](https://deep-paper.org/en/paper/2410.10093/images/cover.png)
超越 SFT: 利用广义自模仿学习 (GSIL) 对齐大语言模型
大语言模型 (LLM) 令人印象深刻,但原始的预训练模型就像才华横溢却难以管教的学生。它们对世界了解很多,但并不总是知道如何表现、遵循指令或分步解决复杂问题。为了解决这个问题,我们执行一个称为对齐 (alignment) 的过程。
目前,对齐的标准配方主要有两个阶段:
- 监督微调 (SFT): 你向模型展示好的提示词和回答示例,它会学习模仿它们。
- 偏好微调 (RLHF/DPO): 你向模型展示两个回答 (一个好的,一个坏的) ,并教它更喜欢好的那个。
第二阶段很强大但昂贵。它需要收集人类偏好数据 (“回答 A 比回答 B 好”) ,这既昂贵又难以扩展。如果我们仅使用第一阶段的演示数据就能达到偏好学习的高性能,会怎么样?
在这篇文章中,我们将深入探讨一篇题为 “How to Leverage Demonstration Data in Alignment for Large Language Model? A Self-Imitation Learning Perspective” 的迷人论文。研究人员提出了一个名为 GSIL (广义自模仿学习) 的新框架。它将对齐问题转化为分类任务,允许模型从自身学习,在不需要昂贵偏好标签的情况下超越标准方法。
标准模仿学习的问题
要理解为什么我们需要 GSIL,我们首先需要看看为什么标准方法——监督微调 (SFT)——还不够。
SFT 本质上是行为克隆 (Behavior Cloning) 。 我们给模型一个提示词 (\(\mathbf{x}\)) 和一个黄金标准的人类回答 (\(\mathbf{y}\)),然后我们最小化负对数似然。换句话说,我们告诉模型: “最大化生成这些确切词语的概率。”
在数学上,SFT 最小化数据分布与模型分布之间的前向 KL 散度 (Forward KL Divergence) :
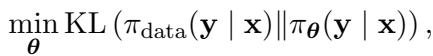
虽然这听起来合乎逻辑,但它有一个被称为质量覆盖 (mass-covering) 行为的隐性缺陷。通过试图覆盖整个人类数据分布,模型试图为每一个可能的人类回答分配概率。但人类数据是有噪声的。如果训练数据既包含高质量的推理,也包含平庸的推理,SFT 会试图将它们平均化。
在编程或数学等复杂任务中,“平均化”是灾难性的。我们不希望模型覆盖所有有效的人类回答;我们希望它找到最佳的、独特的高质量答案模式。我们需要模式搜索 (mode-seeking) 行为。
这就是前向 KL (用于 SFT) 和 反向 KL (Reverse KL) 之间的区别变得至关重要的地方。
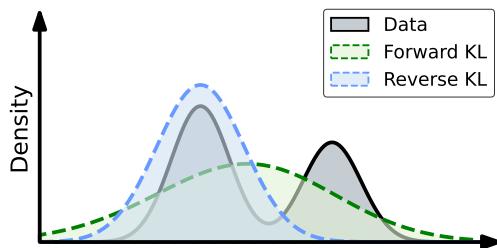
如上图 1 所示:
