](https://deep-paper.org/en/paper/2410.05975/images/cover.png)
人类拥有一种非凡的能力,仅通过少量示例就能掌握新技能。给一个孩子看一张斑马的图片,他们很可能就能在不同情境下认出其他斑马——即使此前从未见过。这与大多数深度学习模型形成了鲜明对比,后者往往需要成千上万甚至数百万个标注样本才能达到类似的准确率。
这种差距催生了一个人工智能领域——元学习 (meta-learning) ,即“学会学习”。元学习的目标是构建像人类一样的模型,能够从少量示例中泛化并快速适应新任务。传统的元学习遵循一个简单的原则: 即训即测 (train as you test) 。它在训练中模拟新任务上的少样本学习过程,使系统能够学习一种可泛化的策略。
但如果即训即测的思路过于狭窄呢?当一个元学习器在多个任务上训练时——例如一个任务是识别狗的品种,另一个是识别汽车型号——它通常会独立地学习每个任务。而这些任务之间的差异性本身蕴含了宝贵的信息,却往往被忽视。
近期论文 《使用对比元目标学会学习》 (Learning to Learn with Contrastive Meta-Objective) 提出了一个优雅的解决方案。研究人员引入了 ConML , 这是一种框架,通过训练模型掌握两种对人类学习至关重要的认知技能,从而增强元学习能力:
- 对齐 (Alignment) —— 能够识别同一任务的不同视角或数据子集应当产生相似理解的能力。
- 区分 (Discrimination) —— 能够识别不同任务的数据应当导致不同模型与表示的能力。
通过添加一个明确优化这些行为的对比目标 , ConML 系统性地提升了各种元学习算法的性能。它结构紧凑、高效,并具备极强的通用性。
下面我们来看看它是如何运作的。
元学习回顾
假设你希望有一个分类器,它能在每个物种只看到五个样本后就识别新的动物类别——这就是典型的少样本学习问题。
元学习并不直接训练一个分类器,而是训练一个元学习器 : 一种能够生成分类器的算法。元学习器会接触到各个领域的任务——例如花卉识别、车辆识别以及手写体分类等。
每个训练轮次 (episode) 包括:
- 一个支持集 (小型训练集) : 例如每类五张图片;
- 一个查询集 (验证集) : 同类的若干额外样本。
