](https://deep-paper.org/en/paper/2410.21716/images/cover.png)
想象一下,你发现了一份丢失的手稿,据称是简·奥斯汀被遗忘的作品,或者你需要识别社交媒体上协同虚假信息传播背后的匿名始作俑者。这些场景都依赖于作者归属 (Authorship Attribution) ——这是一门依据语言模式确定特定文本作者的计算科学。
几十年来,该领域主要依赖于手动统计词汇或近年来对庞大神经网络进行微调。但是,一篇名为 A Bayesian Approach to Harnessing the Power of LLMs in Authorship Attribution 的新论文提出了一个令人着迷的转变。研究人员不再训练模型对作者进行分类,而是利用像 Llama-3 这样的大型语言模型 (LLM) 原始的、经过预训练的概率特性。
在这篇文章中,我们将剖析这种方法是如何工作的,为什么它在“单样本 (one-shot) ”场景中优于传统技术,以及它如何将 LLM 的生成能力转化为精确的取证工具。
问题: 识别机器背后的幽灵
作者归属可以说是笔迹分析的数字化版本。每位作者都有独特的“风格计量 (stylometric) ”指纹——这是词汇、句子结构、标点习惯和语法特质的组合。
历史上,解决这个问题主要涉及两种方法:
- 风格计量学 (Stylometry) : 统计特征的统计方法 (例如某人使用“the”或“however”的频率) 。这些方法具有可解释性,但往往会忽略文本中复杂的长距离依赖关系。
- 微调神经网络: 采用像 BERT 这样的模型,并在特定的作者数据集上重新训练它。虽然准确,但这在计算上非常昂贵,需要大量数据,而且每当嫌疑人名单中增加新作者时,都需要重新训练模型。
大型语言模型的登场
随着 GPT-4 和 Llama-3 的兴起,我们拥有了几乎“阅读”过整个互联网的模型。它们隐式地理解风格。然而,简单地问 LLM“这是谁写的?” (一种称为问答或 QA 的技术) 效果很差。LLM 容易产生幻觉,并且往往难以从长长的候选名单中做出正确选择。
这篇论文的研究人员认为,我们使用 LLM 的方式是错误的。与其把它们当作能够生成答案的聊天机器人,我们应该把它们当作能够对可能性进行评分的概率引擎。
核心方法: 贝叶斯方法
这篇论文的核心是一种被称为 LogProb 的方法。它将经典的贝叶斯统计与现代 Transformer 架构结合在了一起。
1. 贝叶斯框架
目标很简单: 给定一段未知文本 \(u\) 和一组候选作者,我们想要找出特定作者 \(a_i\) 写出 \(u\) 的概率。
在数学上,这使用贝叶斯定理表示:
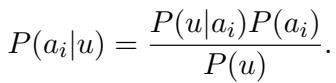
这里:
- \(P(a_i|u)\) 是后验概率 (posterior) : 即该作者写了这段文本的概率。
- \(P(u|a_i)\) 是似然概率 (likelihood) : 即假设是该特定作者写的情况下,这段文本存在的概率。
- \(P(a_i)\) 是先验概率 (prior) : 即我们在看到文本之前,该作者是撰写者的可能性 (通常假设所有候选者的先验概率相等) 。
由于 \(P(u)\) (文本通常发生的概率) 对所有作者来说都是常数,因此任务归结为计算似然概率 \(P(u|a_i)\)。如果我们能准确测量作者 A 写出文本 U 的可能性,我们就能解开这个谜团。