- SFT (前向 KL): 绿色虚线试图覆盖整个黑色曲线 (数据) 。它把自己摊得很薄,可能包括了低概率或噪声区域。
- GSIL (反向 KL): 蓝色点划线聚焦于峰值 (模式) 。它忽略尾部,专注于好数据密度最高的区域。
研究人员认为,为了实现高性能对齐,我们应该最小化反向 KL 散度 。
核心方法: 广义自模仿学习 (GSIL)
GSIL 的目标是最小化反向 KL 散度。这个目标如下所示:
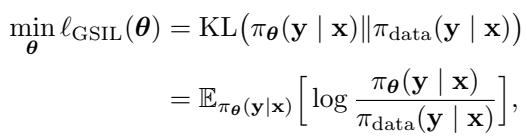
挑战
这里有个陷阱。最小化反向 KL 比前向 KL 难得多。要优化方程 (6),你需要计算数据分布 \(\pi_{\text{data}}\) 和模型当前策略 \(\pi_{\theta}\) 之间的比率。但我们没有“数据分布”的公式——我们只有一个样本数据集。
在强化学习 (RL) 中,这通常使用复杂的对抗训练 (如 GAN) 来解决,你需要训练一个单独的“判别器”网络来区分真实数据和假数据。但这通常是不稳定且计算量巨大的。
代理目标
作者提出了一个聪明的变通方案。他们推导出一个代理目标来转换问题。他们不使用复杂的 RL 循环,而是将问题视为最大化基于真实数据与模型自身生成数据之间密度比 (density ratio) 的奖励函数。
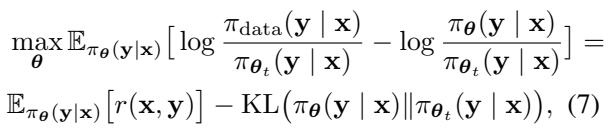
这里,\(r(\mathbf{x}, \mathbf{y})\) 充当奖励,定义为数据概率与模型概率的对数比。如果模型能够估计这个比率,它就能将其生成推向真实数据分布。
密度比估计 (DRE)
我们如何在没有单独奖励模型的情况下估计这个比率?我们把它变成一个分类问题 。
想象一下,我们混合了真实的人类演示 (标记为 1) 和模型自己生成的回答 (标记为 0) 。我们可以训练一个分类器来区分它们。论文表明,该任务的最佳分类器与我们所需的密度比直接相关。
这个密度比估计 (DRE) 的损失函数看起来像标准的逻辑回归:
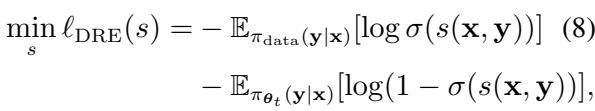
“自模仿”的转折点
这是 GSIL 最优雅的部分。作者没有训练一个单独的分类器网络 (判别器) 和一个生成器网络 (LLM) ,而是使用 LLM 本身 来参数化判别器。
他们推导出一个闭式解,其中最佳判别器分数 \(s^*\) 使用模型的策略 \(\pi\) 来表示:
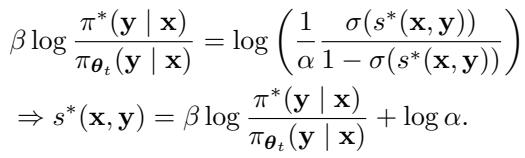
将其代回损失函数,我们得到了语言模型的直接优化目标。我们不需要单独的奖励模型或 PPO (近端策略优化) 循环。我们只需要最小化一个分类损失,其中的“logits”是 LLM 本身的对数概率。
最终的 GSIL 目标 如下所示:
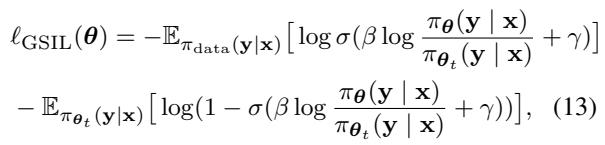
这在直觉上意味着什么?
