](https://deep-paper.org/en/paper/2410.05725/images/cover.png)
引言
像 GPT-4 和 Llama 这样的大型语言模型 (LLM) 的兴起彻底改变了我们与技术交互的方式。从编写代码到总结法律文件,这些模型似乎无所不能。然而,对于处理高度敏感信息的行业——如医疗保健和金融——使用这些强大的工具面临着巨大的困境。
医院希望利用病历记录训练模型来辅助医生,银行希望分析交易历史来检测欺诈。但这些数据是严格保密的。你不能简单地将患者历史记录上传到公共 API,否则会违反隐私法律 (如 HIPAA 或 GDPR) 并面临数据泄露的风险。
这就造成了实用性 (让模型变聪明) 与隐私 (保证数据安全) 之间的根本性矛盾。
目前,从业者通常只能在两条有缺陷的路径中二选一:
- 基于 API 的方法: 使用强大的外部 API (如 OpenAI) 生成合成训练数据。虽然这能产生高质量的文本,但需要将隐私数据发送到第三方服务器,从而产生隐私风险。
- 本地模型方法: 使用较小的本地模型在内部处理所有事务。虽然这确保了隐私,但这些较小的模型往往缺乏生成高质量数据的智能,导致性能不佳。
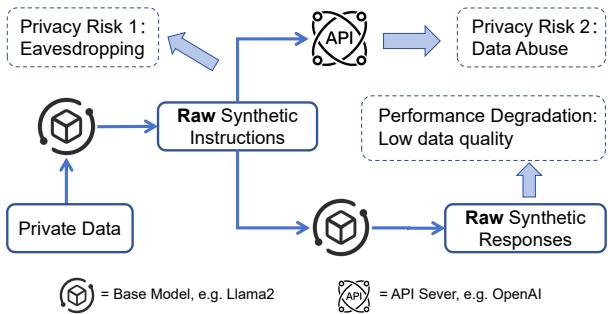
如上图所示,我们要么被迫冒险泄露数据隐私 (窃听/数据滥用) ,要么被迫接受一个“愚笨”的模型 (性能下降) 。
在这篇文章中,我们将深入探讨一种名为 KnowledgeSG (基于知识的合成数据生成) 的新框架。这一方法由浙江大学和上海交通大学的研究人员提出,它提供了一个巧妙的第三种选择: 一种客户端-服务器架构,允许本地模型从强大的服务器端“专业”模型中学习,而无需暴露原始隐私数据。
背景: 隐私与实用性的差距
在了解解决方案之前,我们需要明白为什么这个问题如此难以解决。
记忆化 (Memorization) 的风险
LLM 本质上是巨大的模式匹配机器。如果你用包含“张三的诊断是 2 型糖尿病”这样的句子训练 LLM,模型可能会记住这一事实。之后,如果用户提示模型“张三的诊断是什么?”,模型可能会复述出这一隐私信息。这就是所谓的记忆化 。
为了对抗这种情况,研究人员通常使用差分隐私 (Differential Privacy, DP) 。 简单来说,DP 会在训练过程中加入数学“噪声”。它确保模型学习一般的模式 (例如,“症状 X 和 Y 通常意味着诊断 Z”) ,而不会学习任何个人的具体细节。
“幼儿园学生 vs 博士生”的问题
