](https://deep-paper.org/en/paper/2410.17739/images/cover.png)
大型语言模型 (LMs) 是其训练数据的镜像。不幸的是,这意味着它们往往反映了互联网海量文本中存在的社会偏见,包括性别刻板印象。虽然我们有许多工具来测量这种偏见——例如检查模型是否比女性更多地将“医生”与男性联系起来——但我们对这种偏见在模型内部具体存在于何处的理解仍然有限。在数百万甚至数十亿的参数中,究竟是哪些具体的数字 (权重) 导致模型认为“护士”意味着“女性”?
在最近的一篇论文《Local Contrastive Editing of Gender Stereotypes》 (性别刻板印象的局部对比编辑) 中,来自曼海姆大学、阿姆斯特丹大学和汉堡大学的研究人员提出了一种新颖的方法来回答这个问题。他们介绍了局部对比编辑 (Local Contrastive Editing) , 这种技术就像是神经网络的显微手术。它使我们能够精确定位负责编码刻板印象的权重子集,并且至关重要的是,可以编辑这些权重以减轻偏见,而无需重新训练整个模型。
在这篇文章中,我们将详细解析这种方法的工作原理、背后的数学机制,以及实验揭示了关于人工智能偏见解剖结构的哪些信息。
挑战: 大海捞针
要解决问题,通常需要先知道问题出在哪里。在深度学习的背景下,这就是可解释性的挑战。像 BERT 这样的模型拥有 1.1 亿个参数。修改所有参数 (微调) 不仅计算成本高昂,而且存在“灾难性遗忘”的风险,即模型学会了新规则却忘记了如何正确使用英语。
研究人员的目标有两方面:
- 定位 (Localization) : 识别驱动性别刻板印象偏见的具体权重。
- 修改 (Modification) : 仅改变这些权重以引导模型的行为,在减少偏见的同时保留模型其余部分的知识完好无损。
解决方案: 局部对比编辑
这篇论文的核心见解是,通过对比最能识别偏见。研究人员不是孤立地观察单个模型,而是将目标模型 (Target Model) (我们想要修复的模型) 与参考模型 (Reference Model) (在相关属性上表现不同的模型) 进行比较。
如下图所示,这是一个两步走的方法。
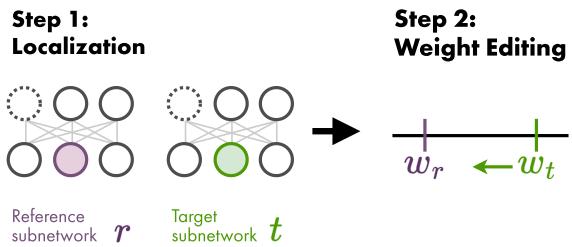
第 1 步: 通过剪枝进行定位
我们如何确定哪些权重是“刻板印象”的?研究人员使用了一种称为迭代幅度剪枝 (Iterative Magnitude Pruning, IMP) 的技术,这通常与“彩票假设”相关联。
其思路是训练一个模型,然后移除 (剪枝) 幅度最小 (数值最接近零) 的权重,假设它们是最不重要的。如果重复这样做,你最终会得到一个“稀疏子网络”——原始模型的骨架,它仍然能很好地执行任务。
研究人员发现,如果你创建一个“刻板印象子网络”和一个“反刻板印象子网络”,它们大部分看起来是一样的。然而,有一小部分权重会表现不同。这些差异就是偏见藏身之处。
他们提出了两种方法来识别这些特定的权重:
1. 基于掩码的定位 (Mask-based Localization)
这种方法关注子网络的结构。“掩码”是一个二进制网格,表示哪些权重被保留 (1) ,哪些被剪枝 (0) 。研究人员假设,在一个模型中存在但在另一个模型中被剪枝的权重,很可能导致了它们在性别问题上的不同行为。
