](https://deep-paper.org/en/paper/2409.14247/images/cover.png)
想象一下,你正在和一个机器人助手一起做饭。你让它“把大碗递给我”。机器人伸手去拿滤锅。你立刻说: “不,是左边那个陶瓷的。”机器人停顿了一下,处理了你的纠正,然后成功地把搅拌碗递给了你。
这种互动对人类来说微不足道。我们在对话中不断地协商意义。如果我们误解了什么,我们会修正它,然后继续。然而,对于人工智能——特别是视觉语言模型 (Vision-Language Models, VLMs) ——这个过程极其困难。目前大多数 AI 基准测试都侧重于根据单条指令一次就把事情做对。但是,当 AI 出错时会发生什么?它能恢复吗?
在论文**“Repairs in a Block World: A New Benchmark for Handling User Corrections with Multi-Modal Language Models”** (积木世界中的修复: 处理多模态语言模型用户纠正的新基准) 中,来自赫瑞瓦特大学的研究人员探索了这个确切的问题。他们引入了一个新的数据集,建立了人类基准,并提出了新颖的训练方法,以帮助 AI 理解“第三位置修复 (Third Position Repairs) ”——即当误解变得明显时所使用的特定类型的纠正。
这篇文章将分解他们的研究,解释为什么机器人难以处理纠正,以及特定的训练技术如何使它们成为更好的协作者。
问题: 沟通是双向的
在自然语言理解 (NLU) 领域,研究通常将沟通视为单向过程: 人类发出命令,机器执行命令。但真正的对话是主动的。它涉及交际基础建立 (Communicative Grounding) ——即确保相互理解的协作努力。
当发生误解时,我们会使用修复 (repair) 机制。作者特别关注第三位置修复 (Third Position Repairs, TPRs) 。 TPR 序列的工作原理如下:
- 轮次 1 (说话者) : 发送信息 (例如,“移动那个绿色积木”) 。
- 轮次 2 (受话者) : 根据他们的理解做出回应或行动 (例如,机器人指向了错误的积木) 。
- 轮次 3 (说话者) : 意识到误解并发出修复 (例如,“不,是它下面的那个”) 。
处理这第三个轮次的能力对于鲁棒的 AI 至关重要。如果模型无法处理修复,整个协作任务就会失败。
介绍 BLOCKWORLD-REPAIRS
为了研究这个问题,研究人员创建了 BLOCKWORLD-REPAIRS (BW-R) 。 这是一个位于虚拟桌面操作任务中的协作对话数据集。目标很简单: 人类指示机器人拿起特定的积木并将其移动到特定位置。
然而,该任务被设计为具有歧义性。桌子上堆满了外观相似的积木,使得单轮指令很容易失败。

如图 1 所示,对话遵循特定的结构:
- T1 (指令) : 用户发出复杂的命令。
- T2 (候选响应) : 系统预测一个边界框 (通常是不正确的) 并请求确认。
- T3 (修复) : 用户纠正系统,通常使用相对语言,如“那下面的积木”。
- T4 (系统预测) : 系统现在必须结合视觉上下文、原始指令、自身的错误以及修复内容来找到正确的目标。
