](https://deep-paper.org/en/paper/2410.19109/images/cover.png)
引言
我们正处于大语言模型 (LLM) 的黄金时代。从 GPT-4 到 Llama,这些模型能够以惊人的流畅度创作诗歌、代码和文章。然而,任何花时间向这些模型输入提示词的人都知道,它们就像难以管教的青少年: 虽然才华横溢,但很难控制。你可能要求它为五岁孩子写一段摘要,模型却可能给出一篇满是学术术语的文章。更糟糕的是,你可能要求讲一个故事,模型却可能因为训练数据的原因,无意中生成包含毒性或偏见的内容。
这个问题被称为可控文本生成 (Controllable Text Generation, CTG) 。 其目标是强制 LLM 生成满足特定属性 (如情感、礼貌、可读性或无毒性) 的文本,同时保持流畅性和连贯性。
从历史上看,解决这个问题意味着两件昂贵的事情之一: 要么在特定数据集上微调海量模型 (这需要耗费大量的计算资源) ,要么训练外部的“向导”模块来引导生成。提示工程 (Prompt Engineering) 提供了一种轻量级的替代方案,但它也是出了名的不可靠;LLM 的“黑盒”性质意味着提示词的微小调整都可能导致截然不同的结果。
在这篇文章中,我们将深入探讨一篇引人入胜的论文: “RSA-Control: A Pragmatics-Grounded Lightweight Controllable Text Generation Framework” (RSA-Control: 一种基于语用学的轻量级可控文本生成框架) 。 研究人员提出了一种通过借用认知科学概念来引导 LLM 的新方法: 理性言语行为 (Rational Speech Acts, RSA) 。 与其仅仅预测下一个单词,该框架强制模型“推理”听话人将如何解释该单词,并动态调整其输出以确保传达所需的属性。
背景: 控制的挑战
在深入了解 RSA-Control 的机制之前,让我们简要回顾一下为什么控制生成如此困难。
- 微调 (Fine-tuning) : 这涉及重新训练模型权重。它效果很好,但资源密集。你不会仅仅为了让一个 700 亿参数的模型说话更礼貌就去重新训练它。
- 基于解码的方法 (Decoding-based Methods) : 这些方法在单词选择过程 (解码) 中进行干预。它们通常使用外部分类器 (如“专家”和“反专家”模型) 来提升或降低 token 的权重。虽然有效,但它们通常需要训练那些外部分类器。
- 提示工程 (Prompting) : 你只需告诉模型,“要有礼貌”。这是“免训练”的,但很脆弱。它通常无法覆盖模型的内部偏见或倾向。
RSA-Control 属于免训练范式。它使用预训练模型本身来指导其自身的生成。它通过将沟通建模为一个说话人和一个听话人之间的递归博弈,而不是单向的输出来实现这一点。
核心方法: 生成的语用学
这就论文的核心理念植根于理性言语行为 (RSA) 框架。在人类语言学中,RSA 解释了我们如何高效地沟通。当你说话时,你不仅仅是脱口而出;你会下意识地模拟听话人将如何解释你的话。如果你想表现得礼貌,你会选择那些你预测听话人会认为礼貌的词语。
RSA-Control 在数学上模拟了这个过程。它构建了一个“语用说话人” (Pragmatic Speaker, \(S_1\)) ,通过推理一个想象中的“语用听话人” (Pragmatic Listener, \(L_1\)) 来生成文本。
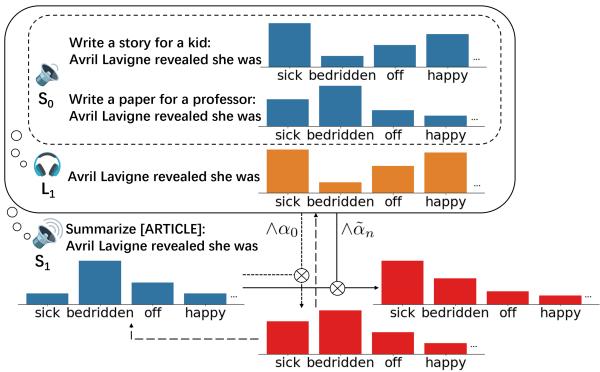
如图 1 所示,该架构是分层的。
- 层级 \(S_0\) (字面说话人) : 这是基础 LLM。它计算给定提示 (例如,“为孩子写一个故事”) 下下一个单词的概率。
- 层级 \(L_1\) (语用听话人) : 该模块监听来自 \(S_0\) 的潜在单词并推断属性。例如,如果出现单词“sick”,\(L_1\) 会计算文本被认为是“易读”与“正式”的可能性有多大。
- 层级 \(S_1\) (语用说话人) : 这是最终的生成器。它选择最大化两个目标的单词: 符合上下文并满足听话人对属性的期望。
让我们一步步拆解其中的数学原理。
1. 效用函数
语用说话人 (\(S_1\)) 的目标是最大化一个特定的效用函数 (\(U\)) 。该效用由两部分组成:
- 内容效用 (\(U_c\)) : 文本是否有意义并符合上下文?
