](https://deep-paper.org/en/paper/2410.05603/images/cover.png)
人们通常将大型语言模型 (LLM) 概念化为“多重宇宙生成器”。当你要求模型补全一个句子时,它不仅是在预测特定叙事中的下一个词;实际上,它是在无数种可能的续写路径中权衡概率。
但是,如果提示词 (prompt) 本身就是模棱两可的呢?如果提供给模型的上下文包含混合在一起的两个完全不同任务的例子,会发生什么?模型会感到困惑吗?它会随意选择一条路径并坚持下去吗?
来自威斯康星大学麦迪逊分校、密歇根大学和微软研究院的最新研究揭示了一个迷人的现象: 任务叠加 (Task Superposition) 。
在一篇题为*《瞬息全宇宙》 (Everything Everywhere All At Once) *的论文中,研究人员证明了 LLM 并不是简单地通过抛硬币来决定执行哪个任务。相反,它们在单次推理调用中同时执行多个、计算上截然不同的任务。这就好比模型处于一种意图的量子叠加态,同时计算翻译、算术和格式化任务的正确答案,并根据提供的上下文对它们进行加权。
在这篇深度文章中,我们将探索这一惊人的能力、其背后的机制 (包括“任务向量”) ,以及它向我们揭示了 Transformer 架构的哪些基本本质。
任务叠加现象
要理解任务叠加,我们首先需要了解上下文学习 (In-Context Learning, ICL) 。 ICL 指的是模型仅通过在提示词中查看几个示例就能学习新任务的能力,而无需任何参数更新。
通常,我们假设提示词定义了一个单一的任务。例如:
- Prompt: “English: Hello, Spanish: Hola. English: Dog, Spanish: Perro. English: Cat, Spanish: …”
- Task: 翻译成西班牙语。
但是,考虑一个混合了示例的提示词。如果我们给模型一些数字相加的例子,同时也给一些将数字翻译成法语的例子,会怎样?

如上图 Figure 1 所示,研究人员构建了包含混合任务的提示词。
- 左图 (Figure 1a): 提示词包含算术示例 (“91 + 83”) ,但答案格式各不相同 (数字、英文单词、法文单词、西班牙文单词) 。
- 右图 (Figure 1b): 提示词混合了“复制第一个数字”和“将两个数字相加”等任务。
