](https://deep-paper.org/en/paper/2409.13980/images/cover.png)
人工智能在“看”世界方面已经取得了巨大的进步。现代模型可以轻松地识别照片中的猫,或者告诉你这辆车是红色的。这被称为视觉感知 。 然而,如果你给 AI 看一张一个人在熨烫三明治的照片,并问它“这有什么好笑的?”,传统模型往往会束手无策。它们可能看得到熨斗和三明治,但无法理解这种情境的荒谬之处。这就是复杂视觉推理的挑战。
虽然像 CLIP 或 BLIP 这样的视觉语言模型 (VLM) 在感知方面表现出色,而像 GPT-4 或 LLaMA 这样的大型语言模型 (LLM) 是推理的大师,但在不花费巨额计算成本的情况下将两者结合起来仍然是一个障碍。通常,连接视觉与语言需要这就需要在数百万个图像-文本对上训练昂贵的“投影层”。
在这篇文章中,我们将深入探讨悉尼大学的一篇研究论文,该论文提出了一种更智能、更高效的方法来缩小这一差距。他们介绍了 CVR-LLM (复杂视觉推理大型语言模型) 。 这种方法不需要重新训练模型去“看”,而是将视觉信息转化为丰富的、上下文感知的文本描述,使 LLM 能够利用其现有的基于文本的智能来对图像进行推理。
视觉推理的版图
在剖析解决方案之前,我们必须先理解问题所在。视觉推理不仅仅是识别物体;它关乎理解关系、文化背景和常识。
研究人员在五个截然不同且困难的基准上测试了他们的模型,如下图所示:
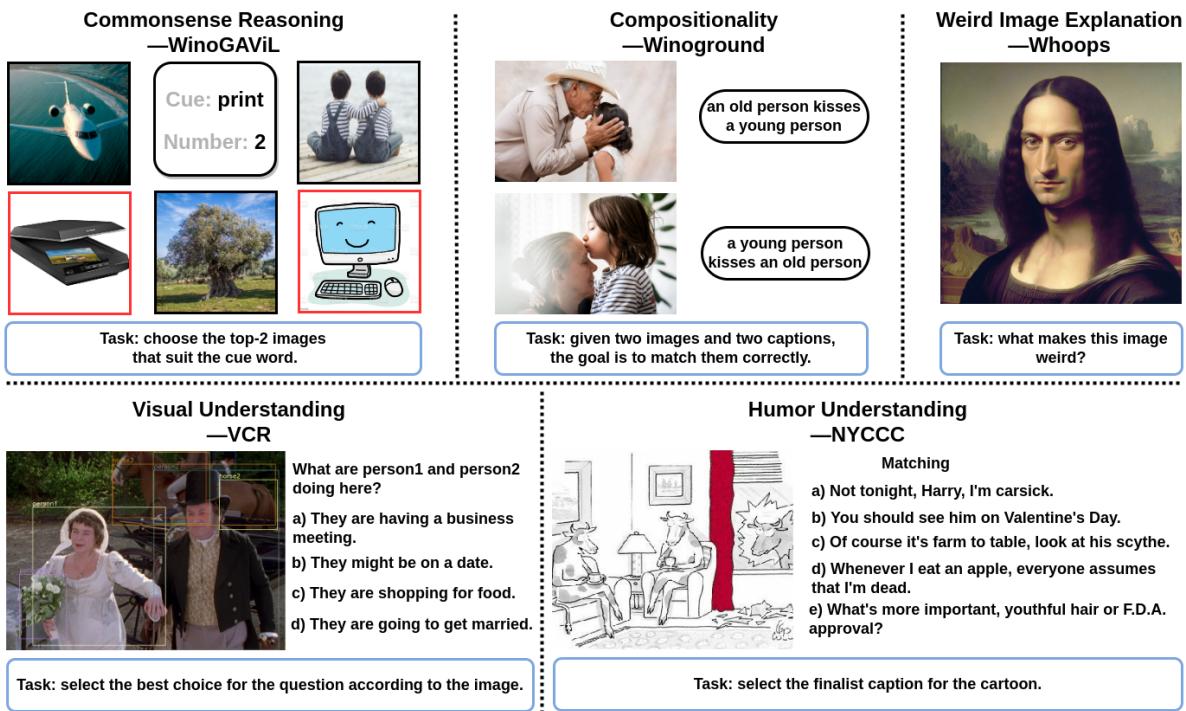
- 常识推理 (WinoGAViL): 基于抽象关联识别图像 (例如,将“打印”与扫描仪还是喷气式滑雪板联系起来?) 。
- 组合性 (Winoground): 区分词序改变导致意义完全不同的句子 (例如,“老人亲吻年轻人”与“年轻人亲吻老人”) 。
