](https://deep-paper.org/en/paper/2409.14065/images/cover.png)
在构建通用人工智能 (AGI) 的竞赛中,我们通常将大语言模型 (LLMs) 视为传统知识库的终极替代品。我们希望能够问 AI 一个问题,比如“林肯之前的总统是谁?”或者“林肯公园在《Meteora》之后发行了哪张专辑?”,并得到即时、准确的回答。
然而,将 LLM 视为一本静态百科全书暴露了一个致命缺陷: 时间。
事实不仅仅是孤立的数据点;它们通常是序列。总统按顺序任职。软件版本按时间顺序发布。如果一个 LLM 知道 事件 B 发生了,它应该逻辑上理解 事件 A 发生在其之前,而 事件 C 发生在其之后。此外,无论你是问“X 之后是什么?”还是“X 被什么紧随?”,模型都应该给出相同的答案。
最近一篇题为 “Temporally Consistent Factuality Probing for Large Language Models” (大语言模型的时间一致性事实探针) 的研究论文揭示了当前最先进模型的一个重大弱点: 它们在保持这种“时间一致的事实性”方面表现糟糕。在这篇深度文章中,我们将探讨研究人员如何通过一个名为 TeCFaP 的新基准来诊断这个问题,以及他们如何提出一种名为 CoTSeLF 的新颖解决方案来教模型尊重时间线。
问题所在: 结构简单性 vs. 时间现实
在 LLM 出现之前,我们使用知识库 (KBs) ——包含诸如 (巴拉克·奥巴马, 出生于, 夏威夷) 等事实的结构化数据库。这些系统虽然死板但保持一致。另一方面,LLM 很灵活。你可以用自然语言向它们提问。
但这种灵活性是有代价的。现有的 LLM 基准测试通常检查“结构简单性”。它们会问模型是否知道主体、关系和客体 (例如,巴黎是法国的首都) 。这些事实通常被视为“当代的”,意味着主体和客体同时存在,没有复杂的时间维度。
研究人员认为这还不够。信息随着时间的推移而产生、维护和丢失。要真正信任一个 LLM,它必须展示出 时间推理 (Temporal Reasoning) 能力。
知识的三个维度
作者将知识可视化为一个三维空间:
- 主体 (Subject) : 我们正在讨论的实体 (例如,林肯公园) 。
- 关系 (Relation) : 动作或连接 (例如,发行) 。
- 时间 (Time) : 事件发生的特定历史时刻。
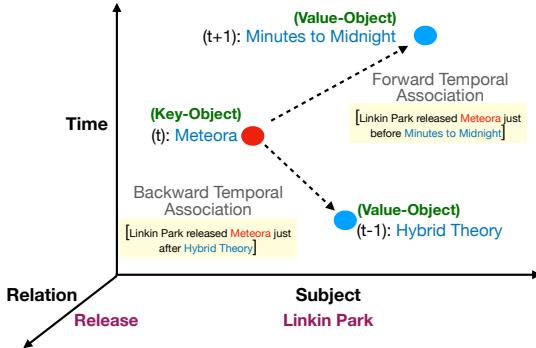
如 图 1 所示,真正的知识测试涉及沿时间轴移动。如果模型知道时间 \(t\) 的“关键对象 (Key Object) ” (例如专辑《Meteora》) ,它能否正确识别时间 \(t+1\) 的“值对象 (Value Object) ” (下一张专辑《Minutes to Midnight》) 或时间 \(t-1\) 的对象 (上一张专辑《Hybrid Theory》) ?
