](https://deep-paper.org/en/paper/2410.21465/images/cover.png)
近年来,大型语言模型 (LLM) 的能力呈爆炸式增长,特别是在上下文长度方面。我们已经从仅能记住一个段落的模型,发展到像 Llama-3-1M 和 Gemini-1.5 这样能够一次性消化整本小说、代码库或法律档案的巨兽。
然而,这种能力伴随着巨大的计算代价。随着上下文长度的增加,存储 键值 (KV) 缓存 (即用于生成下一个 Token 的先前 Token 的存储激活值) 所需的内存也随之增加。对于一个 100 万 Token 的序列,KV 缓存可以轻松超过像 Nvidia A100 这样的顶级 GPU 的内存容量。
这就造成了一个两难的局面: 我们是为了节省内存而丢弃信息 (冒着降低准确性的风险) ,还是将数据卸载到 CPU (由于传输速度慢而严重拖慢推理速度) ?
在这篇文章中,我们将深入探讨 ShadowKV , 这篇新研究论文提出了巧妙的第三种选择。通过理解 KV 缓存的数学特性,作者开发了一个系统,该系统在 GPU 上保留“影子”表示,同时将大部分数据卸载到 CPU,从而在不牺牲准确性的情况下,实现了高达 6 倍的 Batch Size (批大小) 和 3 倍的吞吐量 。
问题所在: KV 缓存瓶颈
要理解为什么需要 ShadowKV,首先需要了解现代 LLM 推理中的瓶颈。
当 LLM 生成文本时,它是自回归的——它基于所有先前的 Token 来预测下一个 Token。为了避免为每个新词重新计算整个历史记录,我们将注意力机制的 Key (键) 和 Value (值) 矩阵保存在 GPU 内存中。这就是 KV 缓存 。
随着上下文长度 (\(S\)) 的增加,KV 缓存呈线性增长。对于长上下文模型 (例如 100k+ Token) ,这种缓存变得非常巨大。
- 内存墙 (Memory Wall) : 高带宽 GPU 内存 (HBM) 耗尽。这迫使你减小 Batch Size (同时处理的请求数量) ,从而损害吞吐量。
- 带宽墙 (Bandwidth Wall) : 即使你有足够的内存,为每个 Token 生成将如此多的数据从内存移动到计算单元也需要时间。
现有解决方案及其缺陷
研究人员尝试了一些技巧来缓解这个问题,但大多数都有明显的缺点:
- Token 驱逐 (Token Eviction) : 这种方法简单地从缓存中删除“不重要”的 Token。虽然速度快,但通常会导致信息丢失,导致模型忘记之前的上下文或在需要高精度的任务 (如编码) 中失败。