上面的方程可能看起来很吓人,但直觉很简单:
- 正向阶段: 第一项鼓励模型增加真实演示数据的概率 (将它们视为“正”类) 。
- 负向阶段: 第二项鼓励模型降低其自身生成数据的概率 (将它们视为“负”类) ,相对于参考模型而言。
模型通过对比真实人类专业知识与其自身的当前尝试来学习。它是通过试图区分专家数据和自己的合成胡言乱语来“模仿”专家。
一个广义的框架
这篇论文之所以被称为“广义” SIL,是因为这种逻辑并不局限于一种特定的损失函数。上面的推导使用了逻辑回归,但作者展示了一整族损失函数 (Hinge 损失、Brier 分数、指数损失) 都可以插入这个框架。
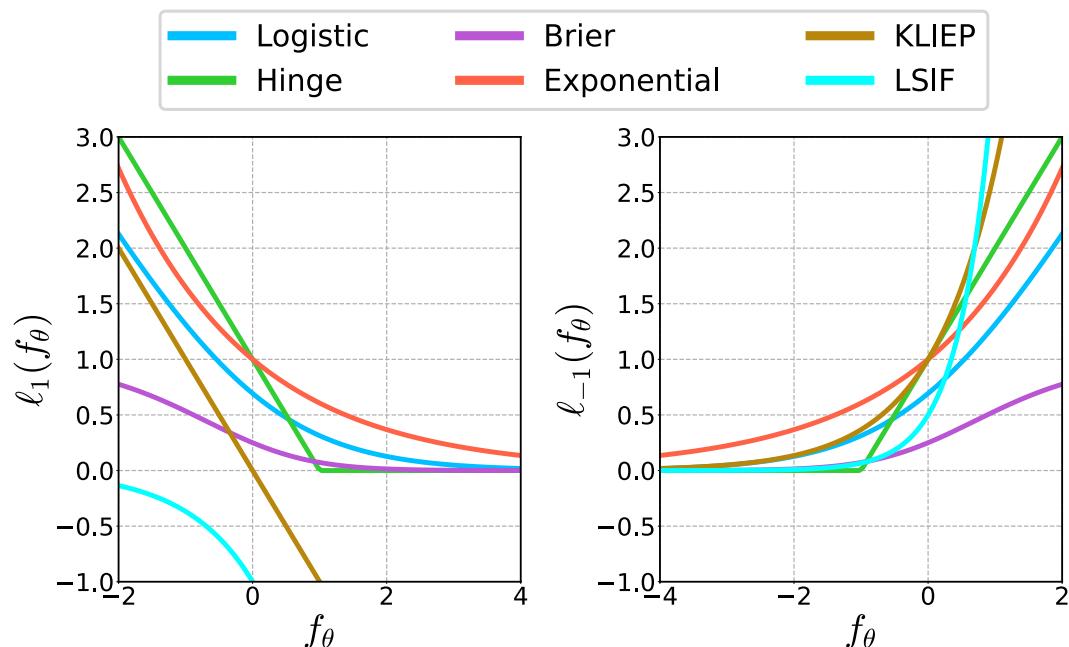
如图 10 所示,不同的损失函数对专家数据和生成数据之间的差异施加了不同的惩罚 (边际) 。这种灵活性使得 GSIL 能够适应不同类型的任务。
与 SPIN 的比较
你可能会想,“这不类似于 SPIN 等其他自博弈方法吗?”
