](https://deep-paper.org/en/paper/2410.22642/images/cover.png)
你是否曾经让 AI 写过一篇关于争议性话题的文章?通常,结果乍一看令人印象深刻。语法完美,词汇考究,结构似乎也很合理。但如果你仔细观察,就会发现裂痕。AI 可能在第一句话中提出了一个大胆的主张,却在三句话后提供了与之相矛盾的证据。或者,它可能列出了一些技术上正确但与当前论点无关的事实。
这是议论文生成 (Argumentative Essay Generation, AEG) 中的一个典型问题。虽然大型语言模型 (LLMs) 在预测下一个单词方面表现出色,但它们往往难以处理高层级的逻辑架构。它们知道如何写作,但往往忘记了为什么要写特定的句子,从而导致“逻辑幻觉”。
在这篇文章中,我们将深入探讨一篇引人入胜的研究论文,题为 “Prove Your Point!: Bringing Proof-Enhancement Principles to Argumentative Essay Generation” (证明你的观点!: 将论证增强原则引入议论文生成) 。 研究人员提出了一个名为 PESA (Proof-Enhancement and Self-Annotation,论证增强与自标注) 的新框架,教导 AI 不仅仅是生成文本,而是像人类辩手一样遵守严格的逻辑和论证原则。
问题: 逻辑混乱
议论文写作不同于创意写作。它需要连贯的流程,即中心论点由多个主张 (Claims) 支持,而这些主张又由具体的证据 (Grounds,即依据) 支持。
目前的方法通常使用“规划-写作” (Plan-and-Write) 范式。它们生成一系列关键词或知识图谱来指导文章。然而,这些规划往往过于简单。它们告诉模型使用什么词,却没告诉模型如何构建论证结构。
看看下面这篇研究论文中的例子。模型被要求讨论公共图书馆是否应该把钱花在昂贵的高科技媒体上。

在上方的例子中 (没有论证原则) ,模型声称技术使获取信息变得更容易。但在紧接着的下一句话中,它提供的“证据”却是搜索引擎无法找到信息。这是一个逻辑上的自相矛盾。下方使用我们要讨论的原则生成的例子,则提出了关于维护成本的主张,并用关于图书馆资金的具体数据来支持它。
