](https://deep-paper.org/en/paper/2410.04699/images/cover.png)
像 GPT-4 这样的大型语言模型 (LLM) 已经迅速从新奇事物转变为必不可少的生产力工具。我们用它们起草邮件、总结会议记录和调试代码。普遍的观点是,这些模型充当了“副驾驶 (co-pilots) ”的角色,在提高效率的同时,人类仍然是掌控全局的驾驶员。
但是,当任务不仅仅关乎速度,而是涉及特定领域的专家判断时,会发生什么?当一位专家依靠 LLM 进行复杂分析时,他们是真的在使用工具,还是工具在潜移默化地影响他们对现实的认知?
乔治梅森大学的研究人员最近发表了一篇题为 “The LLM Effect: Are Humans Truly Using LLMs, or Are They Being Influenced By Them Instead?” (LLM 效应: 人类是真的在使用 LLM,还是反被其影响?) 的论文,直面了这个问题。通过设计一项涉及政策专家和“印度 AI 政策”的严谨研究,作者揭示了工作流速度与分析独立性之间一个引人入胜——也略带令人担忧——的权衡。
在本文的深入探讨中,我们将剖析 LLM 如何引入“锚定偏差 (anchoring bias) ”,为什么它们难以处理细微差别,以及数据揭示出的 AI 效率背后的真实代价。
核心问题: 效率 vs. 偏差
这项研究背后的动机非常直接。LLM 正越来越多地被部署在需要高度专业知识的领域,如法律分析、医疗诊断和政策研究。这些领域通常依赖“主题建模 (Topic Modeling) ”——即从海量文档中识别潜在主题。
传统上,这是一个缓慢且劳动密集型的过程,由人类完成。LLM 承诺将其自动化,或者至少显著加快速度。然而,研究人员假设,在这个工作流中引入 LLM 可能会触发锚定偏差 。
锚定偏差是 Tversky 和 Kahneman 于 1974 年首次描述的一种认知现象。它指的是个体在做决定时,过度依赖最初获得的信息 (即“锚点”) 。如果 LLM 首先提出了一组主题或标签,人类专家可能会下意识地将自己的分析锚定在这些建议上,从而可能忽略 AI 遗漏的独特或微妙的见解。
为了验证这一点,研究人员设计了一个两阶段实验,以衡量 LLM 的效率提升及其带来的认知影响。
研究设计: 双组记
该研究聚焦于一个具体且复杂的领域: 分析有关印度 AI 政策演变的访谈。这些内容信息密度大、细微差别多,且需要领域专业知识才能正确解读——这是测试人机协作的完美试验台。
研究人员招募了四名政策专家,并将研究分为两个截然不同的阶段:
- 主题发现 (Topic Discovery) : 阅读文档以创建一个相关主题列表。
- 主题分配 (Topic Assignment) : 使用该列表为新文档中的特定段落打标签。
关键在于,专家们被分成了两种设置:
- 对照组 (Control Setting) : 专家独自工作,仅依靠自己的判断。
- 实验组 (Treatment Setting) : 专家会收到 LLM 生成的建议 (主题或标签) 作为指导。
