](https://deep-paper.org/en/paper/2409.04206/images/cover.png)
训练大型语言模型 (LLM) 的计算成本非常高昂。即使我们已经从从头训练转向微调预训练模型,对于学生和研究人员来说,时间和 GPU 计算量 (FLOPs) 的成本仍然是一个巨大的障碍。
为了缓解这一问题,社区采用了参数高效微调 (PEFT) 方法,其中 LoRA (低秩自适应) 是无可争议的冠军。LoRA 通过冻结主要模型权重并仅训练一小部分参数,显著减少了内存占用。但问题在于: 虽然 LoRA 节省了内存,但它并不一定能大幅加快训练过程本身。你仍然需要运行数千次随机梯度下降 (SGD) 迭代。
但是,如果我们能加速优化过程本身呢?如果像 Adam 这样的标准优化器对于低秩训练的特定几何结构来说太过谨慎了呢?
在一篇引人入胜的论文 “Fast Forwarding Low-Rank Training” (快进低秩训练) 中,研究人员提出了一种简单得有些可疑的方法。他们问道: 如果优化器告诉我们要朝某个方向移动,为什么我们不干脆朝着那个方向一直走,直到它不再起作用为止?
这种被称为 Fast Forward 的技术,可以减少高达 87% 的 FLOPs 和 81% 的训练时间 , 且不牺牲模型性能。在这篇文章中,我们将拆解这篇论文,准确解释该算法的工作原理,并探讨为什么这种看似“愚钝”的坚持可能是训练 LoRA 适配器最聪明的方式。
现代优化的问题
在深入解决方案之前,我们需要先了解目前训练模型的背景。现代机器学习严重依赖 Adam 或 SGD (随机梯度下降) 等优化器。
标准的循环如下所示:
- 前向传播 (Forward Pass) : 将数据通过模型以获得预测。
- 损失计算 (Loss Calculation) : 将预测值与实际目标进行比较。
- 反向传播 (Backward Pass/Backprop) : 计算梯度,以查看每个参数如何导致误差。
- 更新 (Update) : 优化器将权重向误差的相反方向稍微移动。
这个过程重复数千次。它很稳定,但很慢。具体来说, 反向传播的计算成本很高。每一步都需要计算所有可训练参数的梯度。
这篇论文的作者意识到,在低秩训练的特定背景下,损失函数的景观 (我们试图导航以找到最低点的地形) 出奇地平滑。如果地形平坦,每走一步都迈着婴儿般的细碎步伐并查看地图 (计算梯度) 是非常低效的。有时,你只需要冲下山坡。
背景: LoRA 与低秩景观
要理解为什么 Fast Forward 有效,我们要先快速回顾一下 LoRA 。
