](https://deep-paper.org/en/paper/2410.02691/images/cover.png)
像 GPT-4 或 Llama 这样的语言模型 (LMs) 彻底改变了自然语言处理,但对于一个截然不同的领域——计算心理语言学 (Computational Psycholinguistics) ——来说,它们也已成为不可或缺的工具。
研究人员使用这些模型来测试关于人类大脑如何处理语言的理论。该领域的主流理论是惊奇理论 (Surprisal Theory) , 该理论认为处理一个单词的难度与大脑看到它的“惊奇”程度成正比。如果一个语言模型给某个单词分配的概率很低,那么它的惊奇值就很高,理论认为,人类阅读它所需的时间就会更长。
但在这种比较中存在一个巨大且常被忽视的技术缺陷。现代语言模型的阅读方式与人类不同。人类阅读的是构成单词和短语的字符。而语言模型阅读的是 Token (词元) ——这是由字节对编码 (BPE) 等算法创建的、任意的子词单元块 (如 “ing”、“at” 或 “sh”) 。
这就造成了错位。当心理语言学家想要知道特定单词或文本区域的惊奇值时,他们往往是在与模型任意的分词方式作斗争。
在论文 Marginalizing Out Tokenization in Surprisal-Based Psycholinguistic Predictive Modeling 中,研究人员 Mario Giulianelli 及其同事指出我们一直以来的做法是错误的。他们提出了一种严谨的方法来弥合基于 Token 的模型与基于字符的人类阅读之间的鸿沟。通过“边缘化消除 (marginalizing out) ”分词器,他们解锁了预测阅读行为的新方法,并发现单词中最具预测性的部分可能根本不是整个单词,而是特定的“焦点区域 (Focal Areas) ”。
在这篇文章中,我们将打破分词器与认知科学之间的壁垒,探索字符级预测背后的数学原理,并看看那些重塑我们对阅读理解的实验结果。
冲突: 人类与机器的“阅读”
要理解这个问题,我们首先需要看看心理语言学实验是如何设计的。
在典型的眼动追踪研究中,参与者坐在屏幕前阅读句子,同时摄像头记录他们看的地方以及看的时间。文本被划分为感兴趣区域 (Regions of Interest, ROIs) 。 通常,一个 ROI 对应一个单词。
考虑这个句子: “Anne lost control and laughed.” (Anne 失去控制并笑了起来。)

如上图所示,研究人员可能会以不同的方式定义 ROI。他们可能包括单词之前的空格 (前导空格,Leading) 或单词之后的空格 (尾随空格,Trailing) 。
- 前导空格 (Leading Whitespace) :
_lost,_control - 尾随空格 (Trailing Whitespace) :
lost_,control_
这种区别对人类来说似乎微不足道。但对语言模型来说,这却是个令人头疼的问题。
标准的语言模型将文本处理为来自固定词表的 Token 序列。从文本到 Token 的映射是确定性的,但往往违反直觉。例如,根据分词器的不同,单词 control 可能是一个单独的 Token,但 _control (带空格) 可能会被拆分为 _ 和 control,或者 _con 和 trol。
这导致了方法论上的危机。如果你想计算单词 “control” 的惊奇值 (难度) ,你应该把哪些 Token 加起来?是否包含空格 Token?如果分词器以一种与你的 ROI 不一致的方式拆分单词怎么办?
