](https://deep-paper.org/en/paper/2409.14907/images/cover.png)
引言
心理健康咨询是一个字斟句酌的领域。在典型的咨询过程中,治疗师必须平衡两项关键任务: 积极倾听客户以建立治疗关系,以及一丝不苟地记录会话以备将来参考。这种文档通常被称为“咨询笔记”或摘要,对于跟踪进展和确保持续护理至关重要。然而,做笔记的认知负荷可能会分散治疗师的注意力,从而可能削弱与客户的联系。
这种场景为人工智能提供了一个绝佳的用例。如果人工智能能够聆听会话并自动生成精确、临床相关的摘要,治疗师就可以全神贯注于他们的客户。然而,尽管像 GPT-4 或 Llama-2 这样的大型语言模型 (LLMs) 呈爆炸式增长,它们在这个特定领域仍然面临巨大挑战。通用型 LLM 经常会产生事实幻觉,遗漏微妙的临床线索,或者无法按照专业人员使用的方式构建笔记。
差距在于规划。人类专家不仅仅是转录;他们会过滤信息,将其与医学知识结合,并进行逻辑结构化。为了弥合这一差距,研究人员推出了 PIECE (Planning Engine for Counseling Note Generation,用于咨询笔记生成的规划引擎) 。这个新框架强制 LLM 在生成任何一个字之前,利用领域特定知识和结构知识“规划”其输出。
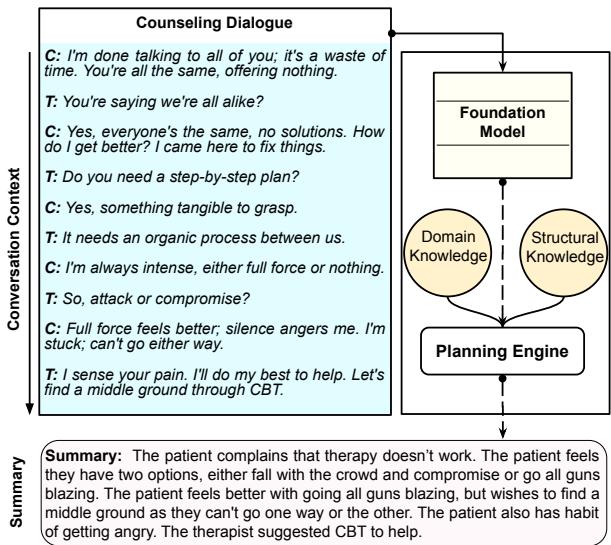
如上图所示,PIECE 不是一个直接的输入到输出过程,而是插入了一个规划阶段,将患者的主诉和治疗技术组织成一个结构化的摘要。
挑战: 为什么标准 LLM 在咨询中表现不佳
要理解为什么需要专门的系统,必须看看标准 LLM 是如何运作的。大多数基础模型都是在海量的通用互联网文本上训练的。当被要求总结一次治疗会话时,它们可能会生成读起来通顺但缺乏临床有效性的文本。
主要有两个障碍:
- 领域知识: 心理健康讨论涉及特定的术语 (例如,根据 PHQ-9 标准区分“情绪低落”和“临床抑郁”) 。标准 LLM 对所有文本的处理权重不仅大致相同,往往保留了“填充性”对话,却遗漏了关键症状。
- 结构细微差别: 咨询会话是一种具有特定流程的对话——介绍性寒暄、症状发现、反思和干预。平铺直叙的总结往往会丢失这种对话的“几何结构”或方向性流程。
研究人员认为,要生成高质量的咨询笔记,我们不能仅仅依靠 LLM 的生成能力。我们需要一个“规划引擎”,充当复杂的过滤器和架构师,指导 LLM 该说什么以及如何组织它。
PIECE 架构
PIECE 框架建立在一个基础模型之上 (具体来说是 MentalLlama,一个针对心理健康微调过的 Llama-2 版本) ,但它增加了一个新颖的双流规划引擎来增强模型。
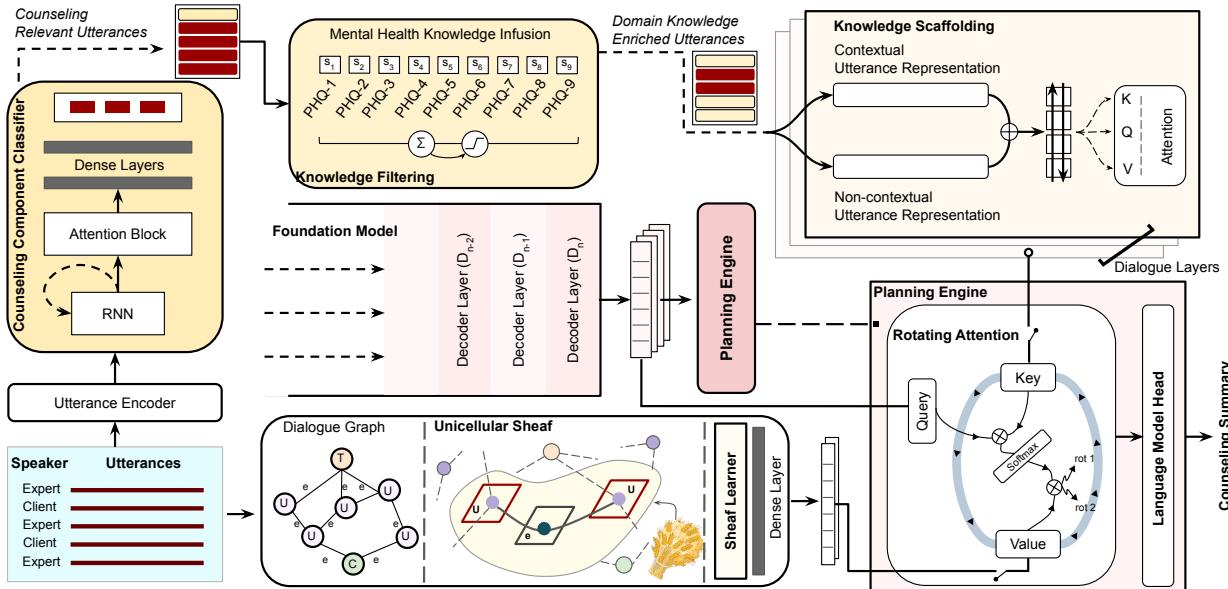
