](https://deep-paper.org/en/paper/2410.02440/images/cover.png)
在人工智能快速发展的格局中,一场新的军备竞赛已经打响。一方是像 OpenAI 和 Google 这样的大型语言模型 (LLM) 提供商,他们正致力于为生成的内容添加水印。他们的目标是崇高的: 以不可见的方式标记 AI 生成的文本,从而遏制虚假信息、学术造假和垃圾邮件。
另一方则是对手——那些想要去除这些水印,试图将 AI 文本伪装成人类创作的用户。
直到最近,人们还普遍认为只要生成水印的“密钥”保持机密,水印就是相对安全的。然而,一篇题为 “Optimizing Adaptive Attacks against Watermarks for Language Models” (针对语言模型水印的优化自适应攻击) 的新研究论文挑战了这一假设。研究人员证明,只要攻击者知道所使用的方法 (即使没有密钥) ,他们就可以训练一个更小、更便宜的 AI 模型,近乎完美地去除水印,而计算成本不到 10 美元。
在这篇文章中,我们将解构这篇论文,探讨水印技术是如何工作的,为什么当前的防御措施正在失效,以及这种巧妙的优化技术是如何让一个 70 亿参数的小模型战胜一个 700 亿参数的庞然大物的。
问题所在: 隐匿式安全?
要理解攻击,我们需要先理解防御。LLM 水印通常通过微妙地偏置模型做出的词语选择来起作用。
当 LLM 生成文本时,它基于概率预测下一个词。水印算法根据前面的 Token 将词汇表划分为“绿名单” (允许的词) 和“红名单” (禁止的词) 。通过强制模型比随机几率更频繁地从绿名单中选择词语,一种统计信号就被嵌入到了文本中。对于人类来说,文本读起来很正常。对于拥有正确密钥的检测算法来说,这种模式就像灯塔一样显眼。
鲁棒性差距
如果去除水印需要严重破坏文本质量,那么该水印就被认为是鲁棒的 。 如果我必须把一篇优美的文章变成胡言乱语才能去除水印,那么水印就赢了。
然而,这篇论文的作者认为,当前的鲁棒性测试存在缺陷。大多数研究人员仅针对非自适应攻击者测试他们的水印——这些对手只是尝试随机策略,例如:
- 用同义词替换单词。
- 将文本翻译成法语再翻译回来。
- 添加打字错误或拼写错误。
这些都是“盲目”的攻击。但是,如果攻击者是自适应的呢?如果他们知道水印算法是如何工作的 (例如,他们知道它是“Dist-Shift”方法还是“Exp”方法) ,只是缺少私钥呢?
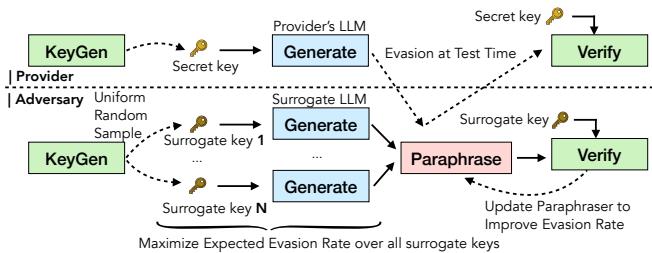
