](https://deep-paper.org/en/paper/2410.09350/images/cover.png)
引言
我们正处于大语言模型 (LLM) 的黄金时代。从 ChatGPT 到 Claude,这些模型能够以惊人的流畅度写诗、编写代码以及进行日常对话。然而,任何用过它们进行事实性研究的人都知道它们那不可告人的秘密: 幻觉 (Hallucinations) 。 由于 LLM 是基于统计可能性而非事实数据库来生成文本的,它们有时会自信满满地胡说八道。
为了解决这个问题,研究人员通常求助于知识图谱 (Knowledge Graphs, KGs) 。 这种方法不再仅依赖模型的内部记忆,而是将对话建立在实体及其关系的结构化图谱之上 (例如: 莱昂内尔·梅西 – 效力于 – 迈阿密国际) 。
但这存在一个问题。将知识图谱与对话系统结合的传统方法通常采用“检索器-阅读器 (retriever-reader) ”架构,该架构依赖于外部图编码器。它们将复杂的对话历史压缩成单个向量表示。这就造成了信息瓶颈 (information bottleneck) ——细微差别丢失,检索系统往往会抓取到错误的事实。
DialogGSR (Dialog Generation with Generative Subgraph Retrieval,基于生成式子图检索的对话生成) 应运而生。在最近的一篇论文中,研究人员提出了一种摒弃外部图编码器的新方法。相反,他们将知识子图的检索视为一种生成任务。通过教导 LLM “说”图谱的语言,他们在事实性对话生成方面取得了最先进 (SOTA) 的结果。
在这篇文章中,我们将剖析 DialogGSR 的工作原理,探索知识图谱线性化 (Knowledge Graph Linearization) 和图约束解码 (Graph-Constrained Decoding) 的概念,并了解为什么这可能代表了真实可信的 AI 对话的未来。
问题所在: 信息瓶颈
在深入探讨解决方案之前,让我们先了解一下现状。在一个典型的基于知识图谱的对话系统中,流程通常如下:
- 输入: 用户提出一个问题 (例如,“谁主演了电影《盗梦空间》?”) 。
- 编码: 系统将对话历史编码为一个向量。
- 检索: 系统将此向量与代表知识图谱中三元组的向量进行比较 (通常使用图神经网络或 GNN) 。