为什么不直接在本地训练一个小的、保护隐私的模型呢?问题在于能力。特定领域的数据 (如病历) 非常复杂。
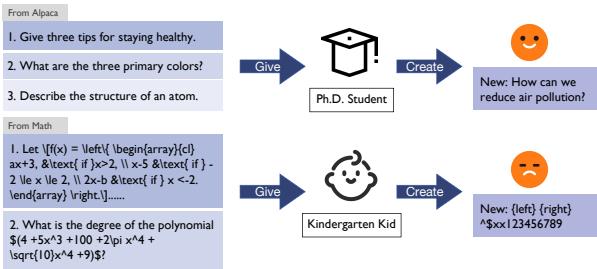
如上面的类比所示,要求一个通用的本地小模型生成合成医疗数据,就像要求一个幼儿园学生写微积分试卷一样。他们可能会模仿格式,但内容将是一派胡言。一个“博士生” (一个大型的专业模型) 可以轻松做到这一点,但这种模型通常运行在云服务器上,我们不能用隐私数据去访问它。
核心方法: KnowledgeSG
研究人员提出了 KnowledgeSG 框架来弥补这一差距。它从联邦学习中汲取灵感——即把模型移动到数据所在的地方,而不是把数据移动到模型所在的地方。
目标是生成一个高质量的合成数据集 , 该数据集能捕捉到隐私数据中的有用模式,但不包含任何敏感信息 (个人身份信息,PII) 。然后,这个合成数据可以安全地用于训练强大的模型。
系统架构
该过程分为两个不同的环境: 客户端 (隐私数据所在的地方) 和服务器 (强大的“专业”模型所在的地方) 。
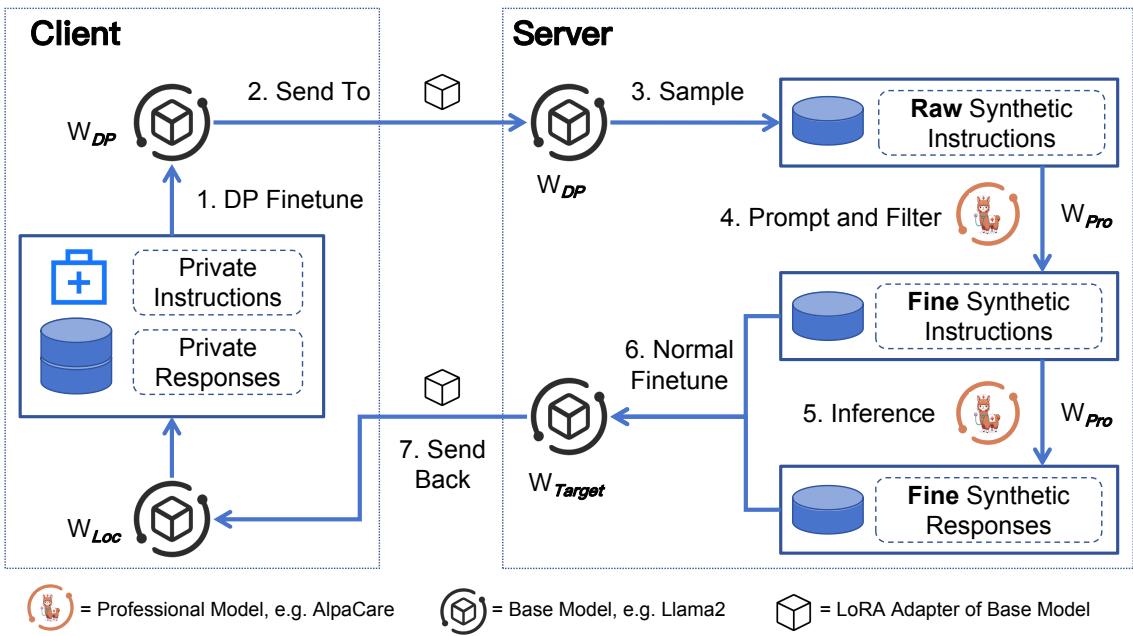
让我们一步步分解上图所示的工作流程。
第一步: 客户端学习 (DP 微调)
在客户端 (安全环境) ,我们从一个本地基座模型 (\(\mathbb{W}_{Loc}\)) 开始,例如 Llama-2-7B。我们在隐私数据 (\(\mathbb{D}_{Pri}\)) 上对该模型进行微调。
关键在于,这种微调使用了差分隐私 (DP-SGD) 。 这意味着模型学习了隐私数据的“形态”和主题 (例如,医患对话的结构) ,但在数学上被阻止了记忆具体姓名或敏感细节。
第二步: 高效传输 (LoRA)
微调整个 LLM 非常繁重,而且通过互联网发送巨大的模型也很慢。为了解决这个问题,研究人员使用了 LoRA (低秩自适应) 。 LoRA 冻结主模型,只训练一个微小的“适配器 (adapter) ”层。
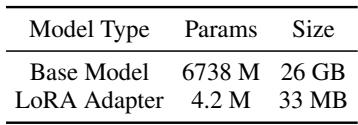
如表 1 所示,差异是惊人的。客户端不需要发送 26 GB 的模型,只需发送 33 MB 的适配器。这使得通信非常快速且高效。
第三步: 服务器端生成与过滤
一旦服务器收到受隐私保护的适配器,它将其与自己的基座模型副本结合。现在,服务器拥有了一个“知道”隐私数据长什么样,但没有记忆其秘密的模型。
- 生成: 服务器提示该模型生成“原始合成指令”。这些是类似于用户在隐私数据集中可能提出的问题或提示。