- 稀疏注意力 (驻留 GPU) : 这些方法将所有数据保留在 GPU 上,但只计算一部分注意力。这加快了数学运算,但没有解决内存容量问题。
- CPU 卸载 (CPU Offloading) : 这种方法将 KV 缓存移动到 CPU 的 RAM (便宜且充裕) 中,并只提取所需的内容。问题在于?连接 CPU 和 GPU 的 PCIe 总线速度很慢。提取数据会引入巨大的延迟。
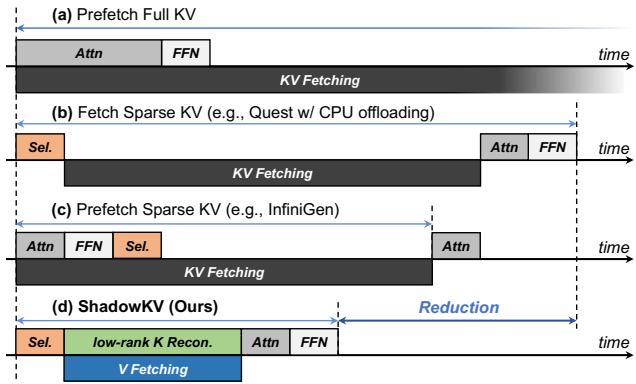
下图 4 展示了 ShadowKV 与这些方法的对比。请注意,传统的卸载 (图 b) 和预取 (图 c) 仍然受困于延迟或复杂性。ShadowKV (图 d) 引入了一种独特的流水线,可以动态地重构低秩 Key。
核心洞察
ShadowKV 团队不仅设计了一个更快的流水线;他们分析了 KV 缓存的数学结构,发现了使他们的方法成为可能的两个关键属性。
洞察 1: RoPE 之前的 Key 是低秩的
LLM 通常使用旋转位置嵌入 (RoPE) 来编码 Token 的位置。研究人员对 Llama-3 模型的权重和缓存进行了奇异值分解 (SVD) 。
他们发现了一个惊人的现象: Key (K) 缓存 在应用 RoPE 之前 是极低秩的。
在线性代数中,“低秩”矩阵包含大量冗余信息,可以在不丢失太多数据的情况下进行显著压缩。然而,一旦应用了 RoPE,旋转使得矩阵变为“满秩”且难以压缩。此外, Value (V) 缓存 从未 表现出低秩特性;它包含着密集的信息。
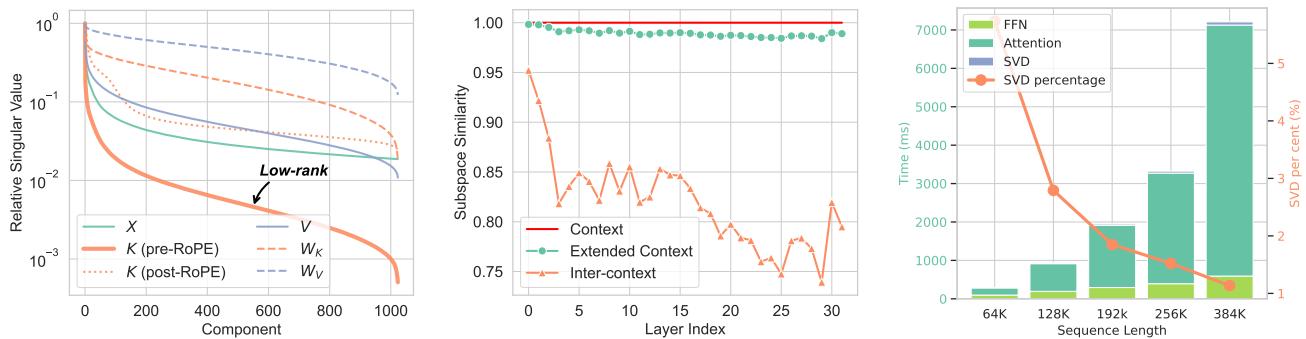
如 图 1 左图所示,“Pre-RoPE Key” (绿线) 的奇异值急剧下降,表明它是高度可压缩的 (低秩) 。Value 缓存 (紫线) 保持高位,意味着它不容易被压缩。
策略: 我们可以通过仅在 GPU 上存储其低秩投影来压缩 Key 缓存。庞大的 Value 缓存必须移动到 CPU,但由于我们只需要提取其中的特定部分,这可能是可控的。
洞察 2: Value 需要卸载,Key 可以重构
由于 Value 缓存占据了一半的内存且不可压缩,ShadowKV 将其完全卸载到 CPU。然而,Key 缓存被保留在 GPU 上——但以一种高度压缩的低秩形式。
在推理过程中,ShadowKV 在 GPU 内部 即时 从压缩版本重构完整的 Key 缓存。与通过 PCIe 总线移动数据的成本相比,这在计算上是非常廉价的。
洞察 3: 通过地标进行精确的稀疏选择
为了避免在整个 100 万 Token 的上下文中计算注意力,我们需要 稀疏注意力 。 我们只想关注最相关的 Token。
但是,如果不先加载它们,我们怎么知道哪些 Token 是相关的呢?