研究人员使用了“大声思维 (Think Aloud) ”协议,要求专家在工作时口述他们的思维过程。这种定性数据与定量日志相结合,为观察 AI 如何 影响他们的决策提供了一个窗口。
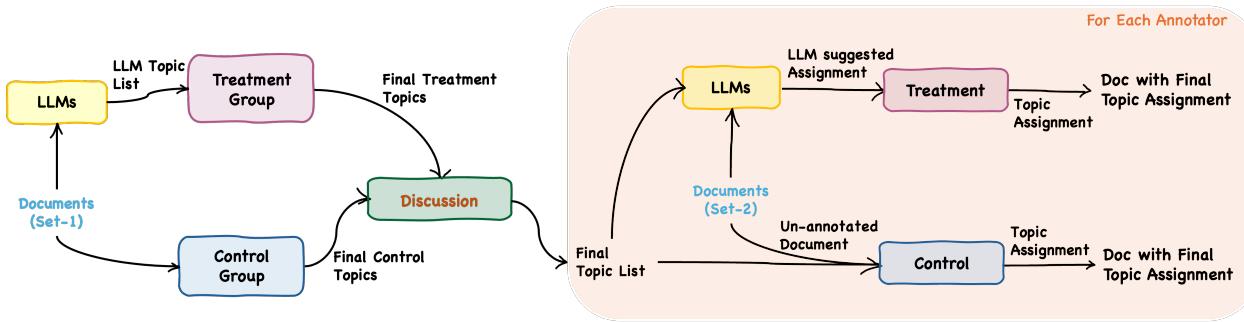
如上图 1 所示,该研究旨在每一步都对比“仅人类”工作流与“人类加 AI”工作流的产出。
第一阶段: 主题发现与“细微差别差距”
在第一阶段,目标是识别访谈记录中实际存在哪些主题。对照组阅读文本并从零开始生成主题。实验组则收到一份由 GPT-4 生成的主题列表,并以此作为起点。
这一阶段的结果凸显了当前 LLM 的一个关键局限性: 缺乏细微差别。
共识过程
在各自工作之后,人类标注者聚在一起合并他们的列表,创建一个“最终主题列表” (H) 。他们比较了对照组列表 (C) 、实验组列表 (T) 和原始 LLM 列表 (L) 。
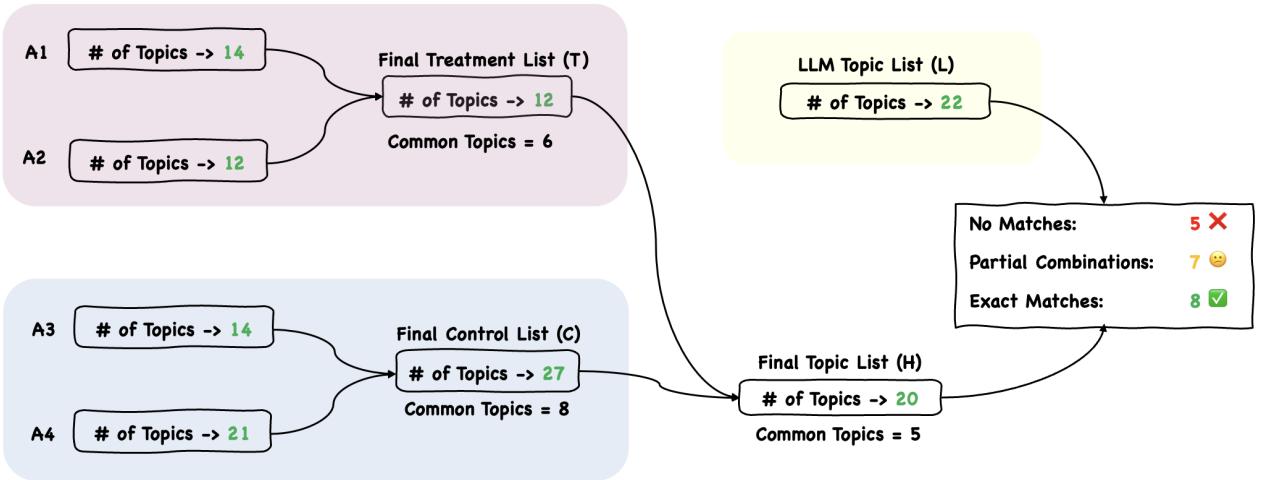
图 2 展示了这一整合过程。虽然存在显著重叠,但专家们发现 LLM 经常提供宽泛、笼统的标签。例如,LLM 可能会建议“性别研究”,而人类更倾向于“性别议题”,以捕捉文本中提到的具体不平等现象。
LLM 错过了什么
第一阶段最能说明问题的数据点是 LLM 完全未能察觉的内容。专家们确定了最终列表中的 20 个核心主题。LLM 成功识别或涵盖了其中的 15 个。然而, 有 5 个主题被 AI 完全遗漏了。

表 1 总结了这种差异。虽然在 20 个主题中遗漏 5 个看起来并非灾难性的,但这 5 个主题的性质至关重要。缺失的主题包括具体且敏感的领域,如 “治安与监控 (Policing & Surveillance) ” 和 “公民社会倡导 (Civil Society Advocacy) ” 。
为什么 LLM 会错过它们?研究人员分析了这些主题在文本中出现的频率。
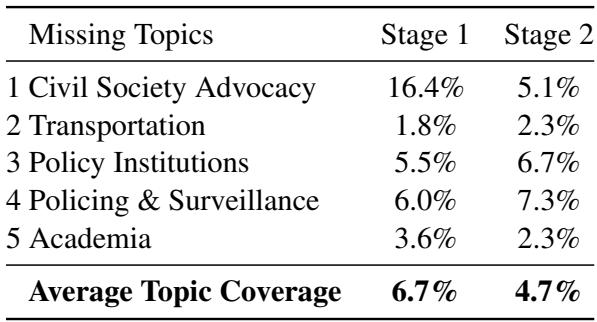
表 2 揭示了答案: 这些主题在文档中的普及率 (覆盖率) 较低。“交通”仅出现在 1.8% 的文本中;“治安与监控”为 6.0%。
这表明模型存在一种“多数票”偏差。LLM 非常擅长总结对话的主体部分 (宽泛、普遍的主题) ,但未能捕捉到频率低但影响大的信号。在政策分析中,对监控担忧的简短提及可能是访谈中最具政治意义的部分,但 LLM 却将其平滑处理掉了。
第二阶段: 主题分配与锚定偏差
研究的第二阶段涉及将最终主题列表应用于新文档。在这里,速度与偏差之间的权衡变得无可否认地清晰。
研究人员使用了拉丁方设计 (Latin Square design) ,这意味着每位专家既作为对照组 (处理一份文档) ,也作为实验组 (处理另一份文档) 。这确保了表现上的差异是由于 AI 辅助造成的,而非个别专家的技能差异。
专家们使用自定义界面 (Label Studio) 为段落分配主题。实验组看到了 LLM 预先高亮的建议,他们可以选择接受、拒绝或修改。

效率大爆发
首先,对于 AI 倡导者来说有个好消息: 效率提升巨大。
当没有 AI 辅助 (对照组) 时,专家的平均标注速度为每分钟 96.4 个词 。 当有 LLM 辅助 (实验组) 时,速度跃升至每分钟 225.0 个词 。