2. 从作者到文本蕴涵
为了计算 \(P(u|a_i)\),研究人员使用了作者提供的一组已知文本,记为 \(t(a_i)\)。他们基于这样一个假设: 如果一位作者写了这些已知文本,那么未知文本 \(u\) 的“风格”分布应该与之匹配。
通过一系列基于“同一作者的文本是独立同分布 (i.i.d.) ”假设的推导,研究人员展开了概率计算:
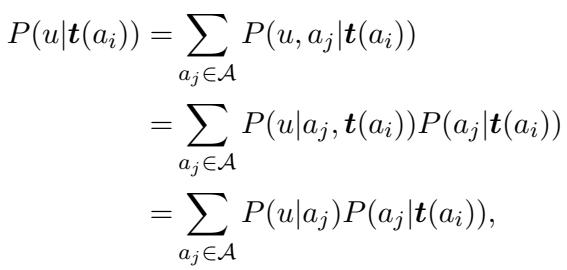
这看起来很复杂,但在“充分训练集”假设下,它会显著简化。理想情况下,已知文本 \(t(a_i)\) 具有足够的辨识度,以至于它们只能来自作者 \(a_i\)。这将其他作者写出这些确切已知文本的概率变为零:
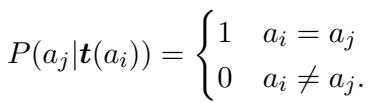
这导出了一个清晰可用的等式,即给定已知文本时未知文本的概率,实际上等同于给定作者时文本的概率:
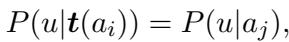
3. 利用 LLM 作为概率计算器
这就是大型语言模型发挥作用的地方。LLM 是自回归的——它们根据之前的 token 预测下一个 token。当 LLM 生成文本时,它会为其词汇表中每个可能的下一个词计算概率。
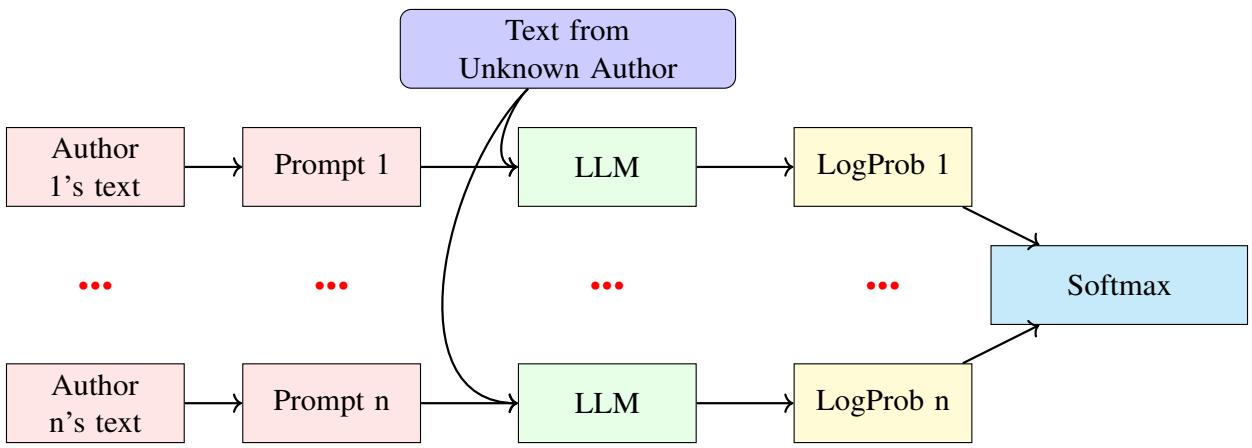
研究人员利用这一点来测量蕴涵 (entailment) 。 他们构建一个包含作者已知文本的提示 (Prompt) ,然后附加上未知文本。他们不是要求 LLM 生成文本;而是将未知文本强制输入模型,并问: “你对这一系列词语感到有多惊讶?”
如果 LLM 在提示中看到了作者的写作风格,并且未知文本与该风格匹配,LLM 将为未知文本中的 token 分配高概率。
给定上下文 (\(x_1\) 到 \(x_m\)) 的一系列 token (\(y_1\) 到 \(y_s\)) 的概率,是每个单独 token 概率的乘积:
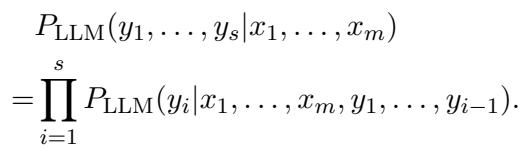
4. 算法实战
“LogProb” 方法将所有这些结合在一起。为了检查未知文本 \(u\) 是否属于某位已知作者,系统会:
- 获取该作者的已知文本 (\(t(a_i)\)) 。
- 构建一个提示 (例如,“这是同一位作者的一段文本: ”) 。
- 将其输入到 LLM 中。
- 计算未知文本 \(u\) 跟随该提示出现的概率。
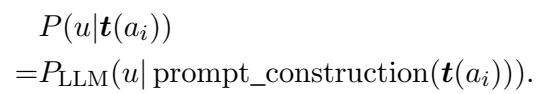
系统会对每位候选作者重复此过程。得出最高概率 (或最小“惊讶度”) 的候选人被认定为作者。
整体架构如下图所示。请注意未知文本是如何针对每个候选作者的模型实例进行评估,以找到最佳匹配的。
实验与结果
为了验证这一理论,研究人员使用了两个数据集: IMDb62 (来自 62 位多产用户的电影评论) 和一个 Blog 数据集 (来自数千名博主的帖子) 。
他们设置了一个“单样本 (one-shot) ”学习场景: 模型只获得候选人的一篇已知文章来学习其风格,然后尝试归属一篇新的匿名文本。
与基准的比较
结果令人印象深刻。研究人员将使用 Llama-3-70B 的 LogProb 方法与以下方法进行了比较:
- QA 方法: 询问 GPT-4 或 Llama-3 “这是谁写的?”