SPIN (Self-Play Fine-Tuning) 是最近的一种方法,也使用了演示数据。然而,SPIN 依赖于 Bradley-Terry 偏好模型,该模型假设赢和输的回答之间存在对称关系。
作者发现 SPIN 有一个副作用: 虽然它压低了生成回答的概率 (这很好) ,但它可能会无意中压低真实演示的概率 。
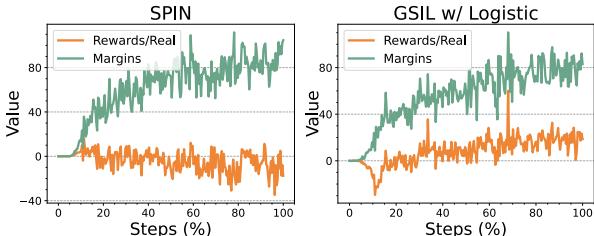
看看图 2 中的橙色线。
- 左图 (SPIN): 真实数据的奖励 (隐含似然) 随着时间推移降至零以下。模型在试图与坏数据保持距离的同时,正在“遗忘”好数据。
- 右图 (GSIL): 真实数据的奖励持续增加或保持正值。GSIL 保持了专家演示的高概率,同时拉大了与合成数据的差距 (边际) 。
这对于数学或编程等任务至关重要,因为在这些任务中,“真实”答案往往是唯一正确的答案,降低其概率是有害的。
实验与结果
为了证明这不仅仅是理论体操,作者在几个具有挑战性的基准测试上测试了 GSIL:
- 推理: ARC, Winogrande
- 数学: GSM8K
- 编程: HumanEval
- 指令遵循: MT-Bench
他们将 GSIL 与标准 SFT 和 SPIN 进行了比较。
主要结果
结果非常令人印象深刻。GSIL 在所有方面都始终优于 SFT 和 SPIN。
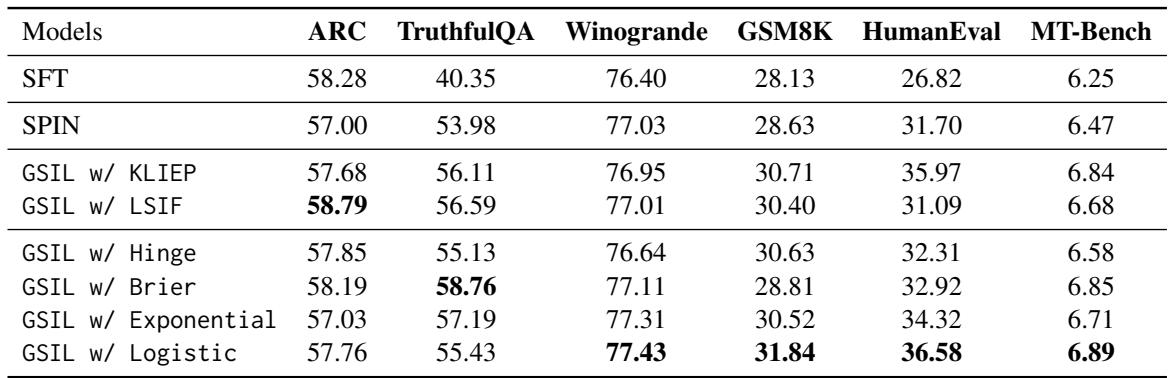
表 2 的主要结论:
- 击败 SFT: GSIL 显著优于 SFT。例如,在编程基准测试 (HumanEval) 上,SFT 得分为 26.82,而 GSIL (Logistic) 得分为 36.58。使用完全相同的数据,这是一个巨大的飞跃。
- 击败 SPIN: GSIL 优于 SPIN,尤其是在数学和代码方面。这验证了 SPIN 降低真实数据概率的倾向会损害精确推理任务性能的假设。
- 损失函数: 虽然 Logistic 损失 (标准) 效果很好,但像 Brier 这样的其他损失也显示出强大的性能,突显了广义框架的好处。
我们可以使用下面的雷达图来可视化这些不同能力的增益:
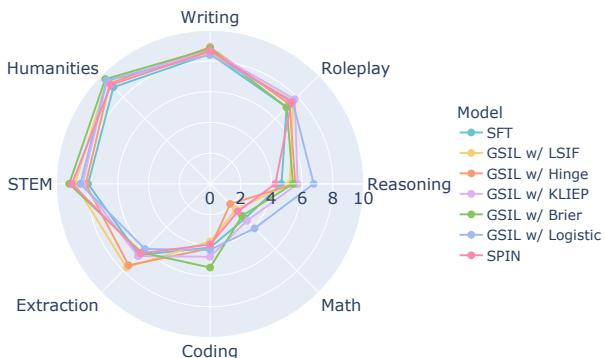
GSIL (彩色线) 与 SFT (蓝色) 和 SPIN (橙色) 相比,向外扩展了边界,尤其是在推理、数学和编程方面。
它能击败偏好微调 (DPO) 吗?