元学习器使用支持集来构建任务特定的模型,并根据该模型在查询集上的表现获得反馈。训练由多个这样的轮次组成,遍及不同任务。随着时间推移,元学习器逐渐形成一种快速适应的内在策略——能够从有限数据中快速学习。
ConML: 模型空间中的对比学习
对比学习革新了无监督表示学习,其核心原理是: 在表示空间中将相似样本 (“正样本对”) 拉近,将不相似样本 (“负样本对”) 推远。ConML 进一步延伸这一理念——将对比学习应用到模型本身 。
关键洞察在于,元学习的轮次训练天生就提供了任务身份这一信息。每个任务自带内在的监督——即两个数据集是否属于同一任务。
ConML 利用这一点,在模型空间中进行对比学习:
- 对齐 (正样本对) : 从同一任务的不同子集学习到的模型表示应当相似。
- 区分 (负样本对) : 从不同任务学习到的模型表示应当彼此区分。
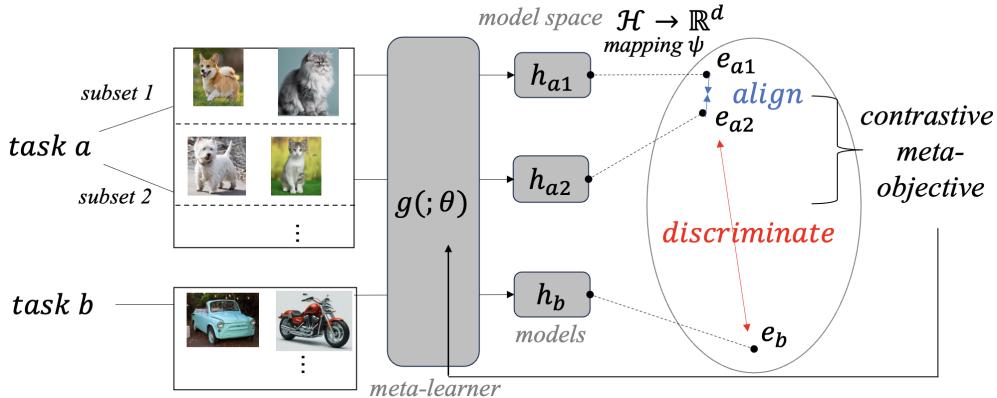
图 1: ConML 在模型表示上执行对比学习——对齐相似的任务子集,同时区分不同的任务。
这种方法使任务身份成为一种额外的监督信号。结果是: 元学习器通过对齐而更稳健地应对噪声子集,并通过区分而更好地泛化到新任务。
构建 ConML 框架
步骤 1. 表示模型
为了比较两个模型,ConML 引入一个投影函数 \( \psi \),将训练好的模型 \( h = g(\mathcal{D}; \theta) \) 映射为定长向量表示 \( e = \psi(h) \)。 这一步确保了它可以兼容任何元学习器架构——这使得 ConML 具备与学习器无关的特性。
步骤 2. 衡量对比目标
每个轮次计算两种距离:
任务内距离 (对齐) : 衡量元学习器在同一任务的不同数据子集上训练时输出的稳定性。最小化此距离可保证任务内部理解的一致性。
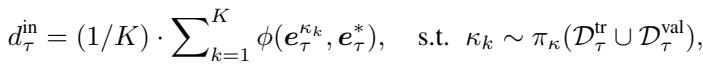
任务间距离 (区分) : 衡量在完全不同任务上训练时输出的差异性。最大化此距离可确保不同任务的模型不会混淆。

步骤 3. 组合损失函数
将对比目标 \( \mathcal{L}_c = d^{in} - d^{out} \) 与标准的轮次损失 \( \mathcal{L}_e \) (在查询集上计算) 相结合。使用标量 \( \lambda \) 平衡二者:
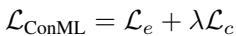