他们通过寻找目标掩码 (\(m_t\)) 和参考掩码 (\(m_r\)) 之间的差异来计算定位掩码 \(b\):
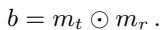
简单来说: 我们在寻找那些在参考模型中“开启”但在目标模型中“关闭” (反之亦然) 的权重。
2. 基于数值的定位 (Value-based Localization)
这种方法关注权重的实际数值。即使两个模型保留了相同的权重,该权重的值可能会有很大差异。研究人员选择目标模型和参考模型之间绝对差值最大的前 \(k\) 个权重。
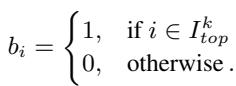
这里,\(I_{top}^k\) 代表参考模型和目标模型分歧最大的权重的索引。
第 2 步: 编辑策略
一旦负责偏见的特定权重被识别 (定位) ,下一步就是编辑它们。研究人员探索了几种数学运算,利用参考模型的信息 (\(\theta_r\)) 来转换目标模型的权重 (\(\theta_t\)) 。
图 2 直观地总结了这些定位和编辑策略是如何相互作用的。
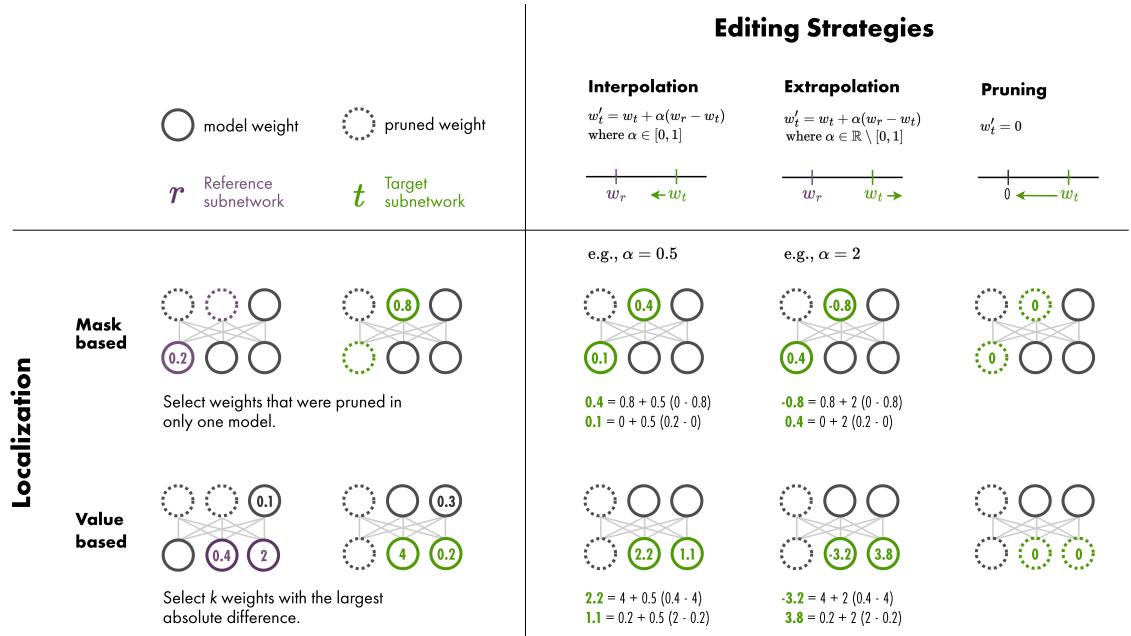
让我们看看具体使用的编辑公式:
权重插值 (Weight Interpolation, IP) : 这将目标权重向参考权重移动。如果 \(\alpha=0.5\),新权重正好位于刻板印象版本和反刻板印象版本的中间。如果 \(\alpha=1\),目标模型直接采用参考模型的权重。
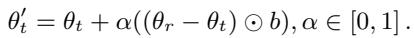
权重外推 (Weight Extrapolation, EP) : 这才是最有趣的地方。我们可以使用大于 1 或小于 0 的 \(\alpha\) 值。这允许我们将模型更进一步推向参考模型的方向,甚至推向相反的方向,从而放大差异。
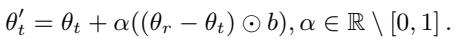
剪枝 (Pruning, PR) : 该策略简单地将识别出的“偏见”权重设为零,有效地将它们从计算中移除。
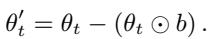
掩码切换 (Mask Switch, SW) : 这是基于掩码定位特有的策略,它将参考模型的掩码应用到目标模型上。
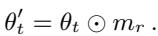
实验设置: 制造“性别歧视”的 BERT
为了测试这种方法是否有效,研究人员需要清晰的测试用例。他们使用了标准的 BERT 模型,并在使用反事实数据增强 (Counterfactual Data Augmentation) 人为修改过的维基百科数据上对其进行了微调。
- 刻板印象模型: 在强化性别关联的数据上微调 (例如,“护士……她”) 。
- 反刻板印象模型: 在交换了关联的数据上微调 (例如,“护士……他”) 。
- 中立模型: 在未修改的数据上微调 (作为对照) 。
然后,他们使用标准的基准测试如 WEAT (词嵌入关联测试) 、StereoSet 和 CrowS-Pairs 来测量偏见。
他们找到偏见了吗?