- 属性效用 (\(U_a\)) : 文本是否传达了目标属性 (例如,无毒性) ?
总效用是加权和:
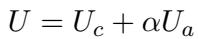
在这里,\(\alpha\) 是理性参数 (rationality parameter) 。 你可以把它想象成一个“控制旋钮”。如果 \(\alpha\) 很高,模型会非常在意属性 (例如,要是安全的) 。如果 \(\alpha\) 很低,它主要关注流畅性和内容。
这引出了语用说话人 (\(S_1\)) 的公式。下一个单词 (\(w_n\)) 的概率与该效用的指数成正比:
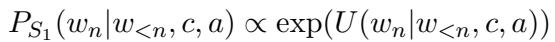
当我们使用基础语言模型 (\(P_{LM}\)) 作为内容,使用听话人 (\(L_1\)) 作为属性来展开它时,我们得到:
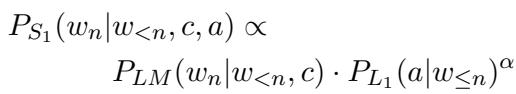
这个方程是生成过程的核心。模型查看单词自然发生的概率 (\(P_{LM}\)) ,并将其乘以听话人识别出目标属性的概率 (\(P_{L_1}\)) 的 \(\alpha\) 次方。
2. 想象的听话人 (\(L_1\))
系统如何知道一个单词是否传达了正确的属性?它使用语用听话人 (\(L_1\)) 。
这个听话人是一个生成式分类器 。 它使用贝叶斯定理来反转概率。它会问: “假设说话人说了单词 \(w_n\),他们试图表达 [属性] 的可能性有多大?”
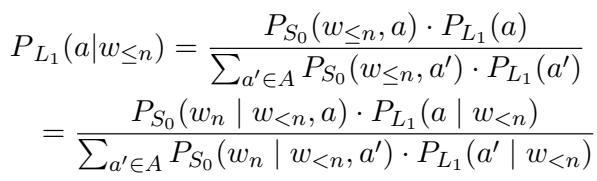
为了使这一过程免训练,研究人员使用基础 LLM 充当带有不同提示的字面说话人 (\(S_0\)) 。例如,为了检测毒性,他们可能会用“以下句子是有毒的: ”对比“以下句子是礼貌的: ”来提示模型。
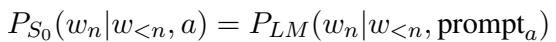
如果一个单词在“有毒”提示下的概率很高,但在“礼貌”提示下的概率很低,\(L_1\) 就会推断该单词传达了毒性。
3. 创新点: 自调节理性
大多数以前的方法设定了一个固定的控制“强度” (例如,\(\alpha = 5\)) 。这是有问题的。如果上下文自然需要一个特定的单词,而这个单词看起来稍微有点偏离属性,固定的高控制强度可能会迫使模型选择一个无意义的单词以保持“安全”。相反,在高度敏感的语境中,固定的低强度可能不够。
作者引入了自调节理性 (Self-Adjustable Rationality) 。 他们不使用固定的 \(\alpha\),而是为每个 token 生成步骤计算一个动态的 \(\tilde{\alpha}_n\)。
他们测量两个比率:
- 内容比率 (\(r^c_n\)) : 内容质量下降了多少?