- 过滤: 服务器生成许多指令并进行过滤。它可以使用简单的指标 (如 BLEU 分数) 来确保新指令与现有指令不太相似,或者要求专业模型 (\(\mathbb{W}_{Pro}\)) 判断指令是否与特定领域相关 (例如,“这是一个有效的医学问题吗?”) 。
第四步: 知识蒸馏 (“老师”介入)
这是 KnowledgeSG 最关键的创新。
本地模型擅长生成问题 (指令) ,因为它见过隐私数据的结构。然而,它可能不擅长生成正确的答案 (回复) ,因为它是一个较小的模型,而且 DP 噪声降低了它的准确性。
为了解决这个问题,该框架利用了驻留在服务器上的专业模型 (\(\mathbb{W}_{Pro}\)) 。这是一个大型专家模型 (如医学领域的 AlpaCare 或金融领域的 FinGPT) 。服务器将合成指令输入专业模型,以生成高质量、准确的回复。
现在我们拥有了一对完美的组合:
- 指令: 源自隐私数据分布 (通过本地模型) 。
- 回复: 源自专家知识 (通过专业模型) 。
第五步: 最终优化与返回
最后,服务器使用这个新的、高质量的合成数据集对本地模型进行最后一次微调 (不使用 DP,因为合成数据已经是安全的) 。这个“目标模型” (\(\mathbb{W}_{Target}\)) 随后被发送回客户端。
现在,客户端拥有了一个表现得像专家并理解其特定领域的模型,而隐私数据从未离开过大楼,服务器也从未见过它。
实验与结果
研究人员在两个高度敏感的领域测试了 KnowledgeSG: 医学和金融 。 他们将该方法与几个基线进行了比较,包括:
- 非隐私 (Non-Private) : 直接在隐私数据上训练 (性能的“非法”上限) 。
- ICL / Self-Instruct: 合成数据生成的标准方法。
- DP-Gene / DP-Instruct: 以前最先进的隐私保护方法。
隐私评估: 重构攻击
最重要的指标是隐私。攻击者能从模型中重构出真实的患者姓名吗?
为了测试这一点,研究人员进行了“重构攻击”。他们掩盖了训练数据中的姓名,并试图强迫模型猜测缺失的姓名。
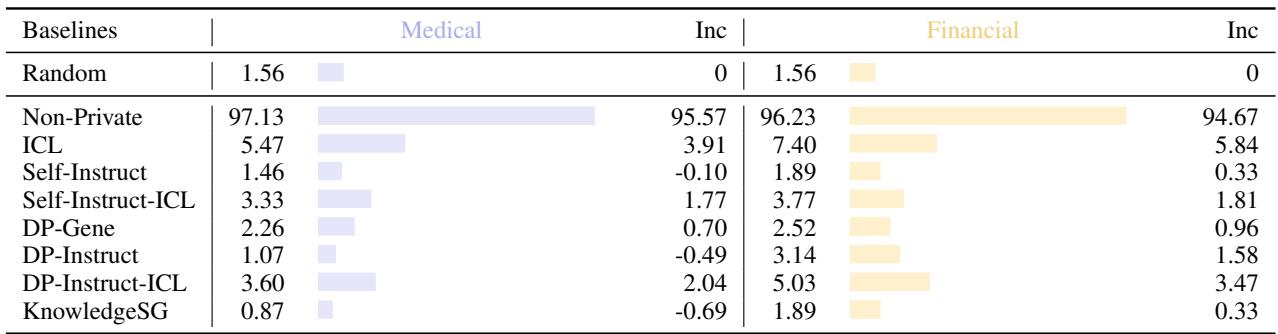
表 2 显示了结果。
- 非隐私训练具有巨大的重构率 (~97%) ,这意味着它几乎记住了每个人的名字。
- KnowledgeSG 在医学领域将其降至 0.87%——基本等同于随机猜测。它提供了顶级的隐私保护,甚至优于其他一些合成数据方法。
性能评估: 模型真的有用吗?