至关重要的是,模型必须保持一致。如果提示暗示了前向方向 (“就在…之前发行”) 或后向方向 (“就在…之后发行”) ,模型必须正确地在时间线上导航。
介绍 TeCFaP 和 TEMP-COFAC
为了测试这种能力,研究人员推出了 TeCFaP (时间一致性事实探针,Temporally Consistent Factuality Probe) 。 这是一项旨在检查 LLM 是否能根据时间顺序一致地检索事实的任务,无论问题是如何表述的。
为了执行这项任务,他们需要数据。他们不能只使用维基百科的摘要;他们需要严格、有序的事件序列。于是他们创建了一个名为 TEMP-COFAC 的新数据集。
TEMP-COFAC 是如何构建的
该数据集的构建是一个严格的半自动化过程,涉及人类专家的参与以确保高质量。
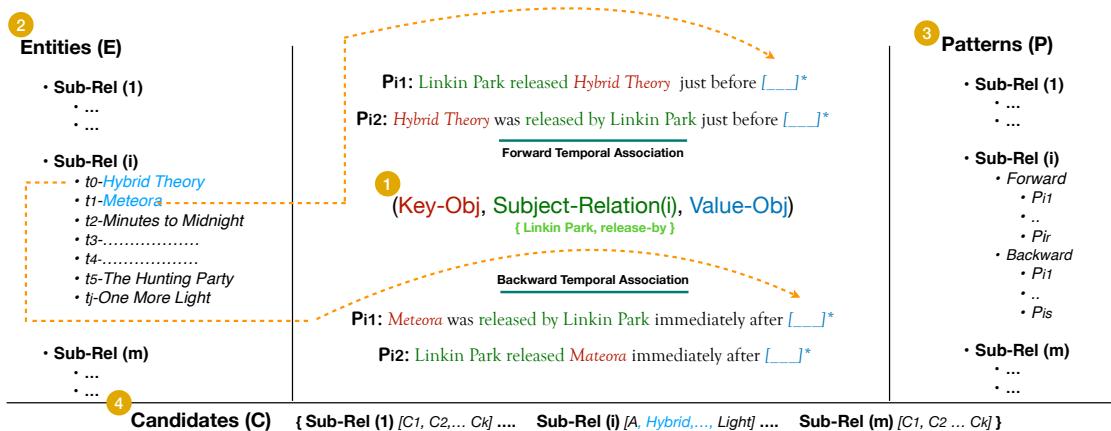
如 图 2 所示,该过程包括四个不同的步骤:
- 主体-关系对: 他们选择了音乐、政治、技术和企业历史等多样的像 (例如,林肯公园 - 发行) 。
- 实体排序: 他们整理了一份严格按时间排序的实体列表 (\(E_i\)) 。这不仅仅是一堆事实;它是一条时间线 (例如,\(t_0, t_1, t_2...\)) 。
- 转述模式: 这对于测试一致性至关重要。他们使用工具和人工验证来创建多种询问同一时间问题的方式。
- *前向: * “X 就在 [Y] 之前发行”
- *后向: * “X 就在 [Y] 之后发行”
- 候选集: 一个可能的答案词汇表,用于检查模型是在完全胡说八道,还是仅仅搞错了顺序。
由此产生的数据集非常稳健,涵盖了跨越几个世纪历史的 10,000 多个独特样本。
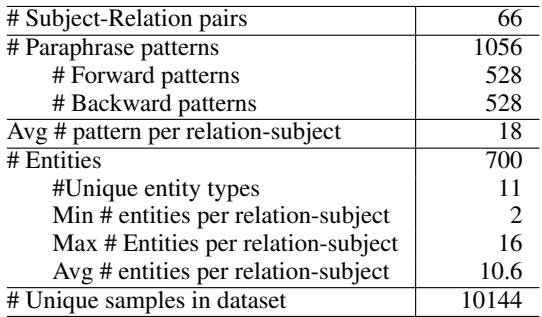
表 1 显示了该资源的规模。它拥有 66 个不同的主体-关系对和 1000 多个转述模式,为任何 LLM 提供了一个全面的压力测试。
指标
研究人员定义了三个关键指标来对模型进行评分:
- 时间事实性 (Temporal Factuality, Temp-fact) : 模型给出的答案正确吗? (例如,如果问《Meteora》之后是什么,它会说是《Minutes to Midnight》吗?)