当我们微调一个巨大的模型 (如 Llama-3 70B) 时,在消费级硬件上更新每个权重是不可能的。LoRA 冻结了预训练权重 (\(\mathbf{W}_0\)) ,并在层中注入成对的小型可训练矩阵 (\(\mathbf{B}\) 和 \(\mathbf{A}\)) 。
更新规则如下所示:

这里,\(r\) (秩) 非常小,通常为 8、16 或 64。这迫使模型学习存在于“低维子空间”中的更新。
还有一种变体叫 DoRA (权重分解低秩自适应) , 它将权重分解为幅度和方向。对我们而言,重要的结论是这两种方法都限制了模型参数的移动。它们不允许权重在高维空间中随意游荡;它们被限制在一个特定的、低维的轨道上。
事实证明,这种约束简化了训练的几何结构。全秩训练涉及在充满陷阱的混乱、颠簸的地形中导航,而低秩训练则创造了一条更平滑的路径。研究人员假设这种平滑性是可以被利用的。
核心方法: Fast Forward
“Fast Forward” (FF) 方法是一种混合优化策略。它在两个阶段之间交替: SGD 阶段 (标准训练) 和 Fast Forward 阶段 (加速) 。
算法
这个概念简单而优雅。你首先使用 Adam/SGD 正常训练模型几步,以获得良好的方向感。这就是“预热”或磨合。一旦优化器找到了一个不错的方向,你就切换到 Fast Forward。
以下是该算法的直观分解:
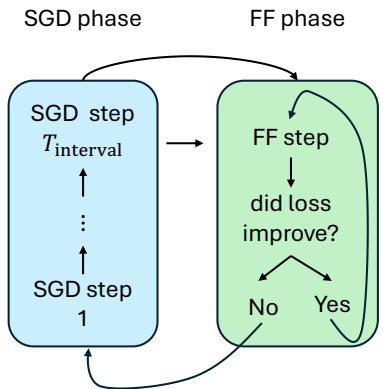
让我们通过图 1 来看一下循环过程:
- SGD 阶段: 模型正常训练设定步数 (例如,\(T_{interval} = 6\)) 。这允许优化器 (Adam) 计算动量并确定良好的更新方向。
- 计算方向 (\(\Delta W\)) : 在 SGD 阶段结束时,我们要看当前权重与上一步权重之间的差异。这个向量代表了优化器想要去的“速度”和方向。
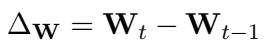
- Fast Forward 阶段: 现在,我们停止反向传播。我们停止计算梯度。相反,我们要取刚才计算出的方向 \(\Delta \mathbf{W}\) 并反复应用它。
- 更新 1: \(W_{new} = W + 1 \cdot \Delta W\)
- 更新 2: \(W_{new} = W + 2 \cdot \Delta W\)
- 更新 3: \(W_{new} = W + 3 \cdot \Delta W\)
- …以此类推。
- 微型验证集: 我们怎么知道何时停止?如果我们永远持续添加 \(\Delta W\),模型最终会冲过谷底并开始爬上另一侧,导致损失增加。 为了防止这种情况,作者使用了一个微型验证集 (仅约 32 个示例) 。在 Fast Forward 阶段的每一次推测性跳跃之后,他们都会检查这 32 个示例的损失。