如架构图所示,在最终生成之前,系统通过两个不同的路径处理输入对话:
- 领域知识封装 (左流) : 基于医学相关性过滤并丰富内容。
- 结构知识封装 (右流) : 使用图论 (特别是层学习 Sheaf Learning) 分析对话的数学结构。
这两条流在规划引擎中汇合,融合这些见解并将其输入到语言模型头 (Language Model Head) 以进行最终输出。让我们分解这些组件。
1. 领域知识封装
该模块确保摘要包含临床相关信息并丢弃噪音。它分两步操作: 过滤和支架 (Scaffolding) 。
知识过滤: 现实世界的对话是混乱的。它充满了“嗯”、“啊”和无关的闲聊 (“讨论填充物”) 。系统首先使用一个咨询组件分类器 (基于 GRU-RNN) 来标记每一句话。它识别一句话是关于症状 (SH) 、患者发现 (PD) 还是反思 (RT) 。无关的填充词会被屏蔽掉。
此外,系统将话语与 PHQ-9 词典 (一种诊断抑郁症严重程度的标准工具) 进行交叉引用。如果一句话与 PHQ-9 术语具有高度相似性,它将被标记为高优先级领域知识。
知识支架: 仅仅过滤是不够的;模型需要理解这些医学术语的上下文。研究人员使用了一种支架技术,结合了上下文嵌入 (来自 BERT) 和非上下文嵌入 (来自 GloVe) 。这些嵌入通过一个 Bi-LSTM 处理,以创建医学事实的丰富表示。
这种支架的注意力机制在数学上定义为:
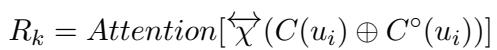
在这个公式中,\(C(u_i)\) 代表上下文 BERT 嵌入,而 \(C^\circ(u_i)\) 代表非上下文 GloVe 嵌入。通过连接 (\(\oplus\)) 这些并通过注意力机制传递它们,系统创建了一个包含丰富领域特定含义的表示 (\(R_k\)) 。
2. 通过层学习 (Sheaf Learning) 进行结构知识封装
这可能是论文中数学上最具创新性的部分。标准的图神经网络 (GNN) 可以通过将话语视为节点并将其序列视为边来对对话进行建模。然而,标准图难以捕捉对话复杂的“几何结构”——即意义如何相对于参与者发生转变和演变。
为了解决这个问题,研究人员采用了层论 (Sheaf Theory) 。 在拓扑学中,“层 (Sheaf) ”允许你将数据 (向量空间) 以保留局部几何结构的方式关联到图的节点和边上。它使模型不仅能理解话语 A 跟随话语 B,还能理解两者之间信息空间是如何转换的。
系统构建了一个对话图,其中话语是节点。然后它应用一个层卷积网络 (SCN) 来学习结构表示 (\(R_{scn}\)) 。
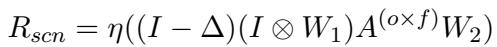