是的。定位步骤显示,负责性别偏见的权重并不是随机分布的。如图 3 所示,选定的权重 (彩色条) 倾向于聚集在特定的组件中,特别是网络较深层的注意力机制的输出稠密层 (output dense layers) 。
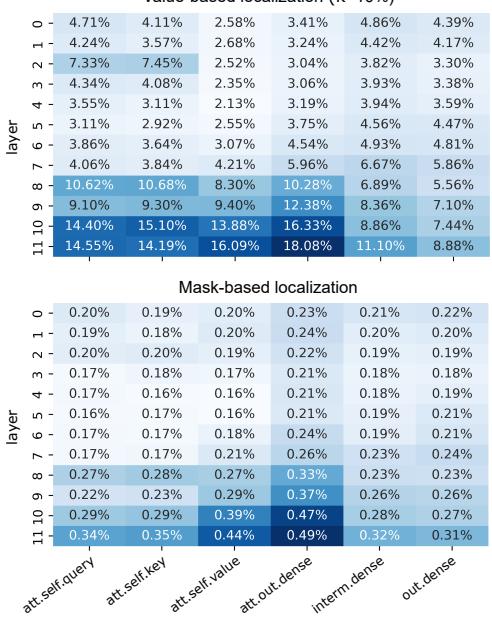
至关重要的是, 只有不到 0.5% 的总权重被确认为相关。这证实了偏见并不是模型“大脑”的整体属性,而是局限于特定的连接中。
关键结果: 控制偏见
这篇论文最令人兴奋的结果是对控制能力的展示。通过仅编辑这一小部分权重 (<0.5%) ,研究人员能够显著引导模型的偏见。
在下图中,x 轴代表偏见得分 (WEAT) 。
- 蓝线代表一个刻板印象目标模型正在被朝向反刻板印象参考模型编辑。
- 红线代表一个反刻板印象目标模型正在被朝向刻板印象参考模型编辑。
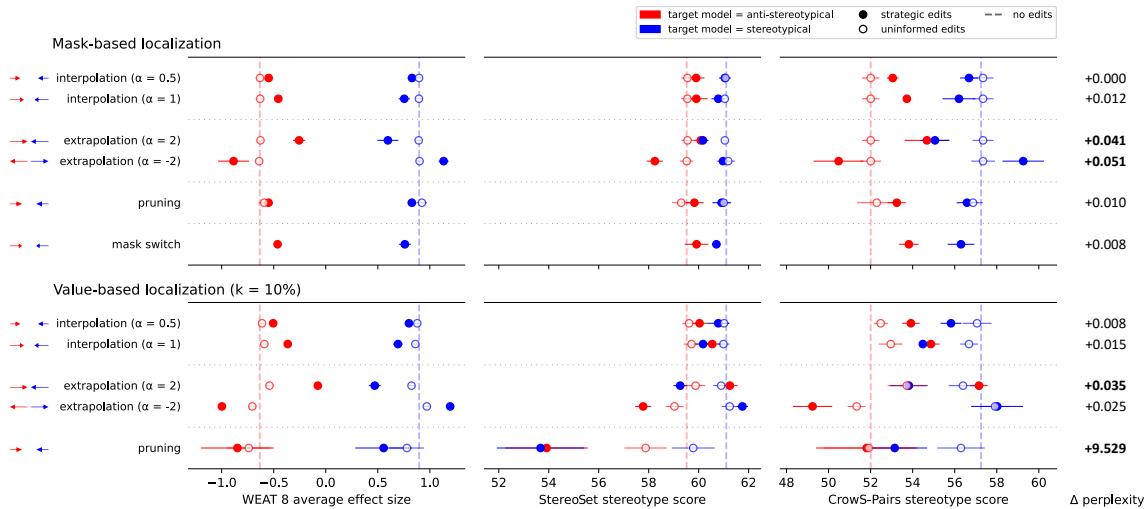
结果要点:
- 有效: 随着编辑强度 (\(\alpha\)) 的增加,蓝线向左移动 (减少偏见) ,红线向右移动 (增加偏见) 。
- 定位很重要: 空心圆圈代表“无信息编辑”——即随机选择权重进行编辑。注意这些点几乎没有移动。这证明你不能仅仅编辑任意权重;你必须找到负责刻板印象的特定权重。
- 外推法的威力: 通过使用外推法 (例如 \(\alpha=2\)) ,研究人员可以将一个刻板印象模型推过“中立”点,将其转变为一个反刻板印象模型。
模型还能正常工作吗?
