](https://deep-paper.org/en/paper/2409.13935/images/cover.png)
引言: 未曾诉说之故事的痛苦
玛雅·安杰卢 (Maya Angelou) 曾经写道: “没有什么比心中怀着一个未曾诉说的故事更痛苦的了。”对于数以百万计的读者来说,这种痛苦因缺乏代表性而加剧。当你翻开一本书时,你在寻找一面镜子——一个长得像你、生活像你、面临着你能理解的困境的角色。这些被称为“镜像书籍 (mirror books) ”。它们验证身份,培养归属感,并显著提高阅读参与度,尤其是在教育领域。
然而,出版业历来难以让每个人都拥有这面镜子。全球人口的多样性与文学作品中角色的多样性之间存在着巨大的鸿沟。
但是,如果每位读者都能拥有一篇专门为他们撰写的故事呢?
在一项题为 “MIRRORSTORIES: Reflecting Diversity through Personalized Narrative Generation with Large Language Models” 的引人入胜的新研究中,研究人员 Yunusov、Sidat 和 Emami 探讨了人工智能——特别是大型语言模型 (LLM) ——是否能够弥补这一鸿沟。他们研究了 AI 是否能够生成忠实反映读者特定人口统计特征和兴趣的短篇故事,更重要的是,读者是否真的比传统的人类撰写的寓言更喜欢这些故事。
背景: 文学中的多样性鸿沟
在深入探讨 AI 解决方案之前,至关重要的是理解问题的规模。鲁丁·西姆斯·毕晓普 (Rudine Sims Bishop) 曾有一句名言,将书籍描述为“镜子、窗户和滑动玻璃门”。镜子反映我们自己的生活;窗户让我们看到他人。当文学缺乏多样性时,少数群体便失去了镜子。
研究人员利用合作儿童图书中心 (CCBC) 的数据强调了这种差异。