- 损失改善了吗? 是 \(\rightarrow\) 继续跳跃。
- 损失改善了吗? 否 \(\rightarrow\) 停止!恢复到上一个好的步骤并返回 SGD 阶段。
为什么这更快?
你可能会想,“等等,你不是还在做步骤吗?这怎么能节省时间?”
奥秘在于操作的成本。在 Fast Forward 阶段, 没有反向传播。 我们不计算梯度。我们只是将一个矩阵加到权重上,并运行前向传播来检查损失。
前向传播比完整的训练步骤 (前向 + 反向 + 优化器更新) 要便宜得多 (大约快 3 倍) 。此外,由于低秩表面是平滑的,算法通常可以有效地进行许多 Fast Forward 步骤,从而在训练中跳跃式前进,而无需支付反向传播的高昂计算成本。
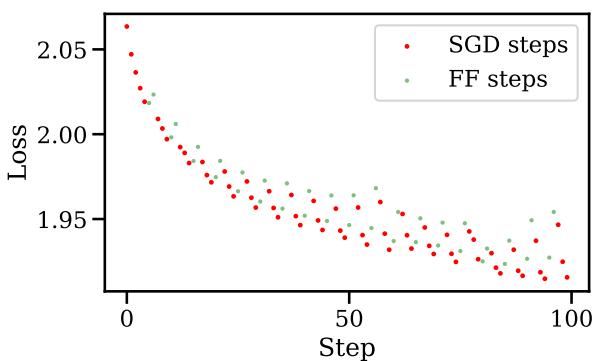
对训练曲线的视觉影响是惊人的。请看下图:
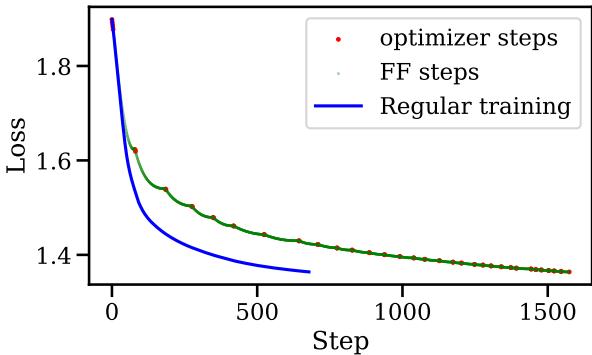
在图 4 中, 红点是标准的 SGD 步骤。 绿点是 Fast Forward 步骤。注意损失在绿色部分是如何垂直下降的吗?那就是算法在一个方向上“滑雪”下坡,在几秒钟内完成了通常需要几分钟昂贵计算才能完成的工作。蓝线代表标准训练——注意 Fast Forward 如何更早地达到了同样的低损失。
实验与结果
研究人员在多个模型 (Pythia 1.4B 到 6.9B,以及 Llama-3 8B) 和不同领域 (医疗、代码指令和聊天) 验证了这种方法。
FLOPs 的巨大节省
深度学习效率的主要衡量指标是 FLOPs (浮点运算次数) 。这衡量了 GPU 完成的原始计算工作量。
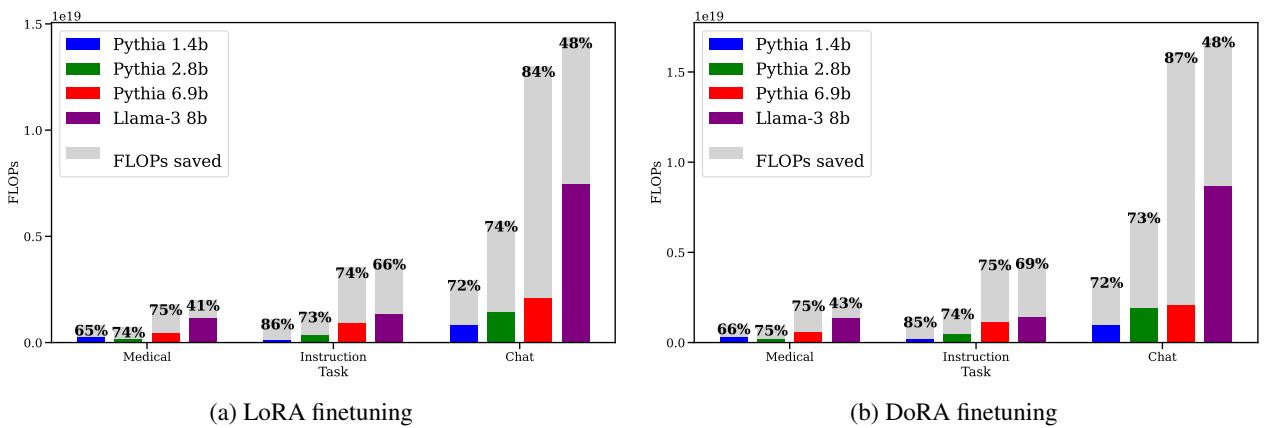
如图 2 所示,结果一致且显著。
- 医疗任务: 根据模型大小,节省了高达 65-86% 的 FLOPs。
- 指令任务: 节省了 66-86% 。
- 聊天任务: 节省了 48-84% 。
灰色条代表你不必做的工作。通过简单地重复上一个好的步骤,模型仅用了一小部分计算量就达到了目标损失。
挂钟时间的节省
理论上的 FLOPs 很好,但它真的能节省实际时间吗?是的。
注意: 图片组中提供的图 3 似乎是描述中的图 14,或者是文件标记错误。我将使用 images/004.jpg,它对应于时间节省图表。
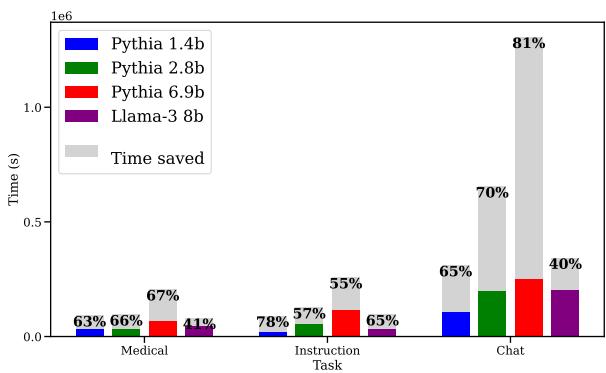
图 3 证实了 FLOPs 的节省转化为实际时间。通常需要数小时的训练运行可以在大约一半的时间内完成。节省的幅度略低于 FLOPs 的节省,因为在 32 个示例上运行验证检查确实需要一些时间,但这种权衡是非常值得的。
会损害性能吗?
