](https://deep-paper.org/en/paper/2410.18050/images/cover.png)
在大型语言模型 (LLM) 飞速发展的世界中,我们见证了向“长上下文”能力的巨大推进。像 Gemini 1.5 或 GPT-4-Turbo 这样的模型号称能够在一个提示词中处理数十万个 token——相当于整本小说或整个代码库。理论上,这应该能解决基于大型文档回答复杂问题的问题。
然而,现实情况却有所不同。当面对海量数据时,LLM 经常遭遇 “迷失中间” (lost in the middle) 现象: 它们擅长记住文档的开头和结尾,但往往会遗忘或臆造 (产生幻觉) 深埋在中间的细节。
解决这个问题的传统方法是检索增强生成 (RAG) 。 普通 RAG (Vanilla RAG) 将文档切分成小块,找到最相关的部分,然后将其喂给 LLM。虽然这种方法很高效,但它往往会破坏全局上下文。你可能会得到一个包含特定人名的片段,但却丢失了解释 为什么 这个人很重要的那一段落。
LongRAG 应运而生。由中国科学院和清华大学的研究人员提出,LongRAG 是一种新的范式,旨在融合两者的优点。它结合了长上下文模型的“宏观”视野与检索系统的精确性。在这篇文章中,我们将剖析 LongRAG 的工作原理,解释它为何优于现有方法,以及它是如何处理全局信息与事实细节之间的微妙平衡的。
问题所在: 为何普通 RAG 和长上下文 LLM 会受挫
要理解 LongRAG,我们需要先了解当前长上下文问答 (LCQA) 方法的局限性。LCQA 任务通常涉及“多跳”推理——你不能只找到一句话来回答问题;你需要将线索 A 和线索 B 连接起来才能找到答案 C。
- 长上下文 LLM: 你可以将整个文档喂给模型。然而,尽管上下文窗口很长,模型在上下文增长时的推理能力却会下降。它们难以在噪声中精确定位特定证据。
- 普通 RAG (Vanilla RAG) : 这种方法检索与查询最相似的前 \(k\) 个片段。缺点是什么? 碎片化。 通过将文本切分成固定的块 (例如 200 个单词) ,语义连接被切断了。模型可能会检索到一个提到“大学”的片段,但错过了前一句提到的大学名称。此外,检索通常会拉入看起来相关但实际上无关的“噪声”片段,从而混淆生成器。
LongRAG 旨在通过采用 “双视角” 方法来解决这些问题: 它显式地提取全局信息 (背景/结构) 并过滤出事实细节 (精确证据) 。
LongRAG 架构
LongRAG 系统是模块化的,由四个“即插即用”的组件组成。与通常只是 检索 \(\rightarrow\) 生成 的标准 RAG 不同,LongRAG 在中间添加了复杂的处理步骤来提炼信息。