当研究人员向模型提问 (例如,“91 + 83 ->”) 时,他们不仅仅关注生成的单一文本输出。他们观察的是下一个 token 的概率分布 。
结果令人震惊。模型为上下文中存在的所有任务对应的有效答案都分配了显著的概率质量。它并没有只选择“法语”或“数字”,而是同时为两者准备了有效的答案。
模拟器视角
这与将 LLM 视为“模拟器的叠加”的观点一致。如果我们把 LLM 看作一个贝叶斯推理引擎,它试图根据提示词推断潜变量——即“任务”。如果提示词有歧义 (包含任务 A 和任务 B 的例子) ,模型会构建一个概率分布,该分布是这两个任务的加权和。
在数学上,研究人员将其概念化为:

这里:
- \(P(output | task, prompt)\) 是如果模型严格执行某一特定任务时,得出某个答案的可能性。
- \(P(task | prompt)\) 是模型根据上下文中的示例混合情况,对该任务可能性的估计。
实证证据: 这绝非巧合
这种行为并不局限于特定模型或特定类型的任务。研究人员在 GPT-3.5、Llama-3 70B 和 Qwen-1.5 72B 上进行了测试,涵盖了四种截然不同的实验设置:
- 多语言加法: 数字加法 vs. 英语、法语或西班牙语的加法。
- 地理知识: 命名首都 vs. 命名大洲 vs. 大写国家名称。
- 算术逻辑: 复制操作数 vs. 相加操作数。
- 字符串操作: 首字母 vs. 尾字母,大写 vs. 小写。
在每种情况下,他们都向模型输入包含 20 个上下文示例的提示词,并随机打乱顺序以包含不同比例的任务混合。
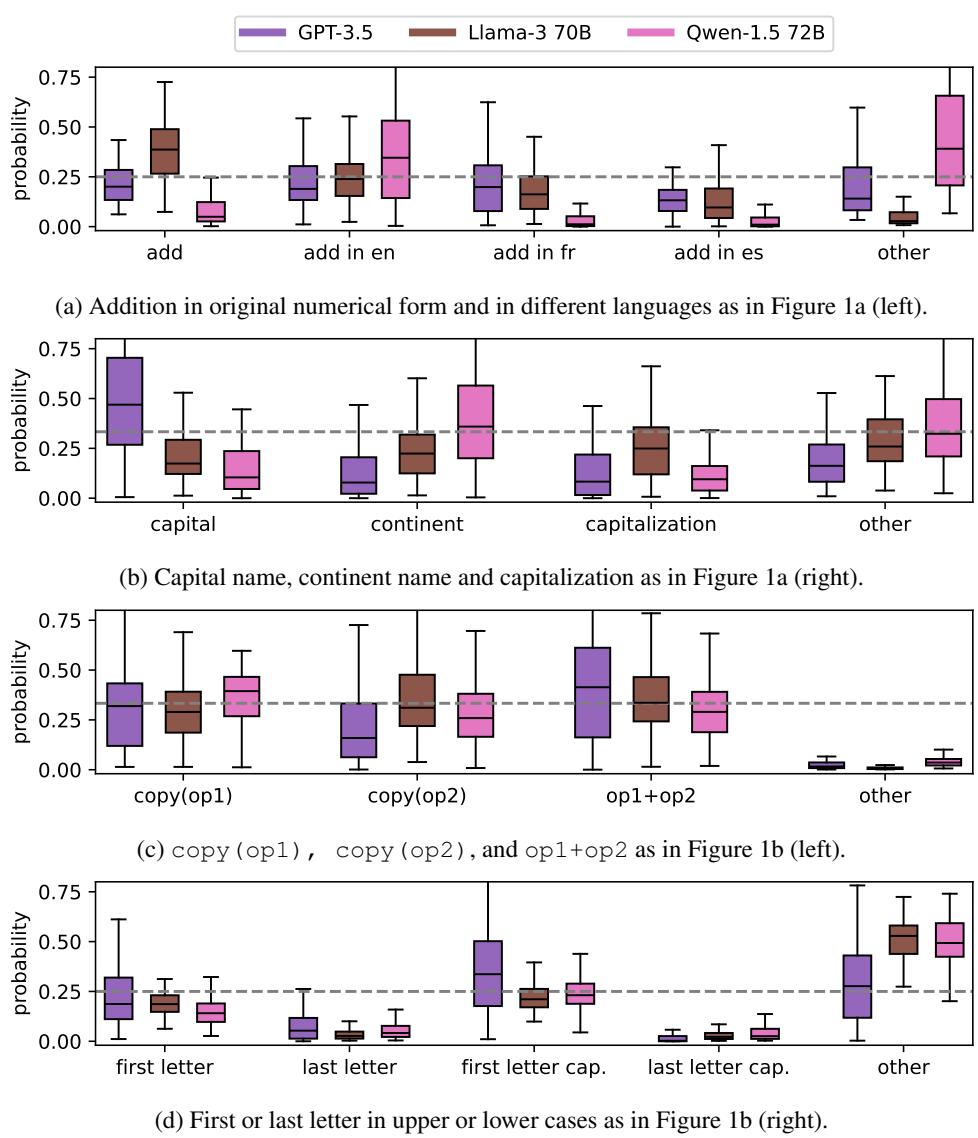
Figure 2 展示了结果。Y 轴代表分配给特定任务正确答案的概率。
- 在 Figure 2a (加法) 中,Llama-3 (棕色) 同时为数字加法 (“add”) 和基于语言的加法 (“add in en/fr/es”) 分配了概率。
- 在 Figure 2b (地理) 中,GPT-3.5 (紫色) 将其概率质量分散在命名首都和命名大洲之间。
至关重要的是,模型并没有完全平均地分配这些概率。它们存在偏好——有些偏好英语,有些偏好数字答案——但多个不同任务的中位概率是不可忽略的 。 这证实了模型正在并行运行这些过程。
涌现: 能否从头学习叠加?