也许最令人惊讶的结果是 GSIL 与 DPO 的比较。请记住,DPO 需要偏好对 (人类标注的“更好 vs 更差”) 。GSIL 只使用演示。
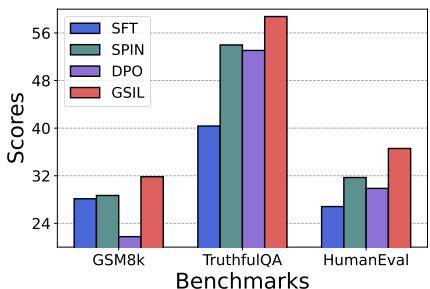
如图 6 所示,GSIL (蓝色柱) 实际上在 GSM8K (数学) 、TruthfulQA 和 HumanEval 上优于 DPO (绿色柱) 。这表明对于重推理任务,好数据上的强自模仿信号可能比嘈杂的偏好信号更有价值。
安全对齐
最大化似然会让模型不安全吗?作者在 Anthropic-HH 数据集 (有用且无害) 上对此进行了测试。
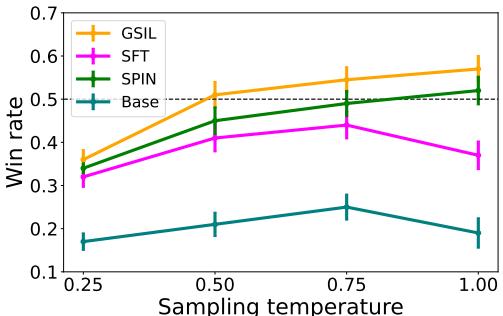
GSIL 针对所选回答实现了约 60% 的胜率,显着高于 SFT 基线 (徘徊在 50% 左右) 。这意味着模型不仅变得更聪明,而且更好地遵守了训练数据中的安全准则。
超参数很重要
该框架引入了两个关键的超参数:
- \(\beta\): 一个缩放参数 (类似于 DPO 中的温度) 。
- \(\gamma\) (偏移): 一个控制赋予演示数据先验权重的参数。
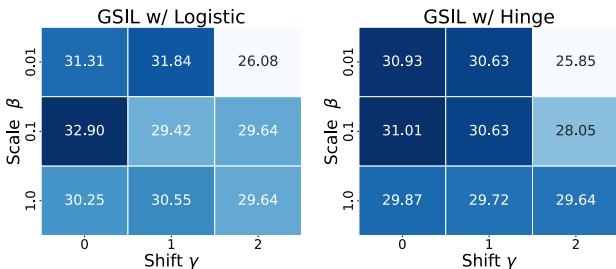
图 7 中的消融研究表明,严格正值的 \(\gamma\) (偏移) 有助于提高性能。这在数学上对应于为真实数据类分配更高的“先验概率”,防止模型在真实数据和合成数据之间混淆。
结论
论文“How to Leverage Demonstration Data in Alignment”为 LLM 训练提供了一个引人注目的新视角。它挑战了我们需要严格依赖强化学习或昂贵的偏好数据来有效对齐模型的假设。
通过将对齐重新构建为广义自模仿学习 (GSIL) , 作者提供了一种方法,它是:
- 有效: 它实现了模式搜索行为 (反向 KL) ,这对推理和编程至关重要。
- 高效: 它避免了对抗训练或 PPO 的复杂性。
- 自给自足: 它从你已经拥有的演示数据中释放出更高的性能。
对于学生和从业者来说,GSIL 代表了一种思维转变。我们不仅仅是教模型“复制” (SFT),而是教它“辨别并自我改进”,将其自身的生成视为要避免的负面示例。随着我们寻找提高 LLM 训练数据效率的方法,像 GSIL 这样能从现有数据中榨取更多信号的技术可能会成为新的标准。