如果模型变得愚笨,隐私也就毫无意义。研究人员评估了模型回答问题和遵循指令的能力。
金融领域
在金融领域,他们测试了模型在情感分析任务 (判断财经新闻是正面还是负面) 上的表现。
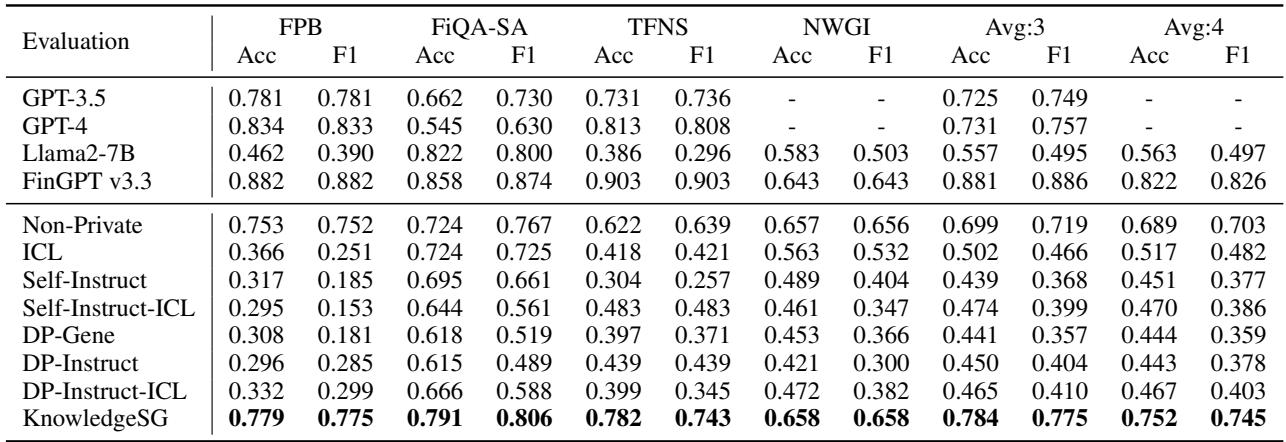
如表 3 所示, KnowledgeSG (最后一行) 在其他隐私基线中占据主导地位。值得注意的是,尽管它是一个受隐私限制训练的小得多的模型,但在几个基准测试中,它甚至达到了与 GPT-3.5 和 GPT-4 相当的性能。
医学领域
在医学领域,准确性关乎生死。研究人员使用了“自由形式评估”,即向模型提出医学问题,并让 GPT-4 判断哪个答案更好 (胜率) 。
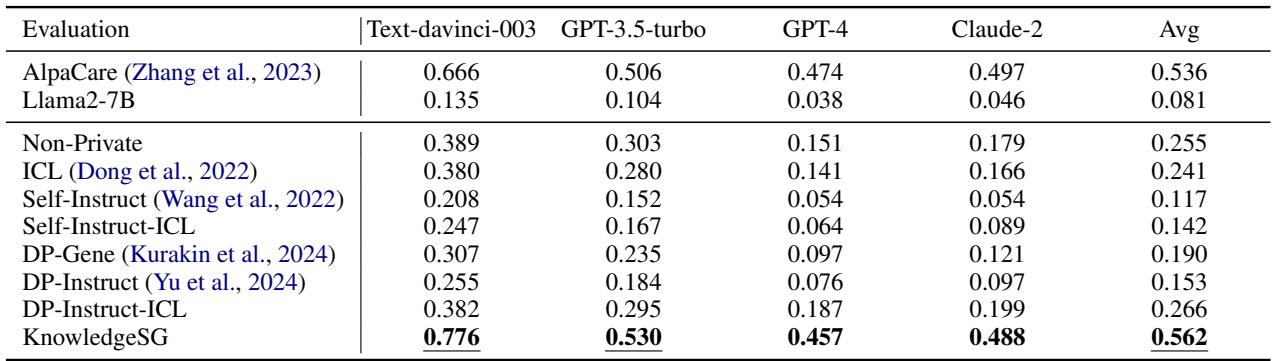
表 4 的结果令人震惊。 KnowledgeSG 取得了 0.562 的胜率,明显高于非隐私方法 (0.255) 。这意味着由服务器端专业模型生成的合成数据实际上比原始、嘈杂的隐私数据更适合用于训练。事实上,在某些指标上,学生 (KnowledgeSG) 甚至超过了老师 (AlpaCare) !
为什么 KnowledgeSG 更好?
研究人员使用称为 IFD (指令遵循难度) 的指标分析了合成数据的质量。分数越低意味着数据越干净,模型越容易学习。
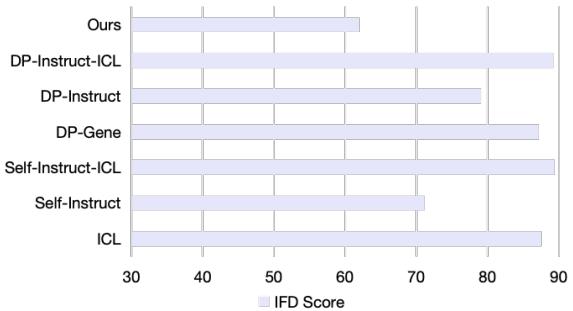
图 3 证实 KnowledgeSG 生成的数据 (标记为“Ours”) 具有最低的 IFD 分数。通过过滤不良指令并使用专业模型编写答案,该框架创建了一个“黄金数据集”,其质量优于本地模型自行生成的数据。