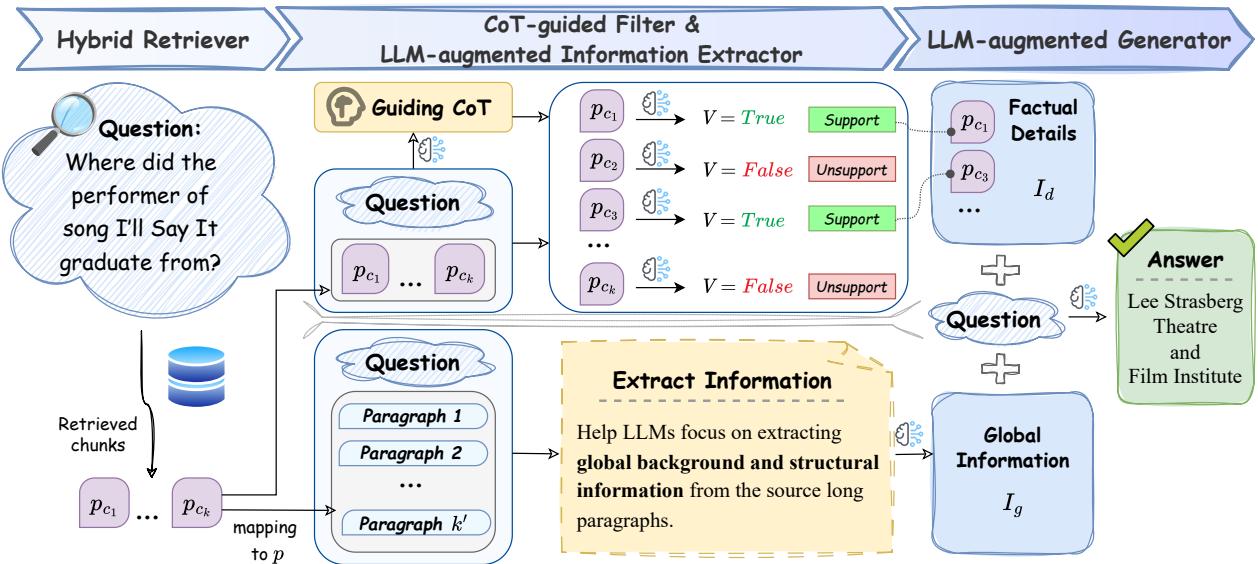
如图 2 所示,流程如下:
- 混合检索器 (Hybrid Retriever) : 检索相关片段。
- LLM 增强的信息提取器 (LLM-Augmented Information Extractor) : 拉远视角以理解全局上下文 (\(I_g\)) 。
- CoT 引导的过滤器 (CoT-Guided Filter) : 拉近视角以验证事实细节 (\(I_d\)) 。
- LLM 增强的生成器 (LLM-Augmented Generator) : 结合两种视角来回答问题。
让我们详细拆解这些组件。
1. 混合检索器
流程始于混合检索策略。系统使用双编码器进行快速的粗粒度检索 (找到大致相关区域) ,并使用交叉编码器进行细粒度重排序 (评分特定片段回答问题的程度) 。这确保了初始片段池的高质量。
2. LLM 增强的信息提取器 (\(I_g\))
该组件解决了普通 RAG 的“碎片化”问题。如果我们只看小片段,就会丢失故事的全貌。
提取器首先将检索到的短片段 (\(p_c\)) 映射回其源段落 (\(p\)) 。它本质上是在问: “这个片段来自哪里?”并拉取周围的上下文。
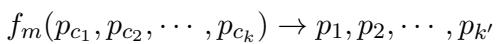
一旦系统拥有了较长的父段落,它就会利用 LLM 提取全局信息 (\(I_g\)) 。 这不仅仅是总结;它使用特定的提示词 (\(prompt_e\)) 来识别与问题 (\(q\)) 相关的背景信息和结构关系。
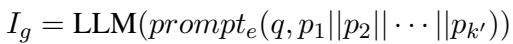
结果 \(I_g\) 充当了相关文档的浓缩“地图”,保留了简单的切分会破坏的连接。
3. CoT 引导的过滤器 (\(I_d\))
当提取器关注大局时, CoT 引导的过滤器则充当细节的严格把关人。在长文档中,“证据密度”很低——这意味着大部分文本都是无关的噪声。
该组件使用思维链 (Chain-of-Thought, CoT) 推理来确定检索到的片段是否有助于回答问题。这是一个两阶段的过程:
阶段 A: CoT 指导 首先,LLM 根据检索到的片段生成一个“思维过程”或线索。它尝试推理出回答问题需要什么样的信息。

阶段 B: 过滤 接下来,系统根据这个 CoT 指导检查每个片段。它分配一个二元标签: True (支持) 或 False (不支持) 。