这里,\(\Delta\) 是层拉普拉斯算子 (表示图几何结构的矩阵) ,\((I \otimes W_1)\) 代表可学习的权重。这个方程本质上是在图上扩散信息,允许模型学习对话的“形状”。输出是一组编码了治疗会话结构流的表示。
3. 规划引擎: 旋转注意力
现在系统拥有两种不同类型的“知识”:
- \(R_k\): 医学事实 (领域知识) 。
- \(R_s\): 对话流程 (结构知识) 。
规划引擎必须使用旋转 (循环) 注意力机制将这些与基础模型自身的理解融合在一起。
Transformer 中的标准注意力机制使用查询 (Q) 、键 (K) 和值 (V) 。通常,这些都来自同一个源。在 PIECE 中,“查询”来自基础模型 (LLM 的当前状态) ,但键和值在领域表示和结构表示之间循环交换。
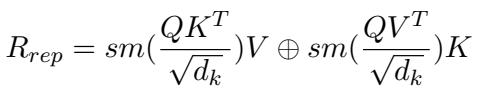
如公式所述,模型每个循环计算两次注意力。在一次通过中,结构知识可能充当键/值。在下一次中,领域知识扮演该角色。结果被连接起来 (\(\oplus\)) 。这迫使 LLM 同等关注所说的内容 (医学事实) 以及它如何融入故事 (结构) ,防止生成的内变成不连贯的症状列表或流畅但空洞的段落。
实验结果
研究人员使用 MEMO 数据集评估了 PIECE,该数据集包含咨询会话的记录和专家撰写的摘要。他们将 PIECE 与 14 个基准模型进行了比较,从标准的序列到序列模型 (如 BART 和 T5) 到现代 LLM (Llama-2, Mistral, Zephyr) 。
定量表现
使用的主要指标是 ROUGE (测量与“金标准”人工摘要的文本重叠) 和 BLEURT (一种判断语义含义的学习指标) 。
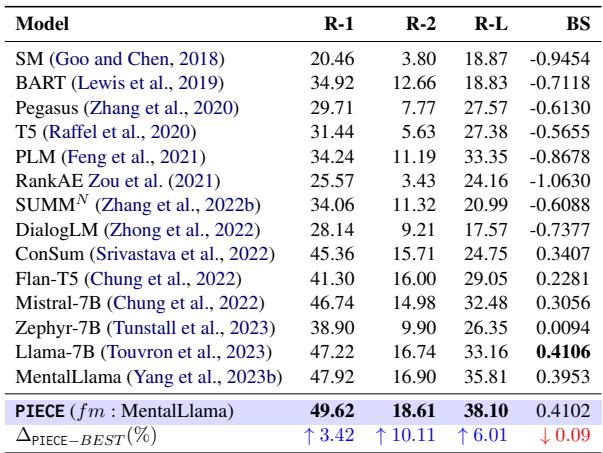
表 1 中的结果令人信服。PIECE (使用 MentalLlama 作为基础) 优于所有基准。
- ROUGE-2: 比最佳基准提高了 10.11% 。 ROUGE-2 测量二元组重叠,表明 PIECE 更擅长捕捉人类专家使用的特定短语和概念。
- ROUGE-L: 提高了 6.01% 。 这测量最长公共子序列,表明更好的句子结构连贯性。
值得注意的是,虽然 Llama-7B 在单独的 BLEURT 分数上略高,但 PIECE 在 ROUGE 上的巨大收益表明它更忠实于医学摘要的具体内容要求。
为什么规划很重要? (消融实验)
为了证明这种复杂的架构实际上是必要的,研究人员进行了消融实验,移除了系统的部分组件以观察性能下降情况。
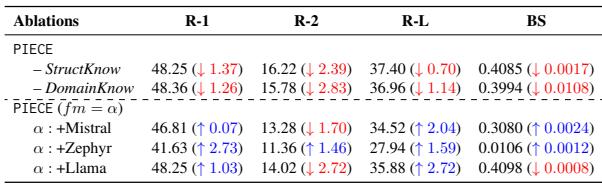
表 2 揭示了两个关键见解:
- 移除知识会有害: 当移除领域知识模块 (只留下结构和基础模型) 时,性能显着下降 (R-2 下降了 2.83 分) 。