讨论与启示
你可能会想: “为什么不直接用程序查找并删除姓名 (数据清洗/擦除) 呢?”
虽然存在用于擦除个人身份信息 (PII) 的工具,但它们并不完美。

图 4 显示了 PII 可能有多么隐蔽。它不仅仅是“我的名字是 X”。它可能是“亲爱的 Eluned 医生”,或者是医生回复“你好 Elaine”。自动擦除工具经常遗漏这些细微差别 (召回率约为 80-97%) ,留下了危险的漏洞。KnowledgeSG 通过从不对最终模型使用原始文本进行训练,完全避免了这个问题——它只使用从数学权重生成的合成文本进行训练。
结论
KnowledgeSG 代表了隐私保护 AI 的重要一步。它成功解决了必须在隐私和性能之间做出选择的困境。
通过拆分工作负载——让客户端通过受隐私保护的权重提供“本地上下文”,让服务器通过专业模型提供“智能”——我们获得了两全其美的效果。
主要收获:
- 隐私优先: 差分隐私和合成数据生成有效地防止了模型记忆敏感用户数据。
- 服务器端蒸馏: 小型本地模型是不够的。利用服务器上的大型“专业”模型来优化合成数据,可以大幅提升质量。
- 低带宽: 使用 LoRA 适配器允许客户端上传他们的“知识”,而无需上传大量文件或原始数据。
对于进入可信 AI 领域的学生和研究人员来说,KnowledgeSG 突显了一个关键趋势: 未来的方向不仅仅是构建更大的模型,而是构建更智能的架构,使我们能够在现实世界中安全地使用这些模型。