- 生成: 相关的三元组被输入到 LLM 中以生成答案。
缺陷在于第 2 步和第 3 步。将长篇幅、多轮次的对话压缩成单个向量,就像试图用一句话总结一部小说一样;你会失去在“大海捞针”时所需的上下文信息。此外,由于使用独立的 GNN 来处理图谱,这些系统无法利用 LLM 本身已经拥有的海量预训练语言知识。
DialogGSR 提出了一种转变: 生成式检索 (Generative Retrieval) 。 与其通过比较向量来搜索图节点,不如直接要求 LLM 生成代表相关子图的 token 序列。
DialogGSR 的架构
DialogGSR 的核心理念是,知识的检索和回复的生成都应由大语言模型本身来处理。
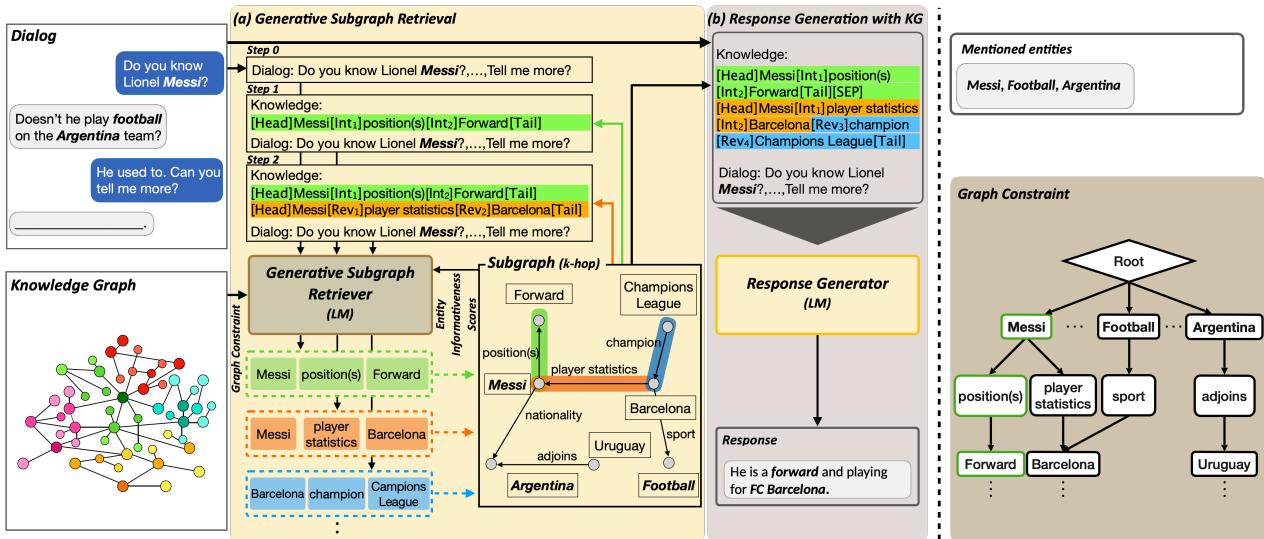
如上方的 图 1 所示,该过程分为两个独特但整合的阶段:
- 生成式子图检索 (GSR) : 模型观察对话,并自回归地生成相关子图的文本表示。
- 回复生成: 模型利用对话以及新生成的子图来生成最终答案。
让我们来详细分解实现这一点的两项主要创新: 结构感知线性化和图约束解码 。
1. 结构感知知识图谱线性化
如何将图结构 (节点和边) 输入到专为线性文本设计的 Transformer 模型中?你必须将其线性化 (linearize) 。
简单的线性化可能看起来像“梅西效力于巴塞罗那”。但这会丢失结构信息,例如关系的方向或实体与关系之间的区别。DialogGSR 引入了一组可学习的特殊 Token 来解决这个问题。
研究人员不仅仅将图中的路径视为单词,而是将其视为结构化的序列:
[Head]: 标记实体的开始。[Int](Interaction) : 标记关系。[Tail]: 标记路径的结束。[SEP]: 分隔不同的路径。
至关重要的是,他们还引入了一个 [Rev] Token。知识图谱是有向的,但在对话中,我们经常需要反向遍历 (例如,从“巴塞罗那”回到“梅西”) 。[Rev] Token 允许模型显式地表示这些反向关系。
线性化子图的数学表示如下所示:

这里,\(z_{\hat{\mathcal{G}}}\) 是代表图的 Token 序列。通过训练这些特殊 Token,LLM 学会了“理解”图结构,而无需外部图神经网络。
通过重构进行自监督学习