- 嵌入方法: 需要训练的基于 BERT 的模型 (BertAA, GAN-BERT) 。
LogProb 方法在 10 个候选人的 IMDb 数据集上达到了约 85% 的准确率 。
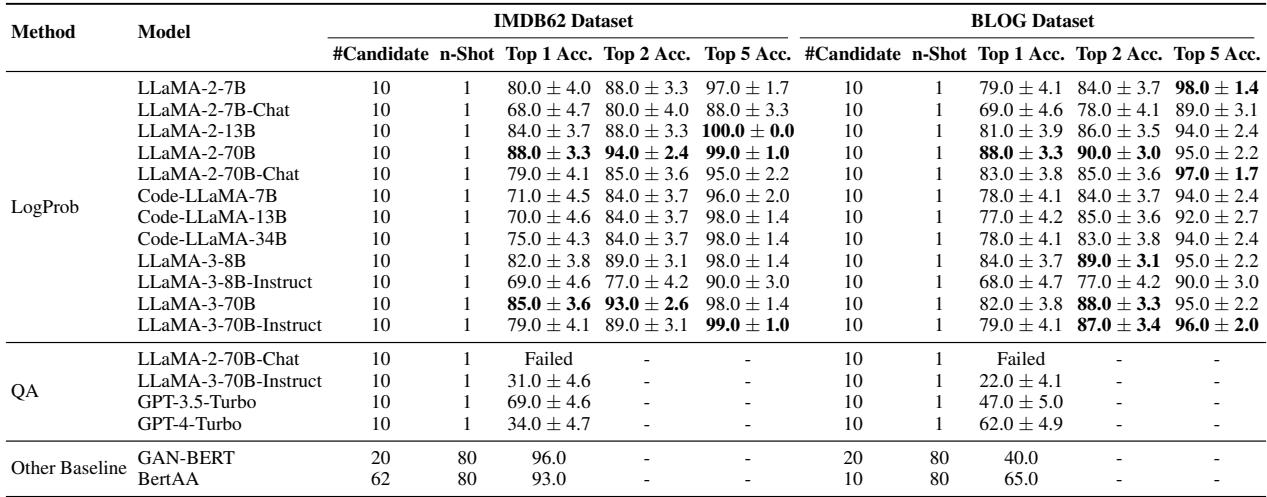
结果的关键结论:
- QA 失败: 如表所示 (标记为 QA) ,直接询问模型会导致性能不佳 (GPT-4-Turbo 为 34%) 。模型很难明确地推理作者身份。
- LogProb 成功: 使用 Llama-3-70B 的贝叶斯方法达到了 85% 的准确率,与需要大量微调的方法相媲美甚至更优。
- 无需训练: 与 GAN-BERT 不同 (后者需要为每组新作者重新训练) ,LogProb 方法仅需一个提示即可即时工作。
规模化的挑战
作者归属中的一个常见问题是,随着嫌疑人数量的增加,准确率会直线下降。如果你有 50 个潜在作者,选出正确的那一个要比只有 2 个时难得多。
研究人员分析了 LogProb 方法是如何应对规模扩展的。
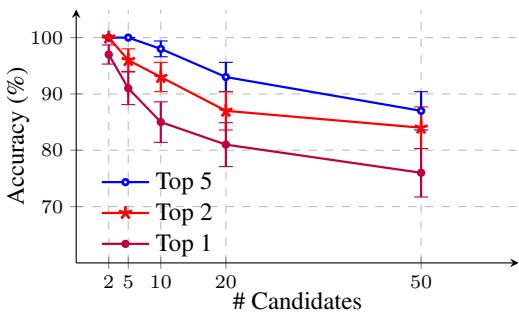
如上图所示,虽然随着候选人池增长到 50 人,“Top 1”准确率 (找到确切作者) 有所下降,但 Top 5 准确率仍然很稳健 (接近 90%) 。这意味着即使模型没有把确切的作者排在第一位,正确的作者也几乎总是在前几个建议中。这对于缩小嫌疑人名单的取证团队来说非常有价值。
作为参考,“Top k Accuracy”指标定义如下:
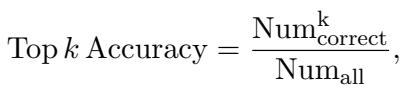
对提示词的敏感度
提示词的具体措辞重要吗?如果我们说“分析写作风格”而不是仅仅说“这是一段文本”,准确率会改变吗?

