](https://deep-paper.org/en/paper/2409.19723/images/cover.png)
想象你在参加一个晚宴。你遇到了一位新朋友,不到十分钟,你就在心里想: “这人非常外向。”
但你为什么会这么认为?
是因为他们说话声音大吗?是因为他们主动发起话题吗?还是因为他们在讲故事时热情地挥舞着双手?作为人类,我们不仅仅是给人贴标签;我们会潜意识地收集证据,分析特定时刻的行为,并随着时间的推移寻找模式,从而形成对某人性格的印象。
多年来,人工智能一直试图通过自动人格识别 (Automatic Personality Recognition, APR) 来复制这一过程。然而,大多数现有模型就像一个“黑盒”。你输入用户的社交媒体帖子或对话记录,模型吐出一个标签: 神经质: 高 (Neuroticism: High)。
但它不会告诉你原因。
缺乏可解释性是一个重大障碍。如果 AI 帮助招聘人员筛选候选人或辅助心理学家进行诊断,仅仅给出“相信我,我是一个算法”这样的解释是不够的。
在一篇引人入胜的新论文 《Revealing Personality Traits: A New Benchmark Dataset for Explainable Personality Recognition on Dialogues》 中,研究人员孙雷、赵金明和金琴提出了一种改变该领域研究方法的新思路。他们引入了一个框架,不仅能猜测你的人格类型,还能解释背后的推理过程,即从具体的行为到暂时的状态,最后推导出的长期特质。
在这篇深度文章中,我们将探讨他们的新颖框架、为此构建的海量数据集,以及他们的实验揭示了现代大型语言模型 (LLM) 的哪些能力。
“为什么”背后的心理学
为了理解研究人员的贡献,我们需要先快速回顾一下支撑他们工作的心理学理论: 大五人格模型 (Big Five Personality Model) (通常简称为 OCEAN) 。
- 开放性 (Openness): 好奇心,对艺术、情感、冒险的欣赏。
- 尽责性 (Conscientiousness): 自律,追求成就,尽职尽责。
- 外向性 (Extraversion): 精力充沛,积极情绪,急切,自信。
- 宜人性 (Agreeableness): 富有同情心和合作精神,而不是多疑和对抗。
- 神经质 (Neuroticism): 容易体验到不愉快情绪 (如愤怒、焦虑、抑郁或脆弱) 的倾向。
特质 (Traits) vs. 状态 (States)
这篇论文利用的一个关键洞察是人格特质 (Personality Trait) 与人格状态 (Personality State) 之间的区别。
- 特质是持久的模式。它们是对你是谁的“长期”定义。
- 状态是短期的。它们是在特定时刻下的思想、感觉和行为的特征模式。
一个内向的人 (特质) 如果试图建立人脉,可能会在聚会上表现出外向的行为 (状态) 。一个通常冷静的人 (特质) 在危机中可能会表现出高度焦虑 (状态) 。
