](https://deep-paper.org/en/paper/2410.05235/images/cover.png)
想象一下你是一名繁忙急诊室里的住院医师。你检查了一位病人,查看了他们的生命体征,然后转向你的主治医师给出了诊断。“是肺炎,”你说。主治医师看着你,问出了医学教育中最令人恐惧的问题: “为什么?”
仅仅答对是不够的。在医学中,推理过程——即将症状与诊断联系起来的证据链——与结论本身同样重要。
这种“可解释性差距”是目前人工智能面临的最大障碍之一。虽然像 GPT-4 或 Med-PaLM 这样的大型语言模型 (LLM) 在行医执照考试中取得了优异的成绩,但它们通常像“黑盒”一样运作。它们给出答案,却难以提供结构化、合乎逻辑的论证来解释为什么这个答案是正确的,以及至关重要的是,为什么其他看似合理的选项是错误的。
在这篇文章中,我们将深入探讨 CasiMedicos-Arg , 这是一篇介绍全新多语言数据集的研究论文,旨在解决这个问题。研究人员创建了一种资源,不仅教 AI 回答医学问题,还要教它使用与人类医生相同的结构逻辑来进行辩论。
问题所在: 缺乏解释的准确性
人们对医学问答 (Medical Question Answering, QA) 的兴趣呈现爆炸式增长。像 MedQA 和 PubMedQA 这样的基准测试推动了模型的发展,使其能够在多项选择题上达到专家级的准确率。
然而,现有的研究存在两个主要缺陷:
- 缺乏论证 (Lack of Argumentation) : 大多数数据集侧重于选择正确的选项 (A、B、C 或 D) 。很少有数据集包含详细的自然语言解释,而且几乎没有任何数据集将这些解释分解为结构化的论证 (主张、前提、支持和攻击) 。
- 语言障碍 (The Language Barrier) : 绝大多数医学 AI 基准测试都是英语的。这限制了在主要语言为法语、西班牙语或意大利语的全球医疗环境中测试和部署这些强大工具的能力。
CasiMedicos-Arg 论文正面解决了这两个问题。它提出了第一个多语言数据集 (英语、法语、意大利语、西班牙语) ,其中的临床病例通过人工标注的解释进行了丰富,展示了医生是如何思考的。
基础: 什么是解释性论证?
要理解这篇论文的贡献,我们首先需要理解研究人员如何定义“论证”。他们不只是让医生写段落;他们根据论证理论将这些段落分解为特定的组成部分。
当医生解释一个病例时,他们本质上是在为某种特定的疾病建立一个“法律案件”。研究人员使用以下结构对文本进行了标注:
- 主张 (Claim) : 结论性的陈述。 (例如: “该患者推测患有结节性红斑。”)
- 前提 (Premise) : 支持或攻击主张的观察事实或证据。 (例如: “患者发烧 39°C。”)
- 关系 (Relations) :
- 支持 (Support) : 证明主张为真的前提。
- 攻击 (Attack) : 证明主张 (或错误答案) 为假的前提。
这种结构使 AI 能够学习到: 症状 X 支持诊断 Y,而症状 Z 攻击诊断 W。
构建数据集: 人工的努力
研究人员从 CasiMedicos 语料库入手,这是来自西班牙住院医师实习 (MIR) 考试的临床病例集。这些病例的独特之处在于,它们包含由志愿医生撰写的金标准解释。
