](https://deep-paper.org/en/paper/2410.09629/images/cover.png)
引言
想象一下,你向一个最先进的大型语言模型 (LLM) 询问一个最近发生的事件——比如,2024 年欧冠决赛的获胜者是谁。或者,你问了一个关于 2024 年税收法规变更的极其具体的问题。
尽管这些模型非常聪明,但它们可能会失败。它可能会告诉你它不知道,或者更糟糕的是,它可能会自信地猜错球队 (产生幻觉) 。出现这种情况是因为 LLM 面临三大主要知识问题: 过时的知识 (训练数据有截止日期) 、领域缺陷 (缺乏金融或医学等专业知识) 以及灾难性遗忘 (在学习新知识时丢失旧知识) 。
标准的解决方案是向模型提供新数据,要么让它查阅文档 (检索增强生成,即 RAG) ,要么对其进行重新训练 (微调) 。但这里存在一个隐蔽的问题: 原始文本很难消化。 简单地把 PDF 或新闻文章扔给 LLM 并不能保证它能理解或检索到你需要的特定事实。
在一篇引人入胜的新论文《Synthetic Knowledge Ingestion: Towards Knowledge Refinement and Injection for Enhancing Large Language Models》中,来自 Intuit AI Research 的研究人员提出了一种名为 Ski (Synthetic Knowledge Ingestion,合成知识摄取) 的解决方案。Ski 不会让模型从原始文本中学习,而是将文本转化为高质量、合成的问答对,这对模型来说更容易学习。
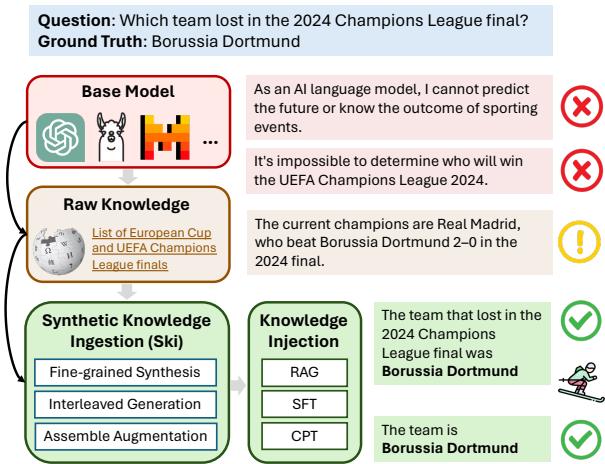
如上图所示,虽然标准模型可能无法回答谁在 2024 年欧冠决赛中输了,但 Ski 方法将原始新闻处理成问答格式,帮助模型生成正确答案: Borussia Dortmund (多特蒙德) 。
在这篇文章中,我们将详细剖析 Ski 的工作原理、其“摄取”过程背后的数学原理,以及它如何显著提高不同 AI 架构的性能。
差距: 摄取 (Ingestion) 与注入 (Injection)
要理解这篇论文,我们首先需要区分两个概念:
- 知识注入 (Knowledge Injection) : 这是我们将知识放入模型中的方式。你可能知道三种主要策略:
- RAG (检索增强生成) : 模型在对话过程中搜索数据库以获取帮助。
- SFT (有监督微调) : 在标记的示例上重新训练模型。
- CPT (持续预训练) : 模型阅读更多未标记的文本以更新其通用知识。
- 知识摄取 (Knowledge Ingestion) : 这是我们放入模型中的内容。这是在到达注入阶段之前对原始数据的获取和处理。
大多数研究都集中在注入上 (更好的模型架构、更好的训练循环) 。但这篇论文认为我们忽视了摄取。如果我们向模型提供未处理、非结构化的文本,就会增加它的工作难度。Ski 的目标是将原始知识转化为一种“可消化”的格式。
在数学上,如果 \(\mathcal{K}_{\mathcal{Q}}\) 是我们的原始知识库,我们希望应用一个变换 \(\mathcal{T}\) 来创建一个精炼的知识库 \(\mathcal{K}_{\mathcal{Q}}^*\):
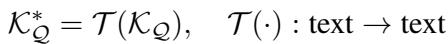
我们的目标是,当我们把这个精炼后的知识注入到模型 \(\mathcal{M}\) 中时,模型在事实性问题上的得分 \(\mathcal{S}\) 会增加:
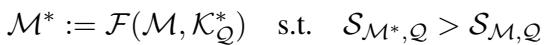
核心方法: Ski 如何运作
研究人员从人类学习中汲取了灵感。我们不仅仅是背诵段落;我们会问“为什么”和“是什么”。我们会通过问题来测试自己。Ski 使用合成数据生成管道自动化了这一过程。
Ski 方法包含三个关键创新: 细粒度合成 (Fine-grained Synthesis) 、交错生成 (Interleaved Generation) 和组合增强 (Assemble Augmentation) 。

1. 细粒度合成 (“N-Gram” 策略)
如果你有一篇很长的文档,如何从中提出好问题?如果问题太宽泛,就会遗漏细节。如果太具体,又会失去语境。
Ski 使用 n-gram 策略 (其中 \(n\) 代表句子的数量) 来解决这个问题。系统不再着眼于整个文档,而是查看句子的滑动窗口 (1 个句子、2 个句子等) ,并使用一个“教师”LLM 为该特定块生成假设性问题。
对于一组句子 \(\{k_j, ... k_{j+n-1}\}\),模型生成一个问题 \(q^n\):
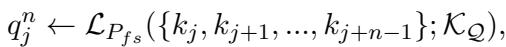
这创建了大量映射到文本特定切片的假设性问题。这比要求模型“总结这一页”要精确得多。
2. 交错生成 (协调问与答)
有时,仅仅拥有问题和文本块是不够的。对于有监督微调 (SFT) ,模型需要简洁、直接的答案,而不是长段的上下文。
Ski 使用交错生成来创建对齐的问答 (QA) 对。它提示模型根据文本切片同时生成问题和答案。这模仿了自然的信息寻求过程。
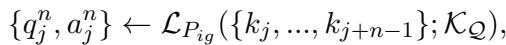
这产生了一个数据集对 \(\{\tilde{Q}^n, \tilde{A}^n\}\),其中答案是为问题量身定制的,消除了原始文本中的噪音。
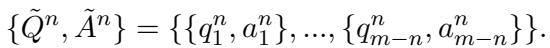
3. 组合增强 (多样性 + 重复性)
有效的学习需要重复,但死记硬背会导致过拟合。为了解决这个问题,Ski 使用了组合增强 。
它结合了从不同 n-gram 级别 (1 句块、2 句块等) 生成的数据。这意味着模型会以多种不同的方式看到同一个事实——有时是关于特定句子的详细问题,有时是关于段落的更广泛的问题。
对于 RAG 应用,Ski 创建了“增强文章”,将问题和上下文缝合在一起:
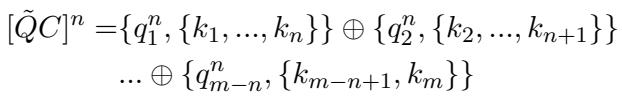
对于微调 (SFT) ,它创建了跨不同 n-gram 的所有 QA 对的并集:
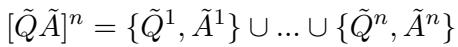
这创建了一个平衡了重复性 (强化事实) 与多样性 (以不同方式提问) 的数据集。
实施 Ski: 注入管道
一旦数据被合成,该如何使用它?作者将 Ski 集成到了前面提到的三个标准管道中。
带有 Ski 的 RAG
在标准的 RAG 设置中,用户提出问题,系统搜索原始文档片段。 使用 Ski-RAG , 系统搜索合成数据。
- Ski-Q: 系统搜索与用户查询匹配的合成问题 (问题对问题匹配) 。
- Ski-QC-ASM: 系统搜索组合的问题-上下文对。这通常效果更好,因为合成问题包含了原始文本中可能缺失的关键词,从而弥合了“语义鸿沟”。
带有 Ski 的 SFT