- 怪异图像解释 (Whoops): 解释为什么一张图像很奇怪 (例如,长着男性面孔的蒙娜丽莎) 。
- 视觉理解 (VCR): 推断意图,比如为什么两个穿西装的人在握手。
- 幽默理解 (NYCCC): 将说明文字与卡通匹配以产生幽默效果。
大多数多模态大型语言模型 (MLLM) 在这里都很吃力,因为它们缺乏特定的“推理”层来将它们所看到的内容与它们对世界的认知联系起来。
核心理念: VLM + LLM
CVR-LLM 的中心论点简单而深刻: 我们要做的不是教 LLM 去“看”,而是教 VLM 更好地去“描述”。
当前最先进的 MLLM (如 LLaVA 或 MiniGPT-4) 依赖于一个投影层,将视觉特征转化为 LLM 可以消化的语言格式。这虽然行得通,但资源消耗巨大。CVR-LLM 通过使用一种仅推理 (inference-only) 的方法绕过了这一点。它使用一个“双循环”系统,由 LLM 实际指导视觉模型去寻找特定的细节。
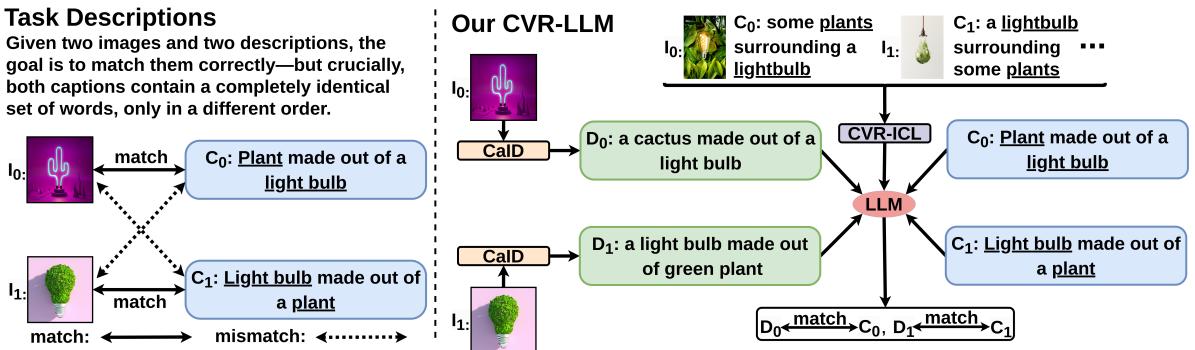
如上图所示,系统不仅仅是将图像输入一个黑盒,而是生成上下文感知图像描述 (CaID) 。 对于像 Winoground 这样的任务,“由灯泡制成的植物”和“由植物制成的灯泡”之间的区别微妙但至关重要,标准的“一个灯泡和一个植物”这样的字幕会失效。CVR-LLM 迭代地修正描述,直到它捕捉到解决难题所需的特定语义细节。
方法第一部分: 上下文感知图像描述 (CaID)
这篇论文的核心是上下文感知图像描述 (CaID) 框架。标准的图像字幕生成器是通用的。如果你给它们看一张抢劫的照片,它们可能会说“穿西装的人站着”。这对于回答“为什么这些人很危险?”毫无用处。
CaID 使用自我修正循环解决了这个问题。
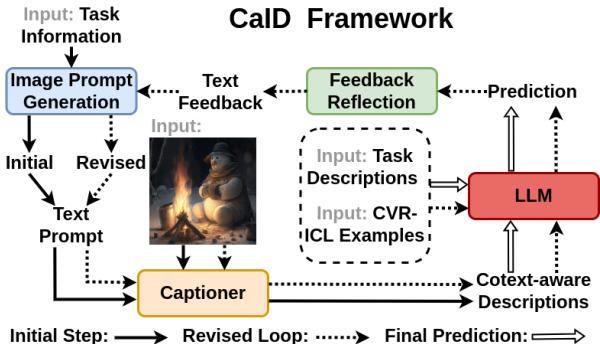