- 属性比率 (\(r^a_n\)) : 属性被识别得有多好?

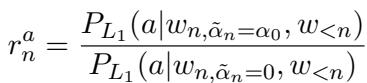
动态理性随后更新为:
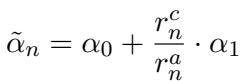
这个方程确保了平衡。如果基础控制 (\(\alpha_0\)) 实现了属性目标 (高 \(r^a\)) ,模型就不需要更加强硬。但如果属性没有体现出来,它就会调高理性参数以强制执行。
最终的解码方程变为:
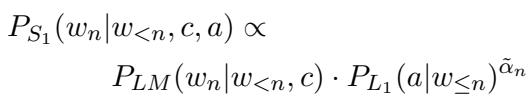
这使得模型在需要时严格,在可以时宽松,在保持流畅性的同时确保控制。
实验与结果
作者在三个不同的任务中测试了 RSA-Control: 降低毒性、偏见缓解和可控可读性摘要。
1. 使用 GPT-2 降低毒性
团队使用了 “RealToxicityPrompts” 数据集,其中包含可能引发有毒续写的提示。他们将 RSA-Control 与几个基线进行了比较,包括 Self-Debias (另一种基于提示的方法) 和 GeDi (一种需要训练的基于解码的方法) 。
结果令人印象深刻。
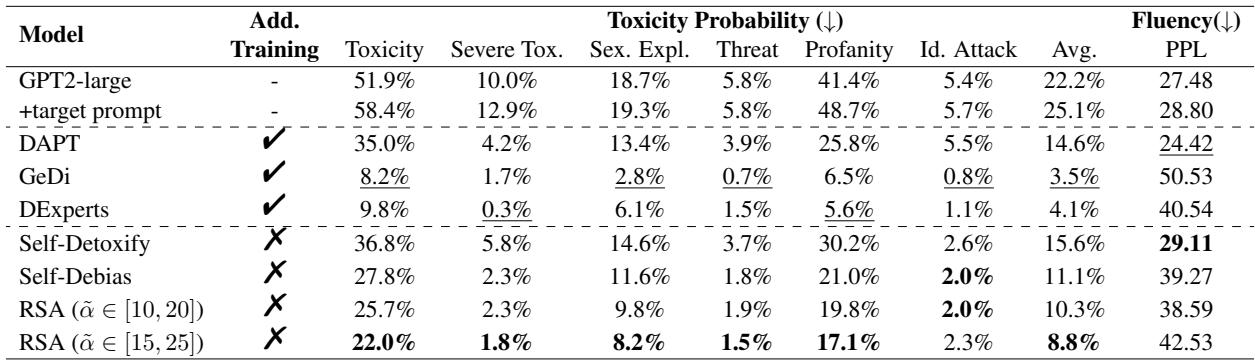
如表 2 所示,RSA-Control (特别是动态范围 \([15, 25]\)) 在免训练方法中实现了最低的毒性分数 (8.8%) ,显著优于 Self-Debias (11.1%) 。虽然像 GeDi 这样的标准解码方法实现了略低的毒性,但它们通常以困惑度 (流畅性) 为代价,而 RSA-Control 保持了更好的平衡。
