](https://deep-paper.org/en/paper/2410.19134/images/cover.png)
想象一下,一位朋友对你说: “我没事。”根据他们的语气、音高和语速,这可能意味着他们真的很高兴,或者无所谓,甚至可能非常愤怒。长期以来,人工智能一直将语音情感视为一个分类任务——仅仅将音频片段归类为“悲伤”、“快乐”或“愤怒”等类别。
但人类的情感很少如此简单。它是微妙的、混合的,并且不断变化的。一个简单的标签无法捕捉到那种“因兴奋而颤抖”或“语速很快且带有不满语气”的复杂性。
这种局限性催生了 语音情感描述 (Speech Emotion Captioning, SEC) 这一领域,致力于生成描述语音情感的自然语言。然而,描述情感比看起来要难。目前的模型经常产生“幻觉”——编造不存在的事实或情感——或者在听到新的声音时无法进行泛化。
在这篇文章中,我们将深入探讨 AlignCap , 这是由中国科学技术大学的研究人员提出的一个新颖框架。AlignCap 通过混合使用知识蒸馏 (Knowledge Distillation) 和偏好优化 (Preference Optimization),不仅将语音处理与文本对齐,还将语音处理与人类偏好对齐,从而解决了上述问题。
问题所在: 幻觉与分布差距
为什么目前的模型会失败?研究人员确定了两个主要罪魁祸首: 幻觉 (Hallucination) 和 泛化差距 (Generalization gaps) 。
当一个 AI 模型听取语音并试图对其进行描述时,它面临着“训练-推理不匹配”的问题。大多数此类模型在文本上进行了大量训练,却被要求从音频中进行推理。由于语音数据的统计分布与文本数据不同,模型会感到困惑。
如下图所示,这导致了三种类型的错误:
- 忠实性幻觉 (Faithfulness Hallucination): 模型忽略用户的指令或编造内容。
- 事实性幻觉 (Factuality Hallucination): 模型误解了语气 (例如,将愉快的声音称为“不满”) 。
- 泛化能力缺失 (Loss of Generalization): 模型默认为通用的、无用的短语,如“一个人在说话”,而不是捕捉具体的情感线索。

为了解决这个问题,我们需要弥合模型“看”文本和“听”音频之间的差距。
背景: 对齐的挑战
在多模态 AI 中,“对齐”是指将不同类型的数据 (如音频和文本) 映射到一个共享空间,以便模型理解它们代表相同的概念。
传统方法通常尝试在大型语言模型 (LLM) 开始解码之前对齐这些模态。它们可能会使用对比学习 (Contrastive Learning, CL) 或投影层来强制音频嵌入看起来像文本嵌入。
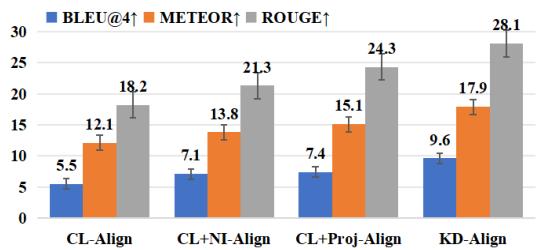