团队选取了其中 558 个临床病例,并进行了严格的人工标注过程。这不仅仅是简单的关键词搜索;人类标注员阅读了医生的解释,并标记了每个句子以识别论证结构。
数据规模
为了让你对规模有个概念,让我们看看病例中标签的分布情况。
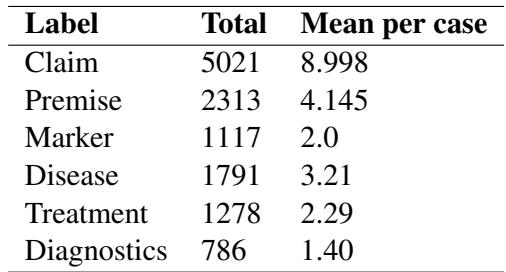
如表 3 所示,该数据集包含超过 5,000 个主张 (Claims) 和 2,300 个前提 (Premises) 。你可能会注意到表中一个有趣的现象: 主张的数量远多于前提。
为什么?在医学推理中,医生经常基于通用医学知识 (在这个模式中算作“主张”) 做出陈述,而不是重述病人病例中的具体事实 (前提) 。例如,医生可能会说*“这种疾病通常影响 30 岁以下的女性”* (基于知识的主张) 来支持他们的诊断,而不是明确重复*“该患者是一名 30 岁以下的女性”* (前提) 。
支持与攻击的逻辑
该数据集最有价值的方面之一是它教 AI 如何排除某些情况,而不仅仅是确认某些情况。
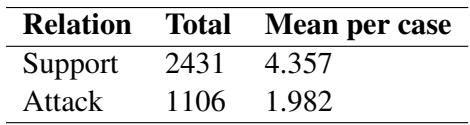
表 5 展示了论证关系。虽然支持 (Support) 关系最为常见 (2,431 个实例) ,但也存在大量的攻击 (Attack) 关系 (1,106 个) 。
这对于医疗安全至关重要。一个可靠的 AI 助手不应该只告诉医生“这是流感”。它应该能够说: “这很可能是流感,因为发烧 (支持) ,而且我们可以排除细菌性脑膜炎,因为没有颈部僵硬的症状 (攻击) 。”
确保质量
标注主观解释是很困难的。为了确保数据可靠,研究人员测量了标注者间一致性 (Inter-Annotator Agreement, IAA) ——也就是两名不同的人类在标签上达成一致的频率。
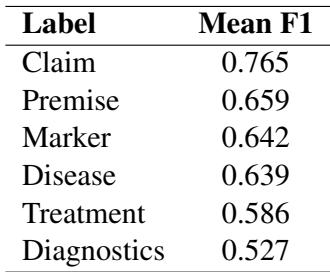
表 1 显示了不同组件的一致性分数 (F1) 。对于主张 (Claims) 来说,0.765 的分数在这类复杂的语言任务中相当高,这表明“医学主张”的定义是一致且可学习的。
走向多语言: 投影方法
这篇论文最突出的特点之一是其多语言能力。最初的解释是西班牙语,后来被翻译成英语、法语和意大利语。然而,如果从头开始为所有四种语言人工标注论证结构,成本将极其高昂且耗时。
研究人员使用了一种聪明的技术,称为标签投影 (Label Projection) 。
- 源标注: 他们在英语版本上完成了繁重的工作 (人工标注主张/前提) 。
- 对齐: 他们使用自动化工具将英语文本中的单词与西班牙语、法语和意大利语中的对应单词进行对齐。
- 投影: 标签被自动“投影”到其他语言上。
- 修正: 关键在于,他们没有盲目信任自动化。他们执行了人工后处理步骤来修正错误 (如缺失的冠词或未对齐的跨度) 。
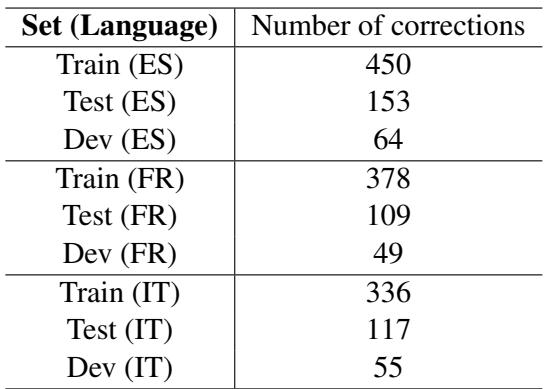
表 8 强调了这种验证所涉及的努力。“训练集 (ES)” (西班牙语) 需要 450 次修正。这种混合方法——自动化后跟人工验证——使他们能够创建一个高质量的四语言数据集,而工作量仅为全人工标注的一小部分。
实验: AI 能检测到论证吗?
建立数据集后,研究人员进入了实验阶段。任务是论证成分检测 (Argument Component Detection) : 我们能否将医学解释输入 AI 模型,并让它正确地高亮显示主张和前提?