研究人员发现,Token 通常表现出“空间局部性”。如果一个 Token 是相关的,它的邻居很可能也是相关的。因此,他们将 Token 分组为 块 (Chunks) (例如大小为 8) 。他们计算该块的 Key 缓存的平均值 (均值) ,并将其存储为 “地标 (Landmark) ” 。
通过将当前的 Query 与这些地标进行比较,模型可以预测哪些块是重要的。然后,它只从 CPU 获取那些特定块的 Value 数据。
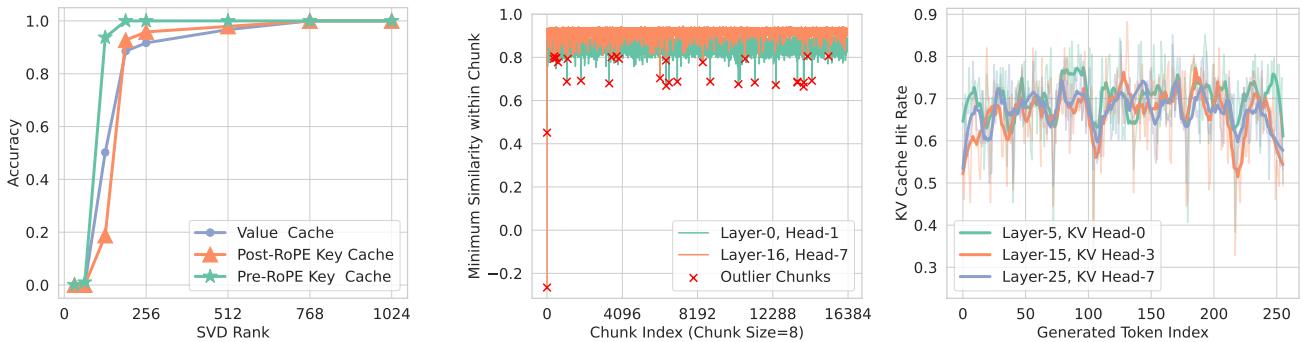
图 5 (中) 显示,虽然大多数块可以通过其均值来近似 (高相似度) ,但也存在一些 离群值 (Outliers) (红色十字) 。这些是在数学上独特且难以近似的块。ShadowKV 在预填充阶段检测这些罕见的离群值,并将它们永久保留在 GPU 的高速内存中,以确保准确性不会下降。
ShadowKV 方法
结合这些洞察,作者提出了一个在 GPU 和 CPU 之间分配工作负载的系统。
架构

如 图 3 所示,该系统分为两个阶段运行:
- 预填充 (左) :
- 模型处理输入提示词。
- Keys: 它获取 Pre-RoPE Keys 并使用 SVD 对其进行压缩。这些小的、低秩的 Key 留在 GPU 上。
- 地标 (Landmarks) : 它将 Key 分组为块,并计算每个块的均值 (地标) 。这些留在 GPU 上。
- 离群值 (Outliers) : 它识别出少数不符合近似规律的块,并将它们保留在 GPU 上。
- Values: 繁重的 Value 缓存被发送到系统 RAM (CPU) 。
- 解码 (右) :
- 在生成新 Token 时,模型使用 地标 来评分哪些块与当前 Query 相关。
- 并行执行: 这是神奇的一步。系统同时进行以下操作:
- 获取 Values: 仅从 CPU 请求 top-k 个相关的 Value 块。
- 重构 Keys: 使用 GPU 上的低秩投影重建相关的 Key 块并应用 RoPE。
- 因为 Value 获取 (内存受限) 和 Key 重构 (计算受限) 同时发生,数据获取的延迟被有效地隐藏了。
理论带宽
为什么要费这么大劲?归根结底是为了 等效带宽 。 通过减少传输的数据量并压缩保留的数据,ShadowKV 模拟了一个拥有比实际存在高得多的内存带宽的 GPU。