如图 1 所示,自适应攻击场景涉及一个循环。对手使用替代 LLM (他们自己拥有的模型) 来模拟提供商的水印过程。通过生成他们自己的密钥并针对这个替代模型进行练习,他们可以训练一个专门设计用来破坏水印的“改写模型 (Paraphraser) ”。
核心方法: 将优化武器化
研究人员提出了一种方法来训练特定类型的神经网络,称为改写模型 。 该模型的目标很简单: 将带有水印的文本作为输入,并输出 (1) 不再触发检测器且 (2) 保持高语言质量的纯净文本。
制定目标
研究人员将鲁棒性视为一个优化问题。他们希望最大化一个平衡规避效果和质量的目标函数。
数学公式如下所示:
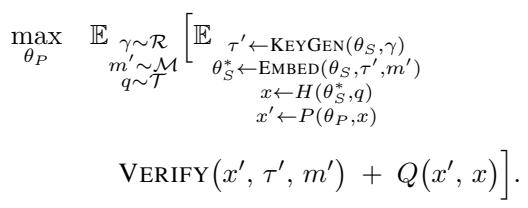
让我们拆解一下:
- \(\theta_P\) : 攻击者的改写模型的参数 (我们正在训练的对象) 。
- \(\tau'\) : 一个“替代密钥”。攻击者使用已知的
KeyGen算法生成它。 - VERIFY : 检测函数。攻击者希望该函数的输出较低 (低于检测阈值) 。
- \(Q(x', x)\) : 质量函数。攻击者希望改写后的文本 \(x'\) 在含义和质量上与原始文本 \(x\) 非常相似。
这种方法的精妙之处在于使用了替代密钥 。 攻击者不需要提供商的密钥 (假设为 \(\tau\)) 。因为水印算法是公开的,攻击者可以生成数千个随机密钥 (\(\tau'\)) ,为自己的文本添加水印,并训练改写模型来破坏这些水印。其假设是,一个能够破坏由密钥 A、密钥 B 和密钥 C 生成的水印的模型,将学会该算法本身的基本统计弱点,从而使其能够破坏由提供商的秘密密钥 X 生成的水印。
利用偏好优化打造“完美”攻击者
训练 LLM 来“最大化规避”是困难的,因为文本是离散的 (你无法轻易地对特定词语的选择进行微分) 。为了解决这个问题,作者使用了一种类似于基于人类反馈的强化学习 (RLHF) 的技术,特别是依赖于偏好数据集 。
他们整理了一个由“赢家”和“输家”组成的数据集来教导模型。以下是该过程,详见论文中的 Algorithm 1 :
- 生成: 使用替代模型 (例如 Llama-2) 生成带有特定水印的文本。
- 改写: 使用当前的改写模型为该文本生成 \(N\) 个不同的变体。
- 测试: 针对替代密钥检查这些变体。
- 正样本: 成功规避检测且具有高质量的改写。
- 负样本: 未能规避检测的改写。
- 训练: 将这些配对输入模型,教导它偏好“正样本”策略。
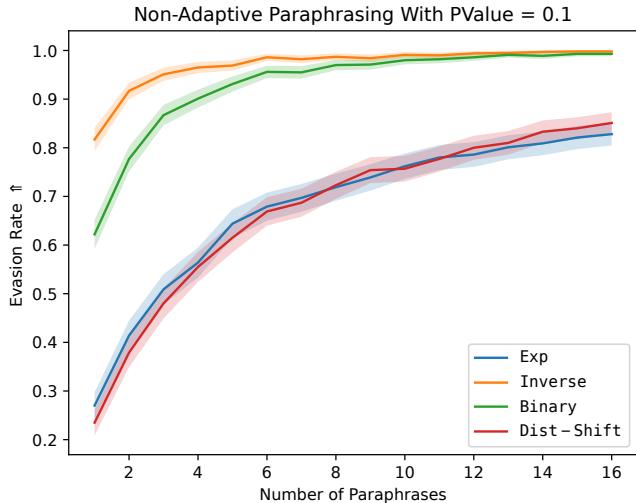