背景: 图尔敏论证模型
为了解决这个问题,研究人员借鉴了哲学和修辞学中的一个经典理论: 图尔敏论证模型 (Toulmin Argumentation Model) 。
该模型由斯蒂芬·图尔敏 (Stephen Toulmin) 提出,认为一个有效的论证由几个特定部分组成。为了适应 AI 生成,研究人员将其简化为一个包含两个主要层级的树状结构:
- 主张 (Claims,抽象层) : 这些是文章所采取的高层级断言或立场。
- 依据 (Grounds,具体层) : 这些是支持主张的具体数据、证据、理据或推论。
大多数 AI 模型试图一次性生成整篇文章 (主张 + 依据 + 填充内容) 。这篇论文的核心思想是强制 AI 先规划主张 , 然后基于这些主张规划依据 , 最后才撰写文章。
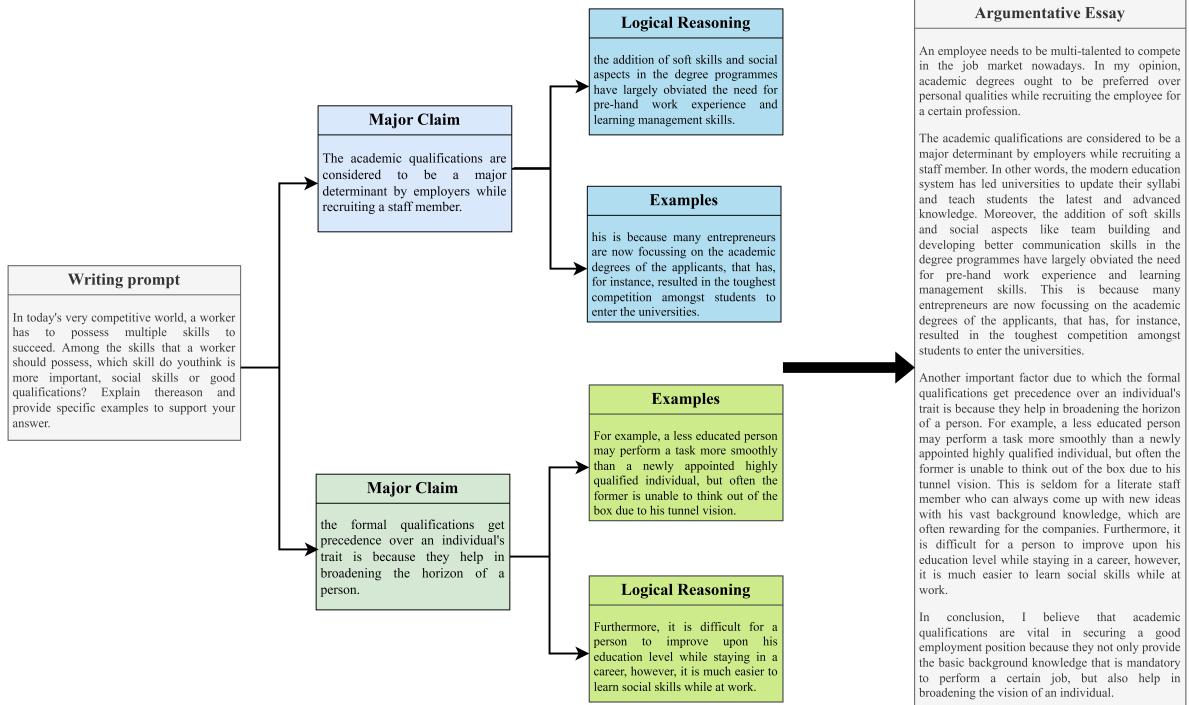
如上图 4 所示,人类撰写的文本自然遵循这种结构。一个写作提示引出主要主张,主张再分支为具体的推理和例子。PESA 框架的目标就是模仿这种思维过程。
核心方法: PESA
研究人员开发了一个名为 PESA 的统一框架。它代表 Proof-Enhancement (论证增强) 和 Self-Annotation (自标注) 。
这两个名称对应了该领域的两大挑战:
- 论证增强: 我们如何强制模型遵循逻辑结构?
- 自标注: 我们从哪里获取训练数据? (标准数据集包含文章,但没有单独标记“主张”和“依据”) 。
让我们看看系统的完整架构:
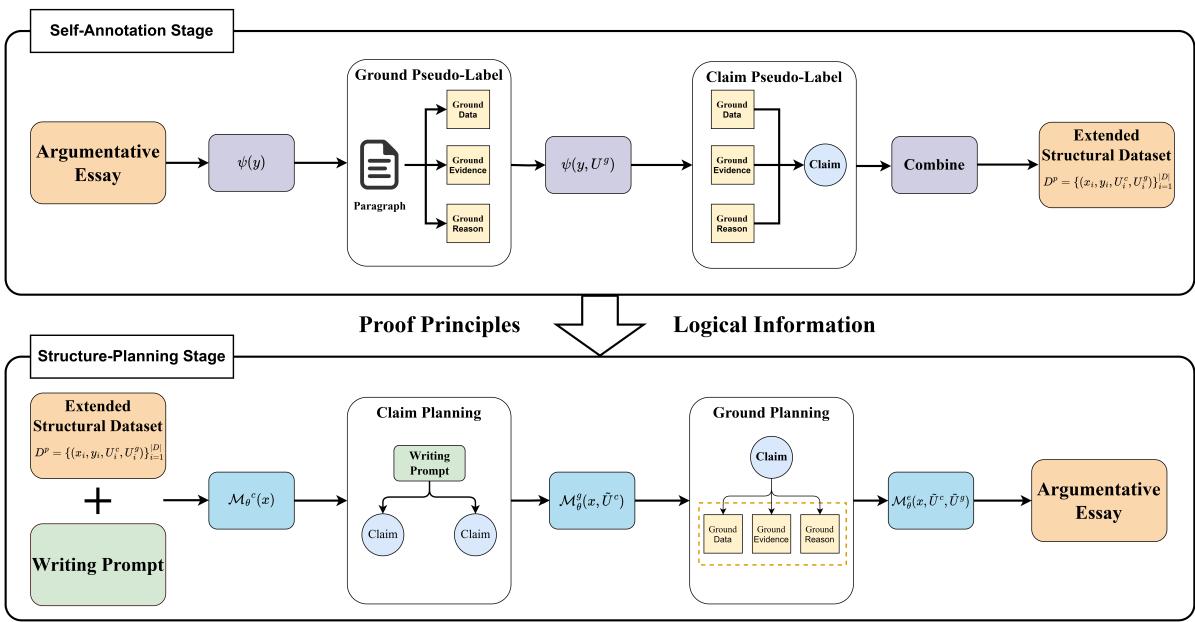
该框架在一个循环中运行。图片的下半部分代表数据准备 (自标注) ,上半部分代表实际生成过程 (论证增强) 。让我们逐步分解。
第一阶段: 自标注 (数据问题)
训练一个模型来生成“主张”和“依据”,需要一个已经将文章拆分为这些组件的数据集。由于手动创建此类数据集成本高昂,研究人员使用了一种称为自标注的技术。
他们利用强大的 LLM (GPT-4) 对现有的高质量文章进行“逆向工程”。这就像文本摘要任务,但是按照写作过程的相反顺序进行的:
- 提取依据 (\(U^g\)) : 模型阅读人类文章 (\(Y\)) 的一个段落,并总结具体的证据和推理。