- 时间一致性 (Temporal Consistency, Temp-cons) : 如果我们用 5 种不同的方式 (转述) 问这个问题,模型每次给出的答案是否完全相同?注意: 答案不一定要正确才算一致,但产生幻觉的模型通常会对不同的提示给出不同的错误答案。
- 时间一致的事实性 (Temporally Consistent Factuality, Temp-cons-fact) : 黄金标准。模型必须在所有转述中既正确又一致。
解决方案: CoTSeLF
当研究人员在这个数据集上运行现有的 LLM (如 LLaMA 和 GPT-J) 时,结果极其糟糕 (详见实验部分) 。为了解决这个问题,他们提出了一种新的训练框架: CoTSeLF (一致性时间敏感学习框架,Consistent-Time-Sensitive Learning Framework) 。
CoTSeLF 结合了两种强大的技术: 多任务指令微调 (MT-IT) 和 一致性时间敏感强化学习 (CTSRL) 。 让我们逐一拆解。
第一阶段: 多任务指令微调 (MT-IT)
标准的指令微调教导模型遵循单个命令。作者意识到,为了提高一致性,模型需要理解两个不同的句子可能意味着同一件事。
他们设置了一个多任务学习目标:
- 任务 k1 (生成) : 标准任务。给定上下文和提示,用正确的事实完成句子。
- 任务 k2 (判别) : 二元分类任务。向模型展示两个句子,它必须决定: “这些是彼此的转述吗?”

图 3 展示了这一过程。通过强迫模型在学习生成事实 (任务 k1) 的同时显式地识别转述 (任务 k2) ,模型建立了对查询意图更稳健的内部表示,而不是被具体的措辞分心。
第二阶段: 一致性时间敏感强化学习 (CTSRL)
指令微调让模型取得了一定进展,但为了真正使模型与时间一致性对齐,研究人员使用了强化学习 (RL) 。
在标准的 RLHF (人类反馈强化学习) 中,模型因生成“好”的文本而获得奖励。在这里,研究人员设计了一个特定的奖励函数,关注 时间 和 一致性 。
奖励函数 \(R_d(x)\) 是两个组成部分的加权混合:
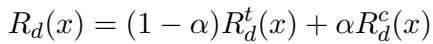
符号含义如下:
- \(R_d^t(x)\): 时间奖励。模型弄对事实了吗?
- \(R_d^c(x)\): 一致性奖励。模型是否正确识别了转述关系?
- \(\alpha\) (Alpha): 一个权重参数,用于平衡模型应在多大程度上关注一致性与纯粹的准确性。
研究人员特别使用了一个“离散”奖励变体,即模型答对得 1 分,答错得 0 分。
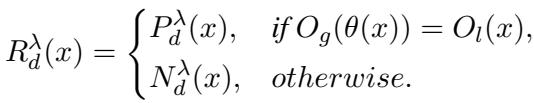
这个公式实际上是在告诉模型: “仅仅猜对正确的专辑是不够的。你还必须理解‘在之前发行’和‘先于’意味着相同的时间关系。”
实验与结果
那么,CoTSeLF 真的有效吗?研究人员使用 LLaMA 系列模型将其与几个基线进行了测试。
基线: LLM 在时间问题上苦苦挣扎