如 图 6 所示,统计数据触目惊心。在 2018 年,一个孩子读到一本关于动物或卡车的书 (27%) 的可能性,比读到一本关于非裔美国人 (10%) 、亚裔 (7%) 、拉丁裔 (5%) 或原住民 (1%) 角色的书的总和还要高。白人角色占据了 50% 的主导地位。
虽然出版业在纠正这一问题上进展缓慢,但 MIRRORSTORIES 的作者认为,LLM (如 GPT-4、Claude-3 和 Gemini) 提供了一种可扩展的、即时的解决方案,可以按需生成包容性的叙事。
方法论: 构建 MIRRORSTORIES 语料库
为了测试 AI 生成个性化文学作品的有效性,研究人员不仅仅是生成了几个故事;他们建立了一个名为 MIRRORSTORIES 的综合语料库。该数据集包含 1,500 个短篇故事,旨在比较三种不同类型的叙事生成方式。
三位竞争者
该研究在三类故事之间设置了一场“吟游诗人之战”:
- 人类撰写的通用故事 (Generic Human-Written) : 这些是经典的《伊索寓言》。它们结构良好,寓意深刻,但在角色身份方面是通用的。
- LLM 生成的通用故事 (Generic LLM-Generated) : AI 被要求写一个传达特定寓意 (例如,“善行从不白费”) 的故事,没有任何具体的个性化指令。
- LLM 生成的个性化故事 (Personalized LLM-Generated) : AI 获得特定的用户档案 (包括姓名、年龄、性别、种族和兴趣) ,并被要求将这些要素编织进传达相同寓意的故事中。
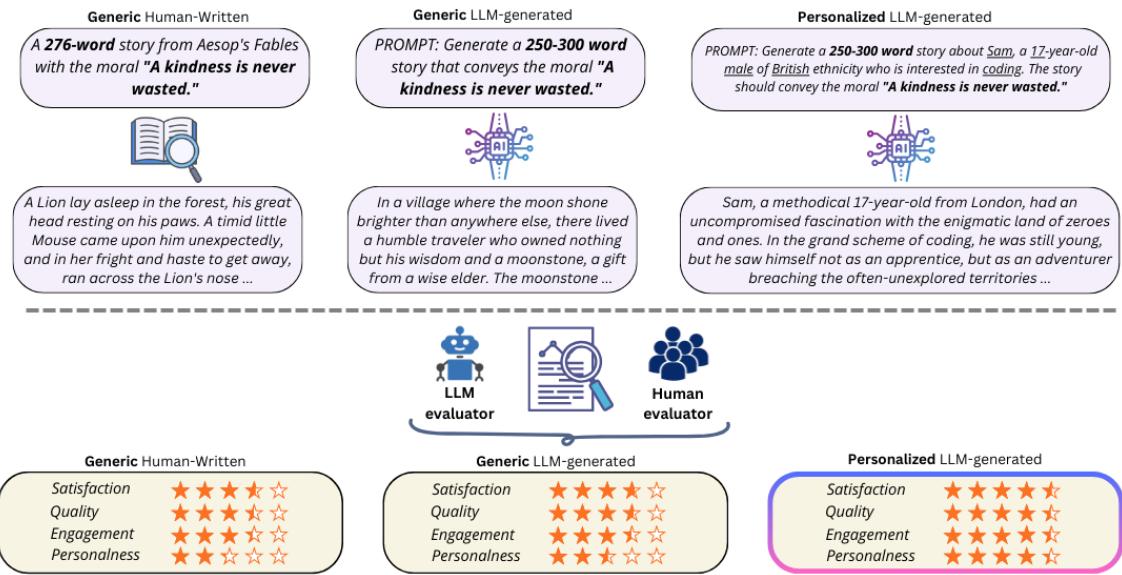
图 1 展示了这个工作流程。你可以看到针对个性化版本的提示词是如何变化的。模型不再接收通用的请求,而是被输入了具体的“身份要素 (Identity Elements) ”。例如,提示词可能会要求写一个关于“Sam”的故事,他是一名喜欢“编程”的“17 岁英国男性”。
身份要素
为了确保个性化故事真正具有多样性,研究人员没有依赖模糊的提示词。他们围绕特定变量构建了数据集。