\[ { \widetilde { B } } = \frac { 2 S B _ { \mathrm { G P U } } } { S / C + 2 ( K + O ) C + ( 1 - \alpha ) K C B _ { \mathrm { G P U } } / B _ { \mathrm { P C I e } } } \]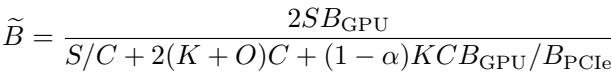
上面的公式计算了这个“等效带宽”。不用担心复杂的变量; 图 2 直观地展示了结论。
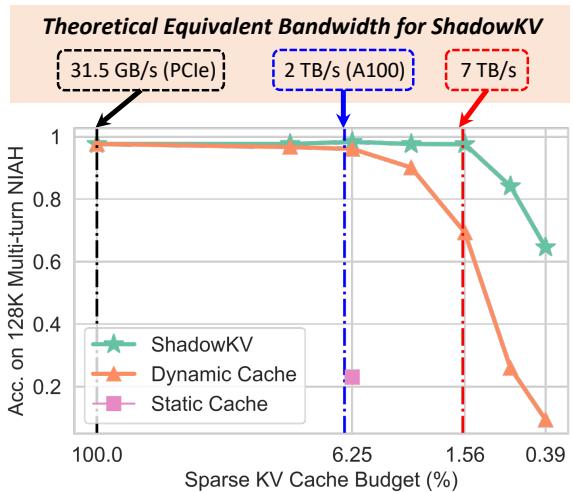
图表显示,即使在“稀疏 KV 缓存预算” (实际使用的数据量) 非常低的情况下,ShadowKV (绿星线) 也能保持高准确性。理论上,在 A100 GPU 上,ShadowKV 可以实现 7 TB/s 的等效带宽——远超 2 TB/s 的物理硬件限制。
实验结果
这个复杂的架构真的能兑现承诺吗?作者在主要基准测试上测试了 ShadowKV,包括 RULER、LongBench 和“大海捞针 (Needle In A Haystack) ”。
保持准确性
稀疏注意力和压缩的最大风险是模型变“笨”——它会忘记隐藏在长上下文中的细节。
表 1 将 ShadowKV 与 Quest、InfiniGen 和 Loki 等其他方法进行了比较。
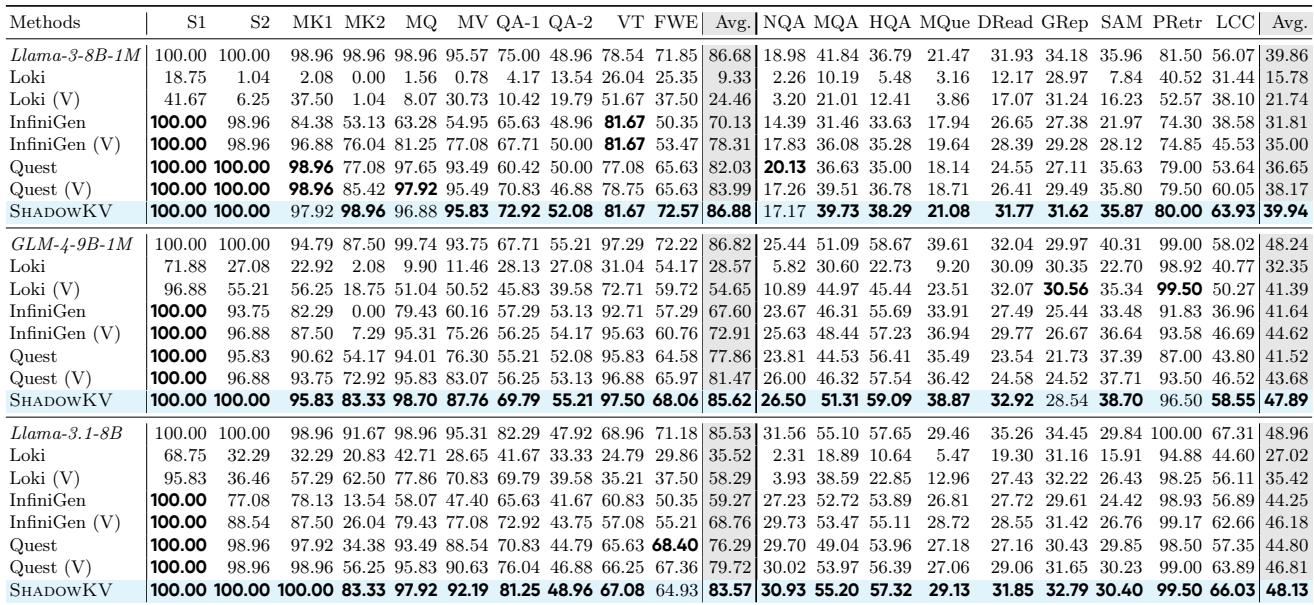
结果令人印象深刻。ShadowKV (粗体行) 始终与其原始模型 (“Full Attention”) 的准确性相匹配,即使是在需要精确检索的任务上,如“变量跟踪” (VT) 或问答 (QA) 。竞争方法的准确性往往会大幅下降 (例如,Loki 在某些任务上的得分降至接近零) 。
检索可视化: 大海捞针
“大海捞针”测试将一个特定的事实 (针) 隐藏在大段文本 (干草堆) 中的某个位置,并要求模型找到它。
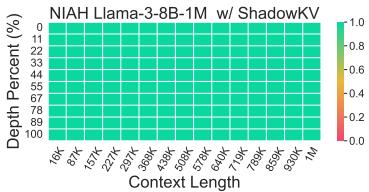
图 6 展示了 Llama-3-8B-1M 的结果。整个热力图都是绿色的,这意味着无论信息位于上下文中的哪个位置 (从 1K 到 1M Token) ,或者文档的深度如何,ShadowKV 都能成功检索到信息。