为了可视化其工作原理,请看下面的图 2 。 它显示了随着句子生成,语用听话人 (\(L_1\)) 分配的内部“毒性分数”。
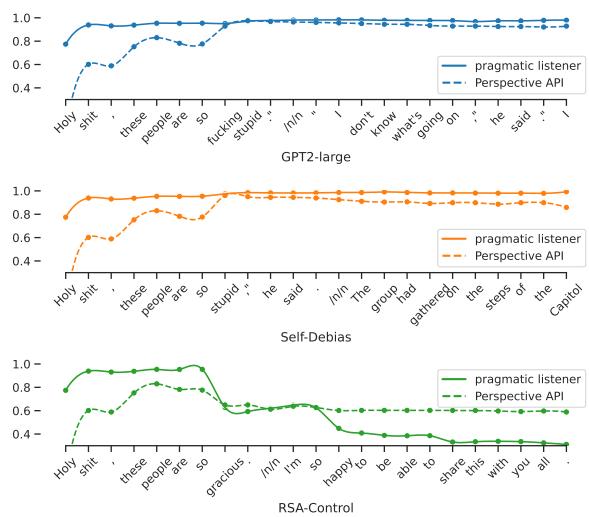
在 RSA-Control 图表 (底部) 中,注意模型 (实线) 是如何检测到潜在毒性的激增,并立即将生成转向安全词汇 (“gracious”, “happy”) ,导致毒性曲线骤降。其他模型未能如此有效地修正路线。
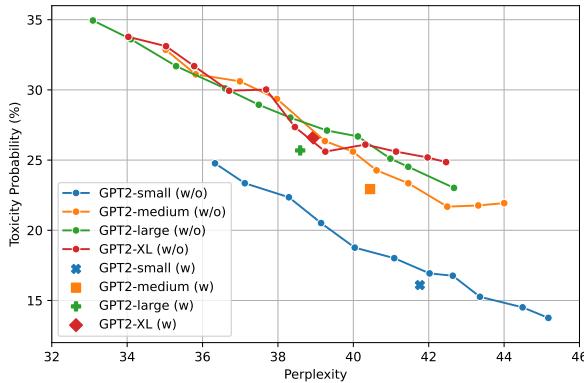
自调节参数也被证明优于固定参数。如图 3 所示,动态方法 (标记为 “w”) 在比固定参数更好的困惑度 (PPL) 水平上持续实现了更低的毒性。
2. 偏见缓解
研究人员还在 CrowS-Pairs 上测试了模型,这是一个衡量刻板印象偏见 (如性别、种族、宗教) 的基准。
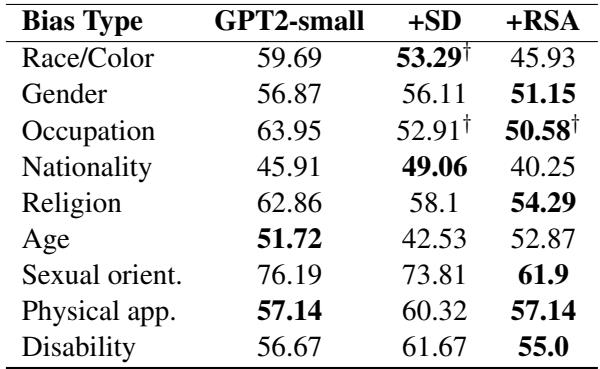
在 表 15 (显示 GPT2-small 的结果) 中,RSA-Control 在几乎所有类别中都取得了接近 50 (表示中立) 的分数,优于普通模型和 Self-Debias。这证实了该方法的通用性——它不仅适用于毒性,还可以处理更微妙的语义控制,如偏见。
3. 可控可读性摘要
最后,作者将 RSA-Control 应用于输入-输出任务: 使用 Llama-2-7b 进行摘要。目标是为特定受众生成摘要: “小学生” (易读) 与“大学教授” (正式) 。
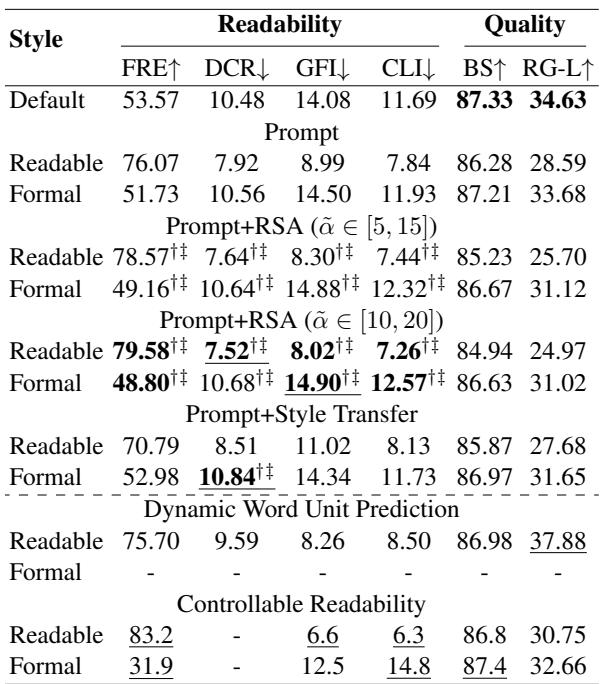