最近的研究一直在争论是应该包含尾随空格还是前导空格,以便最好地拟合人类的阅读时间。Giulianelli 等人认为这种争论没有抓住重点。特定的分词方案是模型的实现细节,而不是语言或人类大脑的属性。
解决方案: 字符级视角
作者提出了一个彻底的简化方案: 分词是无关紧要的。
或者更确切地说,它应该是无关紧要的。我们应该将语言模型视为字符字符串上的概率分布,而不是 Token 上的概率分布。即使模型内部使用 Token,我们也可以从数学上将其输出转换为字符级的概率。
定义惊奇值 (Surprisal)
首先,让我们形式化核心指标。 惊奇值是字符串的负对数概率。如果我们有一个字符序列,在给定上下文 (之前的单词) 的情况下,特定区域 (如一个单词) 的惊奇值定义为:
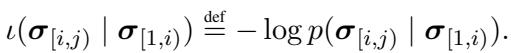
这里,\(\sigma_{[i, j)}\) 代表我们要研究的感兴趣区域 (ROI) 中的字符,而 \(\sigma_{[1, i)}\) 是上下文历史。
挑战在于语言模型给出的是 \(p(\text{tokens})\),而不是 \(p(\text{characters})\)。为了弥合这一差距,作者利用了一种称为边缘化 (Marginalization) 的技术。
对分词器进行边缘化
这是论文的数学核心。由于单个字符串理论上可以由多种不同的 Token 序列表示 (这种现象称为“伪歧义”) ,我们需要将导致目标字符串的所有可能的 Token 序列的概率加起来。
理想情况下,像 BPE 这样的分词器是确定性的——一个字符串等于一个 Token 序列。然而,要将模型视为真正的字符级模型,我们必须承认模型会给任何有效的 Token 序列分配概率质量。
字符串 \(\sigma\) 的概率是解码后为 \(\sigma\) 的所有 Token 序列 \(\delta\) 的概率之和:
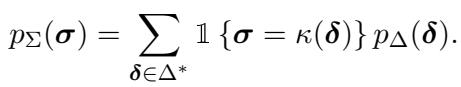
通过执行这种求和 (或使用“波束求和 (beam summing) ”算法来近似处理计算复杂性) ,我们将 Token 级的 GPT-2 转换为了字符级预测器。
这为什么重要? 因为它解放了我们。
一旦我们有了字符级模型,我们就不再局限于计算“Token”的惊奇值。我们可以计算任何我们想要的子字符串的惊奇值。我们不再被迫问: “这个 BPE Token 的惊奇值是多少?”,而是可以问: “这特定的 3 个字母的惊奇值是多少?”
这种自由让作者引入了一个新概念: 焦点区域 (Focal Areas) 。
焦点区域: 聚焦阅读行为
如果我们假设大脑是一个预测引擎,那么它究竟在预测什么?是预测下一个完整的单词?下一个语素?还是下一个字母?
眼动追踪研究告诉我们,人类的视觉是复杂的。当我们注视一个单词时,我们的周边视觉 (“副中央凹”) 会捕捉到关于下一个单词的信息。我们甚至可能在移动眼睛去看它之前,就已经看到了下一个单词的前几个字母。
