](https://deep-paper.org/en/paper/2410.09642/images/cover.png)
简介
在机器学习领域,“数据是燃料”这句口头禅虽已是老生常谈,但从根本上讲它是正确的。训练数据集的特征——其质量、多样性和隐藏的偏差——决定了最终模型的能力。然而,分析这种“燃料”是一项众所周知的难题。
目前,如果数据科学家想要了解他们的训练数据,通常会关注诸如“难度” (这个样本有多难学?) 或“噪声”等属性。虽然有用,但这些指标通常孤立地关注单个实例。它们无法回答更广泛的问题: 数据集 A 与 数据集 B 有多相似?这 100 个样本组成的特定子集是否代表了整个数据集的知识?
这就引出了 RepMatch , 这是由 Modarres、Abbasi 和 Pilehvar 提出的一种新颖框架。RepMatch 不再基于文本的统计属性 (如词频或关键词重叠) 来分析数据,而是透过模型本身的视角来表征数据。
在这篇文章中,我们将探讨 RepMatch 如何通过比较模型在数据子集上编码的“知识”,来量化任意数据子集之间的相似性。我们将详细拆解它是如何巧妙利用低秩自适应 (LoRA) 使这种比较在计算上变得可行,并了解该方法如何用于选择更好的训练数据以及检测数据集中的伪影 (artifacts) 。
核心问题: 比较知识
想象一下你有两本不同的教科书。你如何确定它们是否涵盖了相同的材料?你可以计算有多少单词重叠,但这太表面了。更好的方法是让一个学生读 A 书,另一个学生读 B 书,然后比较他们学到了什么。如果两个学生对物理学有了相同的理解,我们可以说这两本书在“表示上是相似的”。
这就是 RepMatch 背后的哲学。研究人员定义,如果在一个数据子集 \(S_1\) 上训练的模型所学习到的表示空间与在 \(S_2\) 上训练的模型紧密一致,则这两个子集 \(S_1\) 和 \(S_2\) 是相似的。
然而,这带来了一个技术瓶颈。现代大型语言模型 (LLM) 拥有数十亿个参数。直接比较两个巨大的权重矩阵不仅计算成本高昂,而且在统计上充满噪声。我们需要一种方法来精确隔离训练期间发生了什么变化,而不会迷失在数十亿参数的噪声中。
解决方案: LoRA 和格拉斯曼相似度
研究人员通过结合两个强大的概念解决了比较难题: 低秩自适应 (LoRA) 和格拉斯曼相似度 (Grassmann Similarity) 。
1. 使用 LoRA 约束更新
标准的微调会更新模型中的所有权重。然而,RepMatch 利用了 LoRA (Hu et al., 2021)。LoRA 冻结预训练模型的权重,并在每一层中注入可训练的小型秩分解矩阵。
在特定数据子集上进行训练期间,只有这些小的 LoRA 矩阵会被更新。这意味着从该特定子集获得的“知识”完全被捕获在这些紧凑的低秩矩阵中。