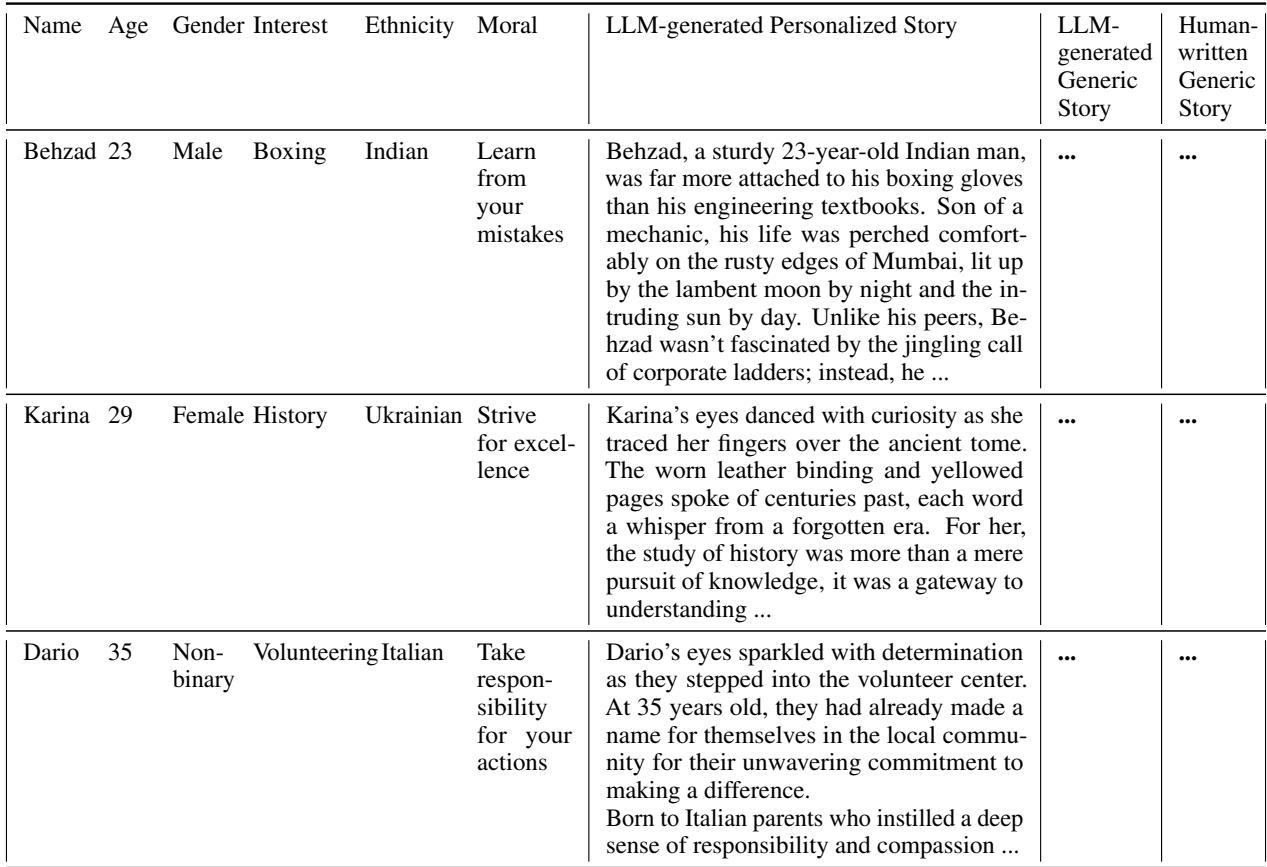
如上文 表 6 详述,数据集中的每个条目都以一个寓意为锚点。然后,个性化故事在此基础上叠加特定属性。研究人员选取了 123 种独特的种族背景和 124 种不同的兴趣 , 范围从射箭到编程。
这种结构化的方法使他们能够系统地测试 AI 是否可以处理复杂的组合——比如一位 29 岁的乌克兰历史学家或一位 35 岁的意大利志愿者——而不会丢失情节或道德教训。
验证: AI 真的听懂了吗?
生成文本很容易;生成准确且巧妙地融入个性特征的文本则较难。在测试用户喜爱度之前,研究人员必须验证故事是否真的包含了所要求的要素。
他们利用人类评估者和 GPT-4 (充当评估者) 来阅读故事,并尝试“猜测”主角的人口统计特征。
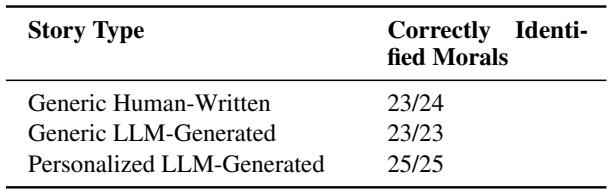
图 3 显示的结果令人印象深刻。
- 性别: 人类评估者以 100% 的准确率 识别出了角色的性别。
- 种族: 人类正确识别种族的比例为 94% 。
- 兴趣: 角色的特定爱好或兴趣被识别出的准确率为 83% 。
这证实了当前的 LLM 非常有能力遵循关于角色身份的复杂指令。它们不只是提到一个名字;它们将文化标记和具体活动有效地编织进叙事纹理中,足以让读者注意到。
可视化个性化
为了让你感受 AI 是如何实现这一点的,研究人员使用主题建模 (BERTopic) 分析了生成故事中最重要的词汇。

表 4 为这种“编织”过程提供了绝佳的例子。
- 对于 Aveline , 一位对阅读感兴趣的非二元性别法国读者,故事集中在 library (图书馆) 、truth (真理) 和 joy (快乐) 等词汇上。
- 对于 Farida , 一位乌兹别克木匠,主要词汇转变为 craft (工艺) 、wood (木材) 和 reputation (声誉) 。
AI 成功地转换了故事的词汇,以匹配读者的“世界”。
结果: 个性化重要吗?