以下是该过程的分步工作原理:
- 初始字幕生成: 系统使用标准 VLM (如 BLIP-2) 生成基本字幕。
- LLM 反馈: LLM 将此初始字幕与用户的意图或任务一起进行审查。
- “提问”阶段: LLM 意识到初始字幕不足。它生成一个特定的查询 (例如,“这些人手里拿着什么?”) 。
- 修正字幕生成: VLM 在这个新查询的指导下重新扫描图像,并生成更丰富、上下文感知的描述 (例如,“穿西装的人手里拿着枪”) 。
数学公式化
研究人员优雅地将这个迭代过程形式化了。初始描述 (\(d_{init}\)) 由字幕生成器 (\(C\)) 使用图像 (\(i\)) 和由 LLM (\(L\)) 基于任务 (\(t\)) 生成的提示词生成:
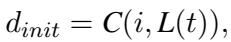
在第二个循环中,系统结合了 LLM 的反馈。LLM 分析初始预测 (\(p\)) 并制定一个查询 (\(Q\))。该查询用于更新提示词,从而产生修正后的描述 (\(d_{revised}\)):
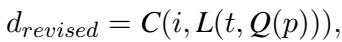
这将一个通用的“盲目”猜测变成了有针对性的调查。
一个具体示例
为了看到实际效果,请看下面来自视觉常识推理 (VCR) 数据集的示例。问题是“为什么 Person1 和 Person4 有枪?”

- 初始字幕: “一张图片,显示一个穿西装带枪的男人和另一个穿西装带枪的人。”
- LLM 查询: LLM 意识到它需要区分他们或理解他们的意图,所以它问: “Person1 和 Person4 的外貌是什么?”
- 修正后的答案: 字幕生成器更新了细节,特别指出了他们的穿着和互动方式。