如果生成的模型很笨,那速度再快也没用。作者对此进行了严格检查。
- 测试损失: Fast Forward 模型收敛到与标准训练相同 (或略好) 的损失值。
- 基准测试: 他们在 PubMedQA 上进行了测试。标准模型的准确率为 49.75% 。 Fast Forward 模型的准确率为 50.95% 。
本质上,你得到了同样的模型,只是速度更快。
为什么它有效? (深度解析)
这通常是让学生困惑的部分。我们被教导说,神经网络的损失景观是非凸的噩梦,充满了鞍点和局部最小值。究竟为什么我们可以沿着直线走 50 步而不撞车?
答案在于 低秩 (Low-Rank) 约束。
子空间中的凸性
作者绘制了与预训练权重、标准 SGD 权重和 Fast Forward 权重相交的平面上的损失曲面。
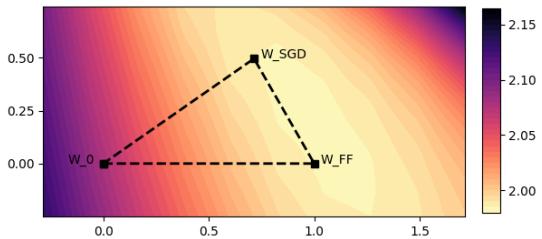
在图 5 中,看看等高线是多么规则和呈“盆地状”。这表明在 LoRA 定义的特定子空间中,损失函数的表现非常好。它大致是凸的。
因为曲线是凸的 (碗状) ,如果你知道碗底的方向,你可以向它迈出一大步。你不需要寸步难行。这在概念上类似于 线搜索 (Line Search) , 一种深度学习时代之前的经典优化技术。Fast Forward 实际上是在使用微型验证集来确定步长 \(\tau\),从而执行动态线搜索。
梯度一致性
另一个迷人的发现涉及 Fast Forward 如何改变训练轨迹。
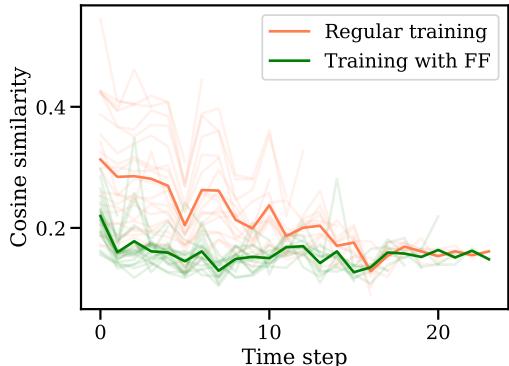
图 6 显示了当前梯度与先前梯度之间的余弦相似度。
- 橙线 (常规) : 梯度与之前的步骤保持某种相似性。
- 绿线 (Fast Forward) : 相似度显著下降。
这意味着当 Fast Forward 迈出一大步时,它“耗尽”了该特定方向的潜力。它榨干了该梯度的所有“果汁”。当 FF 阶段结束且 SGD 重新介入时,优化器被迫寻找一个新的、不同的方向来改进模型。它阻止了优化器一步步冗余地追溯相同的路径。
秩的作用
一个反直觉的发现与 LoRA 适配器的秩有关。你可能会猜测,随着秩的增加 (增加更多可训练参数) ,景观会变得更复杂,Fast Forward 会失效。
结果恰恰相反。
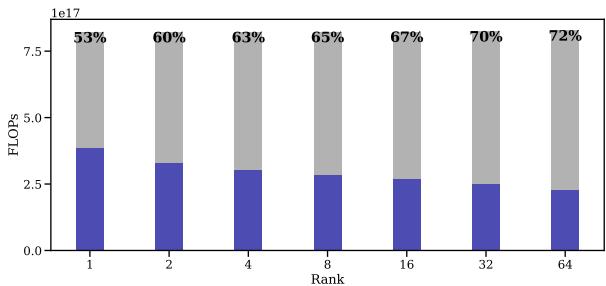
在图 7 中,我们看到随着秩从 1 增加到 64,节省量 (灰色区域) 实际上增加了。甚至在全秩 (\(r\) 等于模型维度) 下,FF 在一项实验中也减少了 74% 的 FLOPs。
这告诉我们,Fast Forward 的成功不仅仅是因为维度低;很可能是由于 LoRA 更新矩阵本身的性质。
它何时失效?
