](https://deep-paper.org/en/paper/2409.14703/images/cover.png)
引言
在数字时代,Meme (网络迷因/表情包) 不仅仅是有趣的图片;它们本身就是一种复杂的语言。它们可以将复杂的政治观点、社会评论和文化内部笑话提炼成一个单一的、易于分享的单元。然而,这种力量也有其阴暗面。Meme 已成为仇恨言论、网络欺凌和虚假信息的有力载体,往往隐藏在传统内容审核系统难以解析的反讽和挖苦层之下。
问题的核心在于 Meme 的多模态性质。一张微笑的卡通人物图片本身可能是无害的,文字“为你自己感到骄傲”单独看也是积极的。但是,将特定的图片与特定的文字结合起来,意义可能会从支持转变为嘲弄,甚至变为仇恨言论。这种复杂性对于边缘化群体 (如 LGBTQ+ 社区) 尤为严峻,在这里,鼓舞人心的声明、幽默的圈内笑话和仇恨性侮辱之间的界限可能非常模糊。
在这篇深度文章中,我们将探讨一篇直面这一挑战的研究论文。研究人员推出了 PrideMM (一个专注于 LGBTQ+ 图像的细致数据集) 和 MemeCLIP (一种旨在有效理解 Meme 细微差别的新颖框架) 。通过利用大规模预训练的力量并结合轻量级架构对其进行调整,这项工作代表了在构建更安全、更包容的互联网空间方面迈出的重要一步。
背景: 为什么 Meme 分析如此困难
要理解这项研究的必要性,我们需要先看看以前方法的局限性。
现有数据集的空白
大多数现有的仇恨言论检测数据集都是二元的: 它们将图像标记为“仇恨”或“非仇恨”。虽然这是一个很好的起点,但它无法捕捉人类表达的频谱。一个 Meme 可能对某些人来说具有冒犯性,但并不构成仇恨,或者它原本是作为讽刺 (幽默) 而非攻击。
此外,通用数据集往往缺乏理解针对特定群体的仇恨所需的具体语境。研究人员发现了关于 LGBTQ+ 运动资源的巨大空白。以前在该领域审核内容的尝试往往因为缺乏细微差别而导致所有 LGBTQ+ 内容受到压制——这种结果被称为“净化式审查”。
介绍 PrideMM
为了解决这个问题,作者发布了 PrideMM , 这是一个包含从 Twitter、Facebook 和 Reddit 收集的 5,063 张嵌入文本图像的数据集。PrideMM 的独特之处在于其 多方面标注模式 。 每一张图片不仅仅有一个简单的二元标签,而是通过四个不同的任务进行分析:
- 仇恨言论检测 (Hate Speech Detection): 内容是否包含仇恨?
- 仇恨目标分类 (Hate Target Classification): 如果包含仇恨,目标是谁? (非针对性、个人、社区或组织) 。
- 立场分类 (Stance Classification): 该 Meme 对 LGBTQ+ 运动是支持、反对还是中立?
- 幽默检测 (Humor Detection): 该 Meme 是否意在搞笑?