这一具体细节使得 LLM 最终能够根据通用字幕会错过的视觉线索,推断出他们是在抢劫酒店房间还是保安人员。
方法第二部分: 复杂视觉推理上下文学习 (CVR-ICL)
LLM 以“少样本学习者”而闻名——如果你给它们几个任务示例 (上下文) ,它们的表现会好得多。这被称为上下文学习 (ICL) 。
然而,为视觉任务选择正确的示例是很棘手的。如果仅根据文本相似性选择示例,你会错过视觉上的细微差别。如果仅使用图像相似性,你可能会错过语义相关性。
作者提出了 CVR-ICL , 这是一种通过分析文本和视觉两个领域的相似性来选择示例的策略。
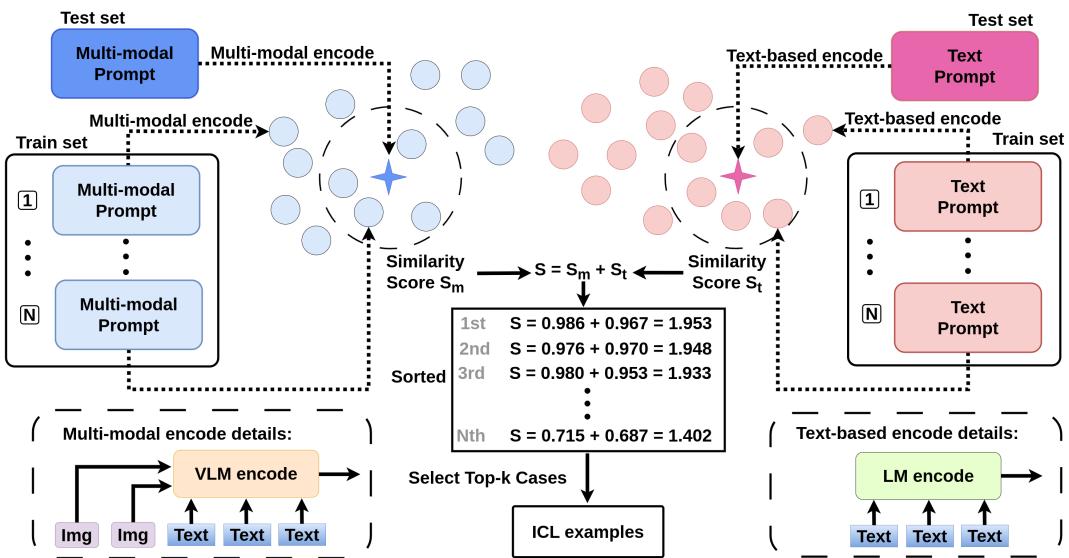
工作原理
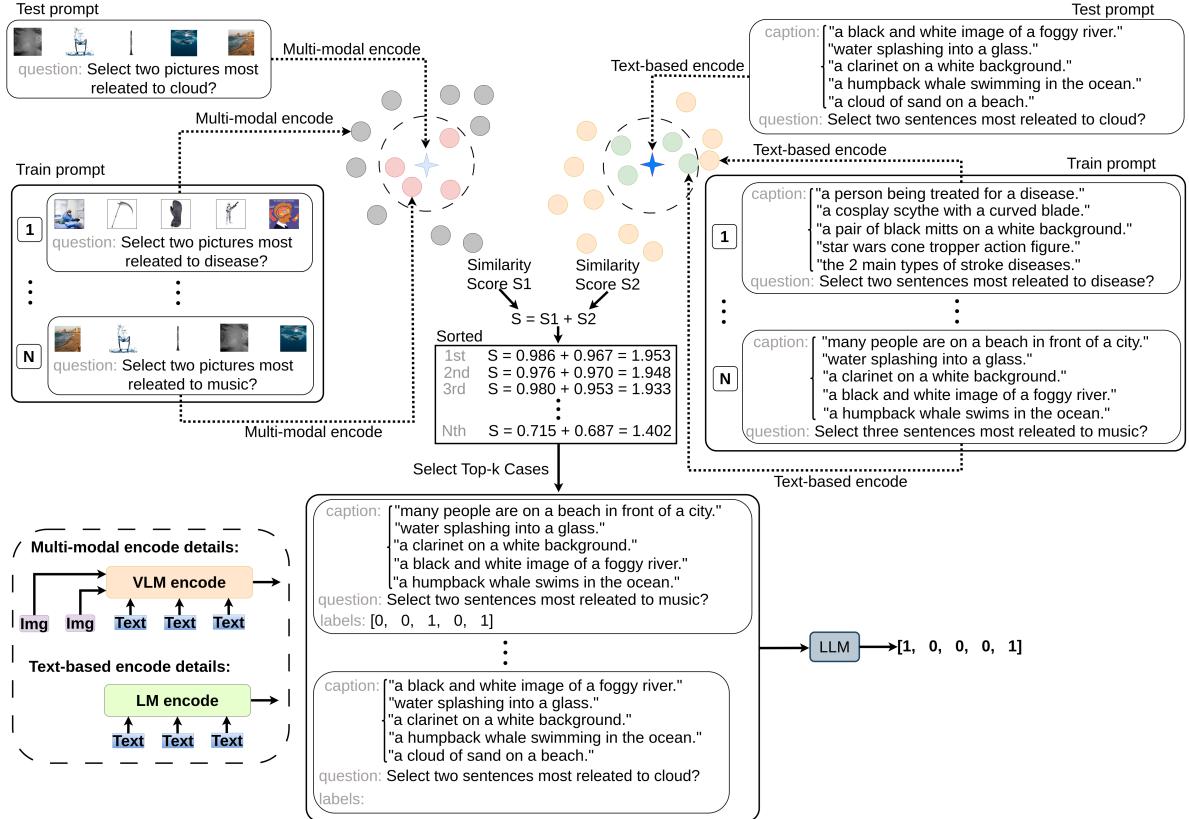
当模型接收到一个新的测试用例时:
- 多模态编码: 它使用 VLM 编码器 (\(f_m\)) 将图像和文本转换为向量表示 (\(x_m\))。
- 基于文本的编码: 它使用文本编码器 (\(f_t\)) 将生成的描述和文本转换为向量 (\(x_t\))。
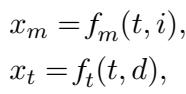
然后,它通过结合多模态向量和文本向量的余弦相似度 (\(f_c\)),计算当前测试用例与训练集中潜在示例之间的相似度分数 (\(s\))。
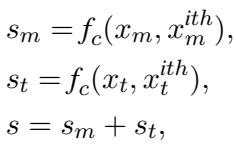
具有最高综合得分 (\(s\)) 的前 k 个示例被作为提示词输入给 LLM。这确保了 LLM 看到的示例不仅在主题上相关,而且在视觉构成上也相关。
下图详细展示了在 WinoGAViL 数据集上的这一检索过程,显示了视觉和文本匹配的并行路径:
评估: 衡量不可衡量之物
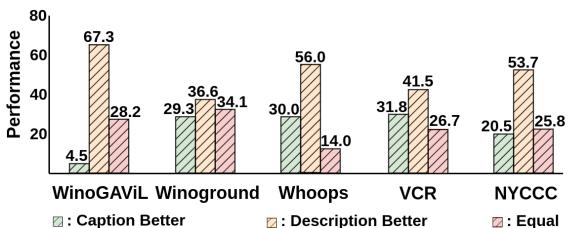
