](https://deep-paper.org/en/paper/2409.14705/images/cover.png)
引言
在大型语言模型 (LLM) 预训练领域,主流理念在很大程度上是“越多越好”。像 GPT-4 和 Llama-3 这样的模型是在数万亿个 Token 上训练出来的,这些数据源自对互联网的大规模、不加区分的抓取。虽然这产生了令人印象深刻的通用能力,但也极其昂贵且计算效率低下。
但是,如果你不需要一个无所不知的模型呢?如果你需要一个在特定领域 (如生物医学研究或法律推理) 表现出色,而无需花费数百万美元在不相关的网络抓取数据上进行训练的模型呢?
这就引出了数据选择 (Data Selection) 的概念。其目标是识别出对你的特定目标任务最有价值的训练数据子集。然而,现有的方法面临一个两难困境: 它们要么过于简单 (如关键词匹配) 并引入严重的偏差,要么过于复杂 (需要另一个神经网络来选择数据) ,从而在计算上变得不可行。
在论文 Target-Aware Language Modeling via Granular Data Sampling 中,来自 Meta AI、弗吉尼亚理工大学和爱荷华州立大学的研究人员提出了一种新颖的解决方案。他们重新审视了一种经典的统计技术——重要性采样 (Importance Sampling) ——并利用多粒度标记化 (Multi-Granular Tokenization) 对其进行了增强。通过同时在子词、整词和多词短语的层面上分析文本,他们证明了我们只需使用约 1% 的原始数据进行训练,就能达到与使用完整数据集训练的模型相匹配的性能。
背景: 核心集选择的需求
要理解这篇论文的贡献,首先需要定义核心集选择 (Coreset Selection) 。 在机器学习的语境下,“核心集”是原始数据集的一个小的、加权的子集。其理念是,如果你在这个核心集上训练模型,应该能产生一个与在整个数据集上训练的模型非常接近的近似模型。
选择这个子集通常涉及比较两个分布:
- 原始分布 (\(q\)): 海量的、未经过滤的数据池 (例如 RefinedWeb, CommonCrawl) 。
- 目标分布 (\(p\)): 代表你实际希望模型学习内容的较小、高质量的数据集 (例如特定推理任务或特定领域的文本) 。
重要性采样方法
一种统计上合理的数据选择方法是重要性采样 。 我们为原始数据集中的每个文档分配一个权重 (\(w_i\))。这个权重代表了该文档对我们的目标任务有多“重要”。从数学上讲,这是在该文档在目标分布中出现的概率与在原始分布中出现的概率之比:
\[w_i = \frac{p(z_i)}{q(z_i)}\]如果一个文档看起来与我们的目标非常相似 (\(p\) 很高) ,但在原始数据中很罕见 (\(q\) 很低) ,它就会获得高权重。
问题在于我们如何表示一个“文档” (\(z_i\))。如果我们简单地使用词袋模型 (计算词频) ,就会丢失上下文。如果我们使用复杂的神经嵌入,选择过程就会变得太慢。这篇论文认为,秘诀在于我们在计算这些权重之前如何对文本进行标记化 (Tokenize) 。
核心方法: 多粒度标记化
研究人员引入了一个流程,融合了 n-gram 特征的高效性与可变长度 Token 的语义丰富性。这个过程允许他们选择在语义上与目标对齐的数据,而不会过度拟合或丧失通用的语言能力。
如图 1 所示,该过程包含三个不同的步骤: 特征化、哈希和采样。
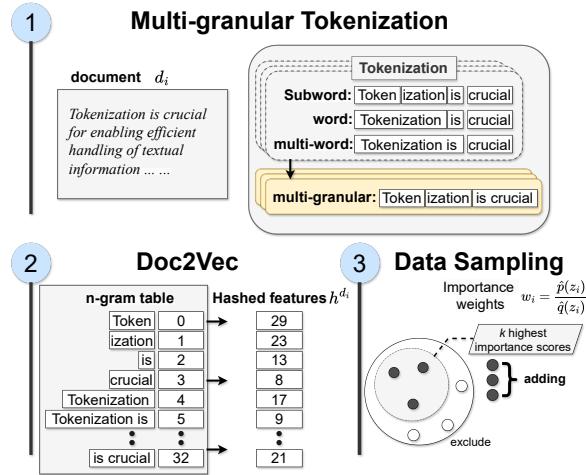
1. 多粒度特征化
标准分词器通常将文本分解为子词 (Subwords) (例如 “Token”, “iz”, “ation”) 。这对于词表的效率很有好处,但往往会割裂语义。相反,只看整词可能会遗漏形态学的细微差别。
作者提出了使用多粒度 Token 。 对于像 “Tokenization is crucial…” 这样的句子,系统同时生成三种类型的特征:
- 子词级别: “Tok”, “en”, “iz”, “ation”
- 整词级别: “Tokenization”, “is”, “crucial”
- 多词级别: “Tokenization is crucial” (短语级别)
通过捕获所有三个级别,模型保留了粗粒度 Token (单词) 中的一般信息,同时捕获了细粒度 Token (子词和短语) 中的特定领域知识。
2. 分词器适配与词表优化
研究人员如何决定包含哪些子词或短语?他们不仅仅使用标准的分词器。他们执行了分词器适配 (Tokenizer Adaptation) 。
他们从一个标准词表 (例如 Llama-3 的分词器) 开始,并将其与从目标任务数据中专门学习到的词表合并。然而,简单地将两个词表拼凑在一起会产生冗余。为了解决这个问题,他们通过最小化熵差来优化词表。
他们利用了一个词表效用度量 \(\mathcal{H}_{v}\),定义如下:
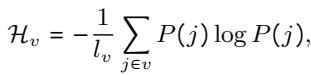