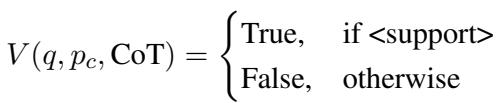
只有标记为“True”的片段会被保留。这组高质量、经过验证的片段被定义为事实细节 (\(I_d\)) 。
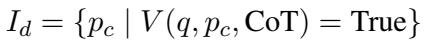
这一步至关重要,因为它移除了经常导致标准 RAG 系统产生幻觉的“噪声”。
4. LLM 增强的生成器
最后是生成阶段。生成器接收的不仅仅是一堆随机片段。它接收两个结构化的输入:
- \(I_g\): 全局信息 (上下文/背景) 。
- \(I_d\): 事实细节 (验证过的证据) 。
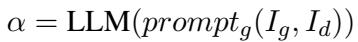
通过与这两种视角交互,生成器能够以高准确率和低幻觉回答复杂的多跳问题。
指令微调: 教模型如何推理
这就论文的关键贡献之一是他们训练组件的方式。他们没有直接使用现成的提示词,而是创建了一个高质量的数据集,称为 LRGinstruction 。
利用更大的“教师”模型 (ChatGLM3-32B) ,他们自动生成了提取器和过滤器的训练数据。这种“指令微调”确保了实际系统中使用的较小模型能够成为遵循指令、提取上下文和过滤噪声的专家。值得注意的是,他们仅使用了 2,600 个样本进行微调就取得了顶级的效果。
实验结果
研究人员在三个具有挑战性的多跳问答数据集上测试了 LongRAG: HotpotQA、2WikiMultiHopQA 和 MusiQue 。 他们将该系统与以下方法进行了比较:
- 长上下文 LLM 方法: LongAlign, LongLoRA。
- 高级 RAG: Self-RAG, CRAG。
- 普通 RAG (Vanilla RAG) : 使用 GPT-3.5, Llama3, 和 Qwen 等模型。
整体性能
LongRAG 显著优于竞争对手。如下表所示,LongRAG (特别是在微调后,即 “SFT”) 始终取得最高分。
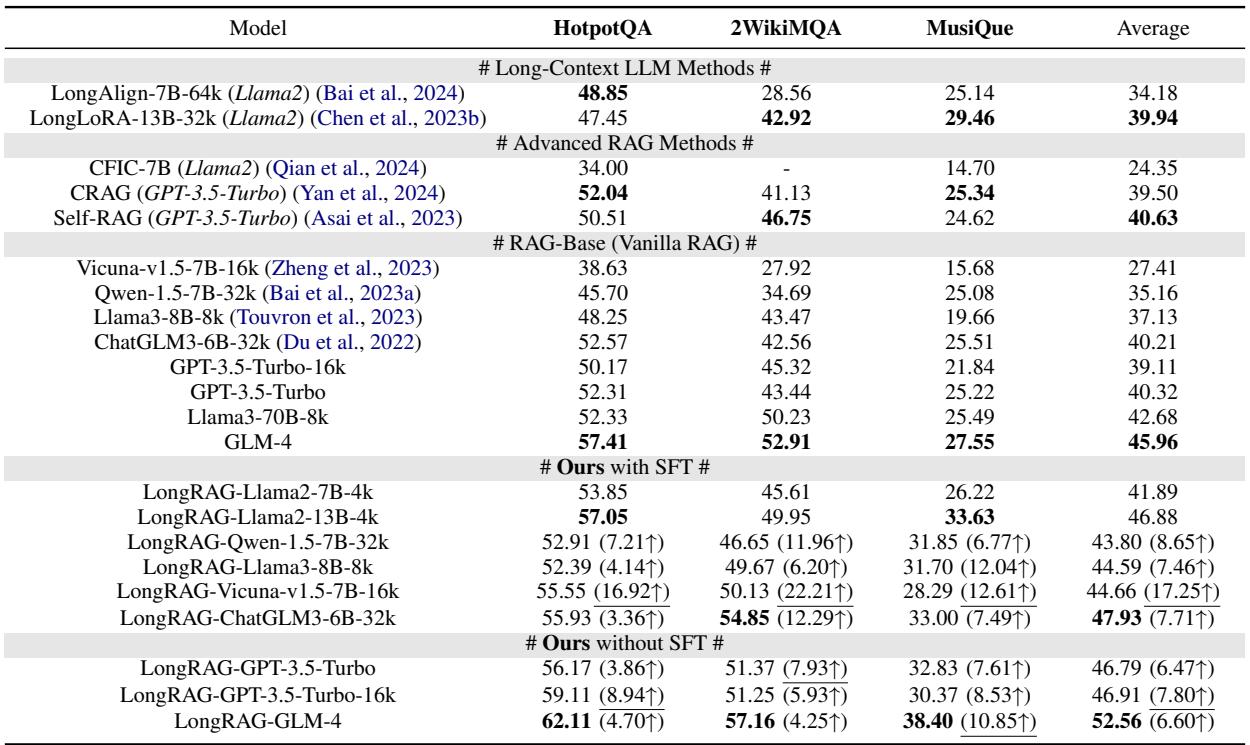
值得注意的是,LongRAG 相比普通 RAG 实现了超过 17% 的相对提升。它甚至比 Self-RAG (一种高度复杂的自适应检索方法) 高出 6% 以上。
为什么我们需要提取器和过滤器? (消融实验)
LongRAG 的复杂性值得吗?作者进行了消融实验,逐一移除提取器和过滤器以观察结果。
- RAG-Base: 表现最差。
- RAG-Long: 将片段映射回段落但不进行处理。好一些,但噪声很大。
- Ext. (仅提取器) : 显著提升。全局上下文很有用!
