](https://deep-paper.org/en/paper/2410.01036/images/cover.png)
引言
在人工智能飞速发展的世界里,“开源”已成为一个热门词汇。从大型语言模型 (LLM) 到语音基础模型 (SFM) ,开发者和研究人员被层出不穷的声称是“开放”的新模型所淹没。但如果你透过表面深入观察,就会发现一个复杂的问题: 开源洗白 (Open Washing) 。
许多模型发布了它们的权重 (训练好的参数) ,但保留了训练数据和代码作为私有财产。即使数据被发布,往往也伴随着限制性许可——例如“非商业用途”或“禁止衍生作品”——这严格违反了开源 AI 的定义。对于刚进入这一领域的本科生和硕士生来说,这一区别至关重要。如果你构建的基础在法律上站不住脚,你就无法构建一个真正开放的、社区驱动的或商业化的应用程序。
这正是论文 “MOSEL: 950,000 Hours of Speech Data for Open-Source Speech Foundation Model Training on EU Languages” 所切入的痛点。
MOSEL 背后的研究人员解决了一个巨大的挑战: 为欧盟 (EU) 的 24 种官方语言创建一个 100% 符合开源原则的训练数据集。他们收集了近一百万小时的语音数据,关键是,他们为其中近一半的数据生成了自动转录文本,并在宽松的许可下发布了所有内容。
在这篇文章中,我们将探讨为什么数据许可很重要,MOSEL 数据集是如何构建的,用于标记海量音频的巧妙技术,以及证明这些数据可以训练出高质量模型 (即使是像马耳他语这样的低资源语言) 的实验证据。
背景: “开源”定义的问题
在深入了解数据集之前,我们需要了解语音基础模型 (SFM) 的现状。像 OpenAI 的 Whisper 或 Meta 的 SeamlessM4T 这样的模型已经彻底改变了自动语音识别 (ASR) 。然而,它们在开放性方面存在很大的局限性:
- Whisper: 模型权重和推理代码是开放的 (MIT 许可) ,但训练数据不公开。我们不知道它确切是在什么数据上训练的,这使得复现变得不可能。
- SeamlessM4T: 模型已发布,但使用的许可不符合开源标准 (它限制了你使用它的方式) 。
- OWSM (Open Whisper-style Speech Model): 该项目旨在实现开放性,但在 MuST-C 等数据集上进行了训练,而 MuST-C 具有“非商业用途” (NC) 许可。这限制了生成的模型用于商业用途。
什么是真正的开源 AI?
根据开放源代码促进会 (OSI) 的说法,只有当一个系统赋予了用户出于任何目的使用、研究、修改和共享该系统的自由时,它才是真正的开源系统。这意味着:
- 代码必须开放。
- 模型权重必须开放。
- 训练数据必须在符合开源 (OS) 标准的许可下可用。
符合开源标准的许可包括 CC-BY (知识共享署名) 或 CC-0 (公有领域) 。像 CC-NC (非商业用途) 或 CC-SA (相同方式共享) 这样的许可不是符合开源标准的,因为它们限制了数据 (以及任何衍生模型) 的使用或分发方式。
MOSEL 项目旨在通过聚合仅符合这些严格标准的欧盟语言数据来填补这一空白。
核心方法: 构建 MOSEL 数据集
MOSEL 的创建包括两个主要阶段: 调研和收集现有的合规数据,然后通过伪标签 (pseudo-labeling) 丰富这些数据。
1. 调研符合开源标准的数据
研究人员对现有的 ASR 数据集和未标记的语音语料库进行了详尽的调研。他们应用了一个严格的过滤器:
- 包含: 公有领域、CC-0、CC-BY。
- 排除: 任何带有非商业用途 (NC) 、禁止衍生 (ND) 或相同方式共享 (SA) 条款的数据集。
他们还必须小心“被污染”的数据集。例如,某个数据集可能是在宽松许可下发布的,但数据的来源 (如 YouTube 视频) 可能有各种限制性服务条款。作者排除了 GigaSpeech 和 MaSS 等数据集,因为它们的底层数据源 (分别是 YouTube 和 Bible.is) 不允许不受限制的衍生作品。
经过这一严格的筛选,他们积累了 950,192 小时的语音数据。
分布问题
虽然总小时数令人印象深刻——超过了 Whisper v2 使用的数据量——但分布极不平衡。
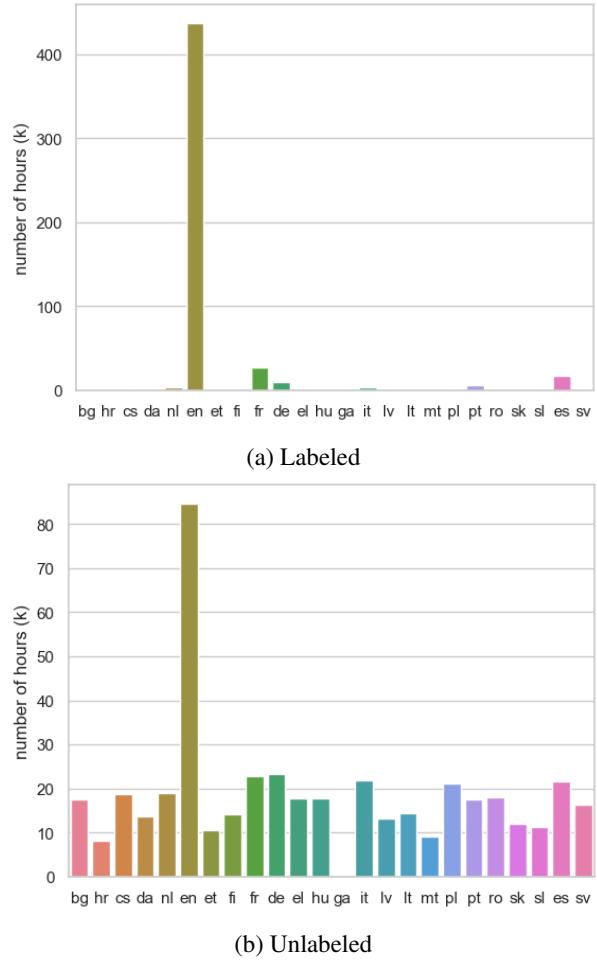
如 图 1 (上图) 所示,有标签数据 (带有该人工转录文本的数据) 以英语 (en) 为主,拥有超过 400,000 小时。其他语言如德语 (de) 、西班牙语 (es) 和法语 (fr) 有相当数量的数据,但许多欧盟语言几乎没有有标签数据。
然而,请看图 1 中的 下图 。 这显示了无标签数据 (没有文本的原始音频) 。在这里,分布要均衡得多。几乎每种语言都有至少 8,000 小时的可用音频 (爱尔兰语除外) 。这一观察结果是他们方法第二部分的驱动力: 伪标签 。
2. 伪标签过程
由于像马耳他语或克罗地亚语这样的人工标记数据稀缺,但原始音频丰富,研究人员转向了 弱监督 (Weak Supervision) , 特别是伪标签技术。
他们提取了 441,000 小时的无标签音频 (主要来自 VoxPopuli 和 LibriLight 数据集) ,并通过一个强大的现有 ASR 模型来生成转录文本。
- 教师模型: 他们使用了 Whisper Large v3 。 尽管 Whisper 的训练数据不开放,但模型权重是 Apache 2.0 许可的,这意味着该模型生成的输出 (转录文本) 可以公开发布。
- 规模: 这个过程在 NVIDIA A100 GPU 上大约需要 25,500 个 GPU 小时 。
绿色 AI 与可复现性
作者为什么要这样做并发布转录文本?为什么不让每个学生或公司自己运行 Whisper?
运行 25,000 个 GPU 小时估计会产生 35,625 千克的二氧化碳排放,并且在 AWS 等云提供商上的成本将超过 100,000 美元。通过一次性生成这些标签并在 CC-BY 许可下发布,MOSEL 团队避免了重复劳动,节省了资金并减少了 AI 研究对环境的影响。
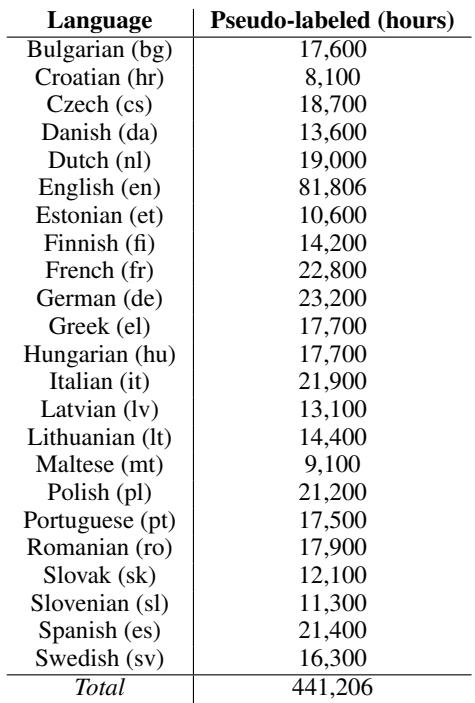
表 4 列出了生成的伪标签数据的数量。这有效地将“无标签”资源转化为“有标签”资源 (尽管带有一些噪声较大的机器生成标签) ,从而为英语以外的其他语言创造了公平的竞争环境。
3. 解决幻觉与数据质量问题
使用模型生成转录文本的一个重大风险是模型可能会犯错。Whisper 和许多生成式模型一样,容易产生 幻觉 (hallucinations) 。
在语音识别的背景下,幻觉不仅仅是拼写错误;它往往是完全的捏造。如果音频背景噪音很大或有长时间的静默,Whisper 可能会输出不存在的文本。

表 6 提供了一些有趣但成问题的例子。
- 在第 2 行中,模型生成了一串重复的“No, no, no, no.”。
- 在其他情况下,模型可能会陷入循环,在整个静默文件的持续时间内重复输出“Amen. Amen. Amen.”或“谢谢” (例如捷克语中的“Děkuji”) 。