为了确保模型真正理解这些 Token,研究人员使用了“图重构”预训练任务。他们从 KG 中提取一条有效路径,掩盖 (mask) 掉其中的一个实体或关系,并强迫模型填补空白。
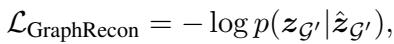
例如,如果三元组是 <红字, written by, 纳撒尼尔·霍桑>,模型可能会看到 <红字, [MASK], 纳撒尼尔·霍桑>,并必须预测关系 written by。这使得模型在尝试处理对话之前,就能学会知识图谱的内部逻辑。
2. 图约束解码
如果我们简单地让 LLM 生成图 Token,它可能会产生幻觉。它可能会生成像 <埃隆·马斯克, CEO of, 苹果> 这样的三元组,这在语法上是正确的,但根据我们的知识图谱,这在事实层面上是错误的。
为了防止这种情况,DialogGSR 使用了图约束解码 (Graph-Constrained Decoding) 。
当模型尝试预测子图中的下一个 Token 时,它不被允许从词表中选取 任意 单词。它被限制在基于知识图谱中实际连接的有效下一个 Token 集合中。这是通过根据对话中提到的实体的邻居构建的前缀树 (trie) 来实现的。
实体信息量分数
然而,仅有约束是不够的。一个通用的连接可能是有效的,但却是不相关的。为了引导模型找到最有用的事实,研究人员引入了实体信息量分数 (Entity Informativeness Score) 。
生成特定 Token 的概率不仅仅基于语言模型的偏好;它是词表概率 (\(p_{vocab}\)) 和图概率 (\(p_{graph}\)) 的加权混合。
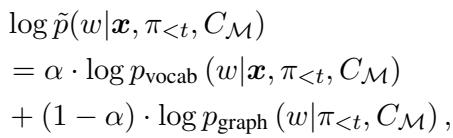
项 \(\alpha\) 控制平衡。但是 \(p_{graph}\) 是什么呢?它与实体相对于当前对话的“信息量”成正比。
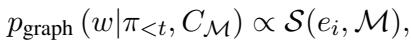
为了计算这种信息量 \(\mathcal{S}\),作者使用了 Katz 指数 (Katz Index) , 这是一种来自社交网络分析的指标,用于根据节点连接到其他节点的路径数量来衡量节点的影响力。这有助于模型优先考虑那些与对话中已经提到的概念紧密且强连接的实体。
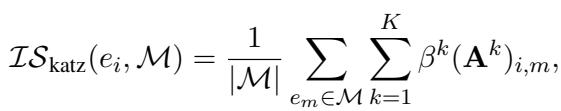