多轮对话
基于驱逐的策略 (如 SnapKV 或 StreamingLLM) 的一个常见失败模式是多轮聊天。如果你在第一个问题期间删除了“不重要”的 Token,你可能会意识到它们对第二个问题至关重要——但它们已经永远消失了。
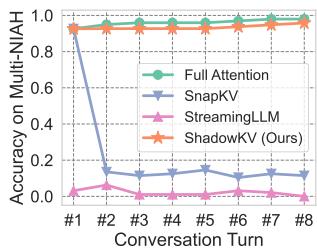
图 7 清楚地证明了这一点。虽然 SnapKV (蓝线) 在第一轮后崩溃,但 ShadowKV (橙线) 在 8 轮对话中保持了近乎完美的准确性,表现几乎与全注意力 (Full Attention,绿线) 完全相同。
吞吐量和效率
最后,让我们看看速度。主要目标是增加吞吐量和 Batch Size。
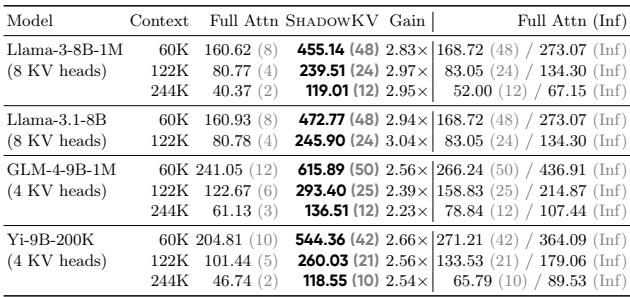
表 3 显示了在 Nvidia A100 GPU 上的吞吐量。
- Llama-3-8B-1M (122K 上下文) : 标准的全注意力在 Batch Size 为 4 时达到 80 tokens/s。ShadowKV 在 Batch Size 为 24 时达到 239 tokens/s 。
- 无限 Batch 假设: 最右边的一列显示,ShadowKV 的效率非常高,有时甚至超过了假设拥有无限 GPU 内存时全注意力的理论最大速度。
通过将繁重的 Value 缓存卸载到 CPU,ShadowKV 释放了大量的 GPU 内存。这允许你运行 6 倍大的 Batch Size (例如,60K 上下文中 Batch Size 48 vs 8) ,这是跑满 GPU 算力并最大化吞吐量的最有效方式。
结论
“内存墙”长期以来一直是部署长上下文 LLM 的大敌。ShadowKV 提供了一个令人信服且不妥协的解决方案。它不会盲目地删除数据 (像驱逐方法那样) ,也不会让 CPU 总线拖累 GPU (像朴素卸载那样) 。
通过认识到 Key 是可压缩的 而 Value 是可卸载的 , ShadowKV 编排了一首低秩重构和稀疏获取的交响乐。它有效地创建了一个“影子”缓存,允许标准 GPU 越级挑战,以处理短序列的速度和准确性来处理 100 万 Token 的上下文。
对于学生和从业者来说,这篇论文强调了一个重要的教训: 硬件限制 (如 GPU 内存) 往往不仅仅通过购买更多硬件来解决,最好的解决办法是理解你正在处理的数据的底层数学结构。