- 提取主张 (\(U^c\)) : 模型阅读提取出的依据和文章,以总结要点 (主要主张) 。
这在数学上形式化为:
\[ \begin{array} { l } { { U ^ { g } = \psi ( y ) , } } \\ { { U ^ { c } = \psi ( y , U ^ { g } ) , } } \end{array} \]这里,\(\psi\) 代表基于 LLM 的提取函数。这个过程将标准的文章数据集转化为包含提示词 (\(X\)) 、主张规划 (\(U^c\)) 、依据规划 (\(U^g\)) 和最终文章 (\(Y\)) 的“伪标签”数据集。
第二阶段: 论证增强 (生成过程)
一旦模型在这个结构化数据上训练完毕,它就可以使用三步走的树状规划方法来生成新文章。这种层级结构确保逻辑自上而下流动,防止了标准语言模型常见的“漫无边际”现象。
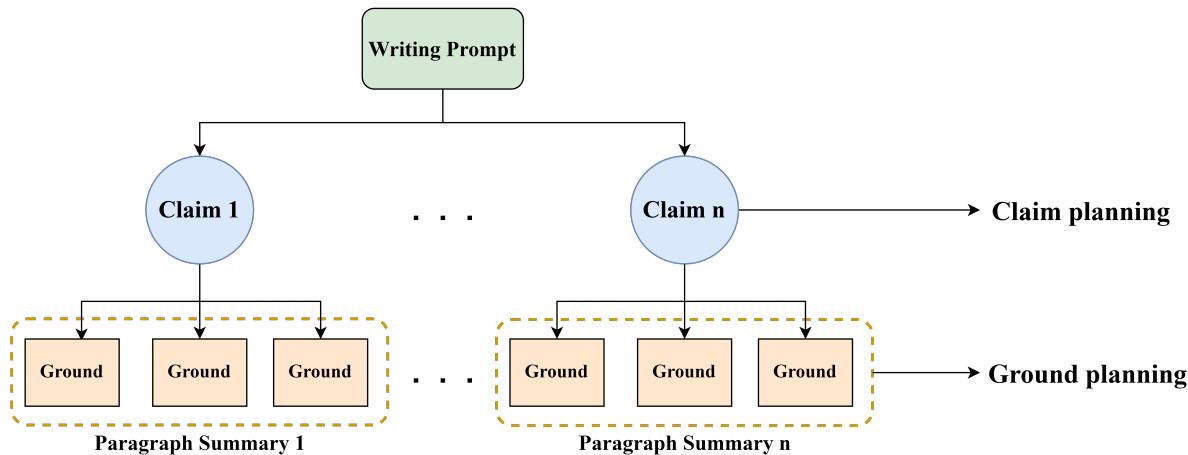
第一步: 主张规划
首先,模型 (\(\mathcal{M}^c\)) 查看写作提示词 (\(x\)) 并生成主要主张 (\(U^c\)) 。这充当了文章的骨架。它决定了立场和主要论点,而不会陷入细节泥潭。
\[ \tilde { U } ^ { c } = { \mathcal { M } } _ { \theta } { } ^ { c } ( x ) . \]第二步: 依据规划
接下来,第二个模型 (\(\mathcal{M}^g\)) 获取提示词 (\(x\)) 以及刚刚生成的主张 (\(U^c\)) ,来生成依据 (\(U^g\)) 。这为骨架填充了血肉——即直接支持主张的证据、数据和推理。
\[ { \tilde { U } } ^ { g } = { \mathcal { M } } _ { \theta } ^ { g } ( x , { \tilde { U } } ^ { c } ) . \]第三步: 文章生成
最后,生成模型 (\(\mathcal{M}^e\)) 利用提示词、主张和依据来撰写最终的文章 (\(y\)) 。由于逻辑和证据已经规划好了,模型本质上只需要用流畅的语言“将这些点连接起来”。