研究人员进行了实验,以观察这些传统对齐方法的表现。如下表所示,虽然对齐 (CL-Align 和 CL+Proj-Align) 相比无对齐提高了性能,但仍有很大的提升空间。
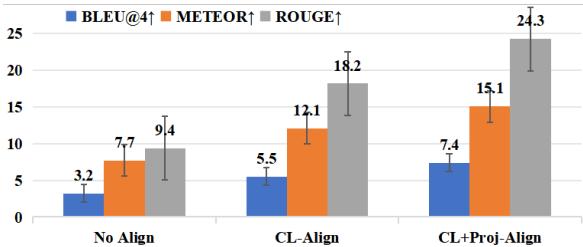
解码前对齐的问题在于 信息丢失 。 通过过早地强迫音频严格匹配文本嵌入,我们丢失了语音特有的丰富、细粒度的细节。AlignCap 采取了不同的方法: 它在 LLM 解码过程 中 和 后 对齐模态。
AlignCap 框架
AlignCap 建立在两个主要支柱之上,旨在引导大型语言模型 (具体为 LLaMA-7B) 生成准确、类人的描述。
- KD-正则化 (KD-Regularization): 用于语音-文本对齐。
- PO-正则化 (PO-Regularization): 用于人类偏好对齐。
让我们分解一下完整的架构。
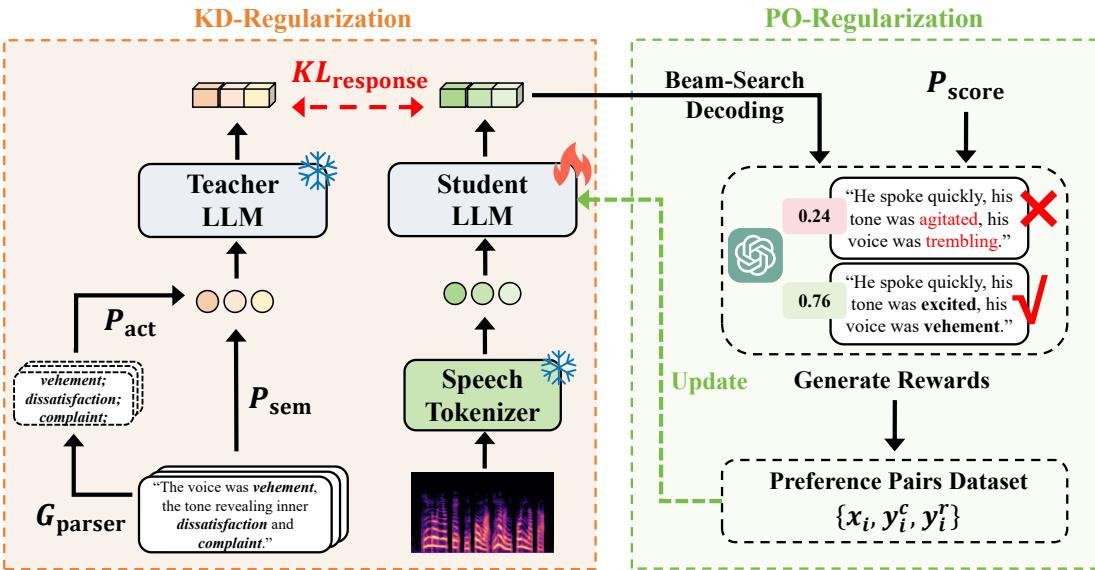
第一支柱: 通过 KD-正则化实现语音-文本对齐
AlignCap 的核心洞察是 知识蒸馏 (Knowledge Distillation, KD) 。 研究人员将 LLM 对 文本 的响应 (它非常擅长) 视为“教师”,将其对 语音 的响应 (它很吃力) 视为“学生”。
如果模型工作正常,无论是阅读愤怒演讲的文字记录,还是听到愤怒的音频本身,它生成下一个词的概率分布应该大致相同。
声学提示 (The Acoustic Prompt) 为了帮助模型,研究人员不仅仅向其提供原始音频 Token。他们提取了一个 声学提示 (\(P_{act}\)) 。 通过在文本字幕上使用语法解析器,他们提取情感线索 (关于语气、音高、节奏的形容词) 并将其插入模板中。
\[ \begin{array} { r l } & { e _ { 1 \sim n } = G _ { \mathrm { P a r s e r } } ( y _ { i } = \{ c _ { i } ^ { 1 } , . . . , c _ { i } ^ { | y _ { i } | } \} ) } \\ & { \mathrm { P } _ { \mathrm { a c t } } = \mathrm { I n s e r t } ( \mathrm { P } _ { \mathrm { T } } , i d x , e _ { 1 \sim n } ) } \end{array} \]这个提示充当了教师模型的“小抄”,确保其拥有丰富的情感语境。
蒸馏过程 在训练期间,模型试图最小化教师的预测分布 (基于文本 + 声学提示) 与学生的预测分布 (基于音频 Token) 之间的 KL-散度 (KL-Divergence) (一种差异度量) 。