这里,\(P(j)\) 是 Token 的相对频率。目标是找到一个词表集合 \(v(t)\),使其与上一步相比熵的变化最小化,从而有效地找到表示目标文本的最优方式:
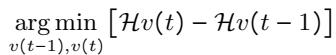
这种优化确保了用于采样的特征在统计上能够代表目标领域。
3. 哈希与重要性加权
一旦文档被标记化为这种多粒度的混合形式,就需要将其转换为数学格式。作者使用哈希 (Hashing) 将这些 n-gram 映射为固定大小的向量。
然后计算重要性权重 \(w_i\)。如果海量原始数据集中的一个文档包含高密度的、在目标数据集中发现的特定多粒度 Token,它就会获得高分。最后,他们根据这些权重采样前 \(k\) 个文档,以形成训练核心集。
为什么粒度很重要: 偏差-方差权衡
你可能会问: 为什么要费力混合子词、单词和短语?为什么不直接使用短语?
作者发现,依赖单一粒度会引入偏差。
- 仅子词: 过于碎片化;模型会丢失语义上的“大局观”。
- 仅短语: 过于具体;采样可能会过拟合目标数据中的特定句子,而忽略了主题相关但措辞不同的文档。
通过混合不同粒度,他们降低了所选数据与目标数据之间的 KL 散度 (KL Divergence) (一种衡量两个概率分布差异的指标) 。
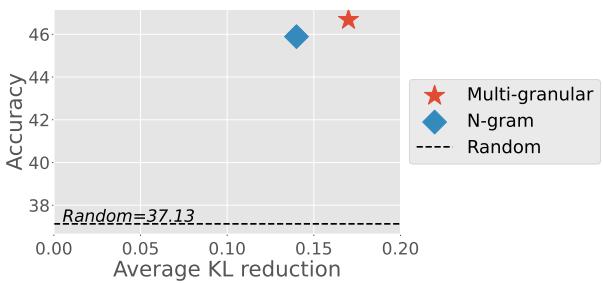
图 2 直观地展示了这种相关性。X 轴显示了 KL 散度的缩减 (与目标对齐得更好) ,Y 轴显示了 HellaSwag 基准测试的准确率。红星 (多粒度) 位于右上角,表明该方法实现了与目标分布的最佳对齐,并因此获得了最高的下游任务准确率。
实验结果
研究人员通过训练参数量从 1.25 亿到 15 亿 不等的仅解码器 Transformer 模型验证了他们的方法。他们使用海量的 RefinedWeb 数据集作为原始来源,并根据八个常识推理任务 (如 ARC, PIQA 和 HellaSwag) 选择了大约 1% 的数据 (约 7 亿个 Token) 。
性能比较
结果总结在表 1 中,令人信服。
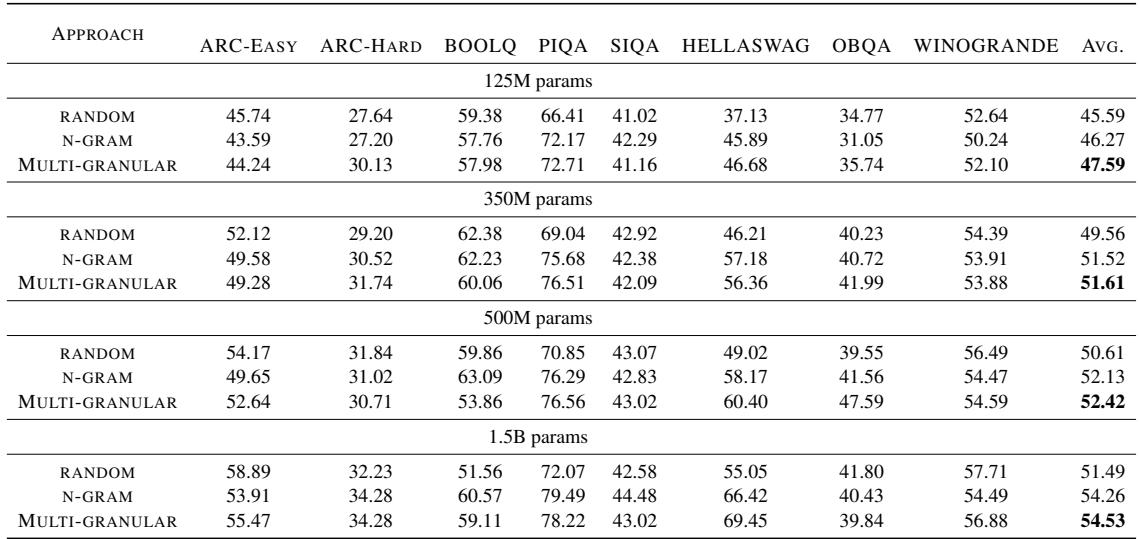
从这个表格中可以得出两个关键结论:
- 持续的优势: 几乎在所有模型尺寸上, 多粒度 (Multi-Granular) 方法都优于随机采样 (Random) 和标准的 N-gram 采样。
- 扩展效率: 即使在 15 亿参数下,多粒度模型 (仅在 1% 的数据上训练) 的平均得分也达到了 54.53 , 明显高于随机基线的 51.49。