他们测试了几种类型的大型语言模型:
- 编码器模型 (Encoder Models) : BERT 和 DeBERTa (传统的擅长分类的模型) 。
- 编码器-解码器模型 (Encoder-Decoder Models) : Medical mT5 (专门在医学文本上训练) 。
- 仅解码器 (生成式) 模型 (Decoder-only Models) : LLaMA-2 和 Mistral (现代风格的 LLM) 。
“数据迁移”策略
研究人员比较了不同的训练策略。最成功的方法是多语言数据迁移 (Multilingual Data-Transfer) 。 他们没有只在西班牙语数据上训练来测试西班牙语,而是将所有四种语言的训练数据汇集在一起。
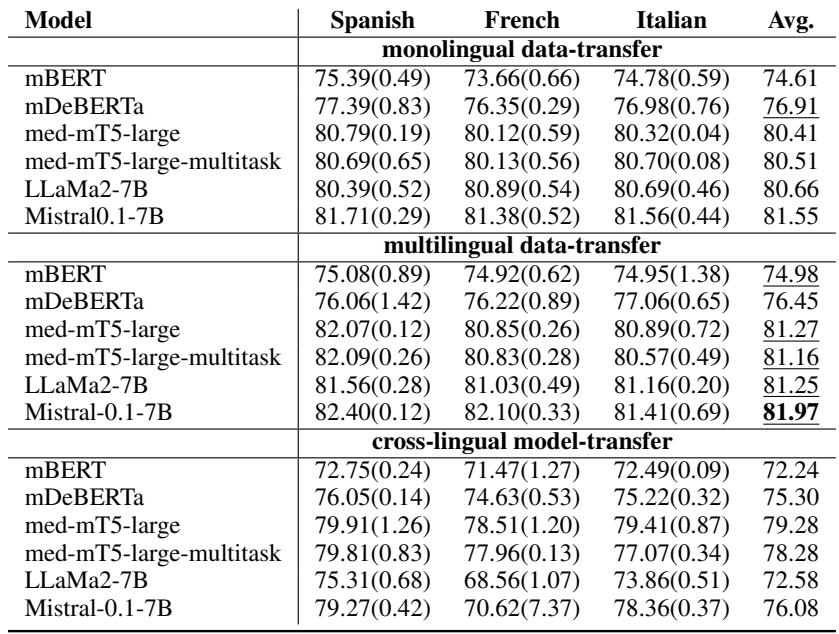
表 7 提供了令人着迷的结果。以下是关键要点:
- 数据越多越好: 标记为“multilingual data-transfer” (多语言数据迁移) 的行几乎总是优于单语设置。通过接触意大利语和英语的医学论证示例,模型在识别西班牙语论证方面变得更强。
- 生成式模型大放异彩: Mistral-0.1-7B 模型在各项指标上都取得了最高分 (F1 分数约为 81-82%) 。这值得注意,因为序列标注 (高亮文本) 传统上是像 BERT 这样的编码器模型的领域。这表明现代生成式 LLM 在结构化任务方面正变得惊人地娴熟。
- 医学专业化很重要: Medical mT5 模型 (专门针对医学进行适配) 表现非常有竞争力,在多种设置下击败了通用的 LLaMA-2。
为什么这很重要
CasiMedicos-Arg 的创建之所以是向前迈出的重要一步,主要有两个原因:
1. 医学领域的可解释人工智能 (XAI): 我们正在超越仅仅满足于基准测试高准确率的时代。为了让 AI 在医院中获得信任,它需要“展示其推导过程”。通过在该数据集上训练模型,开发人员可以创建这样的系统: 它不仅能输出正确的诊断,还能高亮显示病历中支持该诊断的具体证据,同时标记出与其他可能性相矛盾的证据。
2. 多语言公平性: 医学知识不应被锁在语言障碍之后。通过证明多语言数据迁移行之有效,这篇论文为如何改善代表性不足语言的医学 AI 提供了蓝图。只要对齐处理得当,在英语数据上训练模型实际上可以帮助它在意大利语或西班牙语中表现得更好。
结论
CasiMedicos-Arg 论文提高了医学 QA 的标准。它提醒我们,在高风险的医学领域,论证与答案同样重要。
研究人员为社区提供了一个强大的多语言数据集,捕捉了临床推理的细微差别。他们证明了将人类专业知识与自动投影技术相结合是创建多语言资源的可行途径。最后,他们展示了现代 LLM,特别是在多样化的多语言数据上训练时,有能力理解医学论证的复杂结构。
随着这些模型的不断进化,我们可以期待 AI 助手不仅仅充当搜索引擎,还能作为推理伙伴,帮助医生用任何语言思考复杂的病例。