该数据集包含通过 Amazon Mechanical Turk 收集的 795 个对话,重点关注复杂的多模态任务指令。
当前模型的挑战
为什么这对 AI 来说很难?当前的视觉语言模型 (如 LLaVA 或 Idefics2) 非常擅长描述图像或回答直接问题。然而,它们在处理指称歧义 (referential ambiguity) 和在多轮对话中保持上下文方面表现挣扎。
研究人员在这个新数据集上测试了几个最先进的模型。他们评估了两个不同的任务:
- 源积木选择 (Source Block Selection) : 识别要捡起哪个积木。
- 目标位置预测 (Target Position Prediction) : 识别将积木放置在哪里 (桌子上的坐标) 。
结果如下面的表 1 所示,揭示了巨大的差距。
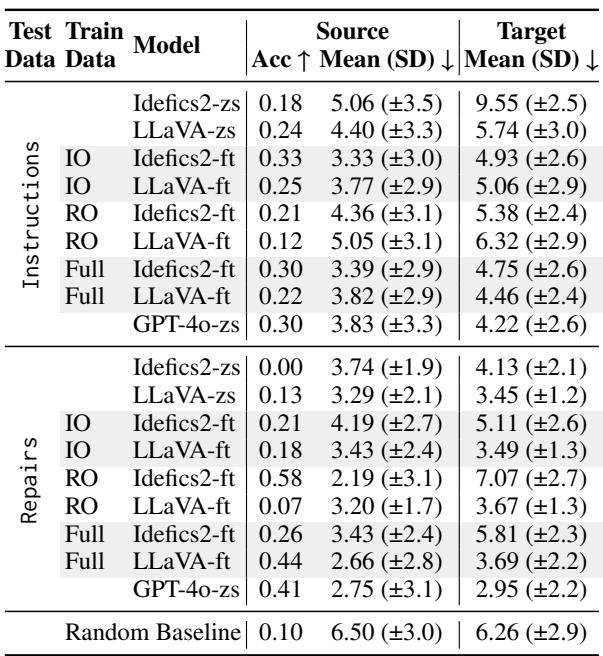
在零样本 (Zero-Shot, zs) 设置下 (即模型没有针对此任务进行专门训练) ,性能很差。例如,Idefics2 在源选择修复上的准确率为 0.00。
当模型经过微调 (Fine-Tuned, ft) 后,性能有所提高,但出现了一个有趣的问题。请注意,仅在“指令” (IO) 上微调的模型在“修复” (RO) 上表现挣扎,反之亦然。泛化是有代价的。模型难以将新指令的逻辑与纠正的逻辑整合在一起。
核心方法: 学习处理修复
研究人员假设 VLM 的标准训练方式可能是问题的一部分。
通常,当 VLM 进行微调时,它使用基于其生成的所有 Token 计算的交叉熵损失 (Cross-Entropy Loss) 。 在包含错误的对话语境中,这是有问题的。如果训练数据包含机器人的错误猜测 (轮次 2) ,随后是用户的纠正,模型可能会从其自身产生的幻觉或错误的中间 Token 中进行“学习”。
为了解决这个问题,作者尝试了Token 掩码策略 (Token Masking Strategies) 。 他们修改了损失函数,以便在训练期间忽略对话的特定部分。
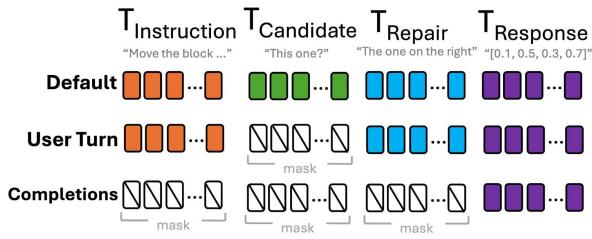
图 2 展示了测试的三种策略:
- 默认损失 (Default Loss) : 模型计算所有系统输出的损失,包括错误的候选响应 (T2) 和最终的正确响应 (T4) 。
- *风险: * 模型从中间的“坏” Token 中学习。
- 用户轮次损失 (User-Turn Loss) : 仅计算用户指令和最终正确响应的损失。中间的系统轮次被掩盖。
- 仅完成损失 (Completion-Only Loss) : 模型仅计算最终、正确的边界框预测 (T4) 的损失。它实际上将整个对话历史 (指令 + 错误 + 修复) 视为提示词 (prompt) ,并且仅根据最终答案进行惩罚。
掩码的结果
掩盖“坏”的中间 Token 有帮助吗? 表 2 中的结果表明确实如此,尤其是在泛化方面。
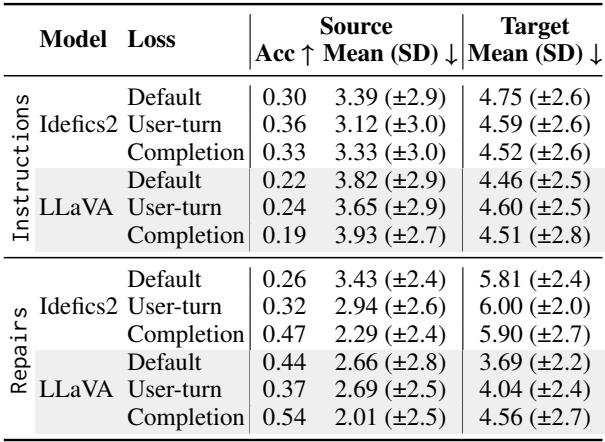
在使用完整数据集进行训练时, 仅完成 (Completion-Only) 损失 (每个模型的最后一行) 显示出最强的结果。
- 对于 LLaVA , 修复的准确率跃升至 0.54 (相比之下,默认损失为 0.44) 。