作者认为,为了准确识别并解释一个人格特质,AI 必须首先识别这些短期状态及其支持证据,然后汇总这些信息以确定稳定的特质。
核心方法: 人格证据链 (CoPE)
目前的研究通常将人格识别视为一个简单的分类任务: 输入文本 \(\rightarrow\) 输出标签。作者认为这跳过了推理过程。
他们提出了一个名为人格证据链 (Chain-of-Personality-Evidence, CoPE) 的新框架。这个框架模仿了人类观察细节并向上推理得出结论的认知过程。
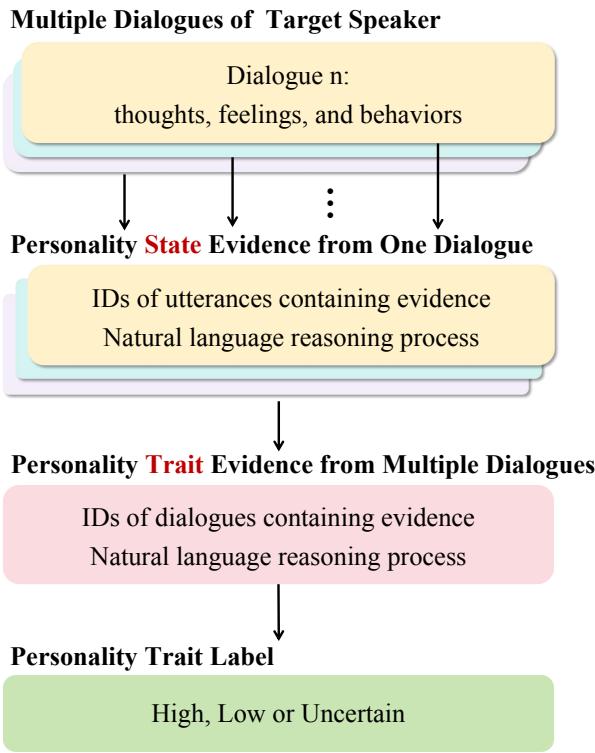
如图 1 所示,CoPE 框架在一个层级结构上运作:
- 输入: 过程始于目标说话人的多轮对话 。 人格不会在单一句子中显露;它需要跨越时间的上下文。
- 状态证据: 对于每一个单独的对话,系统识别出作为证据的特定话语 ID (Utterance IDs) (句子) 。它使用自然语言推理来推断该特定情境下的人格状态 。
- 特质证据: 系统不会停留在状态层面。它汇总来自多个对话的证据。它观察状态的模式以形成人格特质证据 。
- 输出: 最后,基于积累的证据,它分配一个人格特质标签 (高、低或不确定) 。
这种“链条”确保了最终的预测是基于特定时刻的。如果模型说某位说话人的“尽责性高”,它可以指向特定的对话,指出该说话人在哪里制定计划、反复检查工作或提前到达,并解释这些瞬间状态如何促成整体特质。
构建 PersonalityEvd 数据集
为了在这个新框架上训练模型,研究人员需要数据。你不能直接从互联网上下载“带解释的人格数据”;他们必须自己构建。他们利用中国电视剧对话 (具体是 CPED 语料库) 创建了 PersonalityEvd 数据集。
为什么要用电视剧?剧本角色的性格通常一致且特征鲜明,旨在让人易于识别,这使他们成为训练模型识别人格标记的绝佳对象。
标注过程
PersonalityEvd 的创建是一项巨大的工程,涉及“人机协同 (human-in-the-loop)”的过程。
- 源材料: 他们选择了 72 位说话人,并分析了每位说话人大约 30 个对话。
- 推理标注: 他们不仅想要标签;他们想要推理过程。他们使用 BFI-2 量表 (一种标准的心理问卷) 作为指导。
- GPT-4 辅助: 为了处理工作量,他们首先使用 GPT-4 生成预标注。GPT-4 分析对话以预测状态并起草推理证据。
- 人工修正: 这是关键的质量控制步骤。心理学专业的学生审查 AI 的工作,纠正错误,完善证据,并确保推理是合理的。

上面的图 2 提供了一个很好的例子,展示了该数据集中单个条目的样子。让我们分解一下:
- 左栏 (输入) : 我们看到名为“唐悠悠 (Tang Youyou)”的角色在对话 5、6 和 11 中的片段。在对话 6 中,她谈到喝自来水和吃过期的巧克力让自己生病。
- 中栏 (状态层级) : 标注者识别特定的话语 (U#) 并解释人格状态 。 对于对话 6,推理指出她故意让自己生病反映了“由于焦虑和担心而表现出的高神经质”。