\[ \tilde { y } = \mathcal { M } _ { \theta } ^ { e } ( x , \tilde { U } ^ { c } , \tilde { U } ^ { g } ) . \]训练模型
该系统针对每个阶段使用不同的损失函数进行训练。这确保了模型既能学会成为优秀的规划者,也能学会成为优秀的写作者。
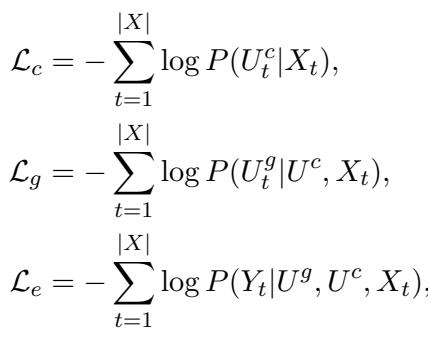
- \(\mathcal{L}_c\): 如果主张与训练数据不匹配,则惩罚模型。
- \(\mathcal{L}_g\): 如果依据不匹配 (在给定主张的情况下) ,则惩罚模型。
- \(\mathcal{L}_e\): 如果最终文章不匹配 (在给定主张和依据的情况下) ,则惩罚模型。
实验与结果
研究人员在 ArgEssay 数据集上评估了 PESA,该数据集包含超过 11,000 篇关于雅思 (IELTS) 和托福 (TOEFL) 等考试主题的文章。他们将 PESA 与几个强基准模型进行了比较,包括 LLaMA-2 (微调版) 和以前最先进的规划模型,如 DD-KW (带关键词的双解码器) 。
自动评估
由于自动评估文章质量很难,研究人员使用 GPT-4 作为裁判,要求它根据相关性、推理有效性和证据可信度对文章进行评分。
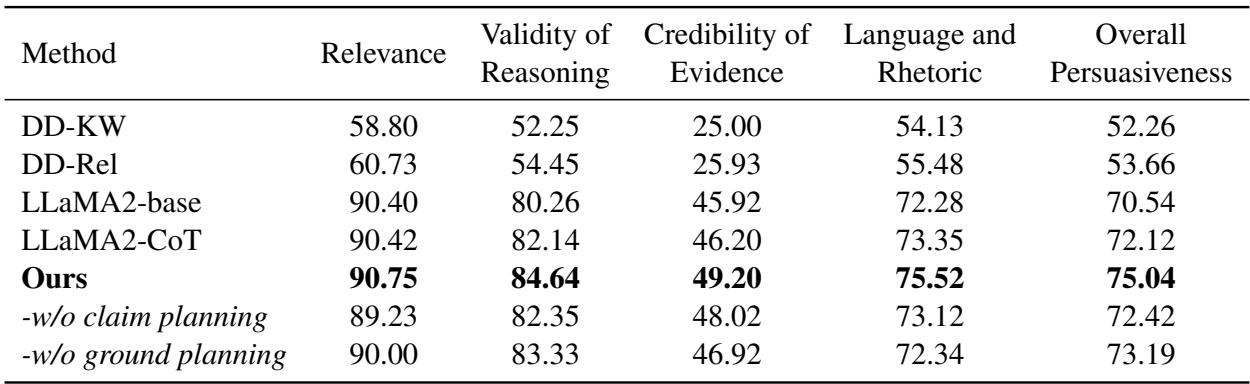
注: 上表显示了自动评估结果。
结果令人印象深刻。PESA (标记为 “Ours”) 的表现优于所有基准模型。
- 推理有效性 (Validity of Reasoning) : PESA 得分为 84.64 , 显著高于标准的 LLaMA2-base (80.26) 。
- 证据可信度 (Credibility of Evidence) : PESA 得分为 49.20 , 击败了最接近的竞争对手。
这证实了显式规划“主张”和“依据”有助于模型坚持逻辑路径。
人工评估
虽然自动指标很有用,但人类判断是写作评估的黄金标准。研究人员聘请了评估员将 PESA 与基准模型甚至 ChatGPT 进行比较。
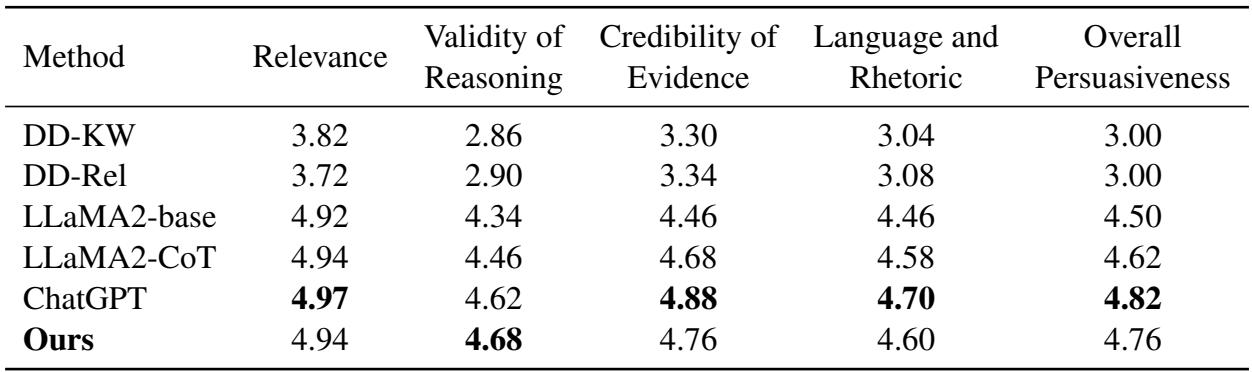