你如何衡量 AI 是否理解“怪异”?像 BLEU 或 CIDEr 这样的标准指标衡量的是单词重叠,但在判断抽象推理方面表现糟糕。
为了解决这个问题,作者引入了比较链 (Chain-of-Comparison, CoC) 。 这是一种使用 GPT-4 作为裁判的新颖评估技术。它强制模型通过四个认知步骤将通用字幕 (选项 A) 与上下文感知描述 (选项 B) 进行比较:
- 初始感知: 字面意思是什么?
- 识别不协调之处: 它是否发现了错误或不寻常的地方?
- 上下文分析: 它如何适应这种情境?
- 关联问题: 哪个选项更好地回答了提示?

作者使用 GPT-4 验证了这一假设,发现在像“Whoops” (识别怪异图像) 这样的复杂任务中,上下文感知描述大大优于标准字幕。
实验结果
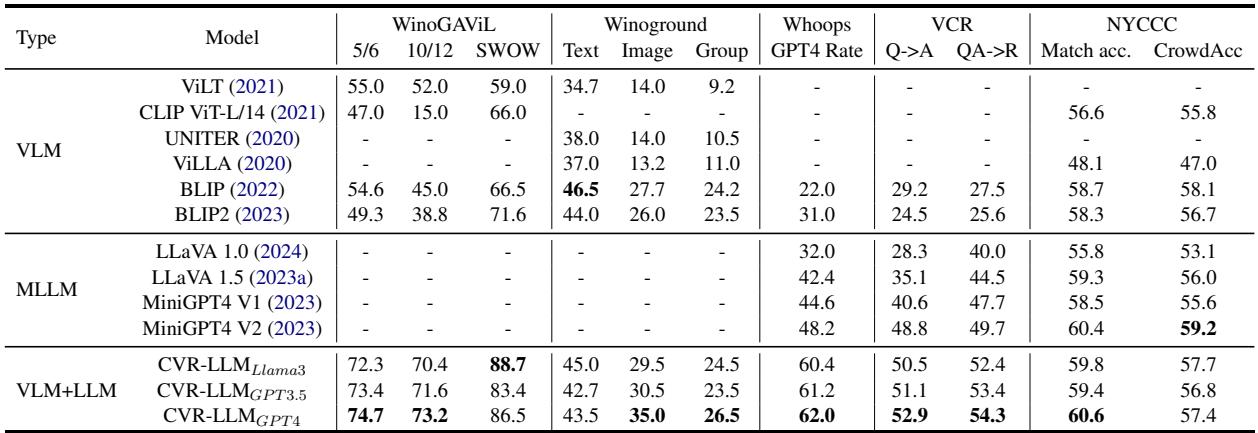
那么,它有效吗?结果表明答案是肯定的。CVR-LLM 与传统的 VLM (如 ViLT 和 CLIP) 以及现代 MLLM (如 LLaVA 和 MiniGPT-4) 进行了测试。
主要发现:
- SOTA 表现: CVR-LLM 在所有五个基准测试中均达到了最先进水平 (State-of-the-Art) 。
- 击败 LLaVA: 在“Whoops”数据集 (检测怪异之处) 中,CVR-LLM (62.0 GPT-4 评分) 显著优于 LLaVA 1.5 (42.4) 。
- 通用性: 无论底层 LLM 是 LLaMA-3、GPT-3.5 还是 GPT-4,它都能有效工作。
定性分析
该模型的强大之处在定性示例中体现得最为明显。在下面的“Whoops”数据集示例中,请看棋子 (下排) 。标准模型可能只会看到“棋子”。但 CVR-LLM 问道: “棋子长什么样?”从而使其识别出这颗棋子看起来像一只独角兽 , 这就解释了为什么这张图片很“怪异”。