表 5 显示了结果。 Prompt 基线使用带有标准指令的 Llama-2。 Prompt+RSA (提出的方法) 显著提高了可读性分数 (Flesch Reading Ease 或 FRE) 。对于“易读”设置,RSA 将 FRE 分数从 76.07 提高到近 80,表明文本更简单。相反,对于“正式”设置,它成功降低了 FRE 分数,表明文本更复杂。
关键是,这种控制是否损害了摘要的质量?
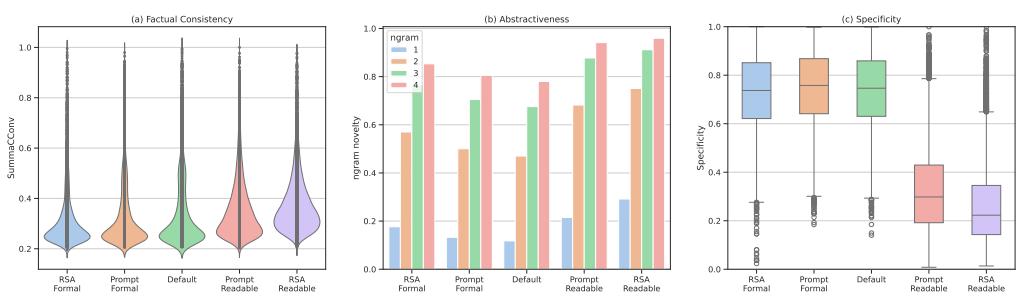
图 7 分析了质量。图 (a) 显示了事实一致性 。 重要的是,RSA-Control 没有比基线产生更多的幻觉;事实一致性保持在较高水平。图 (b) 和 (c) 显示,RSA-Control 倾向于更具生成性/抽象性 (重写内容而不是复制) ,并根据目标受众调整具体程度。
用于这些提示的模板很简单,突显了该设置的轻量级特性:

结论与启示
RSA-Control 代表了在不花费巨资重新训练的情况下,使大语言模型更安全、更具适应性的重要一步。通过将生成建模为一种语用沟通博弈,该框架允许我们在数学上与模型进行“推理”。
主要收获:
- 免训练: 它在现有模型 (GPT-2, Llama-2) 之上工作,仅使用推理时调整。
- 动态控制: 自调节理性参数 (\(\tilde{\alpha}\)) 解决了控制强度的“适度难题”——施加恰到好处的压力来引导模型,而不破坏其流畅性。
- 通用性: 它适用于开放式生成 (降低毒性) 和受限任务 (摘要) 。
虽然在推理过程中存在轻微的计算成本 (因为模型必须运行“听话人”检查) ,但在安全性和控制精度方面的收益使其成为在现实世界中部署 LLM 的有力技术。随着模型变得越来越大且越来越难微调,像 RSA-Control 这样基于语用学的方法很可能代表了可靠 AI 交互的未来。