现在来到最关键的问题: 读者真的更喜欢这些故事吗?
研究人员招募了一组多样化的人类评估者。他们使用了一种巧妙的评估设置,称为“个性化影响 (Personalization Impact) ”。每位评估者收到三个故事:
- 一个通用的伊索寓言。
- 一个通用的 AI 故事。
- 一个专门为该评估者生成的个性化 AI 故事,基于他们自己的人口统计特征和兴趣。
他们根据四个指标对故事进行评分: 满意度 (Satisfaction) 、质量 (Quality) 、参与度 (Engagement) 和个人相关性 (Personalness) 。
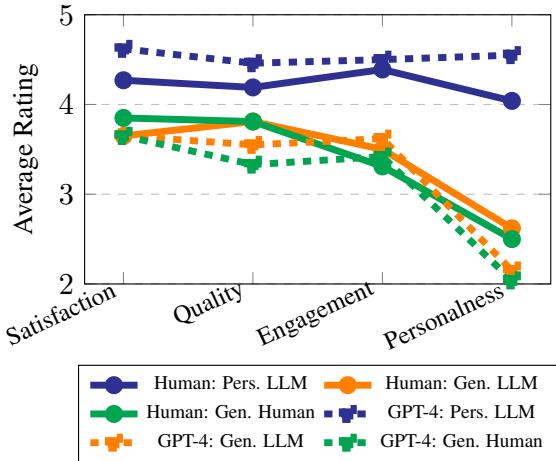
图 4 揭示了个性化的决定性胜利。
- 通用 AI vs. 人类: 有趣的是,通用 AI 故事 (紫色虚线) 的得分通常低于或大致等于通用人类故事。仅仅使用 AI 并不能保证故事更好。
- 个性化提升: 个性化故事 (蓝线) 在所有指标上的得分都显著更高。
- 参与度: 读者发现关于他们自己的故事更具吸引力。
- 个人相关性: 自然,这个分数飙升。
- 质量与满意度: 甚至写作的感知质量也因为故事是个性化的而被评为更高。
结论很明确: 个性化是参与度的倍增器。读者仅仅因为感觉被叙事所关注,就愿意给故事打出更高的质量分。
机器中的偏见
虽然结果是积极的,但这篇论文也作为一个警世故事,提醒我们 LLM 固有的偏见。研究人员分析了 GPT-4 如何评估这些故事,并发现了“偏好偏差 (preferential biases) ”。
即使写作质量相似,AI 评估者也倾向于给某些人口统计特征的故事打出比其他特征更高的分数。
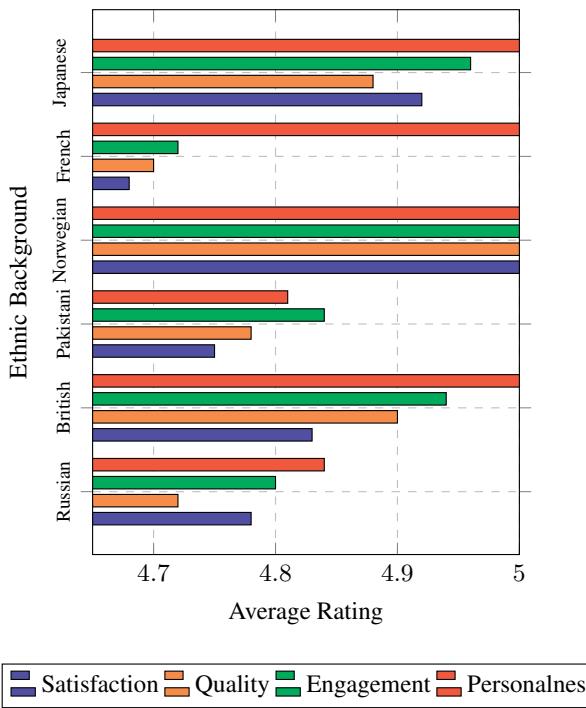
图 14 强调了模型对特定文化的迷恋。以 日本人 和 挪威人 为角色的故事获得的分数始终较高 (接近 5.0) ,而以 法国人 或 巴基斯坦人 为角色的故事得分则相对较低。