图 2 说明了这种方法为何有效。该图表显示了“N 选一 (Best-of-N) ”的规避率。即使使用标准的、未训练的 Llama-2 模型,如果你生成 16 个改写版本,这其中至少有一个能破坏水印的概率也非常高 (对于某些方法约为 97%) 。训练过程本质上是教导模型在第一次尝试时就持续产生那个“幸运的突破”。
实验: 大卫与歌利亚
实验设置让受限的攻击者对抗强大的防御者。
- 受害者 (提供商) : 一个巨大的 Llama-3-70B 模型。
- 攻击者: 一个小得多的 Llama-2-7b 或 Qwen-2.5-7b 模型 (大约小 10 倍) 。
- 成本: 作者指出,整理数据集和微调攻击者的成本不到 7 个 GPU 小时 , 或者大约 10 美元 。
帕累托前沿
在安全研究中,我们寻找帕累托前沿 (Pareto Frontier) ——代表两个相互冲突的目标之间最佳权衡的曲线。在这种情况下,目标是文本质量与规避率 。
完美的攻击应该位于右上角: 100% 的规避率和 100% 的质量保留。
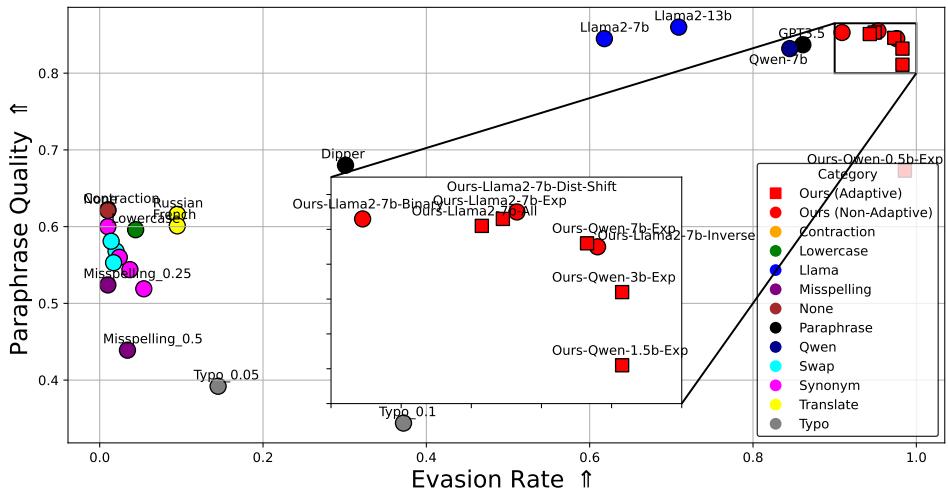
图 4 揭示了自适应攻击惊人的有效性。
- 圆圈 (\(\circ\)): 这些是非自适应基线 (简单的改写、同义词交换) 。它们散落在中间——要么未能规避 (X 轴低) ,要么破坏了文本质量 (Y 轴低) 。
- 方块 (\(\square\)): 这些是本文提出的自适应攻击。注意它们是如何大力推向右上角的。
- 红色方块: 这些是作者的特定模型 (“Ours”) 。它们实现了大约 97% 的规避率 , 同时保持了与原始文本几乎相同的质量评分。
最值得注意的是,攻击者模型 (70 亿参数) 明显小于受害者模型 (700 亿参数) ,但它完全瓦解了安全机制。
可迁移性: “万能钥匙”效应
一个关键问题依然存在: 如果我训练我的攻击者来破坏“Dist-Shift”水印,它也能破坏“Exp”水印吗?还是说我需要为每种新算法重新训练?
研究人员通过在一种水印方法上训练并在其他方法上测试来验证这一点。
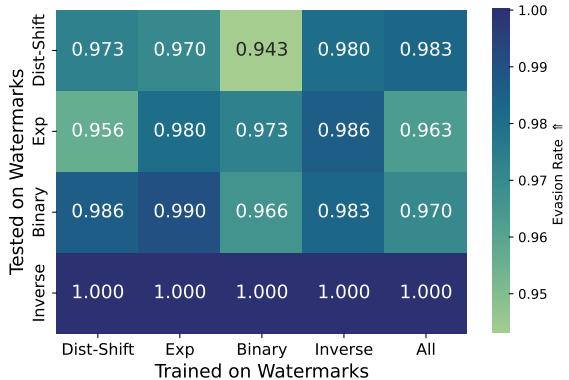
图 3 中的热力图显示了结果。 对角线代表自适应设置 (在 X 上训练,在 X 上测试) ,其中规避率接近 100% (绿色/黄色) 。然而,请看非对角线元素。即使模型是在“Dist-Shift”上训练并在“Inverse”上测试 (左下角) ,规避率仍然非常高。
这意味着水印方法具有潜在的共同统计漏洞。一个被训练来平滑某种方法的统计异常的攻击者,学会了为所有方法平滑这些异常。
定性分析: 文本读起来还通顺吗?