研究发现,使用某种提示比没有提示要好 (第 1 行与第 2-5 行相比) 。然而,提示的具体措辞 (Prompt 1 与 Prompt 4) 对最终分数的影响微乎其微。这表明该方法是鲁棒的,不需要脆弱的“提示工程”也能工作。
偏见与子群体分析
关于性别和年龄,出现了一个有趣的,也许是社会语言学方面的发现。
性别差异
模型发现归属女性博主的作者身份比男性博主更容易。
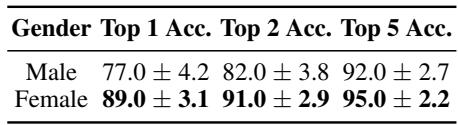
如上表所示,女性作者的 Top-1 准确率 (89.0%) 明显高于男性作者 (77.0%) 。作者推测,该数据集中的女性撰写的博客可能包含更独特的个人风格标记,使其更容易被识别指纹。
我们也可以在这里看到汇总的性别数据:

年龄与内容评分
研究人员还查看了作者的年龄和评论的内容。
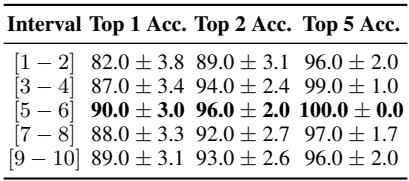
- 年龄: 年轻作者 (13-17 岁) 更容易被识别 (90% 准确率) ,而年长作者 (33-40 岁,约为 88%) 则相对难一些。这符合语言学理论,即年轻群体通常使用更独特、不断演变的俚语和风格选择。
- 评分: 在 IMDb 数据集中,极端的评论 (评分非常高或非常低) 比中庸的评论 (评分 5-6) 稍微难归属一些,后者达到了最高的准确率。
效率: 速度与成本
最后,为什么要使用这种方法而不是标准的问答 (QA) ?除了准确性之外,还有一个巨大的效率论据。
在 QA 方法中,LLM 必须逐个生成 token 来写出作者的名字。在 LogProb 方法中,模型只需执行单次前向传播来计算概率。

如表所示,LogProb 方法的速度大幅提升 (462 秒 vs 2065 秒) ,同时准确率也高得多。
结论
论文 A Bayesian Approach to Harnessing the Power of LLMs in Authorship Attribution 标志着司法语言学迈出了重要一步。通过将大型语言模型不视为创意作家,而是视为概率计算器,作者们解锁了一种强大的、无需训练的作者身份识别方法。
这种 “LogProb” 方法:
- 消除了微调的需求 , 节省了计算资源。
- 大幅优于直接询问 LLM 的效果。
- 扩展性良好 , 可应对许多候选人,并能有效处理有限数据 (单样本) 。
虽然存在局限性——例如运行 70B 参数模型的高成本以及可能从训练数据中继承的潜在偏见——但这项研究表明,LLM 的真正力量可能潜藏在其生成的文本表面之下,深植于驱动它们的数学概率之中。对于 NLP 学生和研究人员来说,这是一个令人信服的提醒: 有时使用模型的最佳方式是停止向它提问,开始测量它的惊讶度。