如果我们有一个预训练权重矩阵 \(W\),微调后的版本就是 \(W + \Delta W\)。在 LoRA 中,这个更新量 \(\Delta W\) 是两个小矩阵 \(A\) 和 \(B\) 的乘积。RepMatch 专注于分析这个 \(\Delta W\),从而有效地隔离了从数据中提取的任务特定特征。
2. 用格拉斯曼几何测量相似度
一旦研究人员隔离了两个不同模型的更新矩阵 (\(\Delta W\)) ,他们就需要一把数学标尺来衡量它们的相似性。他们选择了格拉斯曼相似度 , 这是一种用于比较子空间的指标。
从概念上讲,低秩矩阵创建了一个特定的几何子空间。如果两个模型学习到了相似的特征,它们的更新矩阵应该形成重叠显著的子空间。
两个矩阵 \(W^r\) 和 \(W^{r'}\) 之间的这种相似度量 \(\phi\) 的数学公式为:
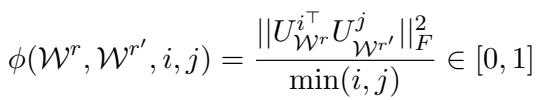
在这里,\(U\) 代表更新矩阵的奇异向量 (通过奇异值分解 SVD 获得) 。该公式本质上计算了一个子空间的基向量与另一个子空间的基向量对齐的程度。结果是 0 (完全不同) 到 1 (完全相同的子空间) 之间的分数。
可视化相似度
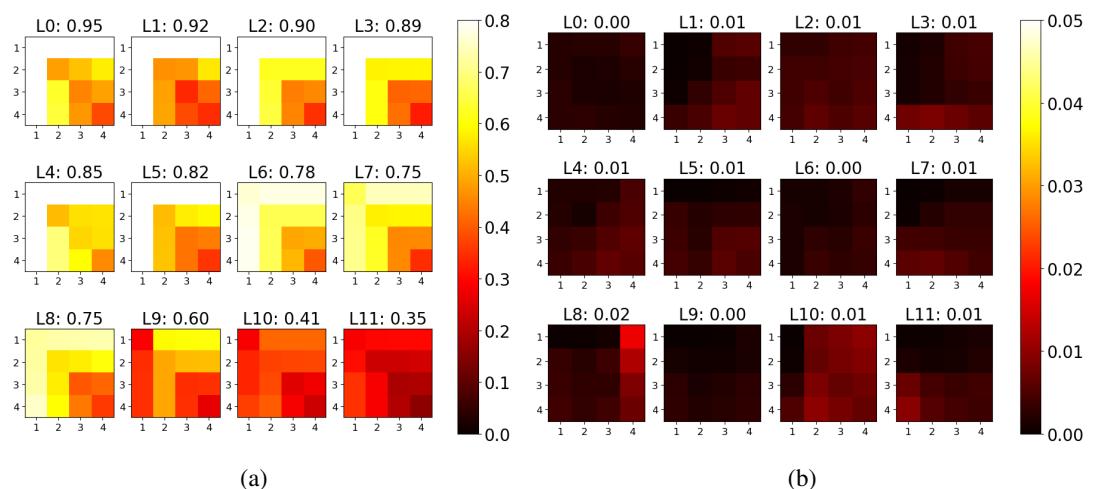
为了证明这种方法有效,作者可视化了 BERT 模型各层之间的相似度。
在下图中,面板 (a) 比较了在同一数据集 (SST-2) 上训练但使用不同随机种子的两个模型。你可以看到明亮的黄色块,表明相似度得分非常高 (在某些层接近 1.0) 。这证实了该指标的鲁棒性;即使随机种子改变,模型也学到了相同的基本“知识”。
相比之下,面板 (b) 将训练好的模型与“随机基线” (一个打乱的矩阵) 进行了比较。结果几乎全是黑色/红色,得分接近 0.02。这种鲜明的对比验证了 RepMatch 真正测量的是学习到的结构,而非随机噪声。
RepMatch 实战: 分析的可能性
RepMatch 的灵活性允许进行两种截然不同的分析: 数据集级和实例级 。 因为该方法不关心子集的大小,你可以将单个句子与整个数据集进行比较,或者将两个巨大的数据集相互比较。
实例级鲁棒性
在信任该指标用于复杂任务之前,我们需要知道它是否能在单个样本的细粒度层面上工作。
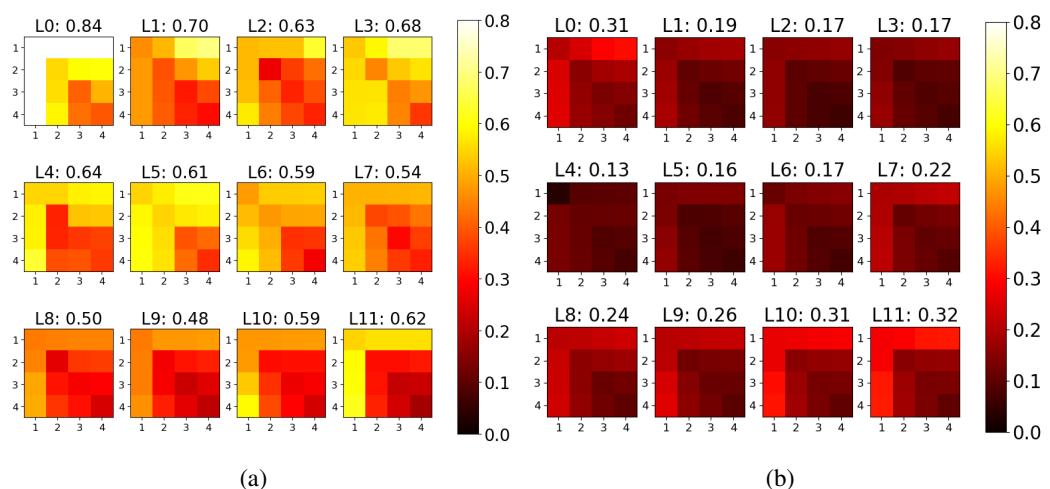
研究人员进行了一项实验,他们在单个实例上对模型进行了微调。
- 图 2a (下) 显示了在同一个实例上使用不同种子训练的模型之间的相似度。得分很高 (大部分是黄色/橙色) 。
- 图 2b (下) 显示了在两个不同实例上训练的模型之间的相似度。得分显著下降 (大部分是红色/黑色) 。