因此,处理一个单词的难度可能取决于它前几个字符的惊奇值,而不是整个单词。作者将焦点区域 (Focal Area) 定义为 ROI 内部或与之重叠的特定子字符串。
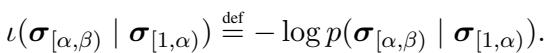
利用他们的字符级数学方法,研究人员定义了几种类型的焦点区域来与人类数据进行对比:
- 完整 ROI (Full ROI) : 标准方法。整个单词。
- 固定大小 (Fixed-size) : 单词的前 3 个字符 (例如,“control” 的 “con”) 。
- 动态大小 (Dynamic) : 前 \(N\) 个字符,其中 \(N\) 根据前一个单词的长度和眼睛能看到的范围 (单词识别跨度) 而变化。
- 前瞻 (Look-ahead) : 包含当前单词加上来自下一个单词的字符。
下表精确地展示了这些焦点区域对于句子 “Anne lost control…” 是如何不同的。
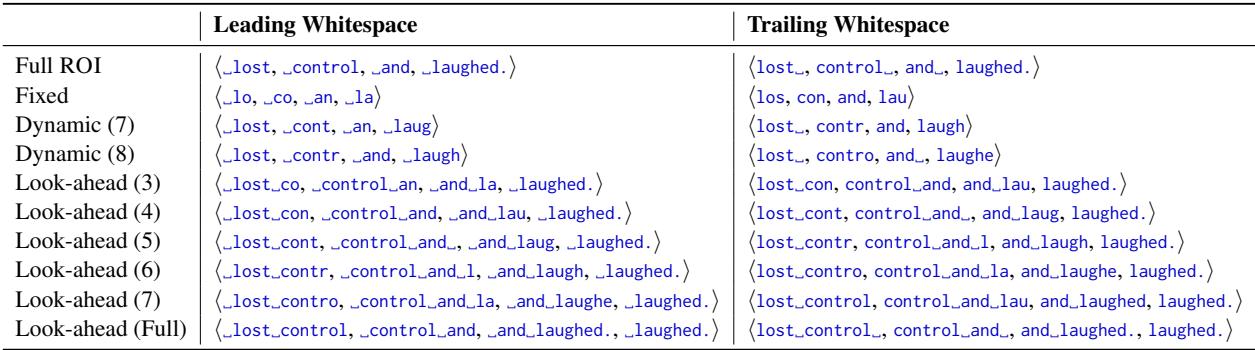
仔细看 “Fixed” (固定) 这一行。对于 ROI “_control”,焦点区域仅仅是 _co。假设是,大脑决定跳过还是处理这个单词,很大程度上取决于这些初始字符。
实验设置
为了测试这些焦点区域中哪一个最能预测人类阅读行为,作者使用了四个主要的眼动追踪数据集: UCL, Provo, MECO, 和 CELER 。
他们测量了两件事:
- 跳读率 (Skip Rate) : 读者完全跳过一个单词的频率。
- 阅读时长 (Reading Duration) : 眼睛在某个区域注视了多久 (首次注视、凝视时长、总时长) 。
他们训练了一个回归模型,使用从不同焦点区域计算出的惊奇值来预测这些人类指标。成功的衡量标准是 \(\Delta R^2\)——也就是,相比于只知道单词长度和频率的基线模型,添加惊奇值特征后模型预测人类行为的能力提高了多少。
关键结果
研究结果挑战了仅使用“单词惊奇值”的标准做法。
1. 预测跳读率
我们什么时候会跳过一个单词?结果表明,我们是根据单词的开头来决定的。
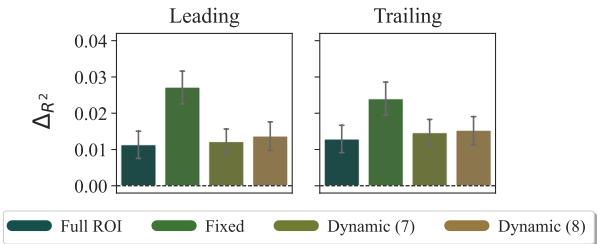
在上图 (来自 CELER 数据集) 中,看代表固定 (Fixed) 焦点区域 (前 3 个字符) 的绿色条柱。它具有最高的预测能力 (\(\Delta R^2\)) ,显著优于“完整 ROI” (深青色) 。
解释: 这与“副中央凹预视 (parafoveal preview) ”的好处相一致。当你读完前一个单词时,你的眼睛捕捉到了下一个单词的前几个字母 (_co) 。如果 _co 在那个语境中是高度可预测的,你的大脑就会说: “我知道这个词,没必要直接看它,”然后你就跳过了它。在整个单词 _control 上计算惊奇值会增加噪音,因为你的大脑在处理单词结尾之前就已经做出了决定。
2. 预测阅读时长
当我们确实停下来阅读一个单词时,什么预测了我们会停留多久?