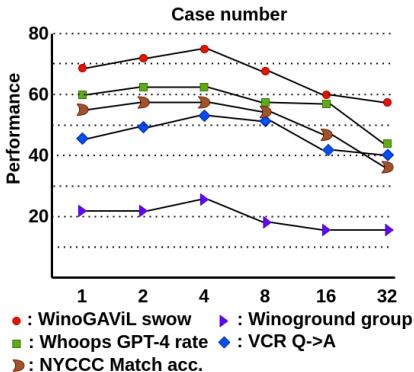
敏感性分析
研究人员还分析了多少个上下文示例 (shot) 是最佳的。有趣的是,并非越多越好。性能在 4 个示例左右达到峰值,然后下降或停滞,这可能是由于上下文窗口变得混乱或不相关所致。
与 GPT-4V 的比较
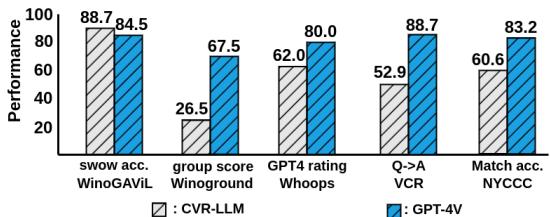
也许最雄心勃勃的比较是与当前的行业巨头 GPT-4V (带视觉功能的 GPT-4) 进行比较。GPT-4V 是一个端到端的多模态模型,而 CVR-LLM 是由独立模型组成的流水线。
虽然 GPT-4V 通常优于 CVR-LLM (考虑到资源差异,这是预料之中的) ,但 CVR-LLM 实际上在 WinoGAViL (SWOW) 基准测试中超越了 GPT-4V。这证明了一个经过精心调整的小型模型流水线,通过使用智能提示和描述修正,可以与庞大的端到端基础模型竞争。
结论
这篇题为“Enhancing Advanced Visual Reasoning Ability of Large Language Models”的论文提出了一个令人信服的观点: 我们并不总是需要更大的多模态模型;我们需要的是现有视觉和文本模块之间更智能的沟通。
通过实施上下文感知图像描述 (CaID) , 作者将静态的图像字幕生成过程转变为动态的对话。通过开发 CVR-ICL , 他们确保了 LLM 能够获得最相关的多模态示例提示。
这项工作使复杂视觉推理变得大众化。它表明,研究人员和学生不需要庞大的计算集群来训练 LLaVA 规模的模型以解决复杂的视觉任务。相反,通过利用 LLM 的推理能力来引导 VLM 的“眼睛”,我们可以在计算机视觉的一些最难题上取得最先进的成果。