首先,看看零样本表现 (在没有任何训练示例的情况下询问模型) ,结果令人震惊。

表 2 显示,像 LLaMA-7B 和 Falcon-7B 这样的标准模型,其 时间一致的事实性 (Temp-cons-fact) 得分几乎为 0% 。 即使是更大的 13B 模型也难以达到 1%。这证实了假设: 标准的预训练并没有让模型具备在转述中保持严格时间序列一致性的能力。
知识 vs. 时间
一个有趣的附带发现是,模型的知识如何随历史时期而变化。
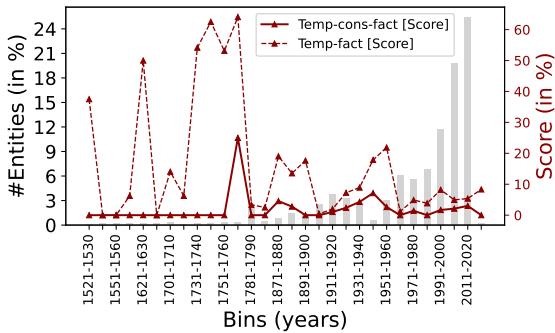
图 5 绘制了模型表现与历史的关系。注意图表右侧 (2011-2020 年) 的巨大峰值。模型对近期事件的时间推理能力远强于 1600 年代或 1700 年代的事件。这种偏差可能源于训练数据——互联网 (以及维基百科) 关于近期流行文化和科技发布的内容远多于历史序列。
CoTSeLF 的提升
当研究人员将 CoTSeLF 框架应用于 LLaMA-13B 模型时,性能显著提高。
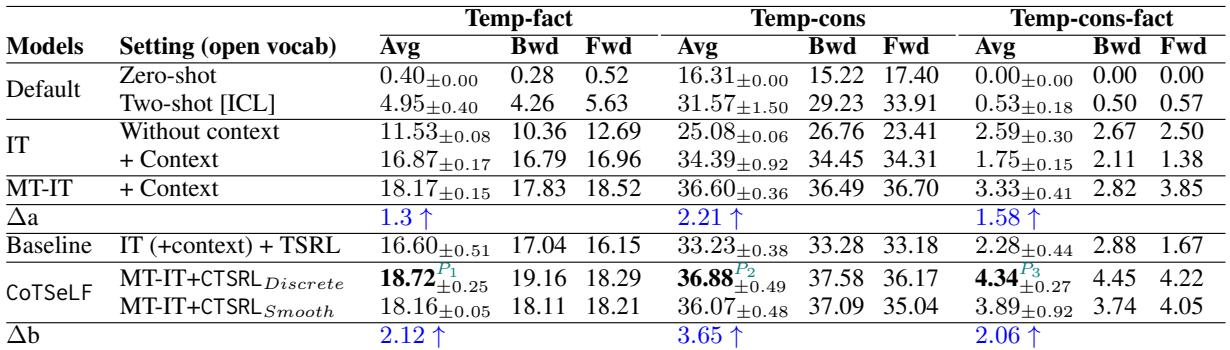
表 3 突出了关键结果:
- 基线 (零样本) : 几乎 0% 的一致事实性。
- 基线 (标准指令微调) : 约 1.75% 的一致事实性。
- CoTSeLF (MT-IT + CTSRL) : 4.34% 的一致事实性。
虽然 4.34% 的绝对值听起来很低,但相对于起点,它代表了比最强基线 (TSRL) 高出 90.4% 的提升 。 它还将严格的 时间事实性 (准确性) 从 16.60% 显著提高到了 18.72% 。
这证明了针对一致性进行训练不仅能使模型更稳定;实际上还能帮助它更频繁地检索到正确信息。
模型哪里出错了?
研究人员进行了错误分析,以查看哪些类型的实体对模型来说最难。
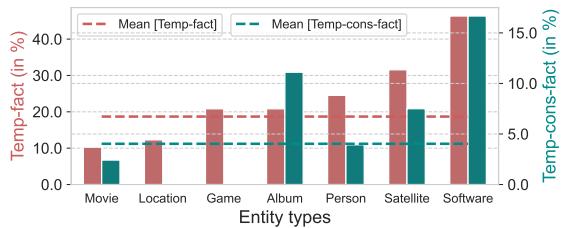
图 8 显示,“游戏”、“卫星”和“软件”的表现优于“电影”或“地点”。这表明,具有非常严格、编号版本控制的实体类型 (如 Android 版本或连续的游戏续集) 可能比电影或专辑的抽象发行顺序更容易让模型掌握。
为什么这很重要
这项研究凸显了我们当前 AI 能力中的一个关键差距。如果我们希望 LLM 能够作为可靠的助手用于法律分析 (先例 A 发生在先例 B 之前) 、病史 (症状 X 出现在治疗 Y 之后) 或历史教育,它们就需要掌握时间。
关键要点:
- 转述会破坏模型: 改变时间问题的措辞通常会导致当前的 LLM 产生幻觉,给出不同的答案。
- 严格序列很难: 模型难以处理 \(t-1\) 和 \(t+1\) 的逻辑,更喜欢依赖松散的关联而不是严格的时间线。
- CoTSeLF 有效: 通过显式训练模型识别转述 (多任务学习) 并奖励一致性 (CTSRL) ,我们可以迫使它们更有效地构建内部知识。
TeCFaP 基准为 AI 的诚实设定了新标准。仅仅知道一个事实是不够的;AI 必须一致地知道它,无论我们如何提问,也无论该事实处于历史时间线的哪个位置。