为了缓解这一问题,MOSEL 团队实施了过滤策略:
- 语种识别 (LID): 他们使用模型来验证音频中说的语言是否实际上与元数据匹配。如果一个文件被标记为“马耳他语”但听起来像“英语”,它就会被丢弃。
- 幻觉检测: 他们标记了包含重复循环或已知幻觉模式 (如“谢谢”循环) 的片段,以便开发者可以选择在训练期间将其过滤掉。
实验与结果: 马耳他语案例
为了证明该数据集确实有用,作者进行了一个“概念验证”实验。他们选择了 马耳他语 (Maltese) , 这是一种闪米特语族语言,虽是欧盟官方语言,但在历史上资源非常匮乏。
为什么选马耳他语?
马耳他语是一个完美的压力测试,因为:
- 它的人工标记数据非常少 (MOSEL 中只有大约 19 小时) 。
- Whisper 在这上面的表现非常糟糕。正如作者指出的那样,Whisper Large v3 在马耳他语上的词错误率 (WER) 超过 70-80%,这实际上是不可用的。
实验设置
研究人员训练了一个序列到序列 (Sequence-to-Sequence) ASR 模型:
- 编码器: 12 层 Conformer (卷积神经网络和 Transformer 的混合体,擅长捕捉局部和全局音频模式) 。
- 解码器: 6 层 Transformer。
- 训练数据: 他们比较了仅使用少量有标签数据进行训练,与结合有标签数据和新的 MOSEL 伪标签数据进行训练的效果。
结果
结果是变革性的。

表 3 展示了词错误率 (WER) 的表现, 数值越低越好 。
- Whisper Large v3 (基线) : 在 CommonVoice 上达到 80.8 的 WER,在 FLEURS 上达到 73.8 。 这表明该模型主要是在猜测。
- MOSEL (有标签 + 伪标签) : 通过在 MOSEL 数据上进行训练,WER 显著下降至 39.4 和 38.9 。 与巨大的 Whisper 模型相比,这几乎减少了 50% 的错误。
- MOSEL (过滤后) : 当他们应用前面讨论的过滤技术 (移除错误的语言和幻觉) 后,WER 进一步下降至 23.8 。
解释
这个实验向学生们展示了一个关键的发现: 数据质量和数量往往比模型架构更重要。
尽管伪标签是由 Whisper (在马耳他语上表现很差) 生成的,但海量的数据,加上音频本身是有效的马耳他语演讲这一事实,使得新模型能够学习到 Whisper 遗漏的声学模式。这个“学生”模型 (在 MOSEL 上训练) 显著优于“教师”模型 (Whisper) 。
结论与启示
MOSEL 论文代表了我们在语音领域对待开源 AI 方式的根本性转变。它超越了“开放权重”,迈向了“开放科学”,确保了从原始数据到最终模型的整个流程都是透明且合规的。
给学生的关键启示:
- 许可协议素养: 务必检查训练数据的许可协议。“公开发布”并不意味着“开源”。
- 伪标签的威力: 你并不总是需要昂贵的人工标注。如果你有足够的无标签数据和一个像样的教师模型,你可以引导出高性能的系统。
- 语言公平性: 资源不平衡是一个主要问题。英语有 40 多万小时的有标签数据;像马耳他语这样的语言只有不到 20 小时。像 MOSEL 这样的项目对于保护和数字化语言多样性至关重要。
- 绿色 AI: 重用计算结果 (如转录文本) 是可持续 AI 开发的重要实践。
通过发布 95 万小时的合规数据和 44.1 万小时的转录文本,MOSEL 为下一代真正开放的欧盟语音基础模型奠定了基石。它邀请社区不仅是下载一个模型,而是去理解、重建并从头开始改进它。