这证实了 RepMatch 可以区分单个数据点的特定信息内容。
数据集级相似度
RepMatch 最直观的应用之一是比较不同的数据集,看看它们是否“兼容”或涵盖类似的任务。
在下面的实验中,研究人员将 SST-2 数据集 (情感分析) 与另外三个数据集进行了比较:
- IMDB: 另一个情感分析数据集。
- SST-5: SST-2 的细粒度版本。
- SNLI: 一个文本蕴含数据集 (完全不同的任务) 。
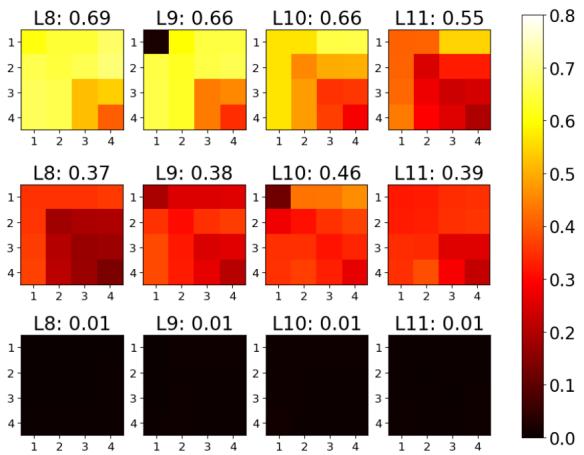
图 3 (上图) 的结果与直觉完美吻合:
- 中间行 (SST-2 vs. SST-5): 高相似度 (亮黄色) 。这些数据集本质上是“兄弟”关系。
- 顶行 (SST-2 vs. IMDB): 中等相似度。它们共享相同的任务 (情感) ,但来自不同的领域 (短语 vs. 影评) 。
- 底行 (SST-2 vs. SNLI): 接近零的相似度 (黑色) 。情感分析的逻辑无法迁移到文本蕴含逻辑中。
这证实了 RepMatch 成功捕捉到了数据集的语义和任务层面的本质 。
与基线比较
你可能会问,“为什么不直接比较数据的预训练嵌入 (Embeddings) 呢?” 作者尝试了这一点。他们使用了一个基线方法,比较原始数据 [CLS] 标记表示的余弦相似度。
结果如表 2 所示,凸显了基线的一个关键失败。
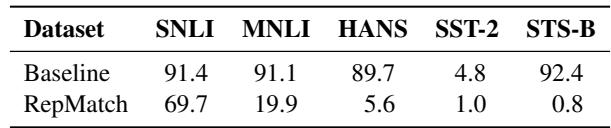
注意 STS-B 这一列。基线方法声称 STS-B 与 SNLI 有 92.4% 的相似度 。 这是误导性的;STS-B 是语义相似度任务,而 SNLI 是推理任务。它们表面上看起来很相似 (都涉及句子对) ,所以预训练嵌入是相似的。然而,RepMatch 正确地识别出解决这些任务所需的知识是不同的,给出的相似度得分仅为 0.8% 。
应用 1: 数据效率 (事半功倍)
对于学生和从业者来说,RepMatch 最令人兴奋的应用或许是数据选择 。
如果我们能测量单个实例与完整数据集的“理想”知识有多相似,我们就能识别出最具代表性的样本。假设很简单: 在一小部分具有高度代表性的数据上进行训练,应该比在随机子集上训练产生更好的结果。
实验
- 计算数据集中每个实例针对整个数据集的 RepMatch 分数。
- 选择分数最高的前 100 个实例。
- 仅在这 100 个实例上训练 BERT 模型。
- 将性能与在 100 个随机实例上训练的模型进行比较。
结果
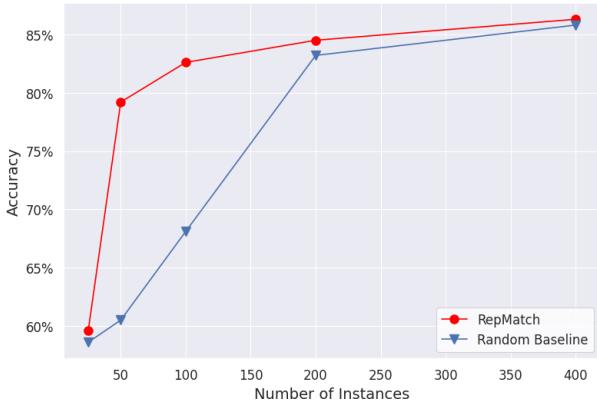
结果在多个数据集中是一致的。如表 1 所示,基于 RepMatch 选择的子集始终优于随机选择。对于 SST-2 数据集,准确率从 69.53% (随机) 跃升至 81.03% (RepMatch) 。