涌现能力
LLM 的一个迷人之处在于“涌现”——随着模型变大而突然出现的能力。 图 3 追踪了在所有模型尺寸上计算出的八个任务的平均零样本性能。
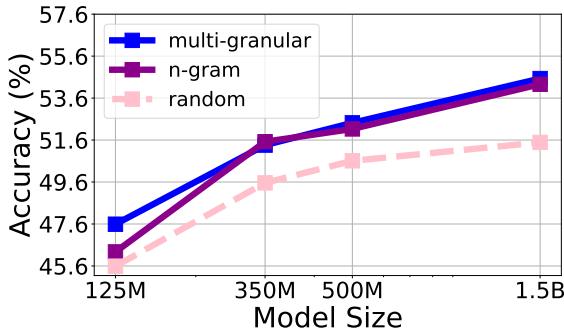
注意趋势线。多粒度线 (顶部) 始终领先。有趣的是,在 3.5 亿参数标记附近有一个急剧的提升,这表明随着模型获得足够的容量来利用这些数据,高质量数据选择的好处变得更加明显。
对抗领域偏差的鲁棒性
目标导向的数据选择的一个主要风险是“灾难性遗忘”或“隧道视野”。如果你主要基于科学论文选择数据,模型可能会忘记如何进行随意的聊天。
作者通过基于单个目标任务 (例如 ARC-Easy) 选择数据,然后测试模型在所有任务上的表现来测试这一点。
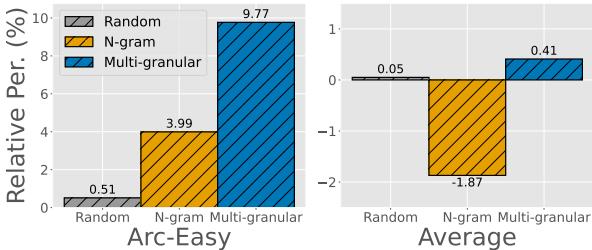
图 4 显示了相对性能。 多粒度方法 (蓝色柱状图) 在目标任务 (ARC-Easy) 上显示出相对于基线的巨大相对提升。关键是,看右侧的“平均 (Average) ”图表,它在整体上也保持了正向的性能增益。这表明多粒度特征捕获了足够的通用语言结构,防止模型在非目标任务上变得毫无用处。
其他数据集上的额外实验进一步支持了这种鲁棒性。例如, 图 5 显示了当使用 HellaSwag、OBQA 或 WinoGrande 作为目标时,同样的模式依然存在。
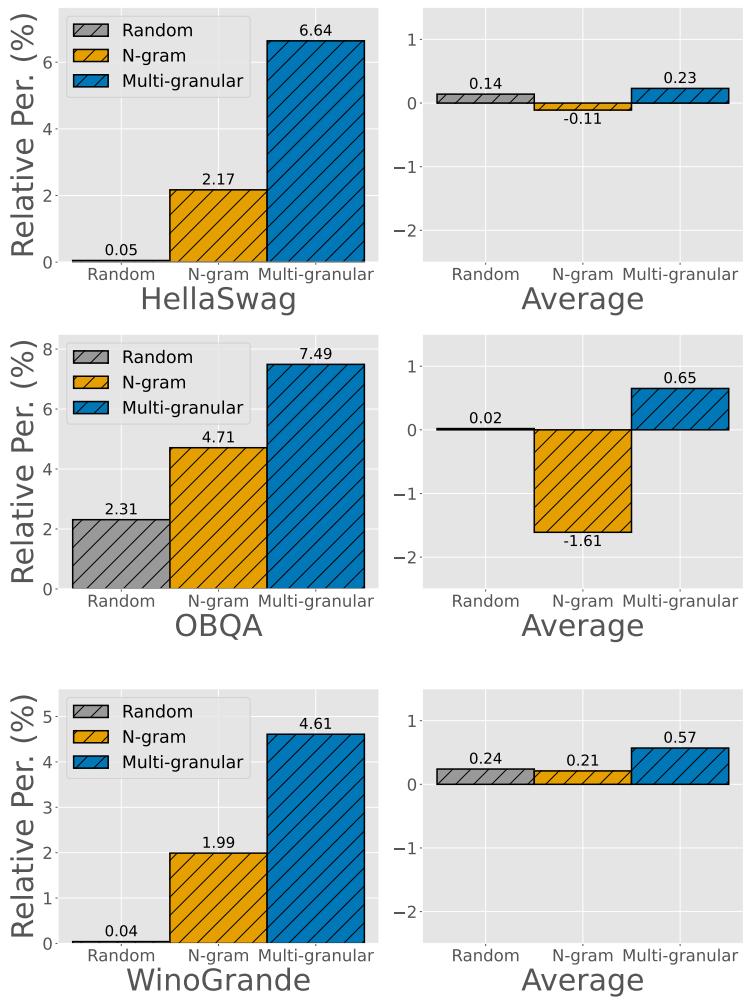
在每种情况下,多粒度选择 (蓝色) 都产生了最高的相对性能增益,证明该方法并非特定于某个数据集的侥幸。
结论
Target-Aware Language Modeling via Granular Data Sampling 中提出的研究为高效的 LLM 训练提供了一条切实的道路。通过超越简单的词频统计并采用多粒度标记化 , 我们可以构建出既包含丰富相关信息又足够广泛以支持通用推理的“核心集”。
对于学生和从业者来说,启示是明确的:
- 数据 > 算力: 你并不总是需要更多的 GPU;有时你只需要更好的数据选择算法。
- 粒度很重要: 你如何表示文本特征 (子词 vs. 短语) 从根本上改变了采样算法“看到”和选择的内容。
- 效率是可实现的: 在 1% 的数据上训练出具有竞争力的模型不仅是理论上的——通过正确的统计采样技术,这是完全可以实现的。
随着我们要迈向专用模型和资源受限环境的时代,像多粒度重要性采样这样的技术很可能会成为 NLP 工程师工具箱中的标准工具。