- 右栏 (特质层级) : 这里汇总了发现。它将神经质细分为焦虑 (Anxiety)、抑郁 (Depression) 和情绪波动 (Emotional Volatility) 等侧面。它综合来自不同对话的证据,得出结论: 唐悠悠的特质水平为高。
这种细粒度的标注——将特定句子 (U#12) 链接到特定状态,再由该状态支持特质的特定侧面——正是该数据集的独特之处。
数据集统计与洞察
最终的数据集包含 1,924 个对话和超过 32,000 条话语。但除了原始数字之外,数据的分布揭示了关于人类 (或角色) 本质的一些有趣现象。
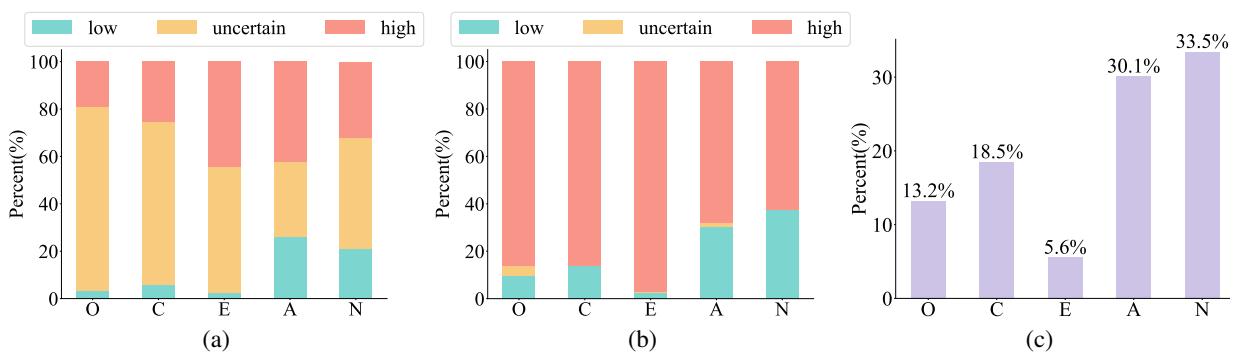
图 3 突显了这项任务的复杂性。看图表 (a) , 即状态标签的分布。你会注意到大量的“不确定 (Uncertain)” (黄色) 部分。这是合理的——在任何给定的对话中,你不一定强烈地表现出你的人格特质。你可能只是在点咖啡。
然而,看图表 (b) , 即特质标签。在这里,“不确定”的部分显著缩小。虽然个别时刻可能模棱两可,但一个人交互的总和通常能描绘出一幅清晰的画面。
最有趣的是,图表 (c) 显示了“状态标签与特质标签不同的比例”。这证实了“特质 vs. 状态”理论。在很大一部分时间里,一个人在特定时刻的行为与其整体人格特质并不匹配。一个以宜人性为主导的人可能会进行一场不愉快的争论。忽略这种区别的模型很可能会失败。
人格可视化
为了了解数据集中的“推理过程”是什么样的,作者基于文本证据生成了词云。

在图 4 中,我们看到了人格的词汇表。
- 高开放性 (a): 诸如 complex (复杂)、creative (创造性)、curious (好奇)、ideas (想法) 和 imagination (想象力) 等词汇占据主导地位。
- 低尽责性 (d): 我们看到诸如 careless (粗心)、irresponsible (不负责任)、lazy (懒惰)、mess (混乱) 和 forget (忘记) 等词汇。
这些词云验证了该数据集捕捉到了与大五人格特质相关的正确语义概念。
两个新任务: EPR-S 和 EPR-T
研究人员定义了两个不同的任务,供未来的 AI 模型使用该数据集来解决:
1. 基于证据的人格状态识别 (EPR-S)
目标: 给定单个对话,预测说话人关于特定维度 (例如,外向性) 的人格状态 (高、低或不确定) 。 要求: 模型必须同时输出证据 :
- 哪些话语 (句子) 导致了这个结论?
- 解释为什么这些句子表明该状态的自然语言说明 (推理) 。
2. 基于证据的人格特质识别 (EPR-T)
目标: 给定一组多轮对话 (历史上下文) ,预测说话人的长期人格特质。 要求: 模型必须提供:
- 哪些对话最相关?
- 涵盖该特质不同侧面的综合解释。
第二个任务要难得多。它涉及处理相互冲突的证据 (“好人也有糟糕的一天”问题) 和处理更大的上下文窗口。
实验: LLM 表现如何?