如表 5 所示,这是133.5% 的速度提升 。 在职业环境中,这种差异是变革性的。它能将为期一周的分析项目变成两天的任务。
隐性成本: 锚定偏差
然而,改变的不仅仅是速度。研究人员使用科恩卡帕系数 (Cohen’s Kappa, \(\kappa\)) ——一种衡量标注者间一致性的统计指标——分析了人类与 LLM 之间的一致性水平。
逻辑如下: 如果人类真的是独立的,无论是否看到建议,他们与 LLM 的一致性应该大致相同。如果仅仅因为看到了建议,他们就更多地同意 LLM,那就是偏差的证据。
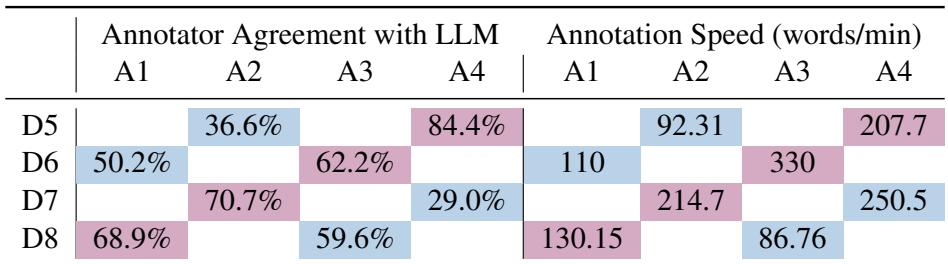
表 6 展示了该研究的“确凿证据”。
请看“标注者与 LLM 的一致性 (Annotator Agreement with LLM) ”下的列。
- 对照组 (蓝色) : 当专家独自工作时,他们与 LLM “基准”的一致性相对较低 (例如,A2 在 D5 上为 36.6%) 。这表明他们独立的专家判断经常与 AI 的逻辑不同。
- 实验组 (粉色) : 当同样的专家看到 LLM 的建议时,他们的一致性飙升 (例如,A4 在 D5 上为 84.4%) 。
统计分析证实这是非随机的 (\(p < 0.001\)) 。专家们不仅仅是变快了;他们正在积极改变自己的决定以与 AI 保持一致。
“大声思维”的记录支持了这一点。在对照组设置中,专家们纠结于艰难的决定,争论一段话是关于“隐私”还是“监控”。在实验组中,专家们通常看一眼建议,觉得“足够好”,然后继续。批判性思维的摩擦被消除,取而代之的是验证的便捷。
问卷结果: 信任 vs. 现实
最后,研究人员在研究前后对专家进行了问卷调查,以评估他们对这项技术的看法。
有趣的是,尽管第一阶段展示了偏差和主题遗漏,专家们对这次合作仍持非常积极的看法。

如分析后问卷 (表 8) 所示:
- 100% 的参与者更倾向于使用 LLM 推荐来完成任务。
- 100% 的人认为将其集成到工作流中“非常容易”。
- 大多数人将体验评价为“好”。
这突显了一种危险的脱节。用户感觉更高效、更满意,但他们没有意识到自己的决策过程在多大程度上已经被机器改变或“锚定”了。他们将该工具视为有益的助手,却没有意识到它实际上正在有效地掌舵。
结论: 权衡与取舍
这篇论文为许多人怀疑的一种现象提供了关键的实证证据。“LLM 效应”是真实的。
- 效率不可否认: 使用 LLM 使专家分析的速度提高了一倍以上。
- 偏差不可避免: 在专家思考之前向其展示答案,会从根本上改变他们的答案。
- 细微差别丢失: LLM 为了宽泛、概括性的主题,抹平了罕见但关键的细节 (如“治安与监控”) 。
这对学生和专业人士的启示是重大的。如果你使用 LLM 来总结论文、分析数据或编写代码,你的工作速度可能会快得多。但也很有可能你会收敛到模型所代表的“平均”观点,从而可能错过高水平研究中往往最重要的那些特异、离群的见解。
作者的结论是,虽然我们不应抛弃这些工具,但我们需要设计更好的工作流——也许是“人类优先”的系统,即在 AI 填补空白之前由专家建立框架——以确保我们在获得引擎速度的同时,不会失去专家的掌控力。