此外,研究人员还注意到性别偏见。模型倾向于将包含 非二元性别 (Non-binary) 角色的故事在“个人相关性”上打分高于男性或女性角色的故事。
这对于开发者来说是一个至关重要的发现。如果我们要利用 AI 来解决多样性鸿沟,我们必须确保 AI 本身不会只是用一套偏见取代另一套偏见。
超越文本: 可视化故事
没有插图,“镜像”体验是不完整的。在一项补充实验中,研究人员探索了使用图像生成模型 (如 DALL-E 2) 来创作伴随文本的个性化插图。
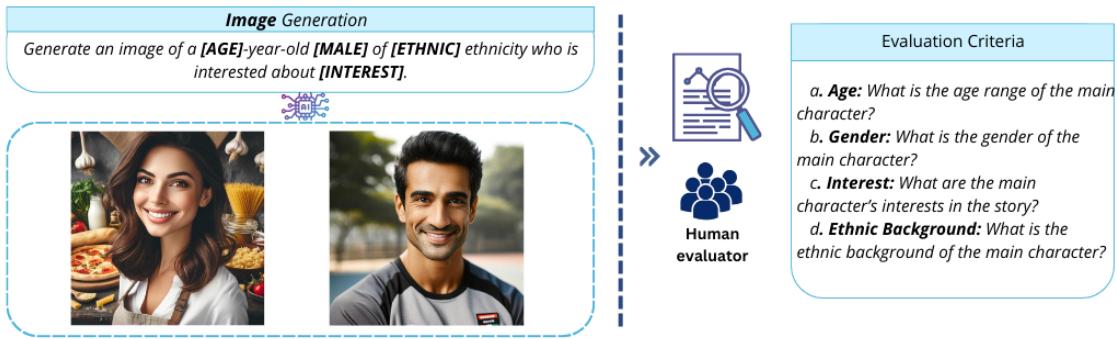
如 图 18 所示,他们使用类似的提示词结构来生成角色图像。然后要求人类评估者仅通过图像猜测年龄、性别和种族。
结果很有希望,特别是对于 性别 (100% 准确率) 和 兴趣 (95% 准确率) 。 然而,种族很难在视觉上准确呈现,识别率较低 (约 73%) 。这表明,虽然文本生成的个性化已经高度成熟,但图像生成在不依赖刻板印象的情况下呈现特定种族细微差别方面仍显吃力。
结论: 阅读的未来
MIRRORSTORIES 论文提供了令人信服的证据,表明我们正在进入文学的新纪元。我们正从“一对多”模式 (数百万人阅读同一本书) 转向潜在的“一对一”模式,即叙事适应读者。
这影响深远,尤其是在教育领域。如果一个学生在阅读理解上遇到困难,一个针对他们对“机器人”或“足球”的兴趣量身定制,并以分享其背景的主角为特色的故事,可能是释放他们潜力的关键。
然而,作者也谨慎地指出了局限性。这些只是短篇故事 (约 300 字) ,且评估是主观的。此外,模型中发现的偏好偏差提醒我们,AI 并不是文化的终立仲裁者。
尽管面临这些挑战,MIRRORSTORIES 证明了 AI 能做的不仅仅是生成文本;它可以生成连接。通过为读者举起一面镜子,LLM 提供了一种使文学比以往任何时候都更具包容性、更具吸引力和更个性化的方式。