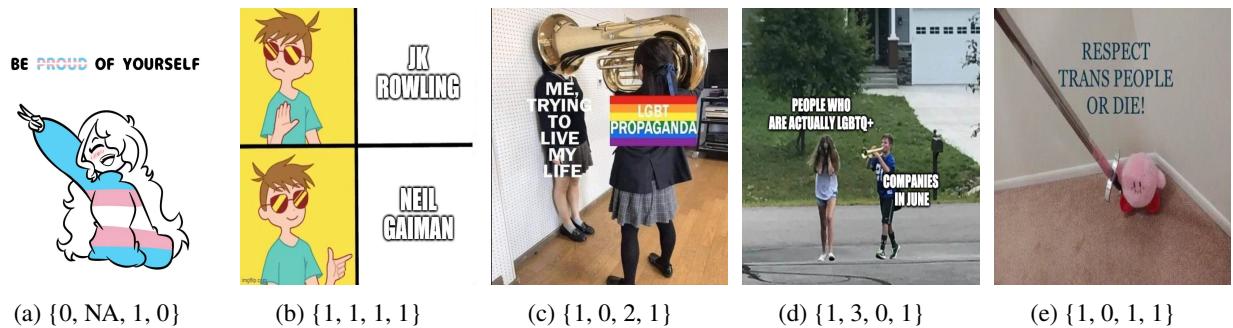
如上图 1 所示,该数据集捕捉了这些互动的复杂性。例如,图像 (c) 在言论上可能被归类为“无仇恨”,但在立场上属于“反对”,而图像 (b) 则针对特定个人 (J.K. Rowling) 。这种粒度允许模型学习区分笑话、政治立场和实际的仇恨言论。
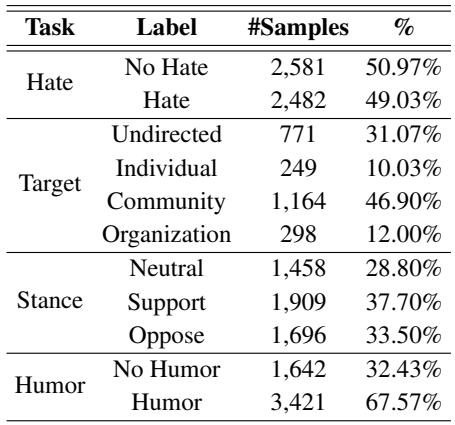
表 2 强调了数据集的分布情况。虽然“仇恨”标签相对平衡,但像“目标”分类这样的任务则严重不平衡,大多数仇恨针对的是“社区”而非特定个人。这种不平衡呈现了一个经典的机器学习挑战,作者提出的模型 MemeCLIP 旨在解决这一问题。
核心方法: MemeCLIP
这项研究的核心是 MemeCLIP , 这是一个旨在有效分类这些复杂多模态输入的框架。
研究人员在 CLIP (Contrastive Language-Image Pre-Training,对比语言-图像预训练) 之上构建了他们的解决方案。CLIP 是一个在大规模图文对 (4 亿对) 上训练的基础模型。它擅长理解视觉概念与语言之间的一般关系。然而,直接使用 CLIP 进行 Meme 分类存在隐患:
- 过拟合 (Overfitting): 在小数据集 (如 PrideMM) 上微调像 CLIP 这样的大型模型通常会破坏其通用知识 (灾难性遗忘) 。
- 纠缠 (Entanglement): CLIP 训练用于匹配图像和描述性文本 (例如,一张狗的照片配上文字“一只狗”) 。然而,Meme 往往依赖于不匹配或反讽,即文字和图像相互矛盾以产生意义。
MemeCLIP 使用轻量级、模块化的架构解决了这些问题。
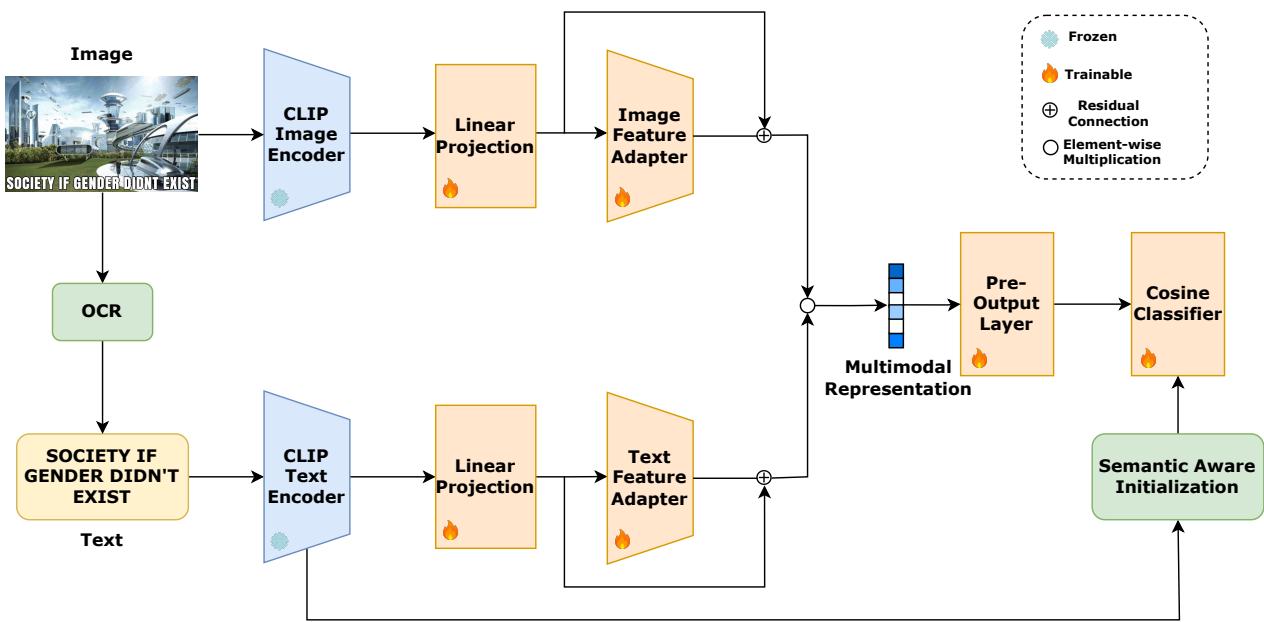
让我们一步步分解图 2 中展示的架构。
1. 冻结的编码器 (Frozen Encoders)
该过程始于标准的 CLIP 图像 (\(E_I\)) 和文本 (\(E_T\)) 编码器。至关重要的是,作者冻结了这些权重。这确保了 CLIP 从互联网上学到的丰富通用知识得以保留,而不会在训练期间被覆盖。