如上表所示,PESA 在整体说服力 (Overall Persuasiveness) 方面达到了 4.76 分,几乎与 ChatGPT (4.82) 持平。考虑到 PESA 基于 LLaMA-13B,这是一个比 ChatGPT 背后的大规模架构小得多的模型,这一成绩非常显著。
研究人员还进行了“正面对决”的胜率分析:
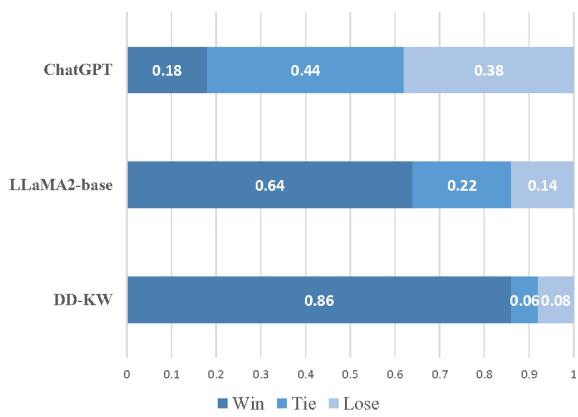
当直接与其他模型对比时:
- PESA 在 86% 的情况下战胜了 DD-KW (之前的特定 AEG 方法) 。
- PESA 在 64% 的情况下战胜了 LLaMA-2-base 。
- 对比 ChatGPT , PESA 在约 62% 的案例中取得了平局或胜利 , 证明它极具竞争力。
“自标注”真的有效吗?
批评者可能会问: “GPT-4 生成的数据真的足以用来训练吗?”研究人员通过让人类对伪标签 (提取出的主张和依据) 的质量进行评分来分析这一点。
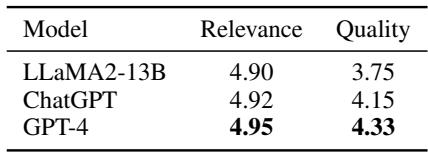
数据显示,GPT-4 (用于最终方法) 生成了高度相关且高质量的规划数据 (相关性得分 4.95/5) 。这验证了利用更强的模型来“教导”较小模型如何构建思维的策略。
结论与启示
PESA 框架代表了自然语言生成领域向前迈出的重要一步。它使我们从“黑盒”生成——即我们寄希望于模型能搞对逻辑——转向了一个结构化、透明的过程。
通过整合图尔敏论证模型 , 研究人员成功教会了 AI:
- 规划其主要论点 (主张) 。
- 用证据充实这些论点 (依据) 。
- 基于该规划撰写连贯的文章。
最令人兴奋的结论是逻辑可以与模型规模解耦 。 你不一定需要万亿参数的模型来写出有说服力的文章。你需要的是一个理解说服结构的模型。通过显式地对论证过程进行建模,一个较小的模型 (LLaMA-13B) 能够实现越级挑战,提供与 ChatGPT 媲美的结果。
对于学生和 AI 研究人员来说,这突显了归纳偏置 (inductive bias) 的重要性——即设计反映问题底层结构 (在本例中是论证的层级性质) 的模型架构,而不是仅仅依赖海量的非结构化数据。