怀疑论者可能会争辩: “这些巨大的模型 (GPT-4, Llama-3) 已经在互联网上阅遍万物。也许它们只是记住了混合数据?”
为了测试叠加是否是 Transformer 架构的基本属性,而不仅仅是海量数据的产物,研究人员进行了一项对照实验。他们从头开始训练了一个小型的 GPT-2 模型 (86M 参数) 。
训练设置
他们创建了一个包含不同任务的合成数据集:
- 检索: 给定一个 8 字符的字符串,检索第 1 个、第 2 个…或第 8 个字符。
- 算术: 给定一个数字,加 0,加 1,…或加 9。
关键在于,该模型被训练为一次只学习一个任务。 在训练期间,每个提示词都只包含来自一个特定任务的示例 (例如,只有“检索第 3 个字符”) 。模型在训练中从未见过混合任务。
测试
在推理时,他们向模型展示了示例的混合体 (例如,50% 的“检索第 2 个字符”和 50% 的“检索第 6 个字符”) 。
如果模型只是学会了将提示词分类到单一桶中,它应该会失败或随机选择一个。相反,该模型表现出了完美的叠加。
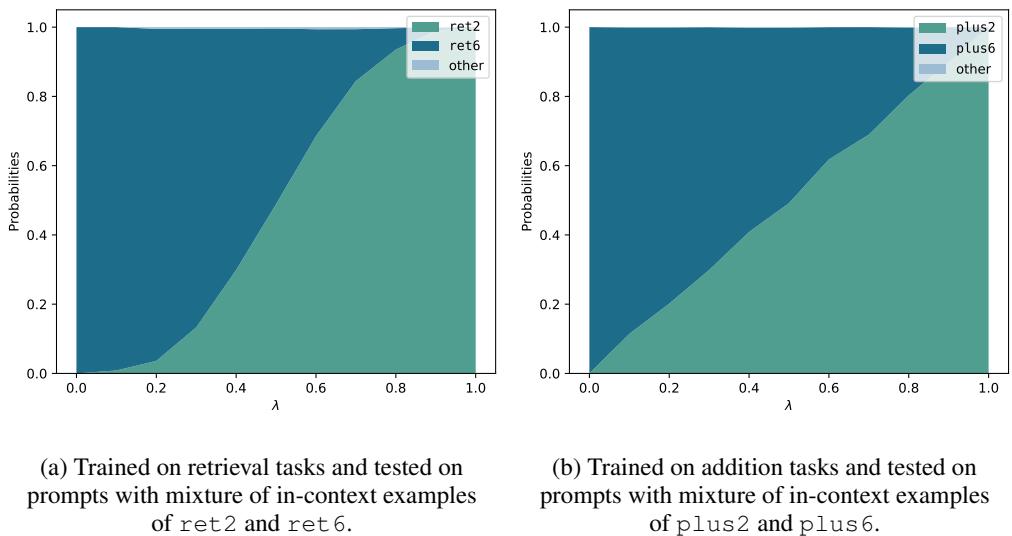
Figure 3 说明了这种涌现行为。
- X 轴 (\(\lambda\)) 代表提示词中任务 A 示例的比例。
- Y 轴是输出匹配任务 A (青色) 或任务 B (深蓝色) 的概率。
随着示例混合比例从 0% 变为 100%,模型的输出概率平滑且线性地发生了转移。在 \(\lambda = 0.5\) (50/50 混合) 时,模型为两个答案分配了大致相等的概率。
发现: 即使从未在混合任务上进行过训练,Transformer 也能学会执行任务叠加。这是该架构聚合上下文的一种固有能力。
机制: 任务向量
模型实际上是如何做到这一点的?它是为每个任务启动了单独的电路吗?