公式: ConML 元目标结合了“学会学习”的准确性与对比正则化。
该计算被无缝整合进训练循环,仅带来极小的额外开销。

算法: 融合 ConML 的轮次训练在标准元学习基础上增加了几步轻量的对比计算。
将 ConML 集成到不同类别的元学习中
映射函数 \( \psi \) 的定义方式取决于元学习器如何建模任务。

表 1: 针对不同元学习范式定制模型表示 \( \psi(g(\mathcal{D}; \theta)) \)。
基于优化的 (如 MAML) : 模型表示是任务数据上梯度更新后的权重。
基于度量的 (如 ProtoNet) : 每个任务由其类别原型 (类别嵌入的均值) 拼接而成的向量表示。
基于摊销的 (如 CNAPs) : 超网络输出的任务特定参数直接作为表示。
情境学习 (In-Context Learning, ICL) : 大型语言模型可通过提示隐式进行元学习。 为计算其“学习表示”,ConML 引入一个虚拟探测输入 \( u \) (例如,“这个任务是什么?”) ,模型对该输入的输出即作为其表示。
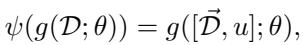
公式: 通过探测输入在情境学习中获得模型表示。
这种灵活性使 ConML 几乎可以集成到任何元学习或情境学习系统中。
实验: 普遍的性能提升
少样本图像分类
作者在 miniImageNet 和 tieredImageNet 基准上,测试了多种元学习算法——包括基于优化、度量、摊销及情境学习的模型。
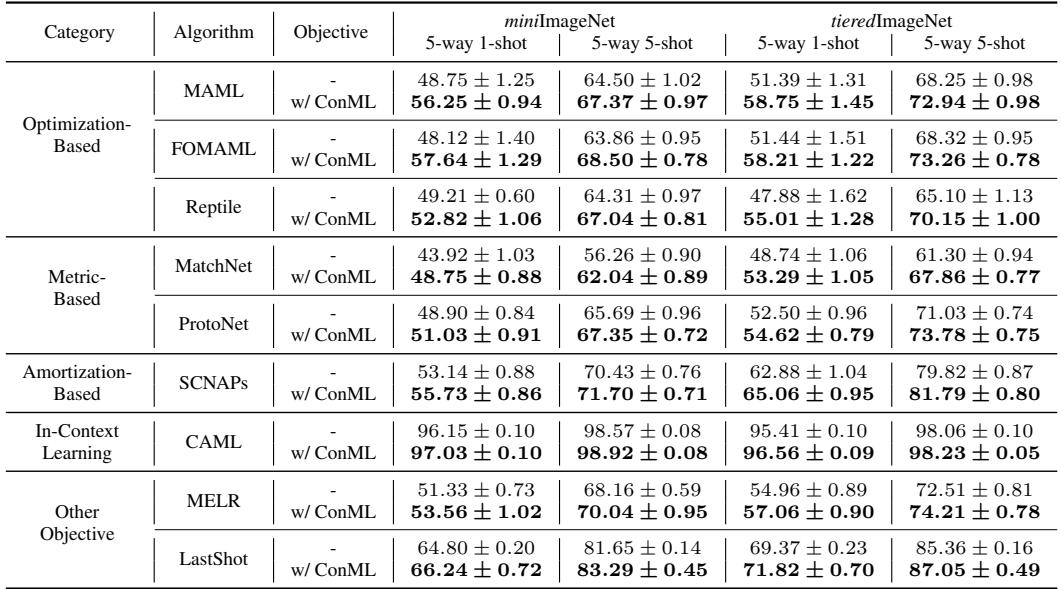
表 2: 在经典少样本基准上,ConML 为多种元学习算法持续带来性能提升。
即使未微调超参数,ConML 也能使所有学习器的准确率提升数个百分点。
为测试泛化能力,研究者还在 META-DATASET 上进行了评估——这是一个跨越多个图像领域的复杂基准。
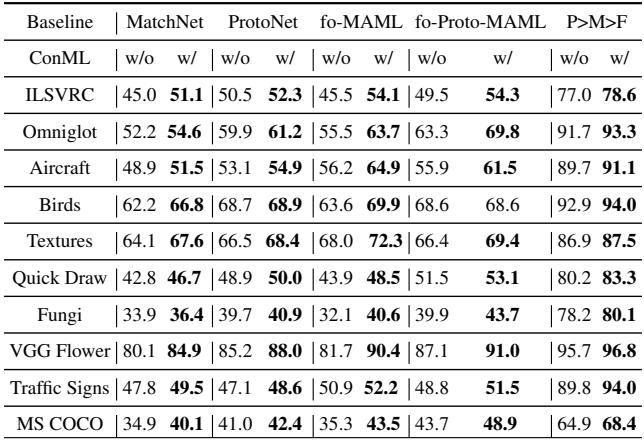
表 3: ConML 提升了跨域泛化能力,展现出与任务类型无关的特性。
在截然不同的数据集上,性能提升均保持稳定,验证了 ConML 的通用性。
情境学习: 更聪明的 Transformer
ConML 也应用于情境学习 。 研究者在合成函数类任务上训练了类似 GPT-2 的 Transformer 模型——包括线性回归 (LR)、稀疏回归 (SLR)、决策树 (DT) 和小型神经网络 (NN)。