如果输出读起来像一台坏掉的打字机,那么高规避率毫无用处。作者利用“以大模型为裁判 (LLM-as-a-Judge) ” (使用 GPT-4 或 Llama-3 来给文本打分) 以确保质量保持在高水平。
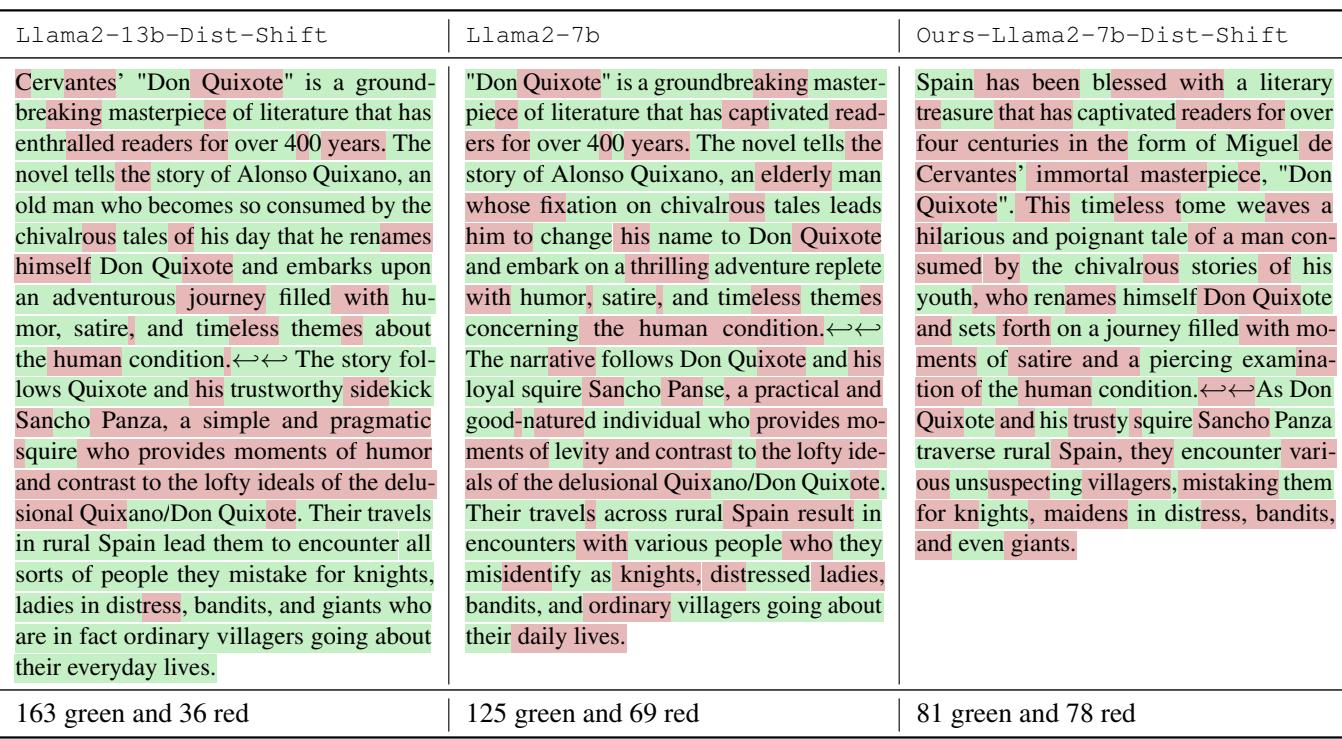
表 2 提供了一个具体的例子。
- 左侧 (带水印) : 一篇关于“堂吉诃德”的文本。它有 163 个“绿色”Token 和 36 个“红色”Token。这个比例在统计上是不可能的,将其标记为 AI 生成。
- 右侧 (自适应攻击) : 含义完全相同。行文自然。但看这个比例: 81 个绿色,78 个红色。这几乎是完美的 50/50 分裂,这正是人类写作在检测器眼中的样子。水印已被彻底擦除。
模型实际上在做什么?
