务之间交换数据,它的训练样本积累速度比基线快得多。这使得模型能从更少的互动中学到更多——当“互动”需要花费真金白银和人类时间时,这是一个关键因素。
语言质量
模型只是变得更擅长玩游戏了,还是真的变成了一个更好的沟通者?
在闭环强化学习中,模型通常会学习“博弈”策略——使用简短、奇怪的关键词,虽然技术上能区分图像,但听起来不像人类语言。这就是所谓的语言漂移 (language drift) 。
作者分析了模型生成的语言:
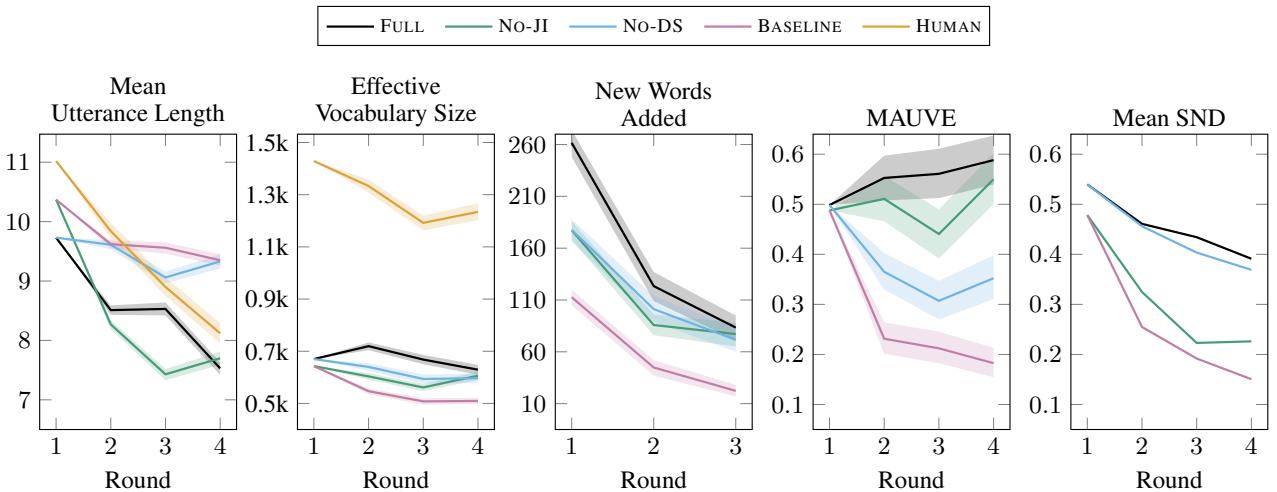
图 5 的关键要点:
- 话语长度 (左上) : 随着人类 (橙色) 成为专家,他们倾向于使用更简短的描述。FULL 模型 (黑色) 完美地模仿了这一趋势。
- 词汇量 (中上) : 基线 (粉色) 坍缩成极小的词汇量 (重复的语言) 。FULL 模型保持了更丰富、更大的词汇量。
- MAUVE 分数 (左下) : 该指标衡量生成文本与人类文本的接近程度 (越低越好) 。FULL 模型与人类分布紧密对齐,而基线则偏离得很远。
空间推理的障碍
尽管取得了成功,作者指出了一个持续存在的弱点: 空间推理 。
当目标需要空间描述 (例如,“左边第二个”) 时,所有模型的性能都下降了 (图 4 中的实线) 。众所周知,视觉-语言模型 (VLM) 在复杂构图中区分“左”与“右”或“上”与“下”方面很吃力。虽然耦合模型的表现仍然优于基线,但 AI 与人类表现之间的差距在这里最为明显。
结论与启示
COGEN 论文提供了令人信服的证据,证明耦合理解与生成为 AI 学习创造了一个良性循环。
- 更好的性能: 通过检查自己的言语 (联合推理) ,模型表达得更清晰。
- 更快的学习: 通过从伙伴的言语中学习 (数据共享) ,模型使训练信号翻倍。
- 人类对齐: 通过利用伙伴的语言进行训练,模型抵制了发明自己奇怪方言的冲动,保持了自然语言的规范性。
这项工作表明,未来的 AI 智能体——无论是家中的机器人还是屏幕上的聊天机器人——不应仅仅被训练去说话或倾听。它们应该被训练同时做这两件事,将每一次互动都视为同时改进这两项技能的机会。就像人类一样,AI 在进行双向对话时学习效果最好。