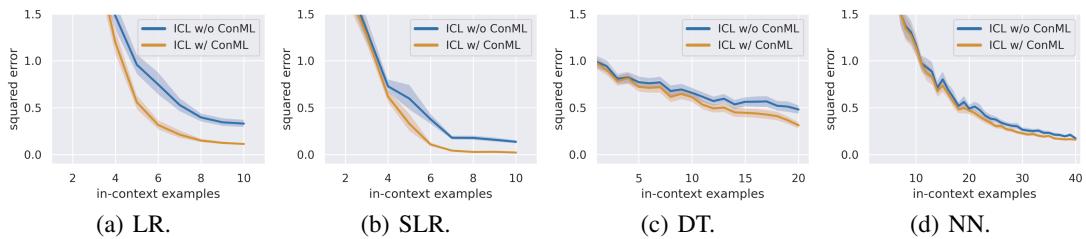
图 3: 在各类任务中,加入 ConML 的情境学习模型推理误差更低。
在所有场景中, ICL+ConML 模型使用更少的提示样本即可达到与标准 ICL 相同的准确率——通常能节省 4–5 个样本。

表 5: 定量优势——更低的相对误差与更少的示例即可达成相同准确率。
这一结果尤为引人注目,因为 ConML 无需更改网络结构,只需调整训练策略,就能提升模型对提示学习的效率。
综合分析: ConML 胜出的原因
为探究 ConML 为何能提升学习效果,研究团队在合成正弦波回归任务上训练了 MAML。
模型表示的可视化揭示了关键现象:
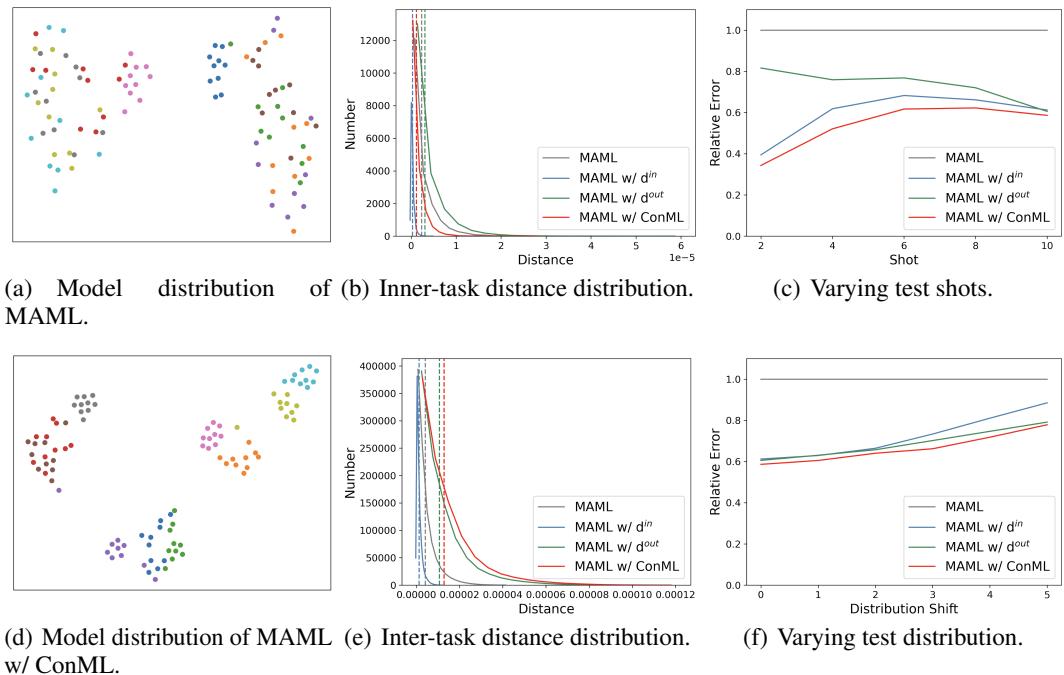
图 4: ConML 在模型层面强化对齐与区分——同任务模型表示形成紧密簇,而任务间保持清晰分界。
同一任务的模型聚集更紧 (对齐) ,不同任务的模型分离更远 (区分) 。
进一步实验显示:
- 对齐 (最小化 \(d^{in}\)) 提升了快速适应能力——这在极少样本情境中至关重要;
- 区分 (最大化 \(d^{out}\)) 增强了任务级泛化能力——有助于跨领域或应对未见分布。
即使是采用单子集样本 (\(K=1\)) 的最简单配置,也能以极低计算代价获得显著提升。
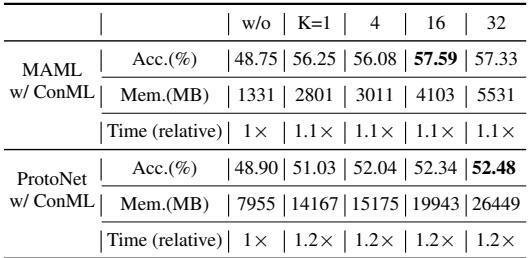
表 4: ConML 以最小的资源成本带来显著性能增益。
结论
论文 《使用对比元目标学会学习》 提出了一个简单却极具变革意义的理念: 任务身份本身可以作为元学习的有效监督信号。
通过将对比学习从数据空间的表示扩展到模型空间的模型表示 , ConML 提供了一种增强“学会学习”能力的通用途径。
核心要点:
- 类人学习目标: ConML 教会模型对齐相似任务视角并区分不同任务——模拟人类的学习方式。
- 普适适用性: 能与多种元学习范式兼容,并提升跨领域泛化性能。
- 高效实现: 轻量整合到现有训练循环,带来稳定且显著的收益。
ConML 并非取代现有的元学习算法,而是强化它们。 随着人工智能向能够从极少数据中动态学习的系统迈进,ConML 成为构建更具泛化性与适应性的学习器的一项可靠且实用的突破。