模型编辑的一个常见担忧是破坏模型理解语言的能力 (困惑度,Perplexity) 。如果你移除了“性别”的概念,模型会忘记“人”是什么吗?
研究人员测试了这种敏感性。图 6 (b) 显示了困惑度 (y 轴) 随权重因子 (\(\alpha\)) 的变化。
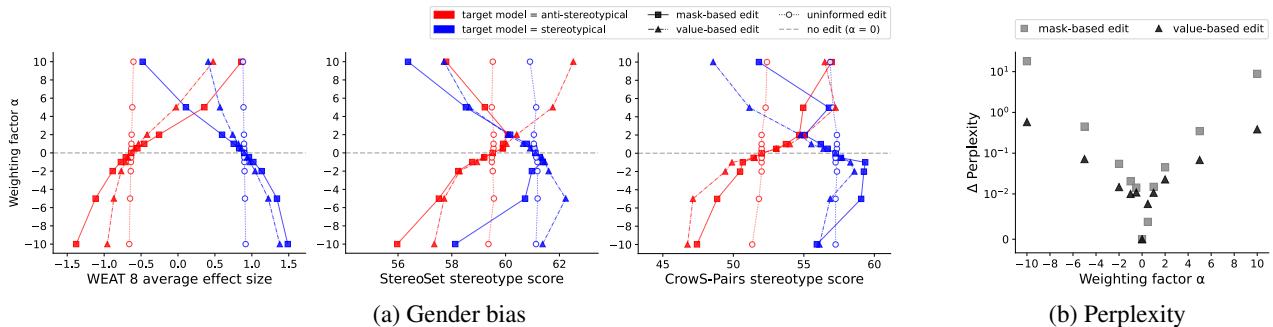
对于大多数策略,困惑度的变化可以忽略不计 (点停留在零附近) 。然而, 基于数值的剪枝 (移除数值差异最大的权重) 导致困惑度大幅激增 (见图 6b 中向上飙升的黑色三角形) 。这表明,虽然这些权重包含偏见,但它们对模型的通用功能也至关重要。相比之下,插值和外推被证明是安全且有效的。
应用于中立模型
最后,研究人员将此方法应用于一个“中立”模型——一个没有被人为强迫变成性别歧视或反性别歧视的模型。他们能减少标准模型中存在的自然偏见吗?
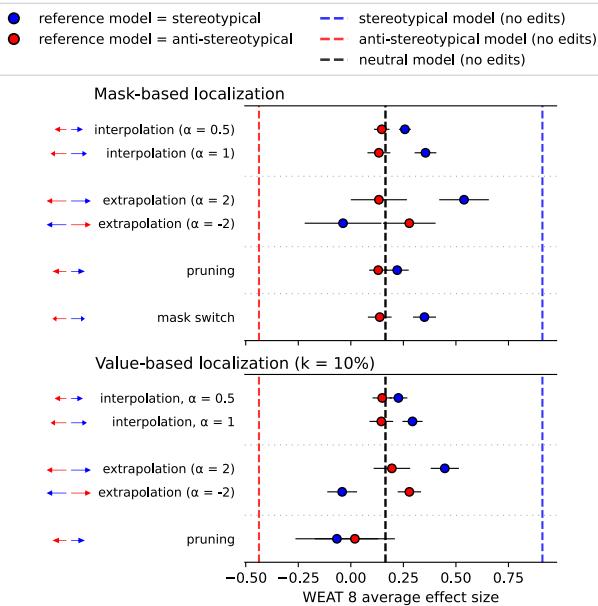
如图 7 所示,使用刻板印象参考模型使他们能够识别并从中立模型中“减去”偏见 (使用负向外推,\(\alpha = -2\),显示为蓝色) 。这证实了该技术适用于现实场景,而不仅仅是人工构建的测试床。
结论
论文《Local Contrastive Editing of Gender Stereotypes》为 AI 安全迈出了令人信服的一步。它使我们从简单地观察偏见,转向了对其进行积极的手术。
主要收获:
- 偏见是局部的: 刻板印象被编码在模型参数的一个非常小的子集 (<0.5%) 中,主要位于深层注意力层。
- 对比是关键: 我们可以通过将模型与其“对立面” (参考模型) 进行比较来找到这些参数。
- 可编辑性: 我们可以对这些权重进行插值或外推,从而平滑地引导模型的性别偏见,而无需重新训练整个网络或破坏其语言能力。
这种方法为“参数高效”的偏见缓解开辟了新途径。未来的开发者可能不需要大规模的重新训练流程,而只需下载一个“补丁”——一小组微小的权重调整——就能修正其大型语言模型中特定的社会偏见。