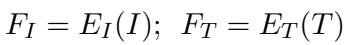
这里,\(F_I\) 和 \(F_T\) 分别代表从图像和文本中提取的原始特征嵌入。
2. 线性投影层 (Linear Projection Layers)
由于 Meme 使用文字和图像的方式往往具有对比性 (不同于 CLIP 训练时使用的标准描述数据) ,原始嵌入可能结合得过于紧密。研究人员引入了线性投影层,以在嵌入空间内“解纠缠”这些模态。
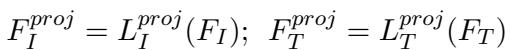
这一步将特征映射到一个空间,使模型能更好地分析 Meme 的文本和视觉组件之间特定的相互作用。
3. 带残差连接的特征适配器 (Feature Adapters with Residual Connections)
这是该框架最具创新性的部分。MemeCLIP 没有微调整个模型,而是在投影层之后插入了特征适配器 (Feature Adapters) 。 这些是轻量级的、可训练的模块。
为了兼顾两全其美——即冻结的 CLIP 的通用知识和 Meme 文化的特定知识——该框架使用了残差连接 。
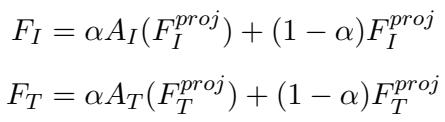
在这些公式中,\(\alpha\) 是一个“残差比率” (实验中设为 0.2) 。这个参数平衡了输入: 它从新学习到的适配器 (\(A_I\)) 中获取少量信息,并将其与大部分原始投影特征相结合。这项技术深受参数高效微调最新进展的启发,在防止过拟合的同时允许模型适应数据集的特定细微差别。
4. 模态融合 (Modality Fusion)
一旦图像和文本特征完成适配,就需要将它们结合起来。作者选择了一种简单而有效的方法: 逐元素乘法 。
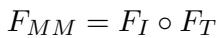
这产生了一个单一的向量 \(F_{MM}\),它封装了 Meme 的综合语义含义。
5. 余弦分类器与语义感知初始化