- Fil. (仅过滤器) : 轻微提升。减少噪声有帮助,但会丢失上下文。
- E&F (提取器 & 过滤器) : 获胜者。
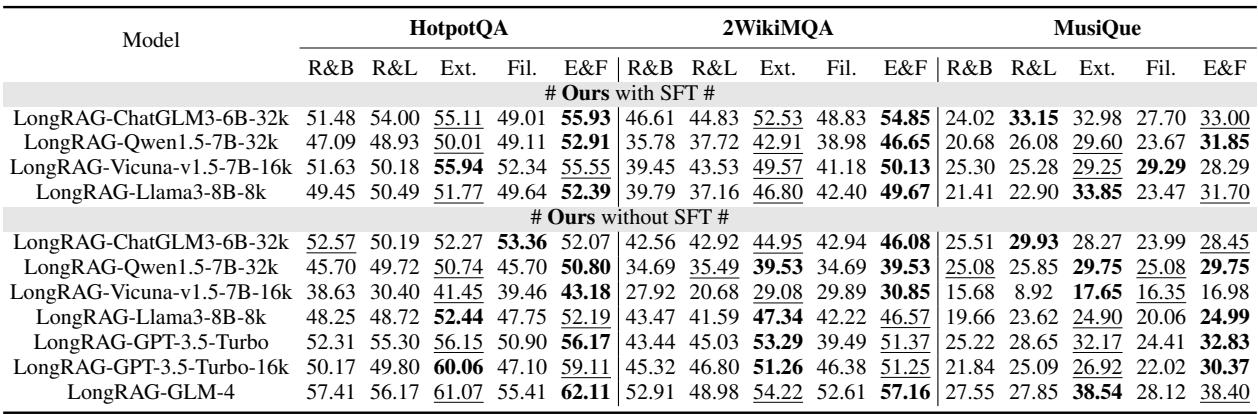
这种组合 (E&F) 确保模型既有理解问题的上下文,又有回答问题的精确细节,而不会被垃圾文本淹没。
效率: 事半功倍
对于开发者来说,最实际的发现可能在于 token 使用量 。 由于 CoT 引导的过滤器在移除无关片段方面非常激进,发送给生成器的最终提示词比其他方法短得多。
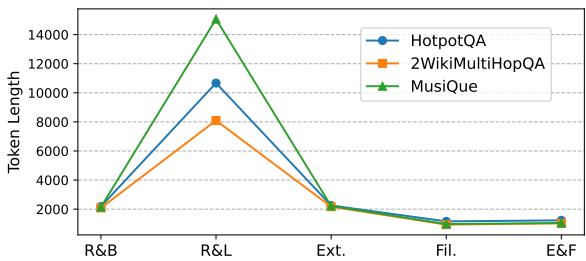
如图 3 所示,“E&F”策略 (最底下的线) 相比 RAG-Long 或标准检索方法大幅减少了输入大小 (token 长度) 。这意味着更低的 API 成本和更快的生成速度 , 同时还能实现更高的准确率。
结论
LongRAG 代表了使检索增强生成在复杂、长上下文任务中变得稳健的重要一步。通过认识到 LLM 既需要“宏观视角” (全局信息) 又需要“脚踏实地” (事实细节) ,作者创建了一个解决“迷失中间”问题的系统。
关键要点:
- 双视角: 结合全局上下文提取与严格的细节过滤优于简单的切块。
- 降噪: CoT 引导的过滤器移除了无关数据,防止了幻觉并节省了 token。
- 高性价比: LongRAG 允许较小的、经过微调的模型 (如 60-70 亿参数) 在特定任务上超越巨大的模型 (如 GPT-3.5) 。
对于从事问答系统研究的学生和研究人员来说,LongRAG 证明了我们并不总是需要 更大 的上下文窗口;有时,我们只需要 更聪明 的方式来处理我们拥有的上下文。