研究人员使用任务向量 (Task Vectors) 分析了模型的内部状态。任务向量是模型激活空间 (特别是多头注意力层) 中的一个方向,编码了特定的能力。先前的研究表明,向模型添加“法语任务向量”可以让它说法语。
研究人员提取了单一任务的任务向量 (例如,“翻译成法语”的向量和“翻译成德语”的向量) 。然后,他们观察了当模型处理混合提示词时产生的向量。
向量几何
他们使用线性判别分析 (LDA) 将这些高维向量投影到二维平面上。
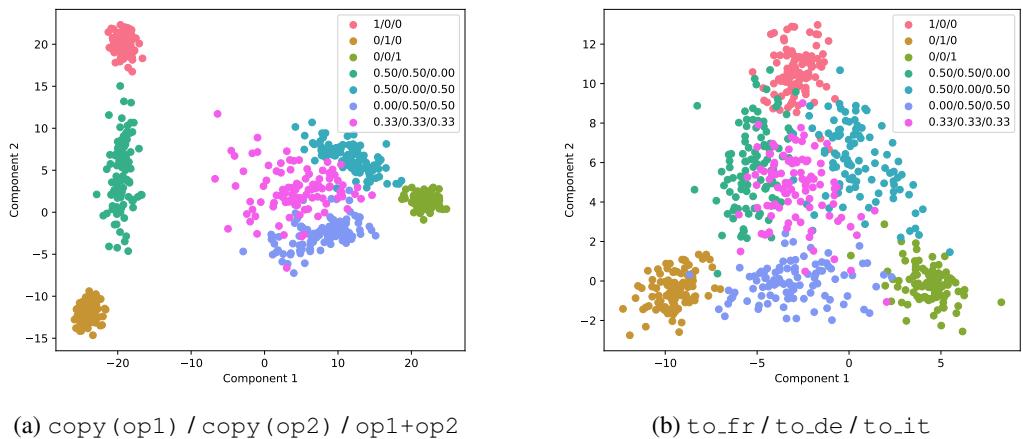
Figure 4 可视化了这些向量。三角形的角 (粉色、棕色、绿色) 代表纯任务。中间的点 (青色、蓝色、品红) 代表混合提示词。
- 结果: 混合任务的向量在几何上位于单一任务向量之间。
- 如果你用 50% 任务 A 和 50% 任务 B 提示模型,由此产生的内部状态非常接近向量 A 和向量 B 的数学平均值。
用数学“破解”模型
这种几何关系意味着我们甚至可能不需要提示词。我们能不能仅通过在内部神经元上做数学运算来强迫模型进入叠加状态?
研究人员通过手动构建任务向量来测试这一点,他们使用了两个单任务向量的凸组合 (加权和) :
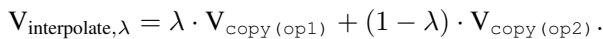
他们将这个人造向量“修补” (patch) 到 Llama-3 中,并将结果与使用混合示例提示模型的结果进行了比较。
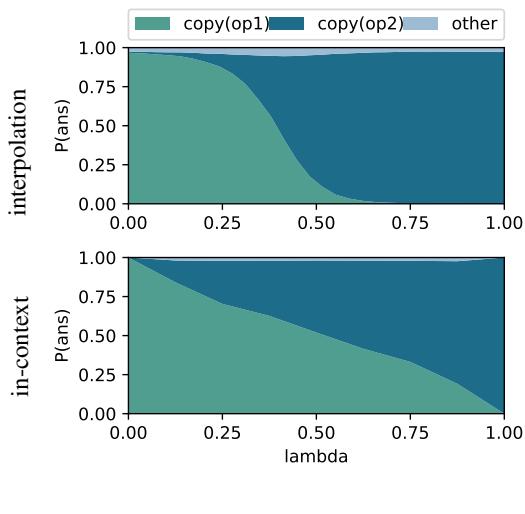
Figure 5 展示了对比结果。
- 上排 (插值): 数学混合向量产生的输出概率。
- 下排 (上下文): 混合提示词示例产生的输出概率。
虽然不完全相同,但趋势惊人地相似。只需将“翻译成德语”的向量加到“翻译成意大利语”的向量上,模型就开始同时输出两种语言的概率。这表明任务向量的线性组合是 LLM 实现叠加的主要机制。
理论证明: Transformer 的容量
研究人员并未止步于经验观察。他们提供了一个理论构造,证明了标准的 Transformer 架构具有足够的表达能力来执行这种叠加。
他们证明了定理 1 : 一个七层的 Transformer 可以在叠加态中执行 K 个任务。
该构造涉及特定的架构逻辑:
- 任务识别: 模型使用早期层将输入示例 \((x, y)\) 与其内部函数库进行比较。它计算函数预测值与实际标签 \(y\) 之间的误差 (差异) 。
- 指示向量: 如果误差接近零,模型会生成一个“标志” (指示向量) ,表示“此示例匹配任务 A”。