在这里,模型直接在 Ski-QA (问答) 或 Ski-QC (问题-上下文) 数据集上进行训练。实验的重点在于,在这些干净的合成对上进行训练是否比在原始文本或非 n-gram 策略生成的“普通” QA 对上进行训练更好。
带有 Ski 的 CPT
对于持续预训练,模型以无监督的方式被馈送组合数据集( Ski-QC-ASM 或 Ski-QCA-ASM ),使其在微调之前吸收结构和事实。
实验与结果
研究人员在一些高难度的数据集上测试了 Ski,包括 FiQA (金融) 、BioASQ (生物医学) 和 HotpotQA (多跳推理) 。他们使用 Llama2-7B 和 Mistral-7B 作为基础模型。
1. RAG 性能
检索增强生成的结果令人震惊。团队将 Ski 与标准检索 (查找原始文章) 和“Inverse HyDE” (一种通过假设性文档嵌入进行搜索的方法) 进行了比较。
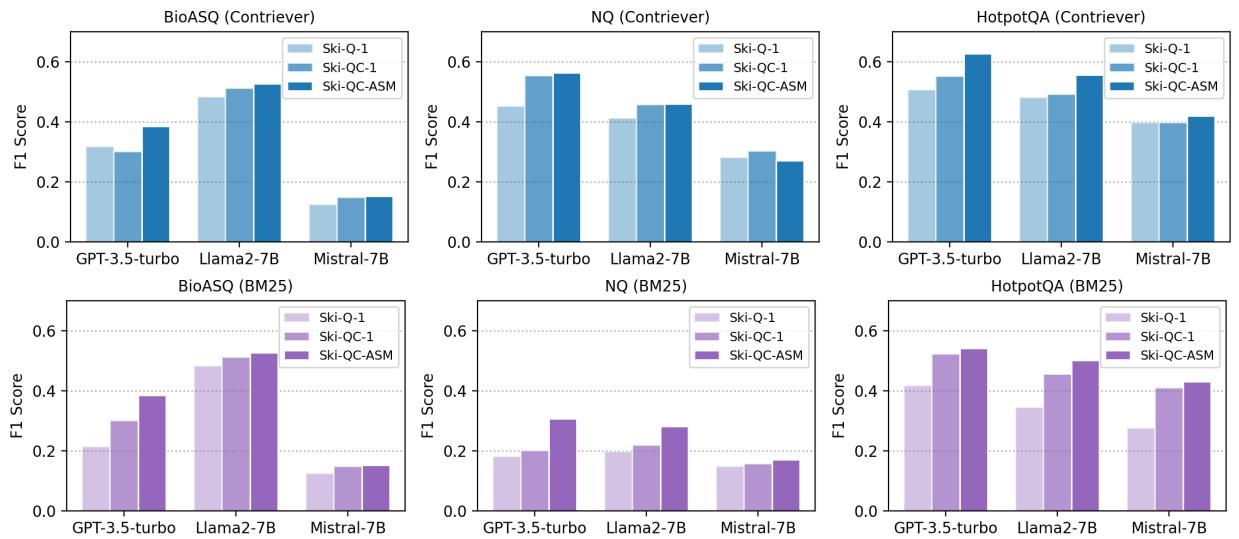
关键结论: 看上面的图表。 Ski-QC-ASM (颜色最深的柱状图) 始终优于其他方法。
- 通过检索“问题 + 上下文”块,模型获得了两全其美的效果: 问题的关键词匹配和上下文的事实细节。
- 它的表现显著优于搜索原始文章 (即论文图表中的“Contriever”基线) 。
2. SFT 性能
模型能仅仅通过在 Ski 数据上进行微调来学习事实吗?是的。
研究人员发现,在 Ski-QA-1 (1-gram 问答对) 上进行训练为有监督微调带来了最佳结果。这表明对于微调,模型更喜欢简洁、直接的 QA 对,而不是较长的上下文块。
有趣的是,“n-gram”的大小非常重要。
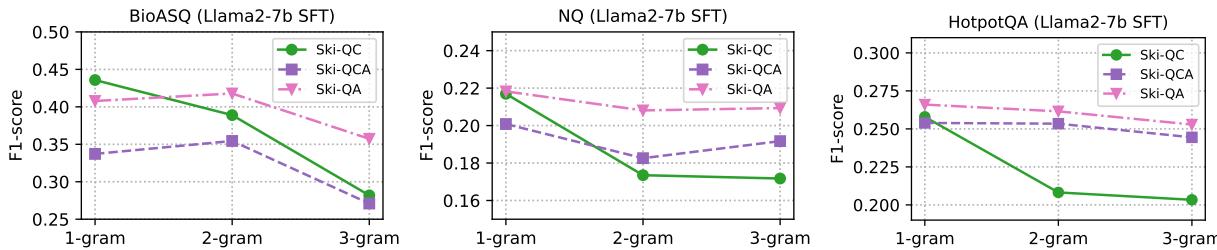
在上图中,注意下降的趋势。 1-gram (细粒度) 合成通常比 2-gram 或 3-gram 表现更好。这证实了一个假设: 将知识分解为最小的原子单元 (细粒度合成) 比给模型大块内容能更有效地帮助模型学习。
3. 整体比较: RAG vs. SFT vs. CPT
最后,论文提出了一个大问题: 哪种注入方法从 Ski 中获益最多?
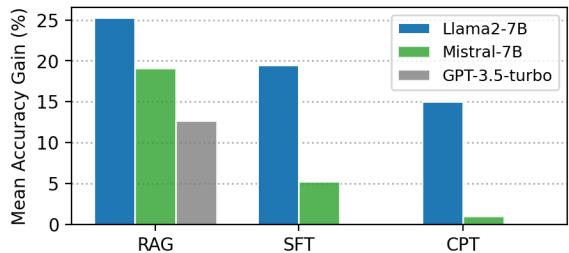
上图显示了相对于基础模型的性能增益:
- RAG (左) : 显示出巨大的收益。Ski 将 RAG 从一个“查找”工具转变为一个高精度的知识引擎。
- SFT (中) : 显示出强劲的改进,特别是对于 Llama2-7B。
- CPT (右) : 显示出适度的收益。似乎仅仅阅读数据 (预训练) 不如被迫回答有关数据的问题 (SFT) 或动态检索数据 (RAG) 有效。
结论与启示
《Synthetic Knowledge Ingestion》 (Ski) 这篇论文将对话从“我们如何构建更好的模型?”转移到了“我们如何构建更好的数据?”。
通过使用细粒度合成分解文本,使用交错生成将问题与答案对齐,以及使用组合增强创建多样化数据集,Ski 允许 LLM “消化”它们原本会错过的复杂信息。
给学生的关键启示:
- 数据表示很重要: 原始文本不是机器以此学习事实的最佳格式。QA 对更优越。
- 粒度是关键: 从单个句子 (1-gram) 生成问题通常比从整个段落生成问题效果更好。
- 注入前先摄取: 在决定是使用 RAG 还是微调之前,请专注于处理你的源数据。
随着 LLM 继续融入法律、医学和金融等专业领域,像 Ski 这样的方法对于确保这些通用模型能够成为可靠的专家至关重要。