即使子集大小增加,这种优势依然存在。 图 4 展示了 SST-2 上的性能曲线。虽然后期随着数据增加,差距会缩小 (最终随机选择也会偶然捕捉到足够多的好数据) ,但在数据或计算资源有限的情况下,RepMatch 提供了巨大的“冷启动”优势。
应用 2: 检测数据集伪影
该论文的最后一个主要贡献是使用 RepMatch 检测“分布外” (out-of-distribution) 实例和数据集伪影 (artifacts) 。
在自然语言推理 (NLI) 数据集中,存在一个被称为重叠偏差 (overlap bias) 的已知问题。模型经常“作弊”,假设如果两个句子共享许多单词,它们就具有“蕴含”关系。像 HANS 这样的挑战数据集就是为了打破这种启发式规则而创建的,其中包含字词重叠度高但实际上不构成蕴含关系的例子。
研究人员假设,标准 NLI 数据集中那些糟糕的训练样本 (那些强化这种作弊行为的样本) 在表示上应该与 HANS 数据集相似。
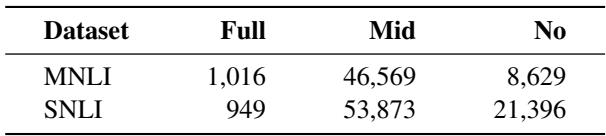
为了验证这一点,他们根据单词重叠度将 NLI 数据分为三组:
- 完全重叠 (Full Overlap)
- 中等重叠 (Mid Overlap)
- 无重叠 (No Overlap)
然后,他们计算了这些组与 HANS 数据集之间的 RepMatch 分数。
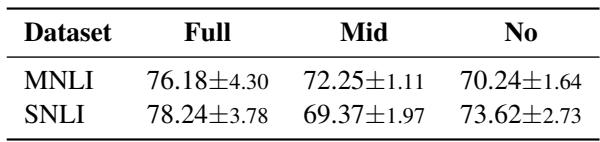
表 5 中的结果证实了这一假设。“完全重叠”子集与 HANS 的相似度最高。这意味着 RepMatch 成功识别出了依赖重叠启发式规则的特定训练数据子集。这种能力对于调试数据集和提高分布外泛化能力非常强大。
结论与未来启示
RepMatch 代表了我们分析数据集方式的一个重大转变。通过摆脱表面统计数据并测量模型表示的变化 , 我们对模型实际学到的内容有了更深入的了解。
这项研究的关键要点是:
- 低秩自适应 (LoRA) 是捕获任务特定知识的高效容器。
- 格拉斯曼相似度为比较这些知识状态提供了稳健的数学框架。
- 实用价值: RepMatch 不仅仅是理论上的。它能有效地选择高质量的训练数据 (击败随机采样) ,并揭示标准数据集中的隐藏偏差和伪影。
对于学生和研究人员来说,这开启了“以数据为中心的 AI” (Data-Centric AI) 的新途径。我们不再仅仅构建更大的模型,而是可以使用像 RepMatch 这样的工具来策划更智能、更高效的数据集,从而产生学习速度更快、泛化能力更好的模型。当我们继续依赖海量、不透明的数据集来训练 AI 时,拥有一个让我们能透过模型的眼睛看世界的工具是无价的。