这种复杂的解码策略确保了生成的子图既是有效的 (存在于 KG 中) ,又是相关的 (在结构上接近对话主题) 。
整合: 回复生成
一旦子图被检索 (生成) 出来,困难的工作就完成了。线性化的子图 \(z_{\hat{G}}\) 与对话历史 \(x\) 被拼接在一起。
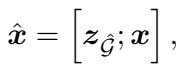
这个组合输入 \(\hat{x}\) 被馈送到回复生成器中。由于子图现在只是文本 (尽管是结构化的文本) ,LLM 的标准编码器-解码器架构可以轻松地关注图中的特定事实,从而构建自然、流畅且符合事实的回复。
实验与结果
研究人员在两个主要的基于知识的对话基准上评估了 DialogGSR: OpenDialKG 和 KOMODIS 。 他们将该方法与包括 SURGE 和 DiffKG 在内的强大基线进行了比较。
定量性能
结果令人印象深刻。在 OpenDialKG 数据集上,DialogGSR 几乎在所有指标上都达到了最先进的水平。
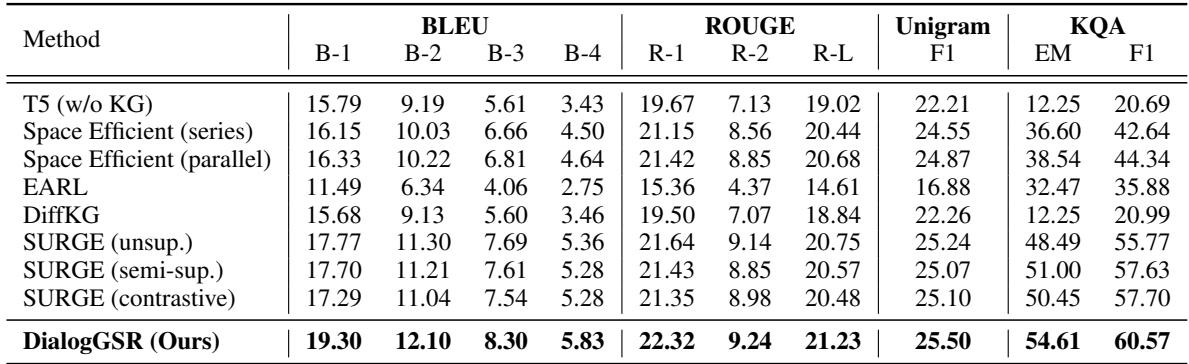
表 1 中的值得注意的要点:
- BLEU & ROUGE: 与以前的方法相比,该模型生成的回复与真实答案的重叠度显著更高。
- KQA (知识质量) : 该指标专门衡量回复中是否存在正确的知识实体。DialogGSR 在完全匹配 (EM) 中得分 54.61% , 显著高于最接近的竞争对手 SURGE (50.45%)。这证明模型不仅是在流畅地聊天;它还能正确地引用来源。
解决瓶颈问题
论文的主要主张之一是生成式检索解决了基于向量的检索器中存在的信息瓶颈问题。结果支持了这一观点。
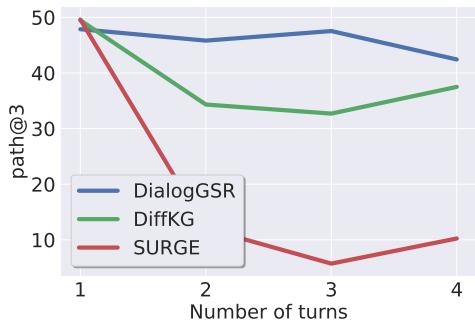
图 2 显示了随着对话变长 (轮数增加) 的检索性能。
- 红线 (SURGE): 随着对话的延长,性能崩溃。向量表示变得“浑浊”。
- 蓝线 (DialogGSR): 即使在第 4 轮,性能仍保持稳定和高水平。通过生成方式直接与对话历史交互,模型能更好地保持上下文。
定性示例
数字固然重要,但在实际应用中效果如何?让我们在一个真实场景中比较 DialogGSR 和基线 (SURGE)。

在 表 7 所示的例子中:
- 上下文: 用户询问米拉·库尼斯 (Mila Kunis) 嫁给了谁。