最后,融合后的表示需要被分类。标准的线性分类器可能会偏向多数类 (这是 PrideMM “目标”任务中的一个主要问题) 。为了缓解这个问题,MemeCLIP 使用了 余弦分类器 (Cosine Classifier) 。
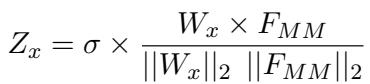
通过归一化权重 (\(W_x\)) 和特征 (\(F_{MM}\)),预测取决于向量之间的角度而不是它们的大小。这使得模型对类别不平衡更具鲁棒性。
此外,分类器权重的初始化并不是随机的。作者采用了 语义感知初始化 (Semantic-Aware Initialization, SAI) 。 他们使用文本编码器为类别标签本身 (例如,“一张仇恨言论的照片”) 生成嵌入,并使用这些嵌入来初始化分类器。这通过在训练开始前注入标签的语义理解,给了模型一个“先发优势”。
实验与结果
研究人员将 MemeCLIP 与多个基线进行了比较,包括单模态模型 (仅文本的 BERT,仅图像的 ViT) 和其他多模态框架 (如 MOMENTA 和 HateCLIPper) 。
在 PrideMM 上的表现
在新的 PrideMM 数据集上的结果令人信服。
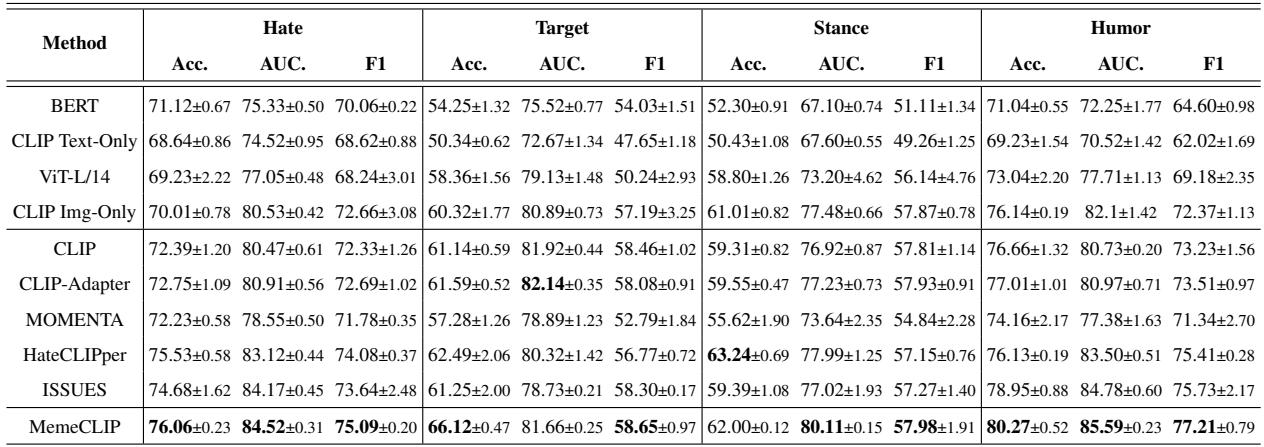
如表 3 所示, MemeCLIP 在仇恨、目标和幽默分类的所有指标上几乎都取得了最佳性能 。
- 目标分类: 注意与其他方法相比,“目标”任务在性能 (F1 分数) 上的显著提升。这验证了余弦分类器在处理不平衡类别方面的有效性。
- 单模态 vs. 多模态: 该表还证实,仅文本或仅图像的模型通常表现较差,证明理解 Meme 需要同时查看两种模态。
对 HarMeme 的泛化能力
为了证明 MemeCLIP 不仅仅擅长 LGBTQ+ Meme,作者在 HarMeme (一个与 COVID-19 仇恨言论相关的数据集) 上进行了测试。
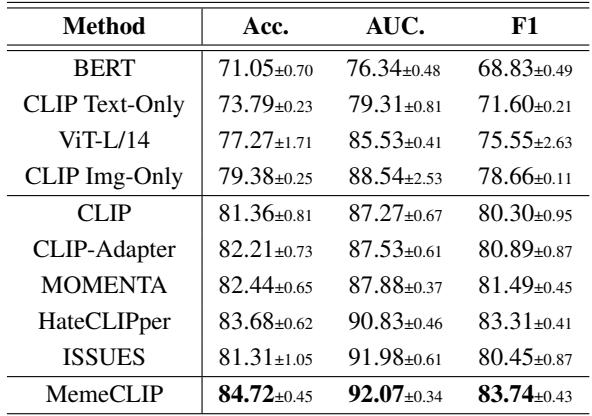
表 4 显示 MemeCLIP 具有良好的泛化能力,优于 HateCLIPper 和 ISSUES 等最先进的基线模型。这表明该架构在不同主题的仇恨言论中都是稳健的。
消融实验: 我们需要所有组件吗?