在这里,情况发生了变化。 前瞻 (Look-ahead) 焦点区域通常表现最好。
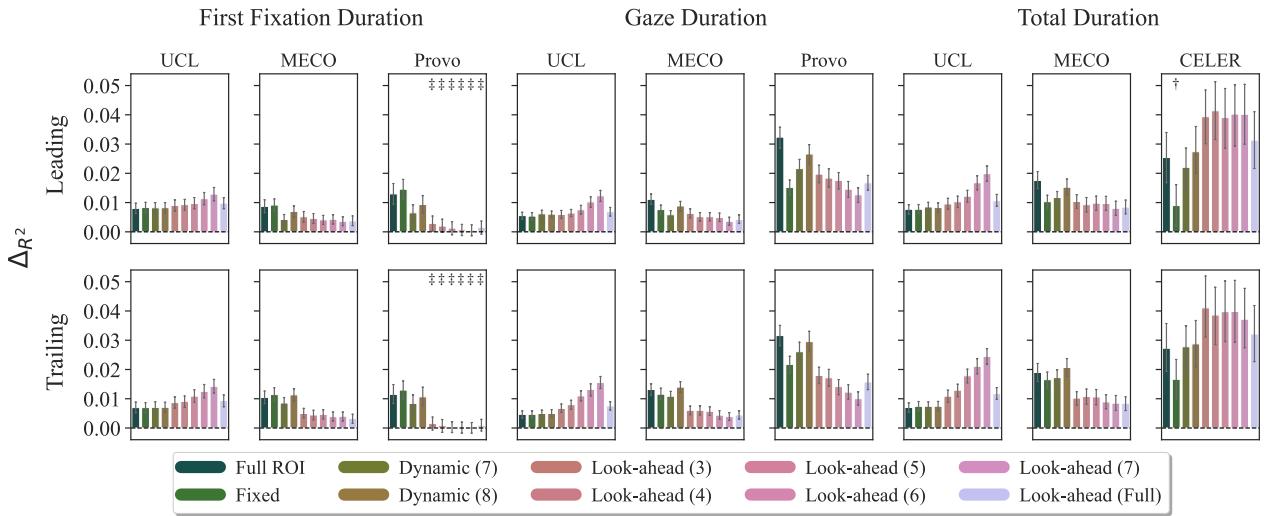
在 UCL 数据集 (图片左上角) 中,注意代表前瞻 (Look-ahead) 的紫色条柱。这些焦点区域包括当前单词加上下一个单词的开头。
解释: 这表明我们在一个单词上花费的时间受整合当前单词以及预处理下一个单词的“处理成本”影响。我们不是在孤立的桶里阅读;我们的处理会溢出。一个向前看的模型比一个停在单词边界的模型更能捕捉这种认知现实。
3. 空格之争
回想一下前面提到的关于“前导”与“尾随”空格 (例如 _word vs word_) 的争论。
结果 (如图 1 和图 2 所示) 显示,虽然存在细微差异,但焦点区域方法对两者都有效。通过边缘化消除分词的影响,研究人员将 ROI 的定义与分词器的伪影解耦了。你是把空格加在前面还是后面,不如你是否测量了正确的认知单元 (例如,前 3 个字符 vs 整个字符串) 的惊奇值来得重要。
结论: 算法 vs. 理论
这篇论文对于计算心理语言学来说是向前迈出的重要一步,因为它清理了一种混乱的方法论。
多年来,研究人员一直被迫绕过分词器进行修补,争论是否要加空格或如何处理被拆分的单词。这篇论文认为, 分词是一种工程上的便利,而不是认知的现实。
通过在数学上边缘化消除 Token,我们可以将大型语言模型视为字符级概率引擎。这种灵活性使我们能够提出关于阅读的更精确的问题。
固定大小 (前 3 个字符) 的焦点区域比完整单词更能预测单词跳读,这一发现有力地验证了这种方法。它表明未来的阅读模型应该少关注作为原子单位的“单词”,多关注大脑实际处理的视觉信息流——字符。
给学生的要点:
- 不要相信分词器: 仅仅因为 GPT-4 将 “ing” 视为一个 Token,并不意味着人类大脑以同样的方式将其处理为一个离散单元。
- 边缘化是强大的: 它允许你将模型的输出分布转换为适合你科学问题的格式,而不是强迫你的问题去适应模型。
- 眼快于心: 我们在看即将到来的文本之前就已经在处理它了。预测模型需要考虑到这种前瞻 (副中央凹) 机制。
我们用来研究思维的工具——比如语言模型——是不完美的代理。像这样的工作有助于我们磨练这些工具,确保我们测量的是人类认知,而不仅仅是分词器的伪影。