作者在这些任务上对三个主要的大型语言模型进行了基准测试: ChatGLM3-6B、Qwen1.5-7B 和 GPT-4-Turbo 。
他们使用了思维链 (Chain-of-Thought, CoT) 微调。这意味着他们训练模型 (或在 GPT-4 的案例中提示它) 在生成最终标签之前生成推理证据,强迫模型对问题进行“思考”。
结果
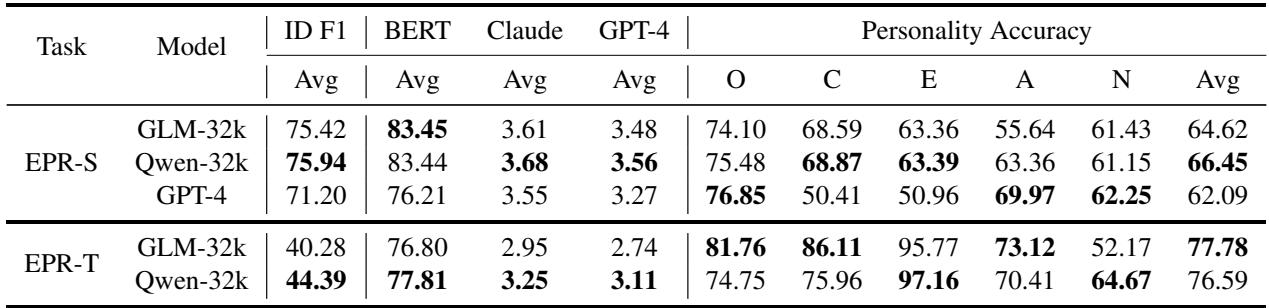
表 2 揭示了目前的最先进水平。解读如下:
- ID F1: 模型识别作为证据的特定句子/对话的准确度。
- BERT / Claude / GPT-4 (Score): 这些指标衡量生成的文本解释与人类 Ground Truth 相比的质量。
- Personality Accuracy: 模型是否正确猜出了最终标签 (高/低/不确定) ?
关键结论:
- 这很难: 特质任务 (EPR-T) 的准确率分数平均在 52% 到 64% 之间 (右下角的 Avg 列) 。这表明尽管现代 LLM 很强大,但解释人格仍然是一个复杂的挑战。
- Qwen 和 GLM 具有竞争力: 经过微调的较小模型 (ChatGLM 和 Qwen) 在几个指标上表现出色,甚至在识别证据 (ID F1) 方面超过了 GPT-4。
- GPT-4 的零样本性能: 即使没有微调,GPT-4 也表现出了强大的推理能力,尽管在纯准确率方面有时落后于专门为此数据训练的模型。
证据的价值
研究人员提出的最重要的问题之一是: 强迫模型解释自己实际上会让它更准确吗?
他们进行了一项消融实验 (移除系统的部分组件以观察结果) 。他们比较了直接 (Direct) 预测 (仅猜测标签) 与 CoT (先生成证据) 。
对于状态识别任务,引入证据 (混合训练) 将性能提高了约 2% 。 这表明,当 LLM 被迫阐述说话人的“思想、感觉和行为”时,它能更好地理解人格状态。
流水线方法: 状态 \(\rightarrow\) 特质
研究人员还测试了知道状态是否有助于预测特质。
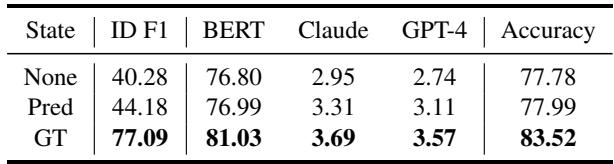
表 5 显示了该实验的结果。
- None: 仅给模型提供原始对话。
- Pred: 给模型提供对话 + 预测的状态 (模型认为的状态) 。
- GT: 给模型提供对话 + Ground Truth 状态 (正确的人类标注) 。
从“None”到“GT”的性能飞跃是巨大的 (准确率从 77.78% 提升至 83.52%) 。即使使用模型自己预测的状态 (“Pred”) 也提供了轻微的提升。
这证实了作者的假设: 理解人格特质的途径在于准确理解瞬间的状态。 如果我们能构建出更擅长识别即时状态 (EPR-S) 的模型,我们自然会更擅长识别长期特质 (EPR-T)。
结论: 迈向具备同理心的 AI
孙雷、赵金明和金琴的这项工作代表了情感计算领域的成熟。我们正在从简单的分类时代 (AI 基于数据中的隐藏模式分配人格标签) 迈向可解释人工智能 (XAI) 的时代,在这个时代,系统必须证明其结论的合理性。
PersonalityEvd 数据集为社区提供了一个具有挑战性的基准。它要求模型执行复杂的推理,处理短期行为与长期特质之间的矛盾,并用自然语言阐述心理学概念。
虽然目前的模型在这些任务上仍难以达到人类水平,但 CoPE 框架提供了改进的路线图。通过模仿人类收集证据以及区分暂时状态与永久特质的过程,我们离能够真正“理解”而不仅仅是标记人类人格复杂性的 AI 更近了一步。