机器学习中的一个常见问题是是否每个组件都是必要的。作者进行了消融研究来找出答案。
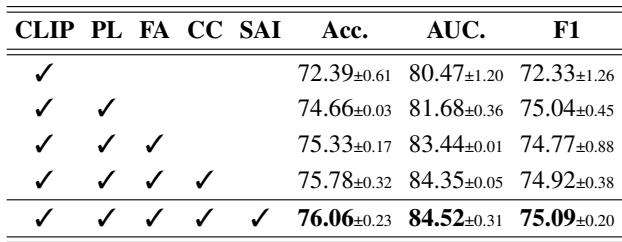
表 5 展示了一个清晰的进展过程。
- 第 1 行: 仅使用带有投影层的 CLIP 得到的基线准确率为 72.39%。
- 第 2 行: 添加特征适配器将其显著提升至 74.66%。
- 第 3 & 4 行: 添加余弦分类器和语义感知初始化提供了最终的推动力,达到 76.06%。 每个组件都为模型的最终成功做出了贡献。
MemeCLIP vs. GPT-4
在大型语言模型主导的时代,一个专门的模型如何与像 GPT-4 这样的巨头抗衡?研究人员使用 GPT-4 进行了零样本 (zero-shot) 比较。
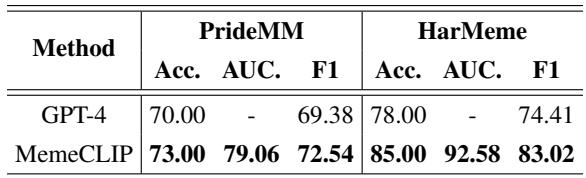
表 6 揭示了一个有趣的发现: MemeCLIP 优于 GPT-4。 定性分析表明,GPT-4 往往“过于安全”。由于其安全对齐 (RLHF) ,GPT-4 倾向于过度审查,将非仇恨但有争议的图像归类为仇恨言论。MemeCLIP 由于在特定领域进行了微调,能更好地理解细微差别,产生的误报更少。
哪里失败了?
没有模型是完美的。作者展示了误分类样本,以帮助理解仍然存在的挑战。

图 3 展示了任务的难度。
- 示例 (a): 一个描绘“跨性别者 (trans ppl)”和“吸血鬼 (vampires)”手臂连接在一起的 Meme。MemeCLIP 预测为“无仇恨”(0),但真实标签是“仇恨”(1)。模型可能忽略了文字“避免照镜子 (avoiding mirrors)”所隐含的微妙贬义关联,将“握手 Meme”模板解读为本质上是积极的。
- 示例 (b): 这张图片被正确识别为仇恨,但目标被错误分类。模型预测目标是一个社区 (可能是由于“trans”和“women”这些词) ,但真实标签是针对个人。
结论与启示
MemeCLIP 论文为多模态机器学习领域做出了两个实质性的贡献。
首先, PrideMM 数据集为理解关于 LGBTQ+ 社区的在线讨论的复杂性提供了急需的资源。通过超越二元标签并纳入立场和幽默,它允许开发更具文化感知能力且不太容易进行全面审查的 AI。
其次, MemeCLIP 框架表明,我们并不总是需要巨大的计算能力才能达到最先进的结果。通过使用特征适配器和余弦分类器等轻量级模块策略性地调整冻结的基础模型 (CLIP) ,作者创建了一个高效的模型,其性能优于更大的竞争对手。
对于机器学习的学生来说,这篇论文是 参数高效迁移学习 的一堂大师课。它表明,只要架构得当,你就可以调整通用模型来解决高度特定、微妙且具有重要社会意义的问题。随着互联网的不断发展,像 MemeCLIP 这样的工具对于在自由表达、幽默和有害内容之间的微妙界限中进行导航将至关重要。