作者对局限性很坦诚。他们尝试将 Fast Forward 应用于 全秩标准微调 (直接更新模型的所有权重,不使用 LoRA) 。
结果完全失败。
如图 8 所示,当他们尝试在全秩训练中进行 Fast Forward (绿点) 时,损失立刻飙升。即使是一个推测性的步骤也太多了。
为什么?全秩损失表面并不平滑。它是锯齿状的。对步骤 \(t\) 好的方向通常对步骤 \(t+1\) 很糟糕。“线搜索”假设对 LoRA 成立,但对标准训练失效。这表明 LoRA 起到了正则化器的作用,平滑了优化景观,从而实现了这些激进的加速。
优化 Fast Forward
该论文还探讨了该方法本身的超参数。例如,你应该在 Fast Forward 爆发之间等待多久?
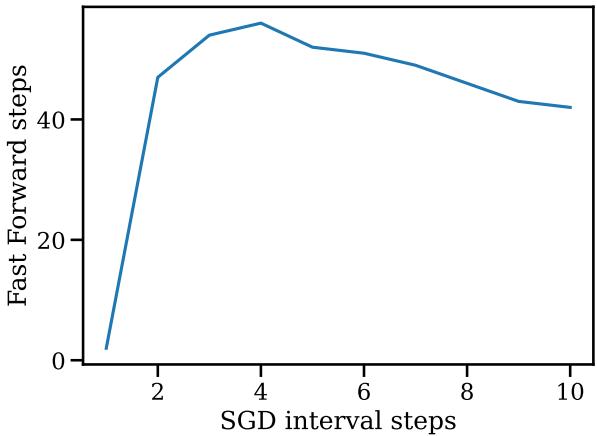
图 14 显示了 SGD 间隔 (你采取多少正常步骤) 与 Fast Forward 长度 (你获得多少廉价步骤) 之间的关系。事实证明,你只需要非常短的 SGD 间隔 (大约 4 步) 就能获得大量的 Fast Forward 步数 (接近 50 步!) 。如果你等待太久 (运行 SGD 10 步) ,“快进”的机会实际上会减少。
这表明梯度中的“方向”信息会迅速过期。你应该计算一个方向,立即用 Fast Forward 利用它,然后重新计算。
结论与关键要点
“Fast Forward” 论文为训练效率提供了一个令人耳目一新的视角。虽然很多业内人士专注于硬件加速 (更好的 GPU) 或架构变更 (混合专家模型) ,但这项工作强调了仅仅因为我们的优化器太过保守,我们就错失了性能。
以下是给学生和从业者的关键要点:
- LoRA 在几何上是独特的: 低秩训练创造了一个比全秩训练平滑得多的损失景观。
- 动量是可利用的: 如果优化器指向某个方向,你很可能可以沿着该方向走很长一段时间,而无需重新计算梯度 (在 LoRA 中) 。
- 前向 vs. 反向: 通过用廉价的前向传播 (在微型验证集上) 交换昂贵的反向传播,我们可以大幅削减计算成本。
- 实现: 这种方法相对容易在现有的训练循环之上实现。它不需要更改模型架构,只需要更改训练循环逻辑。
随着 LLM 的持续增长,像 Fast Forward 这样无需硬件升级即可削减 80% 训练成本的方法,可能会成为机器学习工程师工具箱中的标准工具。有时,取得领先的最佳方式就是停止过度思考,只是继续前进。