\[ \begin{array} { r l } { \displaystyle } & { \displaystyle \min _ { \mathrm { L L M } _ { \mathrm { s t u } } ( \cdot ) } \mathcal { L } _ { \mathrm { K L } } ( p , x , y ) = } \\ & { - \displaystyle \sum _ { t , y _ { n } } p _ { \theta } ( y _ { n } | p _ { n } , y _ { < n } ) \log p _ { \theta } ( y _ { n } | x _ { n } , y _ { < n } ) } \end{array} \]通过最小化这种损失,学生 (语音模型) 学会了模仿教师 (文本模型) 的行为。
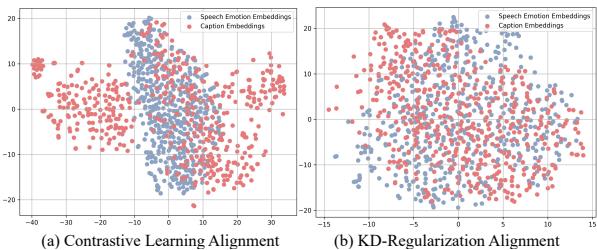
为什么在解码后对齐? 研究人员使用 t-SNE (一种高维数据可视化技术) 可视化了语音和文本输出的嵌入。
在下图中, (a) 显示了解码 前 的传统对齐。注意蓝点 (语音) 和红点 (文本) 形成了多少有些分离的簇。 在 (b) 中,使用了 AlignCap 的 KD-正则化 (解码 后) ,蓝点和红点紧密地交织在一起。这证明了模型几乎以相同的方式处理语音和文本,有效地弥合了分布差距。
第二支柱: 通过 PO-正则化实现人类偏好对齐
即使模型理解了语音,它仍可能生成机械或重复的字幕。为了解决这个问题,AlignCap 采用了 偏好优化 (Preference Optimization, PO) 。
这与 ChatGPT 等模型中使用的著名的 RLHF (人类反馈强化学习) 不同,后者需要训练单独的奖励模型,且计算成本高昂。相反,AlignCap 使用 直接偏好优化 (DPO) , 这是一种更简单、更稳定的方法。
创建偏好对 首先,模型为一段语音生成多个候选字幕。使用 GPT-3.5 根据特定的评分标准对这些字幕进行评分:

根据这些分数,研究人员创建了“选中” (\(y_c\)) 和“拒绝” (\(y_r\)) 的响应对。
优化 然后对模型进行微调,以增加生成“选中”字幕的可能性,同时降低生成“拒绝”字幕的可能性。这有效地推动模型远离幻觉,转向高质量、人类偏好的描述。
\[ \begin{array} { r } { \mathcal { L } _ { \mathrm { P O } } = \mathbb { E } _ { ( x , y _ { g } , y _ { n } ^ { c } ) } \Big [ \beta \log \sigma ( \log \frac { \pi _ { \theta } ( y _ { g } | x ) } { \pi _ { r e f } ( y _ { g } | x ) } } \\ { - \log \frac { \pi _ { \theta } ( y _ { n } ^ { c } | x ) } { \pi _ { r e f } ( y _ { n } ^ { c } | x ) } ) \Big ] } \end{array} \]实验与结果