- 泛化能力: 研究人员将 PIECE 规划引擎应用于其他 LLM (Mistral, Zephyr, Llama) 。几乎在所有情况下,添加规划引擎都提高了基础模型的性能。这表明“规划”概念是通用的,而不仅仅是特定模型的一个特例。
捕捉心理健康信息
像 ROUGE 这样的通用指标并不能说明全部情况。一个摘要可能在语法上很完美,但却遗漏了患者有自杀倾向的事实。研究人员使用了一种称为 心理健康信息捕获 (MHIC) 的领域特定指标,该指标衡量摘要捕捉特定咨询组件 (如症状或患者发现) 的程度。
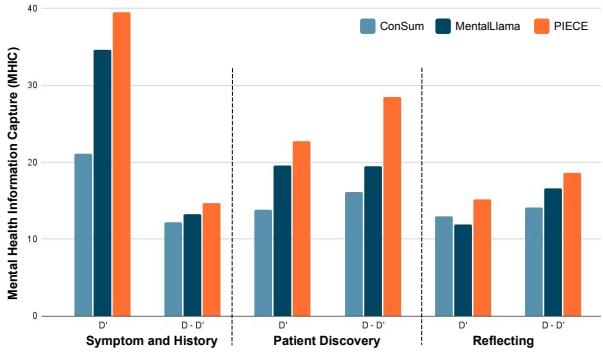
图 3 显示了鲜明的对比。与 MentalLlama (深蓝色) 和 ConSum (浅蓝色) 相比,橙色条 (PIECE) 在所有类别中始终达到更高的 MHIC 分数。这证实了“过滤和支架”阶段成功地迫使模型保留了关键的临床细节。
专家人工评估
在临床 AI 中,自动化指标是不够的。一个由临床心理学家和语言学家组成的小组对摘要进行了评估。
语言质量: 评估者对相关性、一致性、流畅性和连贯性进行了评分。
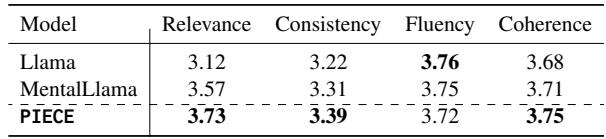
PIECE 在相关性方面获得了最高分 (3.73) ,证实规划引擎成功地优先考虑了正确的信息。它在连贯性方面也持平或击败了基准,这可能归功于基于层的结构学习。
临床可接受性: 一位拥有超过 10 年经验的临床心理学家使用临床可接受性框架评估了摘要。

专家评估 (表 5) 非常积极。在“感知有效性”方面,该模型得分很高,专家指出在 56.3% 的案例中,PIECE 优于具有竞争力的 MentalLlama 模型。至关重要的是,专家发现 75% 的实例中幻觉“可以忽略不计”,这对于医疗保健 AI 的安全性来说是一个巨大的胜利。
结论与未来影响
PIECE 框架展示了我们如何处理特定领域的大型语言模型的关键转变。这项研究强调了推理时规划的力量,而不是简单地把模型做得更大或在更多文本上进行训练。
通过明确地将“理解医学事实” (领域知识) 和“理解对话流程” (结构知识) 的任务分开,然后通过规划引擎将它们融合,PIECE 生成的咨询摘要不仅流畅,而且具有临床实用性。
关键要点:
- 先规划后写作: 注入规划阶段允许 LLM 更好地处理复杂的、非结构化的对话。
- 结构至关重要: 对话几何结构的数学建模 (层学习) 提高了生成文本的连贯性。
- 安全第一: 这种方法显著减少了幻觉,使其成为心理健康护理辅助工具的可行候选者。
虽然作者强调这是一个针对临床医生的辅助工具——而不是替代品——但它代表了向能够可靠处理人类心理健康细微差别和敏感性的 AI 系统迈出的重要一步。