- 对于 Idefics2 , 修复的准确率达到 0.47 (相比之下,默认损失为 0.26) 。
这表明,通过防止模型对其自身模拟的错误进行优化,我们鼓励它将对话历史视为最终正确解决方案的上下文。它学会了“倾听”修复,而不是强化错误。
人类与机器: 性能差距
为了了解 AI 还有多远的路要走,研究人员进行了一项现场研究,由人类扮演机器人的角色。他们看到了相同的对话和图像,并被要求选择积木。
表 3 凸显了严峻的现实。
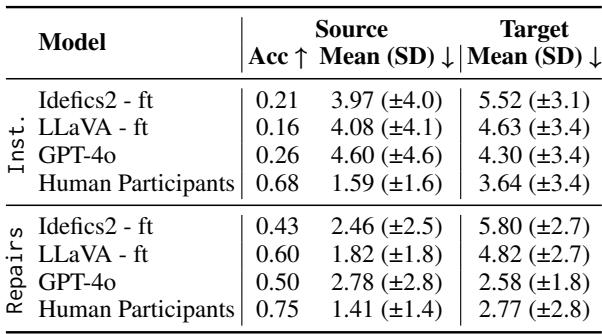
人类在源选择修复方面达到了 75% 的准确率 , 而最佳微调模型 (LLaVA) 达到 60% , GPT-4o 仅达到 50% 。
在目标位置预测 (确定把积木放在哪里) 方面,差距甚至更大。这是一个更难的任务,因为它涉及识别相对于其他对象的空白空间 (例如,“在那堆积木的右边”) 。人类保持了较低的误差距离 (2.77),而模型则表现得非常吃力。
错误可视化
我们可以在图 3 中看到这些挣扎的实际情况。
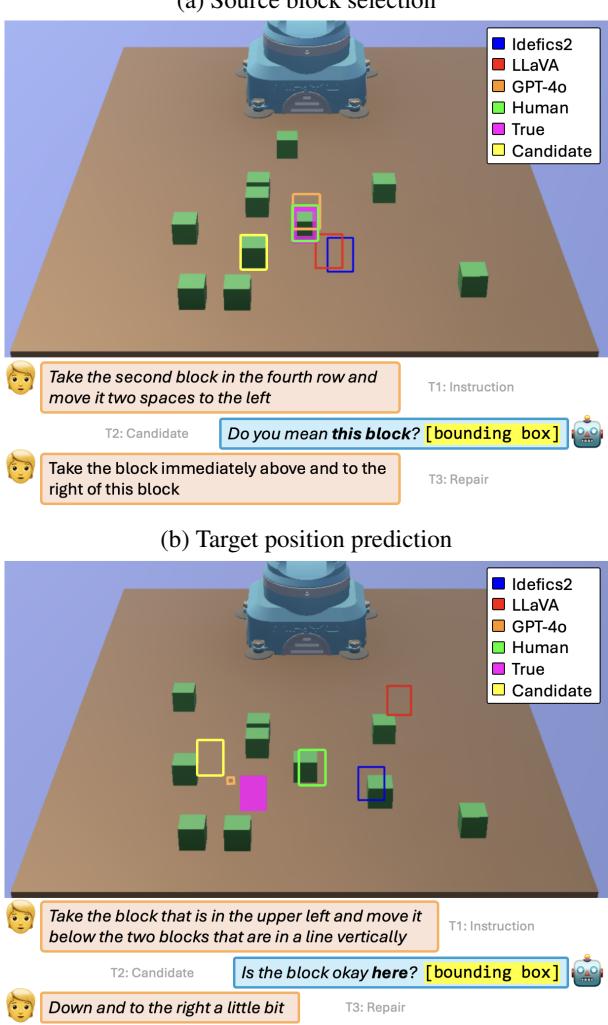
在顶部图像 (a) 中,尽管有修复,模型 (蓝色和红色框) 仍未能识别正确的积木。人类参与者 (绿色框) 正确识别了目标。模型在处理像“行”或“列”这样的抽象概念时很吃力,并且经常抓住像“左”或“右”这样的简单关键词,而不理解完整的关系上下文。
难度的悖论
最令人惊讶的发现之一来自对任务“难度”的分析。研究人员根据人类的表现将对话分为简单、中等和困难。你可能会预期 AI 会遵循同样的趋势: 在简单任务上表现良好,在困难任务上失败。
表 4 揭示了相反的情况。
看看源积木选择的困难 (Hard) 类别。人类的准确率为 0.00 (由类别的定义决定) ,然而 LLaVA 达到了 0.25 , Idefics2 达到了 0.22 。 相反,在人类表现完美 (1.00) 的简单 (Easy) 任务上,模型表现不佳 (0.35 - 0.45) 。
为什么会这样? 研究人员提出了一个语言学原因。对人类来说“简单”的例子通常涉及冗长、描述性的句子 (更多单词) 。“困难”的例子可能很短且指代不明 (单词较少) 。严重依赖文本模式的 VLM 实际上可能觉得“困难” (短) 的指令更容易解析,即使它们对人类来说有歧义。反之,对人类来说清晰的复杂、冗长的描述可能会压倒模型的空间推理能力。
结论与启示
BLOCKWORLD-REPAIRS 基准表明,虽然视觉语言模型正在进步,但它们尚未准备好在物理世界中进行无缝协作。
- 修复是独特的: 它们要求模型根据新信息修改其内部理解,而不仅仅是处理一条新命令。
- 训练很重要: 当数据涉及错误时,标准的训练目标可能会有害。掩盖中间错误有助于模型更好地泛化。
- “人类”差距: 模型在人类觉得直观的空间关系和抽象概念 (如“第三行”) 上表现挣扎。
对于学生和研究人员来说,这就这篇论文强调了未来工作的一个关键领域: 从交互中学习 。 要构建真正有用的机器人,我们不能仅仅用静态指令来训练它们。我们必须训练它们倾听、犯错,最重要的是,当我们说“不,不是那个”时,它们能理解我们。