- 加权: 模型对上下文中所有示例的这些标志进行平均。如果 70% 的示例匹配任务 A,则任务 A 的权重变为 0.7。
- 叠加: 在最后几层中,模型在并行注意力头中执行所有任务。最终输出是这些头输出的总和,并由计算出的比例进行加权。
下面的矩阵可视化了该理论构造中的一个步骤,其中模型计算实际标签 \(y^{(j)}\) 和预测标签 \(g(x^{(j)})\) 之间的差异以识别任务:

这个理论框架证实,在 GPT-4 和 Llama-3 中观察到的现象并非魔法;这是注意力机制在数学上可证明的能力。
缩放定律: 越大越好
最后,论文探讨了模型规模如何影响这一能力。他们比较了 Qwen-1.5 系列中从 5 亿到 140 亿参数不等的模型。
他们测量了两个指标:
- \(r\) (完成的任务数): 在 Top-K 概率输出中出现了多少个不同的任务?
- KL 散度: 模型的输出概率与输入混合的匹配程度如何? (例如,如果提示词是 25% 的任务 A,输出概率也是 25% 吗?)
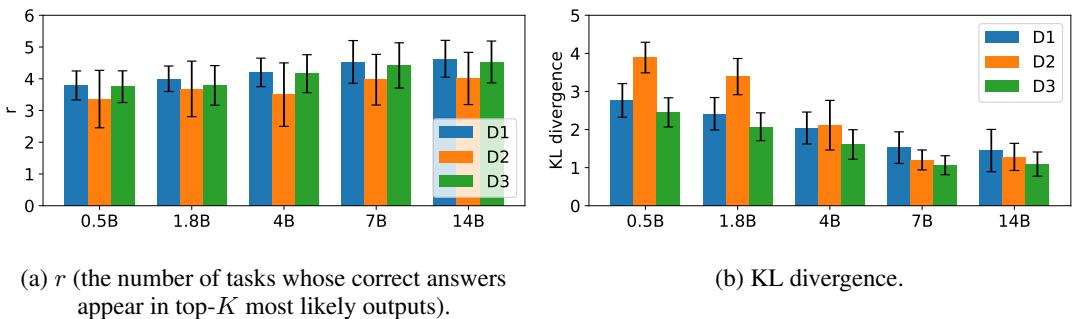
如 Figure 6 所示:
- 左图 (a): 模型可以在叠加态中维持的任务数量 (\(r\)) 随着模型规模的增加而增加。
- 右图 (b): KL 散度随着规模增加而减小 (越低越好) 。
启示: 更大的模型不仅更擅长解决难题;它们更擅长同时维持多个相互竞争的假设。它们是更好的模拟器。
结论与“生成坍缩”
这项研究从根本上改变了我们对 LLM “推理”步骤的看法。我们通常认为模型是先做出决定然后生成文本。实际上,在处理提示词的过程中,模型是“瞬息全宇宙”的——它正在计算它在上下文中识别出的每一个相关任务的结果。
然而,这里有一个限制: 生成坍缩 (Generation Collapse) 。 虽然模型计算了多个任务的概率,但它通常只能输出一个文本序列。一旦它选择了第一个 token (例如,总和的第一位数字) ,下一个 token 的上下文就会发生变化,叠加态就会坍缩成一个单一的特定任务。
作者建议,未来的解码算法可以利用这一点。想象一下“叠加解码 (Superposed Decoding) ”,模型可以通过保持叠加态,仅通过一次传递就输出多路答案流 (翻译、摘要和代码) 。
对于 AI 领域的学生来说,这篇论文突显了高维潜空间的力量。事实证明,在 4000 维的空间中,你不必在任务 A 和任务 B 之间做选择。你可以直接选择它们之间的空间。