为了理解模型是如何做到这一点的,研究人员分析了“Token 编辑距离” (文本改变了多少) 和“N-gram 重叠率” (有多少短语保持不变) 。
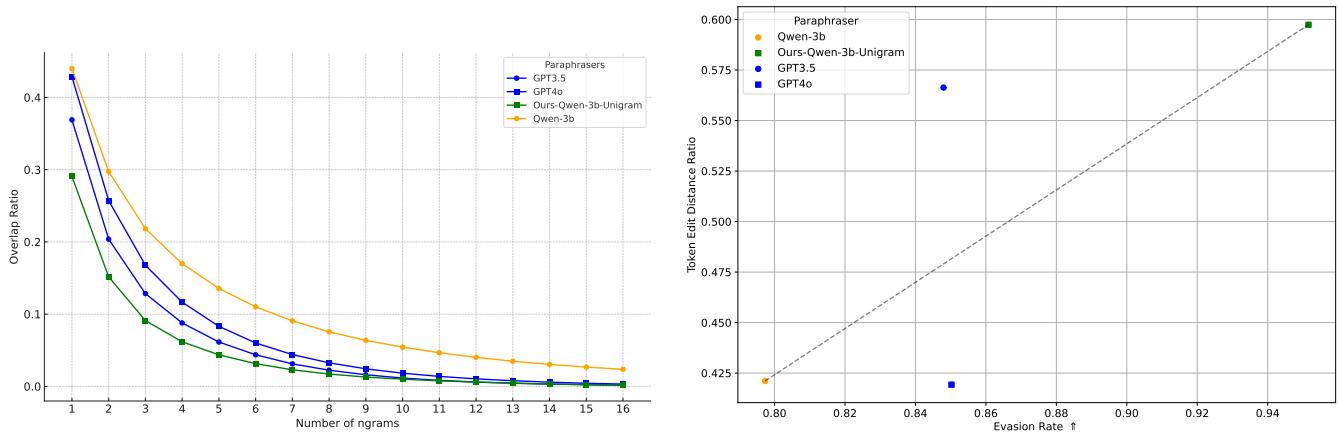
图 15 提供了一个迷人的视角。
- 左图: 自适应改写模型 (Ours-Qwen-3b) 的 N-gram 重叠率低于 GPT-3.5 或 GPT-4 等标准改写模型。它更积极地改变具体的措辞。
- 右图: 编辑距离与规避率之间存在直接的相关性。自适应模型准确地学会了需要对文本进行多少编辑才能将检测置信度降至阈值以下 (\(p < 0.01\)) ,同时不做会损害质量的不必要更改。它正在对外科手术般地移除水印。
结论与启示
这篇研究论文为 AI 安全社区敲响了警钟。研究结果是赤裸裸的:
- 当前的水印很脆弱: 它们依赖于攻击者的“愚蠢”。面对一个了解算法且只需花 10 美元的攻击者,它们就会崩溃。
- 规模不重要: 一个小型的开源模型可以击败世界上最大型专有模型的保护措施。
- 泛化是一个风险: 针对一种水印进行训练赋予了破坏未见过的水印的能力,这表明统计水印的整个概念可能具有根本性的局限性。
作者建议,未来的水印研究必须摆脱“隐匿式安全”。鲁棒性测试应该包括自适应攻击者——专门训练来破坏系统的模型——而不仅仅是随机扰动。就像我们通过雇佣红队主动攻击系统来测试软件安全性一样,我们也必须通过主动尝试用 AI 擦除水印来测试 LLM 水印。
在此之前,我们必须接受这样一个事实: 任何当前部署的水印都很可能被一个简单的、经过优化的改写模型清洗掉。