团队在多个数据集上评估了 AlignCap,包括 MER2023、NNIME 以及他们构建的一个名为 EMOSEC 的新数据集。
零样本 (Zero-Shot) 性能
对 AI 模型最严峻的考验之一是“零样本”推理——即在从未见过的数据上执行任务。
如表 1 所示,AlignCap (特别是同时包含 KD 和 PO 的版本) 显著优于 HTSAT-BART 和 SECap 等基线模型。
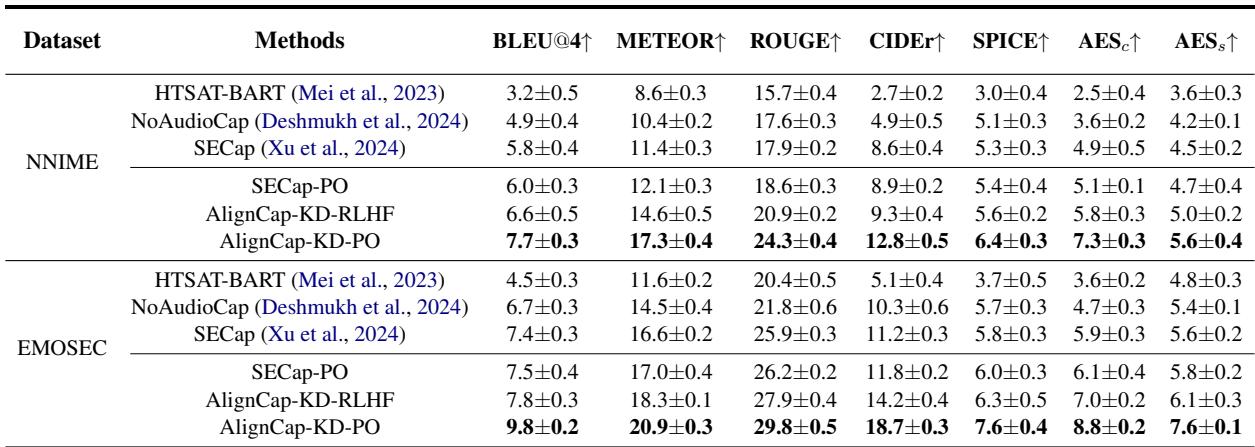
结果的主要结论:
- 指标: AlignCap 在 BLEU@4 (措辞准确性) 和 METEOR/ROUGE (丰富度和召回率) 方面领先。
- PO 的影响: 采用偏好优化 (PO) 的模型始终击败未采用的模型,证明与人类偏好对齐可以减少幻觉。
为什么 KD-对齐胜出
研究人员将他们基于 KD 的对齐与对比学习 (CL) 和投影等其他流行方法进行了比较。结果很明确: 将对齐视为知识蒸馏问题可以产生更好的翻译质量 (BLEU) 和语义丰富度 (METEOR)。
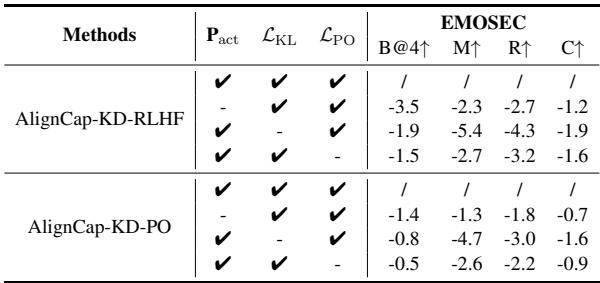
消融实验: 我们需要所有部分吗?
为了确保每个组件都是必要的,他们逐一移除了模型的部分。
- 移除 \(P_{act}\) (声学提示): 导致情感一致性下降。
- 移除 \(\mathcal{L}_{KL}\) (KD-正则化): 导致事实准确性显著下降,表明了语音-文本对齐的重要性。
- 移除 \(\mathcal{L}_{PO}\) (偏好优化): 导致忠实度得分降低,意味着模型开始更频繁地忽略指令。
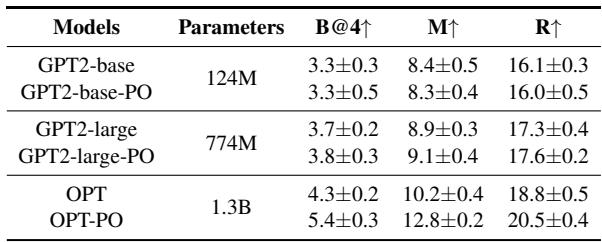
它在小模型上有效吗?
有趣的是,研究人员将 PO-正则化应用于较小的模型,如 GPT-2 和 OPT。虽然极小的模型 (GPT2-base) 获益甚微,但稍大一些的模型 (OPT-1.3B) 却有显著提升。这表明模型需要一定的“容量”来理解并从偏好优化中受益。
结论
AlignCap 代表了机器理解人类语音方式的重要一步。它超越了简单的“快乐/悲伤”标签,生成了丰富、描述性的字幕,捕捉到了我们说话方式的细微差别。
通过使用 KD-正则化 , 它强制模型像处理文本一样可靠地处理音频。通过使用 PO-正则化 , 它确保这些描述实际上对人类有意义,并且忠于事实。
随着我们迈向更具互动性的 AI 助手,这种技术将至关重要。它使 AI 不仅能理解你说了 什么,还能领会你在说这些话时的 感受——而且不会产生不存在的情感幻觉。