- 基线 (SURGE): 它被先前的上下文搞糊涂了 (之前提到了贾斯汀·汀布莱克) ,检索到了关于他的三元组。它产生幻觉说米拉·库尼斯嫁给了詹妮弗·劳伦斯 (事实显然不可能) 。
- DialogGSR: 它正确识别了与
Ashton Kutcher(阿什顿·库彻) 相关的romantic relationship(恋爱关系) ,并生成了正确答案。
这是另一个展示检索精度的例子:
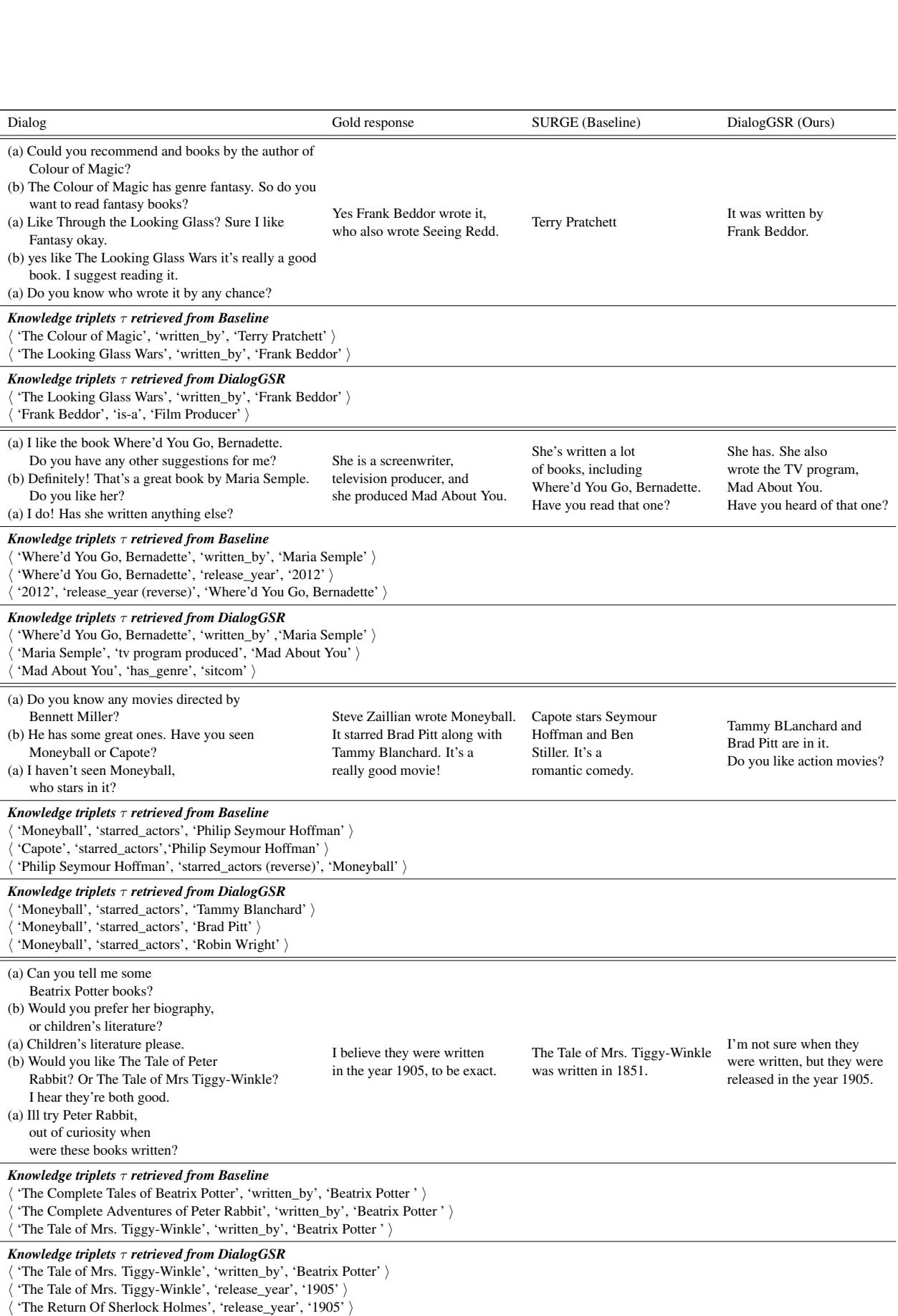
在 表 9 的第一行中,用户询问《镜中奇遇》 (The Looking Glass Wars) 的作者。
- SURGE 检索到了“特里·普拉切特” (之前提到的《魔法的颜色》的作者) 。
- DialogGSR 正确导航到了“弗兰克·贝多尔 (Frank Beddor) ”。
消融实验
所有这些复杂的组件都是必要的吗?作者进行了消融实验来找出答案。
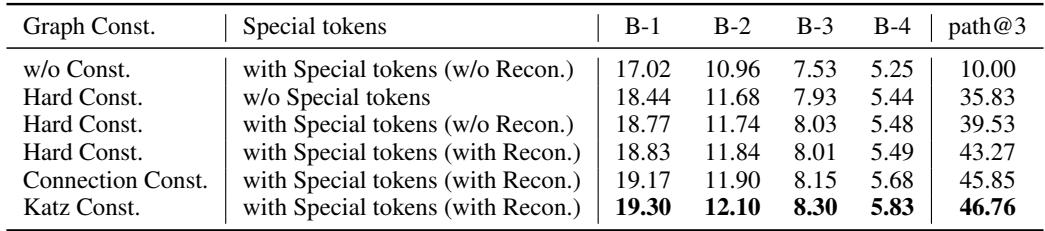
表 5 显示,移除 图约束 (w/o Const.) 会急剧降低性能 (BLEU-1 从 19.30 降至 17.02) 。同样,使用 Katz 指数 作为信息量指标比简单的连接计数效果更好。这证实了利用结构化图数据引导 LLM 是至关重要的——你不能仅仅依赖 LLM 原始的生成能力。
结论与启示
论文《Generative Subgraph Retrieval for Knowledge Graph–Grounded Dialog Generation》为 AI 领域迈出了引人注目的一步。通过将检索框架化为生成任务, DialogGSR 缩小了结构化的知识图谱世界与流动的语言模型世界之间的差距。
关键要点:
- 不要压缩: 将对话历史压缩成单个向量会损害长对话中的性能。
- 说图谱的语言: 通过特殊 Token 线性化图谱,允许 LLM 利用其在结构化数据上的预训练能力。
- 约束输出: 我们不能相信 LLM 会独自讲出事实。在解码过程中使用结构约束 (前缀树 + Katz 指数) 可确生成的知识既有效又相关。
随着我们迈向需要在现实世界中发挥作用的 AI 智能体——无论是预约、查询医疗事实还是浏览法律数据库——像 DialogGSR 这样将生成与结构化验证紧密结合的方法,对于构建我们可以真正信任的系统将是必不可少的。